通过requests库re库进行淘宝商品爬虫爬取(对中国大学mooc嵩天老师爬虫进行修改)
中国大学mooc上的爬取淘宝页面商品已经因为淘宝的维护而无法爬取
比如,只出现个表头:
![[外链图片转存失败,源站可能有防盗在这里插入!链机制,建描述]议将图片上https://传(implog.csdnimg.cn/20203Sdbz309195430123.png4)(https://img一直-blog.csdnimg.cn/20200309195430123.png)]](http://img.e-com-net.com/image/info8/29beb4de46f7409cb7a9756afbd1a1ca.png)
这是我按照嵩天老师代码学习,遇到的问题。
原代码如下:
import requests
import re
def getHTMLText(url):
try:
r= requests.get(url,timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def parsePage(ilt,html):
try:
plt = re.findall(r'\"view_price\":\"[\d+\.]*\"',html)
tlt = re.findall(r'\"raw_title\"\:\".*?\"',html)
for i in range(len(plt)):
price = eval(plt[i].split(':')[1])
title = eval(tlt[i].split(':')[1])
ilt.append([price,title])
except:
print("F")
def printGoodsList(ilt):
tplt = "{:4}\t{:8}\t{:16}"
print(tplt.format("序号","价格","商品名称"))
count = 0
for g in ilt:
count = count +1
print(tplt.format(count,g[0],g[1]))
def main():
goods = '书包'
depth = 2
start_url = "https://s.taobao.com/search?q="+ goods
infoList = []
for i in range(depth):
try:
url = start_url +'&s='+str(44*i)
html = getHTMLText(url)
parsePage(infoList,html)
except:
continue
printGoodsList(infoList)
main()
这段代码在过去是可以爬取淘宝商品信息,但是因为淘宝的反扒技术升级,便不能让你大摇大摆地进出自如了。
所以,想要用爬虫爬淘宝,先要学会伪装。
简单来说,就本课例而言,我们需要把headers内容中的referer和cookies进行替换,改头换面,就可以爬取我们所需要的淘宝信息了。
实际操作如下:
1.首先打开淘宝页面,搜索书包

有时必须登录才能搜索,或不,但都不会影响到爬虫运行。
2.然后按F12,进行如下图的操作,即按照红色箭头以此操作:Network→All→右击search文件→Copy→ Copy as cURL(bash)
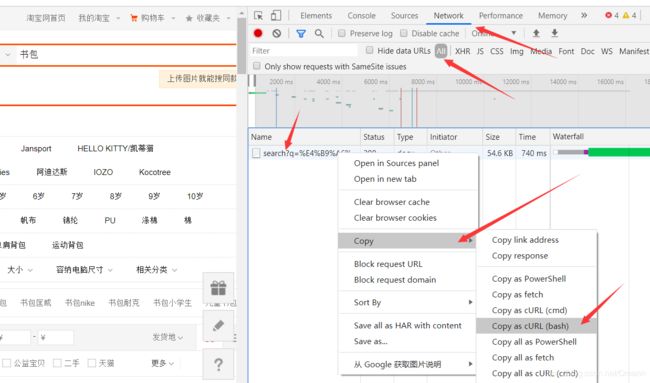
3.然后将复制内容复制到https://curl.trillworks.com/中的curl command窗口中
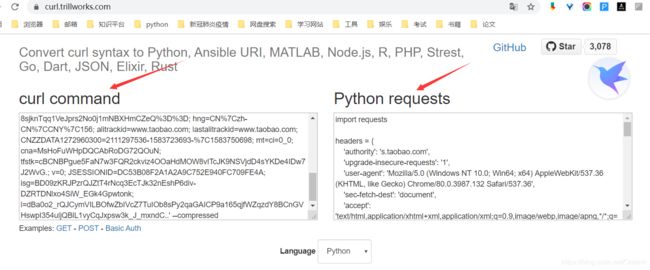
4.将python requests框内的headers={**}内容进行复制,如下:
headers = {
‘authority’: ‘s.taobao.com’,
‘upgrade-insecure-requests’: ‘1’,
‘user-agent’: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36’,
‘sec-fetch-dest’: ‘document’,
‘accept’: 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,/;q=0.8,application/signed-exchange;v=b3;q=0.9’,
‘sec-fetch-site’: ‘same-origin’,
‘sec-fetch-mode’: ‘navigate’,
‘sec-fetch-user’: ‘?1’,
‘referer’: ***********,
‘accept-language’: ‘zh-CN,zh;q=0.9’,
‘cookie’: ***********,
}
(此处的headers信息中referer和cookie已经被我隐藏了,你直接复制你自己的headers={}就可以了)
5.最后,修改到原程序里,如下:
import requests
import re
def getHTMLText(url):
try:
header = { 'authority': 's.taobao.com',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36',
'sec-fetch-dest': 'document',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'sec-fetch-site': 'same-origin',
'sec-fetch-mode': 'navigate',
'sec-fetch-user': '?1',
'referer': '**********',
'accept-language': 'zh-CN,zh;q=0.9',
'cookie': ‘***********’,}
r= requests.get(url,headers = header)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def parsePage(ilt,html):
try:
plt = re.findall(r'\"view_price\":\"[\d+\.]*\"',html)
tlt = re.findall(r'\"raw_title\"\:\".*?\"',html)
for i in range(len(plt)):
price = eval(plt[i].split(':')[1])
title = eval(tlt[i].split(':')[1])
ilt.append([price,title])
except:
print("F")
def printGoodsList(ilt):
tplt = "{:4}\t{:8}\t{:16}"
print(tplt.format("序号","价格","商品名称"))
count = 0
for g in ilt:
count = count +1
print(tplt.format(count,g[0],g[1]))
def main():
goods = '书包'
depth = 2
start_url = "https://s.taobao.com/search?q="+ goods
infoList = []
for i in range(depth):
try:
url = start_url +'&s='+str(44*i)
html = getHTMLText(url)
parsePage(infoList,html)
except:
continue
printGoodsList(infoList)
main()
除了添加更改header外,还要记得
r.requests.get(url,timeout=30)
改成
r.requests.get(url,headers=header)
运行
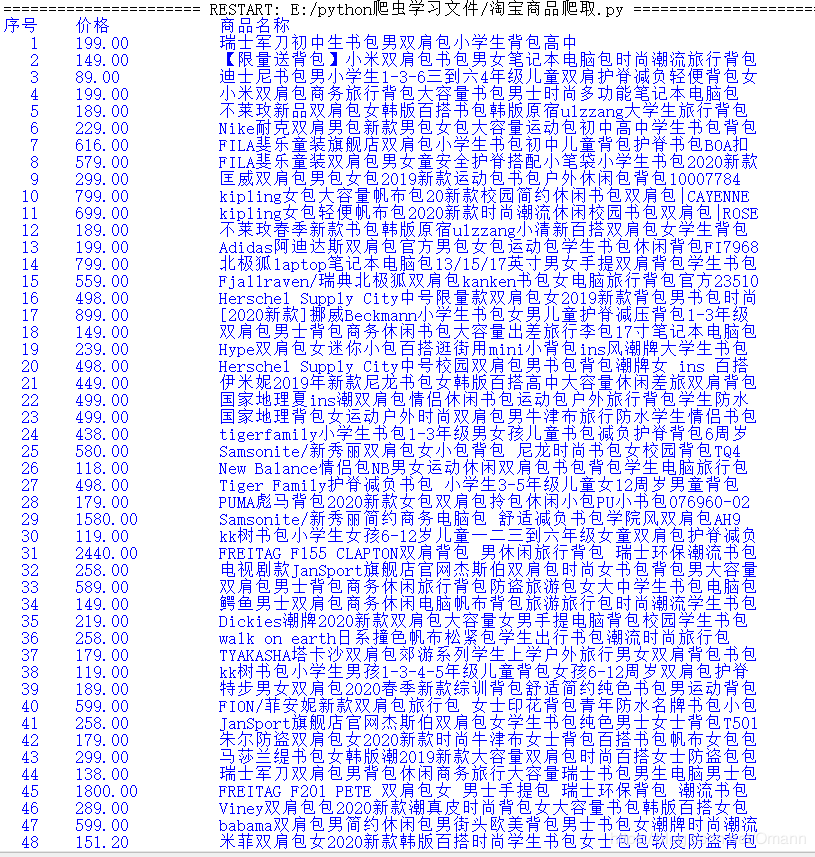
成功