ARTS打卡13-少即是多
Algorithm做算法题,Review点评英文文章,Tip总结技术技巧,Share做技术分享。每周打卡一次,这就是ARTS打卡。
1. 做算法题
以前做Leetcode算法题都比较简单,一般是挑选70%通过率的题目取做,很少去题解和别人的思路。这样对算法的掌握不是很到位,提高不明显。看到一名华科CS硕士的博客,他坚持了几年把Leetcode前300题做完,并每题都写了详细的题解。很佩服。
以后我会按照Leetcode题目顺序做题,遇到不懂的不跳过,并用大O分析法分析算法的时间、空间复杂度。这周从第一题开始,Leetcode第一题,两数之和。
题目描述:
给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标。你可以假设每种输入只会对应一个答案。但是,数组中同一个元素不能使用两遍。
示例:
给定 nums = [2, 7, 11, 15], target = 9,因为 nums[0] + nums[1] = 2 + 7 = 9
所以返回 [0, 1]
解题思路1:最笨的方法是两重循环查找遍历所有数字,并相加,与目标值比较。时间复杂度是O(n^2),没增加额外空间开销,空间复杂度O(1)。代码实现上可以简化一下,第二重循环不需要遍历所有其他元素,直接遍历第一层循环位置以后的值。
解题代码1:
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
for i, num in enumerate(nums):
if target - num in nums[i+1:]://第二重循环用in代替,直接比较残差是否在列表中
return [i, nums.index(target - num,i+1)]
解题思路2:再看看解法1的第二重循环,用了in代替for循环遍历,本质上还是在遍历。列表的查找要循环,而字典的查找不用,直接依据键来查找。更具这个思路把nums列表转换为字典,查找起来将第二重循环的时间复杂度O(n)降低为O(1),整体时间复杂度降低为O(n),但这个过程中创建了字典,把复杂度从O(1)增长为O(n)。牺牲空间换时间。
解题代码2:
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
map_dict = dict()
for i, num in enumerate(nums):
if target - num in map_dict:
return [i, map_dict[target - num]]
map_dict[nums[i]] = i
2. 点评英文文章
文章Machine Learning is Fun!用通俗的案例介绍了什么是机器学习。作者给出机器学习的定义是:
Machine learning is the idea that there are generic algorithms that can tell you something interesting about a set of data without you having to write any custom code specific to the problem. Instead of writing code, you feed data to the generic algorithm and it builds its own logic based on the data.
机器学习是一些能揭示数据有趣信息的通用算法,而且不需要你特意去编写代码。不用写代码,你给通用算法喂数据就够了,算法会自己形成逻辑。
这是我看过对机器学习最贴切的解释,我常误以为机器学习是要编写大量代码。其实大量的编码反而远离了机器学习的本质。
3. 技术技巧
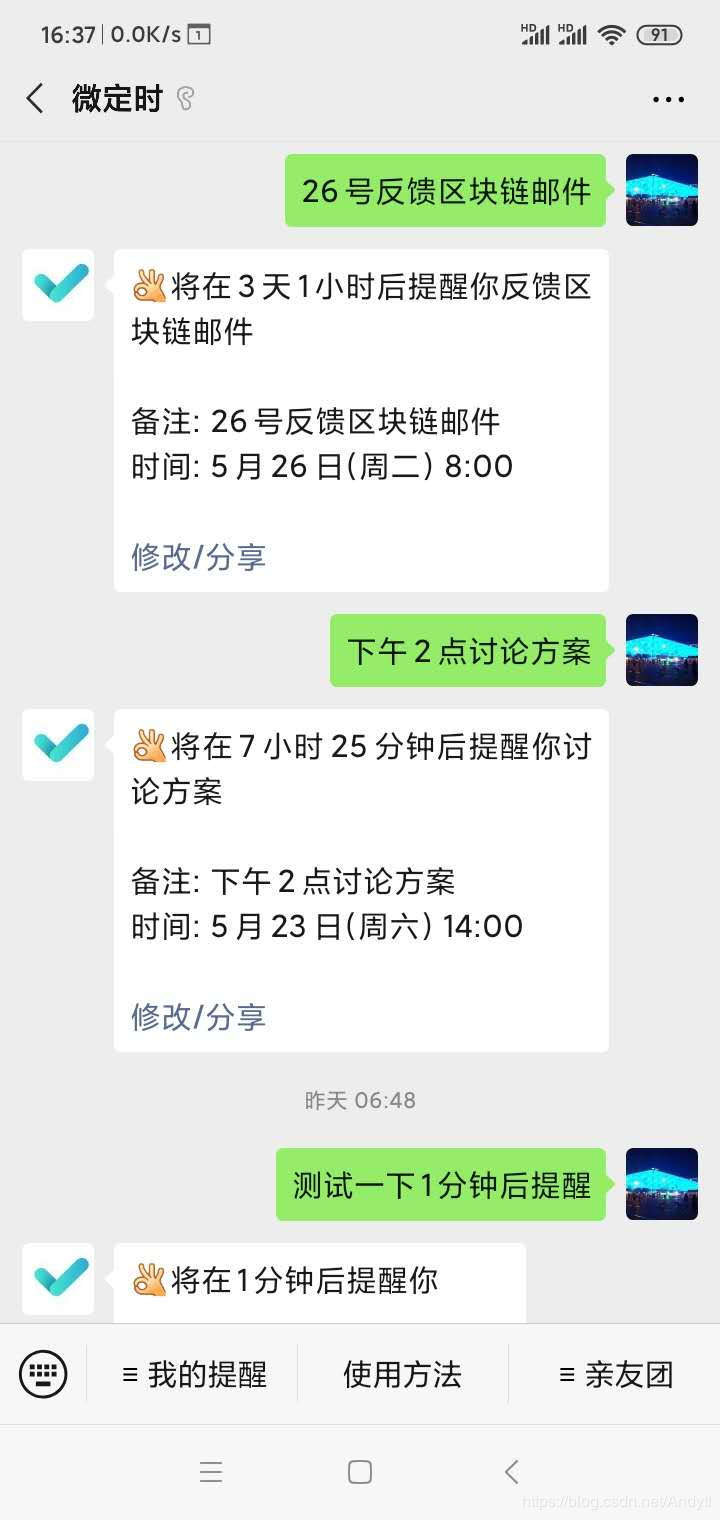
听了极客时间小程序开发的直播,提到小程序依托微信生态天生离用户很近,非常适合试验新想法,迅速通过流量、服务、广告变现。除了小程序,还有一些公众号直接把微信当作简单输入输出界面,后台跑着复杂应用。例如,微定时公众号,把微信当作一个定时工具,对着公众号发一条文字或语音即可定时提醒。
4. 技术分享
Linux中安装软件和Windows有很大的不同,这是个好消息也是个坏消息。好消息Windows中的病毒对Linux无效,坏消息是Linux安装软件更加复杂。Linux中一个软件的安装,一般会伴随一系列依赖包的安装。还好yum工具能自动分析下载依赖包,解决了依赖的问题。但是yum卸载软件时也会卸载相关依赖,如果其他软件正好也要使用这些依赖,就会导致软件崩溃。所以在Linux下卸载程序时要慎重。