mybatis配置文件
一.全局配置文件配置
1.1 properties标签
Properties标签可以用来加载配置文件.例如,我们可以将数据库的连接信息放入到一个配置文件(db.properties中..)
下为db.properties
db.driverClass=com.mysql.jdbc.Driver
db.url=jdbc:mysql://localhost:3306/mybatis?useUnicode=true&characterEncoding=utf8
db.username=root
db.password=root在全局配置文件mybatis_Config.xml中引入该配置文件.
然后就可以在全局配置文件的关于数据库的配置信息里使用配置文件的信息了
也可以在properties标签下配置property的name和value,则可以替换.properties文件中相应属性值。
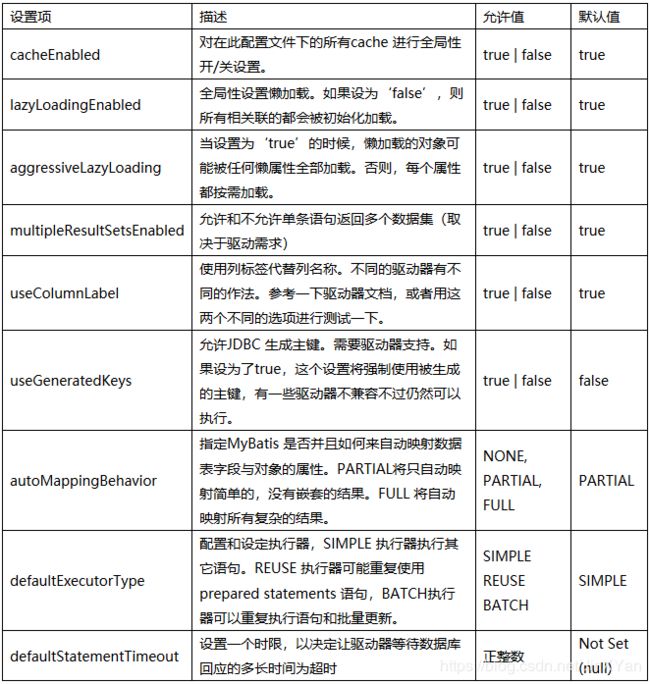
1.2 settings设置
这是MyBatis 修改操作运行过程细节的重要的步骤。下方这个表格描述了这些设置项、含义和默认值。
1.3 typeAliases类型别名
类型别名是Java 类型的简称。它仅仅只是关联到XML 配置,简写冗长的JAVA 类名。例如:

现在我们就可以使用别名了:

批量定义别名.(用于定义包)包下面的类的别名默认为类名.首字母大小写即可.

使用别名:

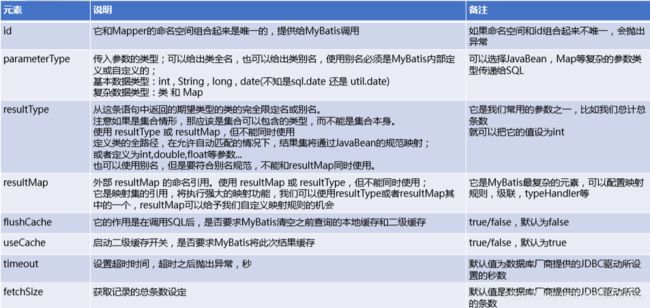
1.4 mapper标签
这里是告诉MyBatis 去哪寻找映射SQL 的语句。可以使用类路径中的资源引用,或者使用字符,输入确切的URL 引用。
1.4.1
- 如:
1.4.2
- 如:
1.4.3
- 如:
- 注意:此种方法要求mapper接口和mapper映射文件要名称相同,且放到同一个目录下;
1.4.4
- 如:
- 注意:此种方法要求mapper接口和mapper映射文件要名称相同,且放到同一个目录下;
1.5 typeHandlers类型句柄(一般不会修改)
无论是MyBatis在预处理语句中设置一个参数,还是从结果集中取出一个值时,类型处理器被用来将获取的值以合适的方式转换成Java类型。下面这个表格描述了默认的类型处理器。
1.6 environments环境
MyBatis 可以配置成适应多种环境,这种机制有助于将 SQL 映射应用于多种数据库之中, 现实情况下有多种理由需要这么做。例如,开发、测试和生产环境需要有不同的配置;或者想在具有相同 Schema 的多个生产数据库中 使用相同的 SQL 映射。有许多类似的使用场景。
不过要记住:尽管可以配置多个环境,但每个 SqlSessionFactory 实例只能选择一种环境。
所以,如果你想连接两个数据库,就需要创建两个 SqlSessionFactory 实例,每个数据库对应一个。而如果是三个数据库,就需要三个实例,依此类推,记起来很简单:每个数据库对应一个 SqlSessionFactory 实例
更多配置请参考官网:http://www.mybatis.org/mybatis-3/zh/configuration.html#environments
XML映射文件(重点)
MyBatis 的真正强大在于它的映射语句,这是它的魔力所在。由于它的异常强大,映射器的 XML 文件就显得相对简单。如果拿它跟具有相同功能的 JDBC 代码进行对比,你会立即发现省掉了将近 95% 的代码。MyBatis 为聚焦于 SQL 而构建,以尽可能地为你减少麻烦。
POJO接口名必须和映射文件名一致
SQL 映射文件只有很少的几个顶级元素(按照应被定义的顺序列出):
- cache – 对给定命名空间的缓存配置。
- cache-ref – 对其他命名空间缓存配置的引用。
- resultMap – 是最复杂也是最强大的元素,用来描述如何从数据库结果集中来加载对象。
- sql – 可被其他语句引用的可重用语句块。
- insert – 映射插入语句
- update – 映射更新语句
- delete – 映射删除语句
- select – 映射查询语句
1、select
查询语句是 MyBatis 中最常用的元素之一,光能把数据存到数据库中价值并不大,只有还能重新取出来才有用,多数应用也都是查询比修改要频繁。对每个插入、更新或删除操作,通常间隔多个查询操作。这是 MyBatis 的基本原则之一,也是将焦点和努力放在查询和结果映射的原因。简单查询的 select 元素是非常简单的。比如:
这个语句被称作 selectPerson,接受一个 int(或 Integer)类型的参数,并返回一个 HashMap 类型的对象,其中的键是列名,值便是结果行中的对应值。
注意参数符号:#{id}
这就告诉 MyBatis 创建一个预处理语句(PreparedStatement)参数,在 JDBC 中,这样的一个参数在 SQL 中会由一个“?”来标识,并被传递到一个新的预处理语句中,就像这样:
// 近似的 JDBC 代码,非 MyBatis 代码...
String selectPerson = "SELECT * FROM PERSON WHERE ID=?";
PreparedStatement ps = conn.prepareStatement(selectPerson);
ps.setInt(1,id);当然,使用 JDBC 意味着需要更多的代码来提取结果并将它们映射到对象实例中,而这就是 MyBatis 节省你时间的地方。参数和结果映射还有更深入的细节。这些细节会分别在后面单独的小节中呈现。
select 元素允许你配置很多属性来配置每条语句的作用细节。
resultType与resultMap
resultType(不建议使用,没有实现POJO与表的解耦和):
- SQL列名和JavaBean的属性是一致的;
- 自动映射等级autoMappingBehavior设置为PARTIAL,需要谨慎使用FULL;
- 如果列名和JavaBean不一致,但列名符合单词下划线分割,Java是驼峰命名法, 则mapUnderscoreToCamelCase可设置为true;
resultMap(推荐使用)
传入多个参数的问题
单参:
public List getXXBeanList(String xxCode);
其中方法名和id一致,#{}中的参数名与方法中的参数名一直,我这里采用的是XXXBean是采用的短名字,
select后的字段列表要和bean中的属性名一致,如果不一致的可以用as来补充。 多参情况:
方法1:顺序传参法
public User selectUser(String name, int deptId);
#{}里面的数字代表你传入参数的顺序。这种方法不建议使用,sql层表达不直观,且一旦顺序调整容易出错。
方法2:Map传参法
public User selectUser(Map params);
#{}里面的名称对应的是 Map里面的key名称。这种方法适合传递多个参数,且参数易变能灵活传递的情况。但可读性差,导致可维护性和可扩展性差,不建议使用。
方法3:@Param注解传参法
public User selectUser(@Param("userName") String name, int @Param("deptId") deptId);
#{}里面的名称对应的是注解 @Param括号里面修饰的名称。这种方法在参数不多的情况还是比较直观的,推荐使用。
方法4:Java Bean传参法
public User selectUser(Map params);
#{}里面的名称对应的是 User类里面的成员属性。这种方法很直观,但需要建一个实体类,扩展不容易,需要加属性,看情况使用。
2、resultMap
resultMap 元素是 MyBatis 中最重要最强大的元素。它可以让你从 90% 的 JDBC ResultSets 数据提取代码中解放出来,并在一些情形下允许你进行一些 JDBC 不支持的操作。实际上,在为一些比如连接的复杂语句编写映射代码的时候,一份 resultMap 能够代替实现同等功能的长达数千行的代码。ResultMap 的设计思想是,对于简单的语句根本不需要配置显式的结果映射,而对于复杂一点的语句只需要描述它们的关系就行了。
ResultMap 最优秀的地方在于,虽然你已经对它相当了解了,但是根本就不需要显式地用到他们。 上面这些简单的示例根本不需要下面这些繁琐的配置。 但出于示范的原因,让我们来看看最后一个示例中,如果使用外部的 resultMap 会怎样,这也是解决列名不匹配的另外一种方式。
而在引用它的语句中使用 resultMap 属性就行了(注意我们去掉了 resultType 属性)。比如:
resultMap属性:
| 属性 | 描述 |
|---|---|
| id | 当前命名空间中的一个唯一标识,用于标识一个结果映射。 |
| type | 类的完全限定名, 或者一个类型别名(关于内置的类型别名,可以参考上面的表格)。 |
| autoMapping | 如果设置这个属性,MyBatis将会为本结果映射开启或者关闭自动映射。 这个属性会覆盖全局的属性 autoMappingBehavior。默认值:未设置(unset)。 |
resultMap子元素

constructor:
当javaBean对象中没有构造方法时(某些情况下禁止含有),可使用该标签。
//对应的构造方法
public POJO(Integer id,String username){
...
}它将结果集映射到构造方法上,它根据参数的类型和顺序来确定构造方法。构造方法注入允许你在初始化时为类设置属性的值,而不用暴露出公有方法。
id & result
- id 和 result 都将一个列的值映射到一个简单数据类型(字符串,整型,双精度浮点数,日期等)的属性或字段 ;
- 两者之间的唯一不同是, id 表示的结果将是对象的标识属性,这会在比较对象实例时用到。 这样可以 提高整体的性能,尤其是缓存和嵌套结果映射(也就是联合映射)的时候。
-
属性 描述 property 映射到列结果的字段或属性。如果用来匹配的 JavaBean 存在给定名字的属性,那么它将会被使用。否则 MyBatis 将会寻找给定名称的字段。 无论是哪一种情形,你都可以使用通常的点式分隔形式进行复杂属性导航。 比如,你可以这样映射一些简单的东西:“username”,或者映射到一些复杂的东西上:“address.street.number”。 column 数据库中的列名,或者是列的别名。一般情况下,这和传递给 resultSet.getString(columnName) 方法的参数一样。 javaType 一个 Java 类的完全限定名,或一个类型别名(关于内置的类型别名,可以参考上面的表格)。 如果你映射到一个 JavaBean,MyBatis 通常可以推断类型。然而,如果你映射到的是 HashMap,那么你应该明确地指定 javaType 来保证行为与期望的相一致。 jdbcType JDBC 类型,所支持的 JDBC 类型参见这个表格之后的“支持的 JDBC 类型”。 只需要在可能执行插入、更新和删除的且允许空值的列上指定 JDBC 类型。这是 JDBC 的要求而非 MyBatis 的要求。如果你直接面向 JDBC 编程,你需要对可能存在空值的列指定这个类型。 typeHandler 我们在前面讨论过默认的类型处理器。使用这个属性,你可以覆盖默认的类型处理器。 这个属性值是一个类型处理器实现类的完全限定名,或者是类型别名。
3、insert, update 和 delete

| id | 命名空间中的唯一标识符,可被用来代表这条语句。与POJO接口方法名一致 |
| parameterType | 将要传入语句的参数的完全限定类名或别名。这个属性是可选的,因为 MyBatis 可以通过类型处理器推断出具体传入语句的参数,默认值为未设置(unset)。一般传一个JavaBean。 |
| useGeneratedKeys | 取值范围true|false(默认值),设置是否使用JDBC的getGenereatedKeys方法获取主键并赋值到keyProperty设置的领域模型属性中。MySQL和SQLServer执行auto-generated key field,因此当数据库设置好自增长主键后,可通过JDBC的getGeneratedKeys方法获取。但像Oralce等不支持auto-generated key field的数据库就不能用这种方法获取主键了 |
| keyProperty | 默认值unset,用于设置getGeneratedKeys方法或selectKey子元素返回值将赋值到领域模型的哪个属性中 |
实例:mapper接口代码:
/**
* 添加学生信息
* @param student 学生实例
* @return 成功操作的记录数目
*/
int add(EStudent student);对应获取主键:至于mapper.xml则分为两种情况了,一种是数据库(如MySQL,SQLServer)支持auto-generated key field,另一种是数据库(如Oracle)不支持auto-generated key field的。
1. 数据库(如MySQL,SQLServer)支持auto-generated key field的情况
手段①(推荐做法):
insert into TStudent(name, age) values(#{name}, #{age})
手段②:
// 下面是SQLServer获取最近一次插入记录的主键值的方式
select @@IDENTITY as id
insert into TStudent(name, age) values(#{name}, #{age})
由于手段②获取主键的方式依赖数据库本身,因此推荐使用手段①。
2. 数据库(如Oracle)不支持auto-generated key field的情况
select CAST(RANDOM * 100000 as INTEGER) a FROM SYSTEM.SYSDUMMY1
insert into TStudent(id, name, age) values(#{id}, #{name}, #{age})
注意:mapper接口返回值依然是成功插入的记录数,但不同的是主键值已经赋值到领域模型实体的id中了。
selectKey子元素
作用:在insert元素和update元素中插入查询语句。
其属性如下:
- keyProperty ,默认值unset,用于设置getGeneratedKeys方法或selectKey子元素返回值将赋值到领域模型的哪个属性中
- resultType ,keyPropety所指向的属性类全限定类名或类型别名
- order属性 ,取值范围BEFORE|AFTER,指定是在insert语句前还是后执行selectKey操作
- statementType ,取值范围STATEMENT,PREPARED(默认值),CALLABLE
注意:selectKey操作会将操作查询结果赋值到insert元素的parameterType的入参实例下对应的属性中。并提供给insert语句使用。
下面就是 insert,update 和 delete 语句的示例:
insert into Author (id,username,password,email,bio)
values (#{id},#{username},#{password},#{email},#{bio})
update Author set
username = #{username},
password = #{password},
email = #{email},
bio = #{bio}
where id = #{id}
delete from Author where id = #{id}
#{}和${}的区别
动态 sql 是 mybatis 的主要特性之一,在 mapper 中定义的参数传到 xml 中之后,在查询之前 mybatis 会对其进行动态解析。mybatis 为我们提供了两种支持动态 sql 的语法:#{} 以及 ${}。
在下面的语句中,如果 username 的值为 zhangsan,则两种方式无任何区别:
select * from user where name = #{name};select * from user where name = ${name};其解析之后的结果均为
select * from user where name = 'zhangsan';但是 #{} 和 ${} 在预编译中的处理是不一样的。#{} 在预处理时,会把参数部分用一个占位符 ? 代替,变成如下的 sql 语句:
select * from user where name = ?;而 ${} 则只是简单的字符串替换,在动态解析阶段,该 sql 语句会被解析成
select * from user where name = 'zhangsan';以上,#{} 的参数替换是发生在 DBMS 中,而 ${} 则发生在动态解析过程中。
那么,在使用过程中我们应该使用哪种方式呢?
答案是,优先使用 #{}。因为 ${} 会导致 sql 注入的问题。看下面的例子:
select * from ${tableName} where name = #{name}在这个例子中,如果表名为
- user; delete user; --
则动态解析之后 sql 如下:
select * from user; delete user; -- where name = ?;--之后的语句被注释掉,而原本查询用户的语句变成了查询所有用户信息+删除用户表的语句,会对数据库造成重大损伤,极大可能导致服务器宕机。
但是表名用参数传递进来的时候,只能使用 ${} ,具体原因可以自己做个猜测,去验证。这也提醒我们在这种用法中要小心sql注入的问题。
4、sql
这个元素可以被用来定义可重用的 SQL 代码段,这些 SQL 代码可以被包含在其他语句中。它可以(在加载的时候)被静态地设置参数。 在不同的包含语句中可以设置不同的值到参数占位符上。比如:
id, user_name, real_name, sex, mobile, email, note,
position_id
这个 SQL 片段可以被包含在其他语句中,例如: