关于卡尔曼滤波的原理
关于卡尔曼滤波的原理
文章目录
- 关于卡尔曼滤波的原理
- 1.基本模型的建立
- 2.引入干扰的情况
- 3.减少干扰的思路
- 4.卡尔曼滤波的递归公式
- 5.参考资料
1.基本模型的建立
我们假设我们的系统的状态量有这样的线性的递归关系:
x k = F k x k − 1 + B k u k x_k=F_kx_{k-1}+B_ku_{k} xk=Fkxk−1+Bkuk
为了辅助读者理解,我们以匀速直线运动为例子,我们以位置(p)和速度(v)为状态量,状态检测的周期为Δt:
x k = [ p k v k ] = [ 1 Δ t 0 1 ] [ p k − 1 v k − 1 ] = F k x k − 1 x_k=\begin{bmatrix} p_k\\ v_k \end{bmatrix}= \begin{bmatrix} 1&Δt\\ 0&1 \end{bmatrix} \begin{bmatrix} p_{k-1}\\ v_{k-1} \end{bmatrix} =F_kx_{k-1} xk=[pkvk]=[10Δt1][pk−1vk−1]=Fkxk−1
在这里,Fk则表示前一个状态量和当前状态量的递归关系。
我们再引用变速直线运动的例子来解释Bk和uk:
x k = [ p k v k ] = [ 1 Δ t 0 1 ] [ p k − 1 v k − 1 ] + [ 1 2 Δ t 2 Δ t ] a = F k x k − 1 + B k u k x_k=\begin{bmatrix} p_k\\ v_k \end{bmatrix}= \begin{bmatrix} 1&Δt\\ 0&1 \end{bmatrix} \begin{bmatrix} p_{k-1}\\ v_{k-1} \end{bmatrix} +\begin{bmatrix} \frac 12\Delta t^2\\ \Delta t \end{bmatrix}a =F_kx_{k-1}+B_ku_{k} xk=[pkvk]=[10Δt1][pk−1vk−1]+[21Δt2Δt]a=Fkxk−1+Bkuk
匀速直线运动是物体在不受到合力的作用的时候所做的运动,其状态改变与外界无关,所以其状态只与上一检测时刻的状态相关。而变速直线运动,其运动状态的改变与加速度相关,加速度和合外力作用挂钩,所以在这个情景下,状态的变化不仅与上一观察时刻的状态相关,与当前的外界输入也相关。
为了描述一维观察量的精确程度,我们用方差这个统计量来表征。对于多维的随机变量,我们则用协相关矩阵来表征:
P k = E ( x k x k T ) = [ Σ p p Σ p v Σ v p Σ v v ] P_k=E(x_kx_k^T)= \begin{bmatrix} \Sigma_{pp}&\Sigma_{pv}\\ \Sigma_{vp}&\Sigma_{vv} \end{bmatrix} Pk=E(xkxkT)=[ΣppΣvpΣpvΣvv]
对于状态变量x的协相关矩阵,根据其性质,我们可以得到其递归表达式:
P k = F k P k − 1 F k T P_k=F_kP_{k-1}F_k^T Pk=FkPk−1FkT
2.引入干扰的情况
但是实际上,我们的状态观察往往存在各种各样的干扰,我们由中心极限定理,可以认为在大多数情境下,干扰服从高斯分布。我们的递归表达式也变为:
x k = F k x k − 1 + B k u k + w k w k ∼ N ( 0 , Q k ) x_k=F_kx_{k-1}+B_ku_{k}+w_k \\ w_k\sim N(0,Q_k) xk=Fkxk−1+Bkuk+wkwk∼N(0,Qk)
于是我们的协相关矩阵的实际的递归表达式也应该为:
P k = F k P k − 1 F k T + Q k P_k=F_kP_{k-1}F_k^T+Q_k Pk=FkPk−1FkT+Qk
不难看出,如果我们一直使用递归的形式来求下一观察时刻的状态观察值,那么最后协相关矩阵也可能会越来越大而不收敛。这也是为什么我们一般不会单独采用会累计误差的测量方法比如积分法的原因。
这个时候,数据融合的优势就体现出来了,加入我们还有一组传感器,它们可以测量出与x相关的被测量,我们假设传感器的测量值组成的矩阵为y,令传感器所测物理量和被观察状态物理量满足线性关系,用矩阵可以表示为:
y = H x y=Hx y=Hx
我们可以认为传感器的测量值Y和递归估计值Hx这两个随机变量都分别服从两个高斯分布:
H k x k ∼ N ( H k x ^ k , H k P k H k T ) Y ∼ N ( y k , R ) H_kx_k\sim N(H_k\hat x_k,H_kP_kH_k^T) \\ Y\sim N(y_k,R) Hkxk∼N(Hkx^k,HkPkHkT)Y∼N(yk,R)
3.减少干扰的思路
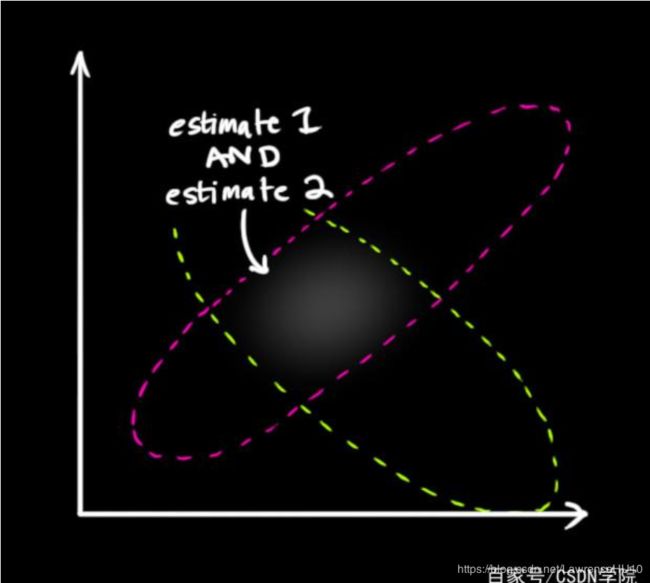 (图源:百家号-CSDN学院)
(图源:百家号-CSDN学院)
我们由上一部分的分析可以得知,当我们传感器测量值Y和状态改变的估计值Hx都服从两个正态分布,假设我们的观测量和测量量都是二维的,那么如图所示,这两个正态分布分布在绿色和红色两个区域(++注意:事实上服从正态分布的随机变量是不会有界的,但是我们一般认为其范围在μ±3σ之内,多维正态分布随机变量也同理++)。如果我们将这两个随机变量的概率密度函数相乘,再将其归一化,不就可以得到一个方差更小的分布吗?
对于一个服从n维正态分布的随机变量,其概率密度函数为:
p ( x ; μ 1 , Σ 1 ) = 1 ( 2 π ) n 2 ∣ Σ 1 ∣ 1 2 exp ( − 1 2 ( x − μ 1 ) T Σ 1 − 1 ( x − μ 1 ) ) p ( x ; μ 2 , Σ 2 ) = 1 ( 2 π ) n 2 ∣ Σ 2 ∣ 1 2 exp ( − 1 2 ( x − μ 2 ) T Σ 2 − 1 ( x − μ 2 ) ) p(x;\mu_1,\Sigma_1)=\frac 1{(2\pi)^\frac n2|\Sigma_1|^\frac 12}\exp(-\frac12(x-\mu_1)^T\Sigma_1^{-1}(x-\mu_1))\\ p(x;\mu_2,\Sigma_2)=\frac 1{(2\pi)^\frac n2|\Sigma_2|^\frac 12}\exp(-\frac12(x-\mu_2)^T\Sigma_2^{-1}(x-\mu_2)) p(x;μ1,Σ1)=(2π)2n∣Σ1∣211exp(−21(x−μ1)TΣ1−1(x−μ1))p(x;μ2,Σ2)=(2π)2n∣Σ2∣211exp(−21(x−μ2)TΣ2−1(x−μ2))
两个概率密度函数做乘法再重新做归一化之后,所得的概率密度函数是一个高斯分布的概率密度函数,其均值和方差分别满足:
μ ′ = μ 1 + K ( μ 2 − μ 1 ) Σ ′ = Σ 1 − K Σ 1 \mu'=\mu_1+K(\mu_2-\mu_1) \\ \Sigma'=\Sigma_1-K\Sigma_1 μ′=μ1+K(μ2−μ1)Σ′=Σ1−KΣ1
其中:
K = Σ 1 ( Σ 1 + Σ 2 ) − 1 K=\Sigma_1(\Sigma_1+\Sigma_2)^{-1} K=Σ1(Σ1+Σ2)−1
这样,我们就可以从概率分布与统计的角度减少了干扰对我们测量值的影响。

值得注意的是,我们的两个高斯分布真的会像这一部分刚开始所展示的图中所示的那样吗?答案肯定是否。但是我们在设定方案时,要尽量使我们的两个正态分布满足这样的关系。比如我们用于姿态结算的9轴传感器,就是利用陀螺仪来得到角速度,再利用角速度递归运算得到欧拉角,再利用加速度计和磁力计这两个可以获取绝对欧拉角的传感器来对结果做修正。这个数据融合的方式就可以选择卡尔曼滤波。陀螺仪可以得到较为准确的角速度信息,但是用其求欧拉角难免会存在累计误差,而加速度传感器和磁力计则没有累计误差,但是在运动时误差会很大,这三种传感器的测量结果恰好和图中的特性一致,利用卡尔曼滤波的方式则可以实现优势互补。
4.卡尔曼滤波的递归公式
根据第三部分所讲,我们可以用概率密度函数相乘的方式得到一个新的高斯分布,我们可以用这个新的高斯分布的均值和方差,作为我们新的状态值和其协相关矩阵的最优估计。
首先我们可以得到传感器测量值y的最佳估计:
Y k ′ = H k x ^ k + K ′ ( y k − H k x ^ k ) Σ Y k = H k P k H k T − K ′ H k P k H k T Y'_k=H_k\hat x_k+K'(y_k-H_k\hat x_k) \\ \Sigma_{Y_k}=H_kP_kH_k^T-K'H_kP_kH_k^T Yk′=Hkx^k+K′(yk−Hkx^k)ΣYk=HkPkHkT−K′HkPkHkT
其中:
K ′ = H k P k H k T ( H k P k H k T + R ) − 1 K'=H_kP_kH_k^T(H_kP_kH_k^T+R)^{-1} K′=HkPkHkT(HkPkHkT+R)−1
我们再根据物理量y与x的关系,得到x关于y的函数:
x = H − 1 y x=H^{-1}y x=H−1y
于是我们对观察状态x的最优估计就可以写为:
X ^ k ′ = H k − 1 Y k ′ = x ^ k + K ( y k − H k x ^ k ) P k ′ = P k − K H k P k K = H k − 1 K ′ = P k H k T ( H k P k H k T + R ) − 1 \hat X_k'=H^{-1}_kY_k'=\hat x_k+K(y_k-H_k\hat x_k) \\ P'_k=P_k-KH_kP_k \\K=H_k^{-1}K'=P_kH_k^T(H_kP_kH_k^T+R)^{-1} X^k′=Hk−1Yk′=x^k+K(yk−Hkx^k)Pk′=Pk−KHkPkK=Hk−1K′=PkHkT(HkPkHkT+R)−1
那么综上所述,卡尔曼滤波关于观测状态x的递归公式为:
x ^ k = F k x ^ k − 1 + B k u k P ^ k = F k P k − 1 F k T + Q X ^ k ′ = x ^ k + K ( y k − H k x ^ k ) P k ′ = ( I − K H k ) P k K = P k H k T ( H k P k H k T + R ) − 1 \hat x_k=F_k\hat x_{k-1}+B_ku_k \\ \hat P_k=F_kP_{k-1}F_k^T+Q \\ \hat X_k'=\hat x_k+K(y_k-H_k\hat x_k) \\ P'_k=(I-KH_k)P_k \\ K=P_kH_k^T(H_kP_kH_k^T+R)^{-1} x^k=Fkx^k−1+BkukP^k=FkPk−1FkT+QX^k′=x^k+K(yk−Hkx^k)Pk′=(I−KHk)PkK=PkHkT(HkPkHkT+R)−1
值得注意的是,应用卡尔曼滤波的时候,我们必须要了解测量误差的方差R和过程误差的方差Q。 对于经典的卡尔曼滤波器,这两个值则需要我们通过测量和估计得到,之后有机会再深入研究一下。
5.参考资料
1.详解卡尔曼滤波原理——CSDN学院
2.【图灵鸡】什么是卡尔曼滤波?其实一点也不难!详解卡尔曼滤波