开箱即用——Alluxio-Presto沙盒使用指南
Alluxio-Presto沙盒是一个已经安装配置好了MySQL、Hadoop、Hive、Presto和Alluxio的docker应用。该沙盒可以让你轻松地进入交互环境,你可以在里面探索Alluxio、使用Presto进行查询,并体验在大数据软件栈中使用Alluxio带来的性能优势。
在本指南中,我们将使用Presto和Alluxio来展示Alluxio如何通过在本地缓存数据以便以内存速度访问数据,从而来提升Presto的查询性能。
本指南的目标是通过Alluxio读取Presto的TPC-DS来运行ss-max查询,Presto的数据存储在Amazon S3桶中。
此查询读取整张表来寻找表的行数和store_sales表每一列的最大值。
基本流程
-
准备工作
-
下载和启动容器
-
探索Alluxio
-
在Alluxio上使用Presto运行查询
准备工作
- 在你的机器(MacOS或Linux)上安装容器
- 本地机器中运行容器的可用内存最小值为6 GB,推荐8 GB
- 端口8080和19999应该被开放并可用
→如果你已有一个本地运行的Alluxio实例,请使用alluxio-stop.sh停止它
Mac上容器的准备工作
如果你在MacOS上运行容器,你需要增加默认的容器虚拟机设置。
- 进入Docker> Preferences > Advanced > Memory,将滑块增加到最小值为6 GB。推荐增加到6.5 GB-8 GB之间
- 推荐给虚拟机配置4个以上的CPU

点击对话框下方的Apply & Restart。
下载和启动容器
如果要开始使用容器,请将其从容器中心中拉下来。
容器镜像大约有1.8GB大小。下载时间取决于你的网络速度。你可以利用这段时间吃点零食:)
$ docker pull alluxio/alluxio-presto-sandbox
下载完成后,用以下命令启动容器:
$ docker run -d \
--shm-size 1G \
-p 19999:19999 \
-p 8080:8080 \
--name alluxio-presto-sandbox \
alluxio/alluxio-presto-sandbox
这个命令会启动容器和其中的所有服务。它们包括MySQL、Hadoop、Hive、Presto和Alluxio。
- -p 19999:19999允许我们访问来自主机的Alluxio的web UI
- -p 8080:8080允许我们访问来自主机的Presto的web UI
打开容器中的命令行。使用以下命令:
$ docker exec -it alluxio-presto-sandbox bash
[root@abcdef12345 ~]#
abcdef12345是你的容器ID的11个主要字符。
对于本指南的其余部分,假定所有的终端命令都应该在容器中运行。终端提示符应该以类似[root@abcdef12345 ~]#的内容开始。
- 服务架构
使用此容器的目的是通过Alluxio读取存储在S3桶中的数据,具体信息举例如下:
-
存储在Amazon S3桶中一个公共数据集,比如s3://bucket-name/path
-
这个公共桶被挂载到Alluxio文件系统中,路径是alluxio:///path/to/mount
-通过语句“CREATE TABLE table_name … LOCATION ‘alluxio:///path/to/mount/table_name’;”将挂载点引用到Hive表定义中
- Presto使用hive metastore中的表来运行“SELECT * FROM table_name”查询
- 关于容器的配置
Alluxio-Presto沙盒附带预装的软件可以在容器中的/opt目录中找到。Alluxio被安装在/opt/alluxio,配置参数位于/opt/Alluxio/conf目录中。
其余服务的配置文件可以在/opt/hadoop、/opt/hive和/opt/presto中的各自目录中找到。请参阅程序的具体文档,来了解每个程序是如何配置的。
容器内的服务都由一个名为supervisord的守护进程管理。这个守护进程负责启动、停止和重启每个服务。
使用supervisorctl命令控制每个进程的状态。
- Supervisorctl status命令会显示每个服务的状态
- Supervisorctl stop
命令会停止某个服务 - Supervisorctl start
命令会启动某个服务 - Supervisorctl restart
命令会重启某个服务 - Supervisorctl help命令会列出所有可用的命令
每个进程的日志可以在/var/log/supervisor目录下找到。
探索Alluxio
我们将结合使用Alluxio的Web UI(http://localhost:19999)和Alluxio命令行来探索Alluxio文件系统和集群状态。
容器附带一个Amazon S3桶,它预先挂载到Alluxio的/scale1目录下。它包含用于TPC-DS基准测试的“scale1”大小因子的数据,大约有跨多个表的1GB数据。
打开Alluxio web UI(http://localhost:19999),检查Alluxio master是否已经成功启动。如果没有,等待几分钟,刷新页面,然后就可以看到了。
通过在容器中运行alluxio fs mount命令,可以看到当前alluxio的挂载情况。
$ alluxio fs mount
s3://alluxio-public-http-ufs/tpcds/scale1-parquet on /scale1 (s3, capacity=-1B, used=-1B, read-only, not shared, properties={aws.secretKey=******, aws.accessKeyId=******})
/opt/alluxio/underFSStorage on / (local, capacity=58.42GB, used=-1B(0%), not read-only, not shared, properties={})
接下来,我们将进一步研究如何与Alluxio交互并将数据加载到缓存中。
现在让我们看看挂载的/scale1目录中有什么:
$ alluxio fs ls /scale1
drwx------ 3 PERSISTED 07-05-2019 19:41:42:054 DIR /scale1/call_center
drwx------ 3 PERSISTED 07-05-2019 19:41:42:100 DIR /scale1/catalog_page
drwx------ 2067 PERSISTED 07-05-2019 19:41:52:535 DIR /scale1/catalog_returns
drwx------ 1832 PERSISTED 07-05-2019 19:41:59:149 DIR /scale1/catalog_sales
drwx------ 3 PERSISTED 07-05-2019 19:41:59:152 DIR /scale1/customer
drwx------ 3 PERSISTED 07-05-2019 19:41:59:156 DIR /scale1/customer_address
drwx------ 3 PERSISTED 07-05-2019 19:41:59:161 DIR /scale1/customer_demographics
drwx------ 3 PERSISTED 07-05-2019 19:41:59:165 DIR /scale1/date_dim
drwx------ 3 PERSISTED 07-05-2019 19:41:59:169 DIR /scale1/household_demographics
drwx------ 3 PERSISTED 07-05-2019 19:41:59:173 DIR /scale1/income_band
drwx------ 262 PERSISTED 07-05-2019 19:42:00:104 DIR /scale1/inventory
...
/scale1目录包含更多的目录,这些目录是以TPC-DS基准测试中常用的表命名的。
通过使用web UI(http://localhost:19999)或运行alluxio fsadmin report命令查看集群使用情况概要。
 注意Workers Capacity和Workers Free/Used字段。这些字段描述了Alluxio工作节点的缓存存储状态。
注意Workers Capacity和Workers Free/Used字段。这些字段描述了Alluxio工作节点的缓存存储状态。
使用alluxio fs load命令将数据从其中一张表加载到内存中,然后运行alluxio fsadmin report命令,WebUI中的空闲和使用容量将会发生变化。
$ alluxio fs load /scale1/customer_demographics
/scale1/customer_demographics/part-00000-68449736-ad44-43d2-841f-4d55afd9e0b3-c000.snappy.parquet loaded
/scale1/customer_demographics/part-00000-267c2412-d427-4907-a398-e6de535ff1d4-c000.snappy.parquet loaded
/scale1/customer_demographics/_SUCCESS already in Alluxio fully
/scale1/customer_demographics loaded
这个命令将下载远程数据。根据网络带宽不同,它可能需要几秒钟或更长的时间来完成,所以你可以利用这段时间吃一些你之前抓的零食J
刷新Alluxio WebUI。Workers Free/Used行将被更新,这反映了Alluxio工作节点中新缓存的数据。
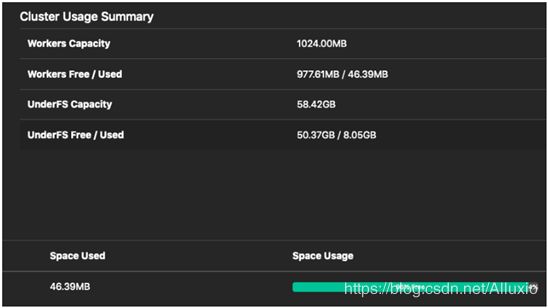
你现在可以看到,Free Capacity字段从以前的值减少到1024MB,而且MEM层的使用容量增加到了7.4MB。
基于Alluxio运行Presto查询
在接下来的章节中,我们将使用Presto和Alluxio来展示Alluxio如何通过读取缓存的数据来大大减少查询时间。
本指南侧重于通过命令行使用Presto;但是,你还可以使用Presto UI(http://localhost:8080)来查看查询状态。
- 通过Alluxio运行一个Presto查询
在容器中启动Presto命令行:
$ presto --catalog hive --debug
presto>
提示:你可以随时退出,只需输入exit即可。
容器在Presto中预装了表。它已经定义了一个名为alluxio的表模式。数据库包含了来自TPC-DS基准测试的表。
presto> show schemas;
Schema
--------------------
alluxio
default
information_schema
(3 rows)
使用alluxio模式:
presto> use alluxio;
USE
presto:alluxio>
当你看到提示符presto:alluxio>,你就可以使用该模式了。表定义可以在/usr/share/tpcdsData/createAlluxioTpcdsTables.sql中找到。
我们将从TPC-DS基准运行ss-max查询,可以在容器中的/usr/share/tpcdsData/ss_max.sql中找到该查询。
这个查询针对store_sales表运行,该表表示零售店在特定时间点的小时信息快照。该表中的列非常类似于商店可能从其销售点系统收集的内容。
查询对store_sales表执行以下操作:
- 使用count(*)获取表中的总行数
- 使用count(ss_sold_date_sk)获取表中非交易日期的总行数
- 使用count(distinct ss_sold_date_sk)获取唯一的销售总数
- 使用表中每一列的最大值。这包括交易日期、交易时间、项目、客户、地址等字段。
总之,它提供了表信息的简短概要。
该查询运行可能需要一些时间,你可以利用这段时间来吃更多的零食:)
select
count(*) as total,
count(ss_sold_date_sk) as not_null_total,
count(distinct ss_sold_date_sk) as unique_days,
max(ss_sold_date_sk) as max_ss_sold_date_sk,
max(ss_sold_time_sk) as max_ss_sold_time_sk,
max(ss_item_sk) as max_ss_item_sk,
max(ss_customer_sk) as max_ss_customer_sk,
max(ss_cdemo_sk) as max_ss_cdemo_sk,
max(ss_hdemo_sk) as max_ss_hdemo_sk,
max(ss_addr_sk) as max_ss_addr_sk,
max(ss_store_sk) as max_ss_store_sk,
max(ss_promo_sk) as max_ss_promo_sk
from store_sales
;
当查询完成时,你可以敲入q离开查询结果概要。输出应该和你的终端输出类似。
total | not_null_total | unique_days | max_ss_sold_date_sk | max_ss_sold_time_sk | max_ss_item_sk | max_ss_customer_sk | max_ss_cdemo_sk | max
---------+----------------+-------------+---------------------+---------------------+----------------+--------------------+-----------------+----
2879789 | 2750838 | 1823 | 2452642 | 75599 | 18000 | 100000 | 1920793 |
(1 row)
Query 20190710_051550_00010_7pbtm, FINISHED, 1 node
http://localhost:8080/ui/query.html?20190710_051550_00010_7pbtm
Splits: 58 total, 58 done (100.00%)
CPU Time: 2.8s total, 1.03M rows/s, 6.12MB/s, 17% active
Per Node: 0.2 parallelism, 210K rows/s, 1.25MB/s
Parallelism: 0.2
Peak Memory: 5.71MB
0:14 [2.88M rows, 17.2MB] [210K rows/s, 1.25MB/s]
注意:这里,在输出的最后一行中,0:14是以mm:ss格式表示查询总耗时。
因为这是我们第一次读取数据,所以它是先从S3中提取,然后再通过Alluxio返回。在这个过程中,Alluxio的工作节点将在内存中缓存数据,以便下次访问数据时可以以内存速度读取这些数据。
如果你重新刷新Web UI,你应该会看到Alluxio工作节点的存储使用量增加了。

因为第一查询必须通过Alluxio读取store_sales表中的所有数据,所以现在数据被缓存到本地存储。再次运行ss-max查询应该会很快。
让我们再次运行查询。祝你在查询结束前吃完零食!
select
count(*) as total,
count(ss_sold_date_sk) as not_null_total,
count(distinct ss_sold_date_sk) as unique_days,
max(ss_sold_date_sk) as max_ss_sold_date_sk,
max(ss_sold_time_sk) as max_ss_sold_time_sk,
max(ss_item_sk) as max_ss_item_sk,
max(ss_customer_sk) as max_ss_customer_sk,
max(ss_cdemo_sk) as max_ss_cdemo_sk,
max(ss_hdemo_sk) as max_ss_hdemo_sk,
max(ss_addr_sk) as max_ss_addr_sk,
max(ss_store_sk) as max_ss_store_sk,
max(ss_promo_sk) as max_ss_promo_sk
from store_sales
;
...
Query 20190710_051959_00011_7pbtm, FINISHED, 1 node
http://localhost:8080/ui/query.html?20190710_051959_00011_7pbtm
Splits: 58 total, 58 done (100.00%)
CPU Time: 2.9s total, 998K rows/s, 5.95MB/s, 52% active
Per Node: 0.6 parallelism, 597K rows/s, 3.56MB/s
Parallelism: 0.6
Peak Memory: 5.71MB
?:?? [2.88M rows, 17.2MB] [597K rows/s, 3.56MB/s]
提示:用exit退出Presto命令行。
注意查询的执行时间。你看到性能的变化了吗?
如果你想完成重新体验相同的实验,则需要从Alluxio内存中释放数据。退出Presto命令行后,运行alluxio free命令释放数据。
$ alluxio fs free/scale1
你可以通过在提示符处输入exit退出容器终端。然后,通过运行docker rm –f Alluxio-presto-sandbox命令关闭和删除容器。
后续
你可以在这里运行来自TPC-DS基准测试的其他查询。
- 访问Alluxio社区网站
- 阅读文档,了解Alluxio为云平台提供快速和无缝数据编排的其他方式!
- 在我们的社区slack频道上寻求帮助
- 将任何反馈发送到[email protected]