正则表达式高级应用(java语言版)
1.边界
package 正则;
import java.util.ArrayList;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Exp001 {
public static void main(String[] args) {
// TODO Auto-generated method stub
String string= "the cat scattered his food all over the room";
String regex = "(cat)";
int num=0;
Pattern pattern = Pattern.compile(regex);
Matcher p = pattern.matcher(string);
ArrayList templist = new ArrayList();
while(p.find()) {
num++;
templist.add(p.group());
}
System.out.println(num);
}
}
结果:2
package 正则;
import java.util.ArrayList;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Exp001 {
public static void main(String[] args) {
// TODO Auto-generated method stub
String string= "the cat scattered his food all over the room";
String regex = "(\\bcat\\b)";
Pattern pattern = Pattern.compile(regex);
Matcher p = pattern.matcher(string);
ArrayList templist = new ArrayList();
while(p.find()) {
templist.add(p.group());
}
System.out.println(templist.size());
}
}
结果:1
对比上面两个结果,发现第一个也将scattered这个单词包含进去了。不符合我们需求,所以我们一般使用第二张方法(位置匹配)。
单向区间匹配:
package 正则;
import java.util.ArrayList;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Exp001 {
public static void main(String[] args) {
// TODO Auto-generated method stub
String string[]= {"caption","cap","cape","capsize","recap"};
String regex = "(\\bcap)";
Pattern pattern = Pattern.compile(regex);
for (String xString: string)
{
Matcher p = pattern.matcher(xString);
if(p.find()) {
System.out.println(xString);
}
}
}
}
结果:
caption
cap
cape
capsize
package 正则;
import java.util.ArrayList;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Exp001 {
public static void main(String[] args) {
// TODO Auto-generated method stub
String string[]= {"caption","cap","cape","capsize","recap"};
String regex = "(\\bcap)";
Pattern pattern = Pattern.compile(regex);
for (String xString: string)
{
Matcher p = pattern.matcher(xString);
if(p.find()) {
System.out.println(xString);
}
}
}
}
结果:
caption
cap
cape
capsize
下表列出了正则表达式中的边界匹配器
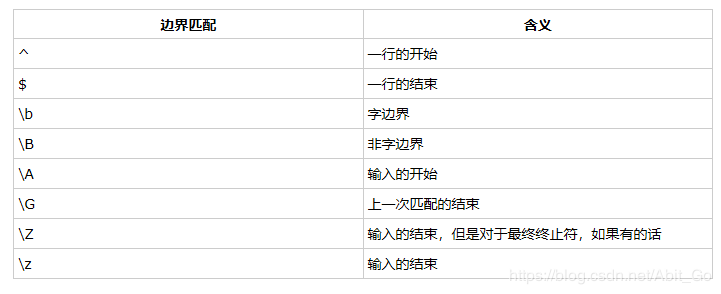
package 正则;
import java.util.ArrayList;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Exp001 {
public static void main(String[] args) {
// TODO Auto-generated method stub
String string[]= {"caption-s","cap - s","a- b","a -b"};
String regex = "(\\B-\\B)";
Pattern pattern = Pattern.compile(regex);
for (String xString: string)
{
Matcher p = pattern.matcher(xString);
if(p.find()) {
System.out.println(xString);
}
}
}
}
结果:
cap - s
知识点:表明不匹配一个单词边境(既字母数字下划线之间,或者非字母数字下划线之间),请使用\B。
2.字符串边界
package 正则;
import java.util.ArrayList;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Exp001 {
public static void main(String[] args) {
// TODO Auto-generated method stub
String string= ""
+ "wsdl:definitions targetNamespace=\"http://tips.cf\"";
String regex = "(<\\?xml.*\\?>)";
Pattern pattern = Pattern.compile(regex);
Matcher p = pattern.matcher(string);
if(p.find()) {
System.out.println(string);
}
}
}
结果:
wsdl:definitions targetNamespace="http://tips.cf"
package 正则;
import java.util.ArrayList;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Exp001 {
public static void main(String[] args) {
// TODO Auto-generated method stub
String string= "it is not a xml"
+ ""
+ "wsdl:definitions targetNamespace=\"http://tips.cf\"";
String regex = "(<\\?xml.*\\?>)";
Pattern pattern = Pattern.compile(regex);
Matcher p = pattern.matcher(string);
if(p.find()) {
System.out.println(string);
}
}
}
结果:
wsdl:definitions targetNamespace="http://tips.cf"
在下面的例子里,虽然匹配到xml的开头部分,但位置完全不对,她匹配到的是第二行而不是第一行
package 正则;
import java.util.ArrayList;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Exp001 {
public static void main(String[] args) {
// TODO Auto-generated method stub
String string= "it is not a xml"
+ ""
+ "wsdl:definitions targetNamespace=\"http://tips.cf\"";
String regex = "(^\\s*<\\?xml.*\\?>)";
Pattern pattern = Pattern.compile(regex);
Matcher p = pattern.matcher(string);
if( ! p.find()) {
System.out.println("这不是xml文件");
}
}
}
结果:
这不是xml文件
知识点:(^\\s*<\\?xml.*\\?>)分析:^\s*将匹配一个字符串的开头和随后的零个或多个空吧字符(这解决了标签前允许有空格、制表符、换行符等空白字符的问题)。作为一个整体,此正则表达式还能对合法的空白字符做出妥善处理。
package 正则;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Exp001 {
public static void main(String[] args) {
// TODO Auto-generated method stub
String string= "it is a html file