神经网络中使用激活函数来加入非线性因素,提高模型的表达能力。
ReLU(Rectified Linear Unit,修正线性单元)
形式如下:
\[ \begin{equation} f(x)= \begin{cases} 0, & {x\leq 0} \\\\ x, & {x\gt 0} \end{cases} \end{equation} \]
ReLU公式近似推导::
\[ \begin{align} f(x) &=\sum_{i=1}^{\inf}\sigma(x-i+0.5) &\text{(stepped sigmoid)} \\\\ &\approx\log(1+e^x) &\text{(softplus function)} \\\\ &\approx\max(0,x+N(0,1)) &\text{(ReL function)} \\\\ 其中\sigma(z) &={1\over 1+e^{-z}} &\text{(sigmoid)} \end{align} \]
下面解释上述公式中的softplus,Noisy ReLU.
softplus函数与ReLU函数接近,但比较平滑, 同ReLU一样是单边抑制,有宽广的接受域(0,+inf), 但是由于指数运算,对数运算计算量大的原因,而不太被人使用.并且从一些人的使用经验来看(Glorot et al.(2011a)),效果也并不比ReLU好.
softplus的导数恰好是sigmoid函数.softplus 函数图像:

Noisy ReLU1
ReLU可以被扩展以包括高斯噪声(Gaussian noise):
\(f(x)=\max(0,x+Y), Y\sim N(0,\sigma(x))\)
Noisy ReLU 在受限玻尔兹曼机解决计算机视觉任务中得到应用.
ReLU上界设置: ReLU相比sigmoid和tanh的一个缺点是没有对上界设限.在实际使用中,可以设置一个上限,如ReLU6经验函数: \(f(x)=\min(6,\max(0,x))\). 参考这个上限的来源论文: Convolutional Deep Belief Networks on CIFAR-10. A. Krizhevsky
ReLU的稀疏性(摘自这里):
当前,深度学习一个明确的目标是从数据变量中解离出关键因子。原始数据(以自然数据为主)中通常缠绕着高度密集的特征。然而,如果能够解开特征间缠绕的复杂关系,转换为稀疏特征,那么特征就有了鲁棒性(去掉了无关的噪声)。稀疏特征并不需要网络具有很强的处理线性不可分机制。那么在深度网络中,对非线性的依赖程度就可以缩一缩。一旦神经元与神经元之间改为线性激活,网络的非线性部分仅仅来自于神经元部分选择性激活。
对比大脑工作的95%稀疏性来看,现有的计算神经网络和生物神经网络还是有很大差距的。庆幸的是,ReLu只有负值才会被稀疏掉,即引入的稀疏性是可以训练调节的,是动态变化的。只要进行梯度训练,网络可以向误差减少的方向,自动调控稀疏比率,保证激活链上存在着合理数量的非零值。
ReLU 缺点
- 坏死: ReLU 强制的稀疏处理会减少模型的有效容量(即特征屏蔽太多,导致模型无法学习到有效特征)。由于ReLU在x < 0时梯度为0,这样就导致负的梯度在这个ReLU被置零,而且这个神经元有可能再也不会被任何数据激活,称为神经元“坏死”。
- 无负值: ReLU和sigmoid的一个相同点是结果是正值,没有负值.
ReLU变种
Leaky ReLU
当\(x<0\)时,\(f(x)=\alpha x\),其中\(\alpha\)非常小,这样可以避免在\(x<0\)时,不能够学习的情况:
\[ f(x)=\max(\alpha x,x) \]
称为Parametric Rectifier(PReLU),将 \(\alpha\) 作为可学习的参数.
当 \(\alpha\) 从高斯分布中随机产生时称为Random Rectifier(RReLU)。
当固定为\(\alpha=0.01\)时,是Leaky ReLU。
优点:
- 不会过拟合(saturate)
- 计算简单有效
- 比sigmoid/tanh收敛快
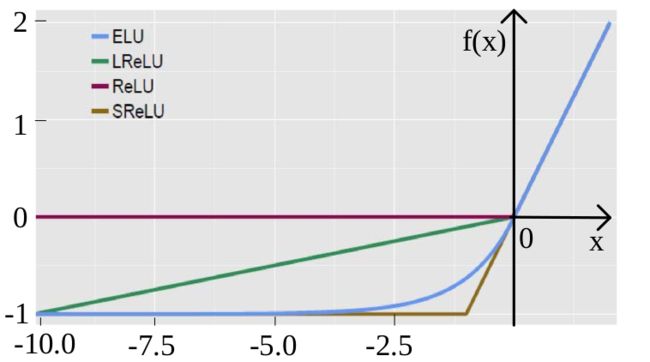
指数线性单元ELU
\[ \begin{equation} f(x)= \begin{cases} \alpha(e^x-1), & \text{$x\leq 0$} \\ x, & \text{$x\gt 0$} \end{cases} \end{equation} \]
\[ \begin{equation} f'(x)= \begin{cases} f(x)+\alpha, & \text{$x\leq 0$} \\ 1, & \text{$x\gt 0$} \end{cases} \end{equation} \]
exponential linear unit, 该激活函数由Djork等人提出,被证实有较高的噪声鲁棒性,同时能够使得使得神经元
的平均激活均值趋近为 0,同时对噪声更具有鲁棒性。由于需要计算指数,计算量较大。
ReLU family:
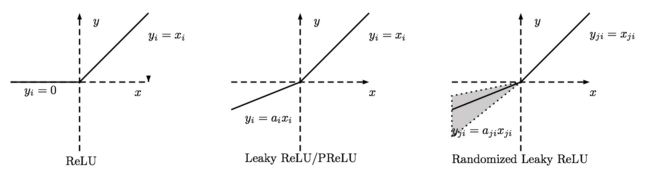
Leaky ReLU \(\alpha\)是固定的;PReLU的\(\alpha\)不是固定的,通过训练得到;RReLU的\(\alpha\)是从一个高斯分布中随机产生,并且在测试时为固定值,与Noisy ReLU类似(但是区间正好相反)。
ReLU系列对比:
SELU
论文: 自归一化神经网络(Self-Normalizing Neural Networks)中提出只需要把激活函数换成SELU就能使得输入在经过一定层数之后变成固定的分布. 参考对这篇论文的讨论.
SELU是给ELU乘上系数 \(\lambda\), 即 \(\rm{SELU}(x)=\lambda\cdot \rm{ELU}(x)\)
\[ f(x)=\lambda \begin{cases} \alpha(e^x-1) & x \le 0 \\ x & x>0 \end{cases} \]
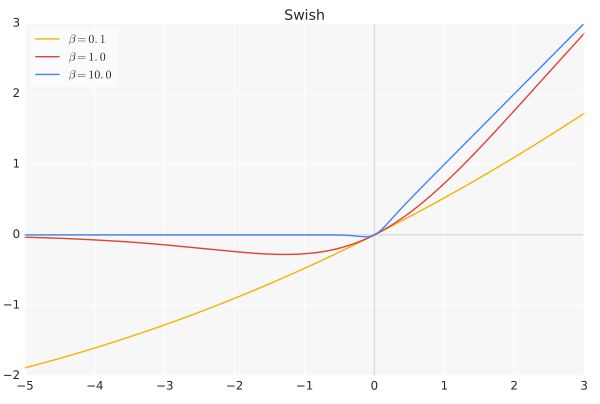
Swish
paper Searching for Activation functions(Prajit Ramachandran,Google Brain 2017)
\[ f(x) = x · \text{sigmoid}(βx) \]
β是个常数或可训练的参数.Swish 具备无上界有下界、平滑、非单调的特性。
Swish 在深层模型上的效果优于 ReLU。例如,仅仅使用 Swish 单元替换 ReLU 就能把 Mobile NASNetA 在 ImageNet 上的 top-1 分类准确率提高 0.9%,Inception-ResNet-v 的分类准确率提高 0.6%。
导数:
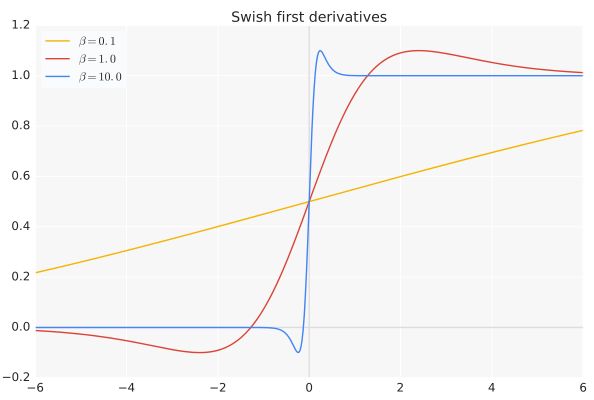
当β = 0时,Swish变为线性函数\(f(x) ={x\over 2}\).
β → ∞, $ σ(x) = (1 + \exp(−x))^{−1} $为0或1. Swish变为ReLU: f(x)=2max(0,x)
所以Swish函数可以看做是介于线性函数与ReLU函数之间的平滑函数.
工程实现:
在TensorFlow框架中只需一行代码: x * tf.sigmoid(beta * x)或tf.nn.swish(x).
在Caffe中使用Scale+Sigmoid+EltWise(PROD)来实现或者合并成一个层.代码参考.
Maxout
论文Maxout Networks(Goodfellow,ICML2013)
Maxout可以看做是在深度学习网络中加入一层激活函数层,包含一个参数k.这一层相比ReLU,sigmoid等,其特殊之处在于增加了k个神经元,然后输出激活值最大的值.
我们常见的隐含层节点输出:
\[h_i(x)=\text{sigmoid}(x^TW_{…i}+b_i)\]
而在Maxout网络中,其隐含层节点的输出表达式为:
\[h_i(x)=\max_{j\in[1,k]}z_{ij}\]
其中\(z_{ij}=x^TW_{…ij}+b_{ij}, W\in R^{d\times m\times k}\)
以如下最简单的多层感知器(MLP)为例:

图片来源:slides
假设网络第i层有2个神经元x1、x2,第i+1层的神经元个数为1个.原本只有一层参数,将ReLU或sigmoid等激活函数替换掉,引入Maxout,将变成两层参数,参数个数增为k倍.
优点:
- Maxout的拟合能力非常强,可以拟合任意的凸函数。
- Maxout具有ReLU的所有优点,线性、不饱和性。
- 同时没有ReLU的一些缺点。如:神经元的死亡。
缺点:
从上面的激活函数公式中可以看出,每个神经元中有两组(w,b)参数,那么参数量就增加了一倍,这就导致了整体参数的数量激增。
Maxout激活函数
与常规激活函数不同的是,它是一个可学习的分段线性函数.
然而任何一个凸函数,都可以由线性分段函数进行逼近近似。其实我们可以把以前所学到的激活函数:ReLU、abs激活函数,看成是分成两段的线性函数,如下示意图所示:
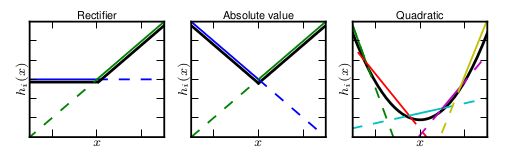
实验结果表明Maxout与Dropout组合使用可以发挥比较好的效果。
那么,前边的两种ReLU便是两种Maxout,函数图像为两条直线的拼接,\(f(x)=\max(w_1^Tx+b_1,w_2^Tx+b_2)\).
sigmoid & tanh
sigmoid/logistic 激活函数:
\[ \sigma(x) ={1\over 1+e^{-x}} \]
tanh 函数是sigmoid函数的一种变体,以0点为中心。取值范围为 [-1,1] ,而不是sigmoid函数的 [0,1] 。
\[ \tanh(x) ={e^x-e^{-x}\over e^x+e^{-x}} \]
tanh 是对 sigmoid 的平移和收缩: \(\tanh \left( x \right) = 2 \cdot \sigma \left( 2 x \right) - 1\).
你可能会想平移使得曲线以0点为中心,那么为什么还要收缩呢? 如果不拉伸或收缩得到 \(f(x)={e^x-1\over e^x+1}\) 不行吗? 我猜想是因为 tanh 更加著名吧。
那么 tanh 这个双曲正切函数与三角函数 tan 之间是什么关系呢?
在数学中,双曲函数是一类与常见的三角函数(也叫圆函数)类似的函数。最基本的双曲函数是双曲正弦函数 sinh 和双曲余弦函数 cosh ,从它们可以导出双曲正切函数 tanh 等,其推导也类似于三角函数的推导。2
根据欧拉公式: \(e^{ix} = \cos x + i\cdot\sin x\) (其中i是虚数\(\sqrt{-1}\)) 有3,
\[ e^{-ix} = \cos x - i\cdot\sin x \\ \sin x=(e^{ix} - e^{-ix})/(2i) \\ \cos x=(e^{ix} + e^{-ix})/2 \\ \tan\ x=\tanh(ix)/i \\ \tanh(ix)=i\tan\ x \]
hard tanh 限界: g(z) = max(-1, min(1,z))
sigmoid & tanh 函数图像如下:

sigmoid作激活函数的优缺点
历史上很流行(Historically popular since they have nice interpretation as a saturating “firing rate” of a neuron),梯度计算较为方便:
\[ \nabla\sigma = {e^{-x}\over(1+e^{-x})^2}=({1+e^{-x}-1\over 1+e^{-x}})({1\over 1+e^{-x}})= \sigma(x)(1-\sigma(x)) \]
优势是能够控制数值的幅度,在深层网络中可以保持数据幅度不会出现大的变化;而ReLU不会对数据的幅度做约束.
存在三个问题:
- 饱和的神经元会"杀死"梯度,指离中心点较远的x处的导数接近于0,停止反向传播的学习过程.
- sigmoid的输出不是以0为中心,而是0.5,这样在求权重w的梯度时,梯度总是正或负的.
- 指数计算耗时
为什么tanh相比sigmoid收敛更快:
- 梯度消失问题程度
\(\tanh'( x ) = 1-\tanh( x )^2 \in (0,1)\)
\(\text{sigmoid: } s'(x)=s(x)\times(1-s(x))\in(0,1/4)\)
可以看出tanh(x)的梯度消失问题比sigmoid要轻.梯度如果过早消失,收敛速度较慢. - 以零为中心的影响
如果当前参数(w0,w1)的最佳优化方向是(+d0, -d1),则根据反向传播计算公式,我们希望 x0 和 x1 符号相反。但是如果上一级神经元采用 Sigmoid 函数作为激活函数,sigmoid不以0为中心,输出值恒为正,那么我们无法进行最快的参数更新,而是走 Z 字形逼近最优解。4
激活函数的作用
- 加入非线性因素
- 充分组合特征
下面说明一下为什么有组合特征的作用.
一般函数都可以通过泰勒展开式来近似计算, 如sigmoid激活函数中的指数项可以通过如下的泰勒展开来近似计算:
\[ e^z=1+{1\over 1!}z+{1\over 2!}z^2+{1\over 3!}z^3+o(z^3) \]
其中有平方项,立方项及更更高项, 而 \(z=wx+b\), 因此可以看作是输入特征 x 的组合. 以前需要由领域专家知识进行特征组合,现在激活函数能起到一种类似特征组合的作用. (思想来源: 微博@算法组)
为什么ReLU,Maxout等能够提供网络的非线性建模能力?它们看起来是分段线性函数,然而并不满足完整的线性要求:加法f(x+y)=f(x)+f(y)和乘法f(ax)=a×f(x)或者写作\(f(\alpha x_1+\beta x_2)=\alpha f(x_1)+\beta f(x_2)\)。非线性意味着得到的输出不可能由输入的线性组合重新得到(重现)。假如网络中不使用非线性激活函数,那么这个网络可以被一个单层感知器代替得到相同的输出,因为线性层加起来后还是线性的,可以被另一个线性函数替代。
梯度消失与梯度爆炸
梯度消失/爆炸原因及解决办法
原因,浅层的梯度计算需要后面各层的权重及激活函数导数的乘积,因此可能出现前层比后层的学习率小(vanishing gradient)或大(exploding)的问题,所以具有不稳定性.那么如何解决呢?
需要考虑几个方面:
- 权重初始化
使用合适的方式初始化权重, 如ReLU使用MSRA的初始化方式, tanh使用xavier初始化方式. - 激活函数选择
激活函数要选择ReLU等梯度累乘稳定的. - 学习率
一种训练优化方式是对输入做白化操作(包括正规化和去相关), 目的是可以选择更大的学习率. 现代深度学习网络中常使用Batch Normalization(包括正规化步骤,但不含去相关). (All you need is a good init. If you can't find the good init, use Batch Normalization.)
由于梯度的公式包含每层激励的导数以及权重的乘积,因此让中间层的乘积约等于1即可.但是sigmoid这种函数的导数值又与权重有关系(最大值1/4,两边对称下降),所以含有sigmoid的神经网络不容易解决,输出层的activation大部分饱和,因此不建议使用sigmoid.
ReLU在自变量大于0时导数为1,小于0时导数为0,因此可以解决上述问题.
梯度爆炸
由于sigmoid,ReLU等函数的梯度都在[0,1]以内,所以不会引发梯度爆炸问题。 而梯度爆炸需要采用梯度裁剪、BN、设置较小学习率等方式解决。
激活函数选择
- 首先尝试ReLU,速度快,但要注意训练的状态.
- 如果ReLU效果欠佳,尝试Leaky ReLU或Maxout等变种。
- 尝试tanh正切函数(以零点为中心,零点处梯度为1)
- sigmoid/tanh在RNN(LSTM、注意力机制等)结构中有所应用,作为门控或者概率值.
- 在浅层神经网络中,如不超过4层的,可选择使用多种激励函数,没有太大的影响。
https://en.wikipedia.org/wiki/Rectifier_(neural_networks)↩
https://zh.wikipedia.org/wiki/%E5%8F%8C%E6%9B%B2%E5%87%BD%E6%95%B0↩
http://mathforum.org/library/drmath/view/54179.html↩
谈谈激活函数以零为中心的问题 https://liam0205.me/2018/04/17/zero-centered-active-function/↩