springboot2.x +kafka使用和源码分析一(自动装配)
序言:
个人感觉springboot的源码是web应用开源框架中写的最好的,观看它的源码可以学习它的编码风格,代码设计思想,如何做到给予使用者最好的使用体验,隐藏连接各应用组件的实现细节,极大降低类开发者实力的要求。查看springboot对各组件的自动装配实现,可以很详细的了解到spring对于组件核心类的初始化过程,以及核心类的作用以及之间的依赖关系。
springboot提供的所有的自动装配类都在spring-boot(直接查看源码)

也可以通过官网来进行查看(选取要看的版本):
https://docs.spring.io/spring-boot/docs/2.2.3.BUILD-SNAPSHOT/reference/html/appendix-auto-configuration-classes.html#auto-configuration-classes-from-autoconfigure-module
在使用springboot项目中集成kafka组件是一件非常简易方便的事情,只需要在引入spring-kafka jar包,添加配置文件基本属性,就可以在项目工程中使用kafka带给我们的功能了。这里我们探究springboot如何初始化kafka 中各基础bean对象。
首先查看项目的依赖jar列表(我这里使用是maven管理jar),会发现存在以下jar包。该jar包中包含的是springboot和各大组件(redis,mq,jdbc等)的自动配置类。
springboot对于kafka的支持在如下图所示: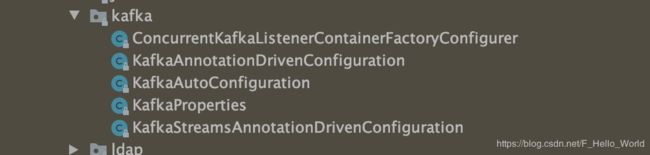
KafkaProperties:
设置各基本配置属性,包含公共的配置(bootstrapServers :kafka服务器地址,clientId),Consumer;producer;admin;streams等配置。
//读取以spring.kafka开头配置
@ConfigurationProperties(prefix = "spring.kafka")
public class KafkaProperties {
//设置kafka brokers地址信息
private List bootstrapServers = new ArrayList<>(Collections.singletonList("localhost:9092"));
/**
* ID to pass to the server when making requests. Used for server-side logging.
*/
private String clientId;
/**
* Additional properties, common to producers and consumers, used to configure the
* client.
*/
//一些公共基础信息
private final Map properties = new HashMap<>();
//映射配置文件中spring.kafka.consumer开头属性
private final Consumer consumer = new Consumer();
//映射配置文件中spring.kafka.producer开头属性
private final Producer producer = new Producer();
//映射配置文件中spring.kafka.admin开头属性
private final Admin admin = new Admin();
//映射配置文件中spring.kafka.admin开头属性
private final Streams streams = new Streams();
//映射配置文件中spring.kafka.listener开头属性
private final Listener listener = new Listener();
//映射配置文件中spring.kafka.ssl开头属性
private final Ssl ssl = new Ssl();
//映射配置文件中spring.kafka.jaas开头属性
private final Jaas jaas = new Jaas();
//映射配置文件中spring.kafka.template开头属性
private final Template template = new Template();
......
}
具体详细配置详细可以参照springboot官网
KafkaAutoConfiguration:用于配置初始化kafka依赖bean
@Configuration(proxyBeanMethods = false)
//上下文中必须包含KafkaTemplate类才执行自动装配
@ConditionalOnClass(KafkaTemplate.class)
//将配置文件中哥属性映射到KafkaProperties对象中
@EnableConfigurationProperties(KafkaProperties.class)
//启动KafkaAnnotationDrivenConfiguration,KafkaStreamsAnnotationDrivenConfiguration配置类
@Import({ KafkaAnnotationDrivenConfiguration.class, KafkaStreamsAnnotationDrivenConfiguration.class })
public class KafkaAutoConfiguration {
private final KafkaProperties properties;
public KafkaAutoConfiguration(KafkaProperties properties) {
this.properties = properties;
}
@Bean
//spring上下文中不包含KafkaTemplate类的实例对象时初始化
@ConditionalOnMissingBean(KafkaTemplate.class)
public KafkaTemplate kafkaTemplate(ProducerFactory kafkaProducerFactory,
ProducerListener kafkaProducerListener,
ObjectProvider messageConverter) {
//设置kafka默认模版类 key,value为Object
KafkaTemplate kafkaTemplate = new KafkaTemplate<>(kafkaProducerFactory);
messageConverter.ifUnique(kafkaTemplate::setMessageConverter);
kafkaTemplate.setProducerListener(kafkaProducerListener);
kafkaTemplate.setDefaultTopic(this.properties.getTemplate().getDefaultTopic());
return kafkaTemplate;
}
@Bean
//spring上下文中不包含ProducerListener类的实例对象时初始化
@ConditionalOnMissingBean(ProducerListener.class)
public ProducerListener kafkaProducerListener() {
//设置默认生产者监听器对象
return new LoggingProducerListener<>();
}
@Bean
//spring上下文中不包含ConsumerFactory类的实例对象时初始化
@ConditionalOnMissingBean(ConsumerFactory.class)
public ConsumerFactory kafkaConsumerFactory() {
//构建默认kafka消费者工厂类,用于后续创建kafak消费者实例类
return new DefaultKafkaConsumerFactory<>(this.properties.buildConsumerProperties());
}
@Bean
//spring上下文中不包含ProducerFactory类的实例对象时初始化
@ConditionalOnMissingBean(ProducerFactory.class)
public ProducerFactory kafkaProducerFactory() {
//构建ProducerFactory 用于创建Producer
DefaultKafkaProducerFactory factory = new DefaultKafkaProducerFactory<>(
this.properties.buildProducerProperties());
//消费者是否开启设置事务管理
String transactionIdPrefix = this.properties.getProducer().getTransactionIdPrefix();
if (transactionIdPrefix != null) {
factory.setTransactionIdPrefix(transactionIdPrefix);
}
return factory;
}
@Bean
//根据是否包含spring.kafka.producer.transaction-id-prefix 是否添加kafka事务管理器对象
@ConditionalOnProperty(name = "spring.kafka.producer.transaction-id-prefix")
@ConditionalOnMissingBean
public KafkaTransactionManager kafkaTransactionManager(ProducerFactory producerFactory) {
//构建默认事务管理器对象
return new KafkaTransactionManager<>(producerFactory);
}
@Bean
//是否开启kafka jaas功能默认为false
@ConditionalOnProperty(name = "spring.kafka.jaas.enabled")
@ConditionalOnMissingBean
public KafkaJaasLoginModuleInitializer kafkaJaasInitializer() throws IOException {
KafkaJaasLoginModuleInitializer jaas = new KafkaJaasLoginModuleInitializer();
Jaas jaasProperties = this.properties.getJaas();
if (jaasProperties.getControlFlag() != null) {
jaas.setControlFlag(jaasProperties.getControlFlag());
}
if (jaasProperties.getLoginModule() != null) {
jaas.setLoginModule(jaasProperties.getLoginModule());
}
jaas.setOptions(jaasProperties.getOptions());
return jaas;
}
@Bean
@ConditionalOnMissingBean
public KafkaAdmin kafkaAdmin() {
//初始化kafkaAdmin对象用于管理topic等元数据
KafkaAdmin kafkaAdmin = new KafkaAdmin(this.properties.buildAdminProperties());
//如果为ture 初始化期间无法连接到代理时无法加载应用程序上下文的情况下检查/添加主题。
kafkaAdmin.setFatalIfBrokerNotAvailable(this.properties.getAdmin().isFailFast());
return kafkaAdmin;
}
}
KafkaAnnotationDrivenConfiguration:用于初始化kafka处理消息的一系列组件
@Configuration(proxyBeanMethods = false)
//classpath引用类路径必须包含EnableKafka
@ConditionalOnClass(EnableKafka.class)
class KafkaAnnotationDrivenConfiguration {
private final KafkaProperties properties;
//记录消息转换器 将ConsumerRecord转换为Message,或者将Message转换为ProducerRecord
//对于MessageConverter的作用使用可参考我的其它博文
private final RecordMessageConverter messageConverter;
//定义消息转换器(处理批次消息)
private final BatchMessageConverter batchMessageConverter;
private final KafkaTemplate kafkaTemplate;
//定义事务管理器
private final KafkaAwareTransactionManager transactionManager;
//设置消费者负载均衡监听器 作用可参考我的其它博文
private final ConsumerAwareRebalanceListener rebalanceListener;
//异常设置全局异常处理器 作用可参考我的其它博文
private final ErrorHandler errorHandler;
//异常设置全局异常处理器(处理批次消息) 作用可参考我的其它博文
private final BatchErrorHandler batchErrorHandler;
private final AfterRollbackProcessor afterRollbackProcessor;
private final RecordInterceptor recordInterceptor;
KafkaAnnotationDrivenConfiguration(KafkaProperties properties,
ObjectProvider messageConverter,
ObjectProvider batchMessageConverter,
ObjectProvider> kafkaTemplate,
ObjectProvider> kafkaTransactionManager,
ObjectProvider rebalanceListener, ObjectProvider errorHandler,
ObjectProvider batchErrorHandler,
ObjectProvider> afterRollbackProcessor,
ObjectProvider> recordInterceptor) {
this.properties = properties;
this.messageConverter = messageConverter.getIfUnique();
this.batchMessageConverter = batchMessageConverter
.getIfUnique(() -> new BatchMessagingMessageConverter(this.messageConverter));
this.kafkaTemplate = kafkaTemplate.getIfUnique();
this.transactionManager = kafkaTransactionManager.getIfUnique();
this.rebalanceListener = rebalanceListener.getIfUnique();
this.errorHandler = errorHandler.getIfUnique();
this.batchErrorHandler = batchErrorHandler.getIfUnique();
this.afterRollbackProcessor = afterRollbackProcessor.getIfUnique();
this.recordInterceptor = recordInterceptor.getIfUnique();
}
@Bean
@ConditionalOnMissingBean
ConcurrentKafkaListenerContainerFactoryConfigurer kafkaListenerContainerFactoryConfigurer() {
//初始化ConcurrentKafkaListenerContainerFactoryConfigurer对象
ConcurrentKafkaListenerContainerFactoryConfigurer configurer = new ConcurrentKafkaListenerContainerFactoryConfigurer();
configurer.setKafkaProperties(this.properties);
MessageConverter messageConverterToUse = (this.properties.getListener().getType().equals(Type.BATCH))
? this.batchMessageConverter : this.messageConverter;
configurer.setMessageConverter(messageConverterToUse);
configurer.setReplyTemplate(this.kafkaTemplate);
configurer.setTransactionManager(this.transactionManager);
configurer.setRebalanceListener(this.rebalanceListener);
configurer.setErrorHandler(this.errorHandler);
configurer.setBatchErrorHandler(this.batchErrorHandler);
configurer.setAfterRollbackProcessor(this.afterRollbackProcessor);
configurer.setRecordInterceptor(this.recordInterceptor);
return configurer;
}
@Bean
@ConditionalOnMissingBean(name = "kafkaListenerContainerFactory")
ConcurrentKafkaListenerContainerFactory kafkaListenerContainerFactory(
//初始化消费者监听容器工厂类用于后续创建容器
ConcurrentKafkaListenerContainerFactoryConfigurer configurer,
ConsumerFactory kafkaConsumerFactory) {
ConcurrentKafkaListenerContainerFactory factory = new ConcurrentKafkaListenerContainerFactory<>();
configurer.configure(factory, kafkaConsumerFactory);
return factory;
}
@Configuration(proxyBeanMethods = false)
@EnableKafka
@ConditionalOnMissingBean(name = KafkaListenerConfigUtils.KAFKA_LISTENER_ANNOTATION_PROCESSOR_BEAN_NAME)
static class EnableKafkaConfiguration {
}
}
KafkaStreamsAnnotationDrivenConfiguration:对于kafka Stream功能基础bean初始化
@Configuration(proxyBeanMethods = false)
@ConditionalOnClass(StreamsBuilder.class)
@ConditionalOnBean(name = KafkaStreamsDefaultConfiguration.DEFAULT_STREAMS_BUILDER_BEAN_NAME)
class KafkaStreamsAnnotationDrivenConfiguration {
private final KafkaProperties properties;
KafkaStreamsAnnotationDrivenConfiguration(KafkaProperties properties) {
this.properties = properties;
}
@ConditionalOnMissingBean
@Bean(KafkaStreamsDefaultConfiguration.DEFAULT_STREAMS_CONFIG_BEAN_NAME)
KafkaStreamsConfiguration defaultKafkaStreamsConfig(Environment environment) {
Map streamsProperties = this.properties.buildStreamsProperties();
if (this.properties.getStreams().getApplicationId() == null) {
String applicationName = environment.getProperty("spring.application.name");
if (applicationName == null) {
throw new InvalidConfigurationPropertyValueException("spring.kafka.streams.application-id", null,
"This property is mandatory and fallback 'spring.application.name' is not set either.");
}
streamsProperties.put(StreamsConfig.APPLICATION_ID_CONFIG, applicationName);
}
return new KafkaStreamsConfiguration(streamsProperties);
}
@Bean
KafkaStreamsFactoryBeanConfigurer kafkaStreamsFactoryBeanConfigurer(
@Qualifier(KafkaStreamsDefaultConfiguration.DEFAULT_STREAMS_BUILDER_BEAN_NAME) StreamsBuilderFactoryBean factoryBean) {
return new KafkaStreamsFactoryBeanConfigurer(this.properties, factoryBean);
}
// Separate class required to avoid BeanCurrentlyInCreationException
static class KafkaStreamsFactoryBeanConfigurer implements InitializingBean {
private final KafkaProperties properties;
private final StreamsBuilderFactoryBean factoryBean;
KafkaStreamsFactoryBeanConfigurer(KafkaProperties properties, StreamsBuilderFactoryBean factoryBean) {
this.properties = properties;
this.factoryBean = factoryBean;
}
@Override
public void afterPropertiesSet() {
this.factoryBean.setAutoStartup(this.properties.getStreams().isAutoStartup());
}
}
} ConcurrentKafkaListenerContainerFactoryConfigurer:用于设置管理ConcurrentKafkaListenerContainerFactory(此类用于对ConcurrentKafkaListenerContainer容器管理) 通过KafkaAnnotationDrivenConfiguration初始化。