Java中String使用及分析(UTF-8简单编码/解码器实现)
0. Java中的字符串(String)
- 在 Java 语言中,字符串即 字符序列(这里的字符可以是一个英文字母例如 ‘A’,也可以是一个汉字例如 ‘楠’,也可以是一个韩语文字例如 ‘남’,也可以是一个 emoji 表情符号例如 ‘?’ 或 ‘?’)。原生类型 char 用来定义一个字符变量,char 类型字符变量用于保存一个字符。String 类型用来表示一个字符串,Java 中所有字符串字面量都是 String 类型的对象实例,而 String 类内部使用 char 类型的数组保存组成该字符串的字符序列,String 并没有提供修改字符串即 字符序列的方法,但这并不因为不能做到。下面是一个 String 类的构造器方法,如下:
public String(String original) {
this.value = original.value;
this.hash = original.hash;
}
可见该方法使用一个 String 类型的实例对象初始化/创建另一个 String 对象,它们内部都指向同一个字符序列,这是通常我们创建一个 String 类型对象实例的方式之一:
String str = new String("this is string");
可见,下面的直接赋值的方法更简洁/高效一点:
String str = "this is string";
- Java中的字符串并非不能修改,下面的例子使用反射来修改字符串对象的值:
import java.lang.reflect.Field;
public class Test3 {
public static void main(String[] args) throws NoSuchFieldException,
SecurityException, IllegalArgumentException, IllegalAccessException {
String str1 = "真楠人";
String str2 = "真楠人";
// 打印字符串 str1 和 str2
System.out.println("str1: " + str1 + ", str2: " + str2);
// 通过反射更改字符串 str1 的值
Field valueField = String.class.getDeclaredField("value");
assert valueField != null;
valueField.setAccessible(true);
char[] value = (char[]) valueField.get(str1);
value[0] = '假';
// 再次打印字符串 str1
System.out.println("str1: " + str1 + ", str2: " + str2);
}
}
代码执行结果如下:
str1: 真楠人, str2: 真楠人
str1: 假楠人, str2: 假楠人
上述程序中,我们通过反射方法仅仅修改了字符串 str1 的内容,但是最后字符串 str2 的内容也一起改变了,原因在于 str1 和 str2 都是引用同一个字符串对象(字符串字面量 “真楠人” 为一个 String 类型的对象实例,虽然这个字面量在代码中出现多次,但是都是引用了同一个 String 实例,可见相同字符序列的字符串共享同一个 String 实例,即 共享字符串,这也解释了为什么 String 类没有提供修改字符串的公共方法以及String 类被设计为 final 类,都是为了共享字符串),这并不难理解。
1. Java中的字符(char)
- 下面的程序打印一个字符 ‘楠’ 字:
public class Temp_3 {
public static void main(String[] args) {
System.out.println('楠');
System.out.println((char)26976);
System.out.println('\u6960');
}
}
运行结果为:
楠
楠
楠
可见,三次打印输出的结果都一样。Java 语言使用 Unicode 字符集,Unicode 为每一个字符都分配的一个唯一的数字,即 这个数字便代表与之对应的字符,其中 ‘\u6960’ 即为字符 ‘楠’ 的 Unicode 十六进制编码,而十进制数 26976 则为这个十六进制数的十进制数值,它俩是同一个数值的不同表示方式而已。
- 我们知道 ASCII 字符集中,字符 ‘A’ 的编号为 65,即 可以对 65 进行强制类型转换即可得到其对应的字符 ‘A’。数值 65 使用一个字节便可存储,显然对于字符 ‘楠’(对应数值为 26976) 一个字节无法存储,那么它需要多少个字节才合适呢?
- 我们可以看看其它编程语言中的情况,在 C 语言中也有一个 char 数据类型,但是它仅仅表示一个字节的空间,看下面的 C 语言中的例子:
#include 执行结果如下:
ubuntu@cuname:~/dev/beginning-linux-programming/temp$ gcc -o use-char-string-test use-char-string-test.c
use-char-string-test.c: In function ‘main’:
use-char-string-test.c:4:14: warning: multi-character character constant [-Wmultichar]
char c = '楠';
^
use-char-string-test.c:4:14: warning: overflow in implicit constant conversion [-Woverflow]
ubuntu@cuname:~/dev/beginning-linux-programming/temp$ ./use-char-string-test
�, -96, size=1 // c
A, size=1 // c2
楠, size=4 // c3
真楠人, size=10 // c4
可以看到,将字符 ‘楠’ 赋值给 char 类型的变量时,gcc 编译器警告提示字符 ’楠‘ 为多字节字符常量,而变量 c 仅仅存储了字符 ’楠‘ 的一个字节的数据(且其数值为 -96,-96 是字符 ‘楠’ 字编码后的字节序列中的一个字节,变量 c 显示乱码),继续查看后续的输出结果,发现字符 ’A‘ 的长度为 1 个字节,而每个汉字占 3 个字节的存储空间(C 语言中的字符串字面量的内部实现为 char 类型的数组,且以一个空字符 ’\0‘表示字符串结尾,所以 sizeof 计算的字符串长度(即 字节数)比实际长度多一个字节)。3 个字节能表示的最大数值为 ’2的24次方‘ - 1 = 16777215,远远大于 26976(即字符 ’楠‘ 对应的数字),其实 2 个字节就足以存储数值 26976(即字符 ’楠‘),而实际上字符 ’楠‘ 却占用了 3 个字节空间,这是为啥?这与字符(即 数值)的编码(即 存储)方式有关,我们知道 Unicode 给每个字符分配一个唯一的数值来代表该字符,例如任一一篇文章很可能会有多个字符,但是在存储或传输该文章时,并不能就直接依次存储或传输与每个字符对应的十进制数字序列,这里需要考虑 2 个问题,第一如何从数字序列中识别一个字符,即每个字符的 ‘数字表示’ 其自身应当是一个整体,必须与其它的数字即与其相邻的数字区分开,第二个问题:成本,字符 ‘A’ 使用 1 个字节即可存储,但是字符 ‘楠’ 却要使用至少 2 个字节才能满足,这时,如果要求每个字符都是使用例如 2 个字节存储,那么对于英语国家的用户来说,相当于增加并浪费了 1 倍的成本,这是不能被接受!UTF-8 便是一种可变长度的 Unicode 字符编码解决方案,且被应用于 Java 语言,于是求助于 UTF-8(即 Unicode Transformation Format 8-bit,)。
2. UTF-8编码
- 参考链接UTF-8 and Unicode
- 下面是对UTF-8编码-规范文档的解读(需要注意区分,Unicode 只是一个字符集,它为每个字符分配一个唯一的数字,从而可以用数字来表达字符,而 UTF-8 是一种编码方式,描述怎样实际存储Unicode 字符对应的数值)
- UTF-8 兼容 ASCII 字符集,即 将编号 0 - 127 留给 ASCII 字符集,这里(ASCII 字符集)总共 128 个数字(即 字符),使用 7 个 bit 的空间即可表示,每个 ASCII 字符占用一个字节,且该字节的最高位始终为 0,反过来,在 UTF-8 编码中,最高位为 0 的字节始终表示一个 ASCII 字符。
- UTF-8 使用 1 - 4 个字节来编码 Unicode 字符对应的数字编号,规则如下图
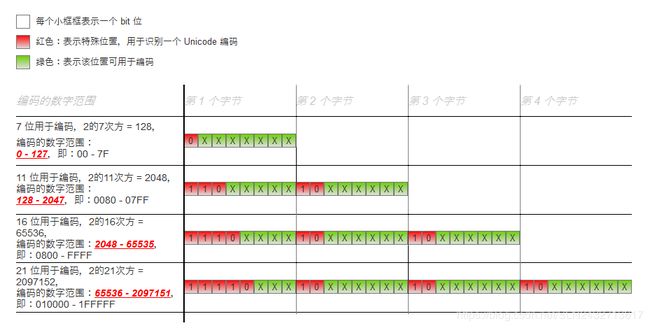 上图与 UTF-8 规范文档中的图有点不同:即 可编码的最大值不同,文档图如下:
上图与 UTF-8 规范文档中的图有点不同:即 可编码的最大值不同,文档图如下:
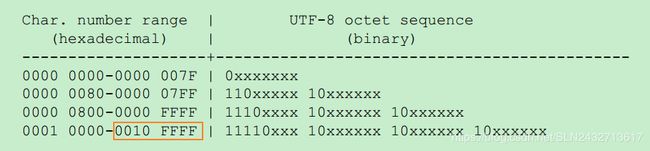 再回到前面说的字符 ‘楠’ 字,该字符的 Unicode 编号为 26976,而 26976 位于 2048 和 65535 之间,所以它使用 3 个字节进行编码并存储。在进行编码时,只需将 26976 的二进制码从低位到高位依次填入‘可用编码位’ 即可得到字符 ‘楠’ 对应的 UTF-8 编码,操作如下图:
再回到前面说的字符 ‘楠’ 字,该字符的 Unicode 编号为 26976,而 26976 位于 2048 和 65535 之间,所以它使用 3 个字节进行编码并存储。在进行编码时,只需将 26976 的二进制码从低位到高位依次填入‘可用编码位’ 即可得到字符 ‘楠’ 对应的 UTF-8 编码,操作如下图:

验证,使用 notepad++ 新建一个文本文件,并写入字符 ‘楠’ 字(注意,使用 utf-8编码),保存文件,然后使用 WinHex 打开该文本文件,结果如下:
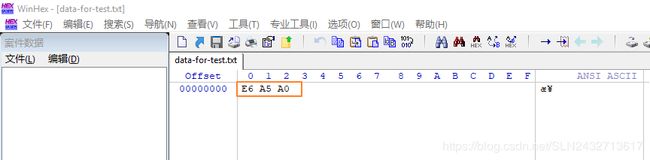 可见,结果正确。
可见,结果正确。 - 上面是编码一个字符,下面从 以UTF-8 编码的字节数据中进行解码(解码是编码的反向操作,编码是将数值位依次插入到对应的可编码位,解码时则从可编码位提取对应的数值位并将它们拼接在一起,从而还原出原来的数值)。综上可以发现,以 UTF-8 编码的数据,其字节类型总共有 5 种,其中只有 4 中类型的字节是可作为一个 UTF-8 编码的起始字节(即标识一个字符编码的开始),如下图:
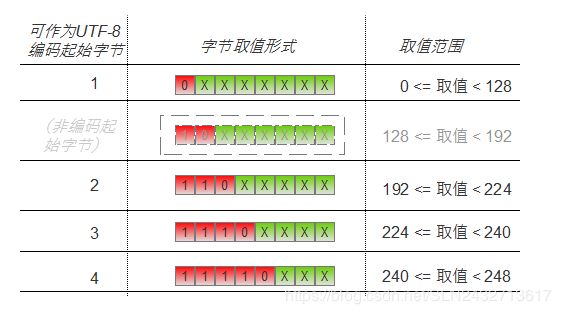
思路:将数值 240(即 ‘1111 0000’)与任意字节作 ‘&’ (即 ‘与’)位操作,其结果必定落在上图中的某个取值范围中,从而可以决定当前字节的类型(是否为一个字符编码的起始字节)。
简单 UTF-8 解码器 Java 实现,代码如下:
/** 简单 UTF-8 解码器(实际应用中,可能必须要注意/处理无效字符 即无效 unicode code-point 的情况) */
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.Random;
public class UTF_8_decoder {
/** 1M,用于缓存数据 */
private static final int BUFFER_SIZE = 1024 * 1024;
/** 文本文件 */
private static final String filePath = "C:/Users/jokee/Desktop/data-for-test.txt";
public static void main(String[] args) throws IOException {
File file = new File(filePath);
FileInputStream fileReader = new FileInputStream(file);
/** 用于缓存文件字节数据 即 缓存待解码的数据 */
byte[] buffer = new byte[BUFFER_SIZE];
/** 缓存所有数据 */
final int bytesLength = fileReader.read(buffer, 0, buffer.length);
String result = doDecoding(buffer, bytesLength);
// 打印结果
System.out.println("解码字符如下:\n" + "---------------------------------------------\n"
+ result);
fileReader.close();
}
/**
* 执行解码操作,默认大端字节序
*
bytes : 待解码字节缓冲区
*
bytesLength :缓冲区 bytes 中,待解码的字节总数
*/
public static String doDecoding(byte[] bytes, int bytesLength) {
/** 保存解码后的数据 */
char[] charData = null;
int charData_index = 0;
String result = null;
if (bytes != null
&& (bytesLength = Math.min(bytesLength, bytes.length)) > 0) {
// 1 从一个随机位置开始解码
// int startIndex = new Random().nextInt(bytesLength);
// 2 解码所有字节数据
int startIndex = 0;
/** 字符类型(参考 getType 方法) */
int type = 0;
/** 保存一个字符的 UTF-8 编码 */
byte[] encodedCharData = new byte[4];
int encodedCharData_index = 0;
// 初始化
charData = new char[BUFFER_SIZE];
for (; startIndex < bytesLength; ++startIndex) {
if (encodedCharData_index == 0 && (type = getType(bytes[startIndex])) < 0) {
// 直到找到一个 UTF-8 编码的起始字节为止
continue;
}
// 读取一个字符的编码
encodedCharData[encodedCharData_index++] = bytes[startIndex];
if (encodedCharData_index < type) {
// 继续读取该字符剩余的其它字节
continue;
}
// 解码一个字符
if (type == 1) {
// 1
// ascii 字符
charData[charData_index++] = (char) Byte.toUnsignedInt(encodedCharData[0]);
} else if (type == 2) {
// 2
// 提取第一个字节,屏蔽前 3 个 bit
int b1 = 0b00011111 & Byte.toUnsignedInt(encodedCharData[0]);
// 提取第二个字节,屏蔽前 2 个 bit
int b2 = 0b00111111 & Byte.toUnsignedInt(encodedCharData[1]);
int aChar = (b1 << 6) | b2;
charData[charData_index++] = (char)aChar;
} else if (type == 3) {
// 3
// 提取第一个字节,屏蔽前 4 个 bit
int b1 = 0b00001111 & Byte.toUnsignedInt(encodedCharData[0]);
// 提取第二个字节,屏蔽前 2 个 bit
int b2 = 0b00111111 & Byte.toUnsignedInt(encodedCharData[1]);
// 提取第三个字节,屏蔽前 2 个 bit
int b3 = 0b00111111 & Byte.toUnsignedInt(encodedCharData[2]);
int aChar = (b1 << 12) | (b2 << 6) | b3;
charData[charData_index++] = (char)aChar;
} else if (type == 4) {
// 4
// 提取第一个字节,屏蔽前 3 个 bit
int b1 = 0b00000111 & Byte.toUnsignedInt(encodedCharData[0]);
// 提取第二个字节,屏蔽前 2 个 bit
int b2 = 0b00111111 & Byte.toUnsignedInt(encodedCharData[1]);
// 提取第三个字节,屏蔽前 2 个 bit
int b3 = 0b00111111 & Byte.toUnsignedInt(encodedCharData[2]);
// 提取第四个字节,屏蔽前 2 个 bit
int b4 = 0b00111111 & Byte.toUnsignedInt(encodedCharData[3]);
int aChar = (b1 << 18) | (b2 << 12) | (b3 << 6) | b4;
charData[charData_index++] = (char)aChar;
}
// 清理工作
// 清除已缓存且已完成解码的字符编码,继续处理下一个字符编码
encodedCharData_index = 0;
}
result = new String(charData, 0, charData_index);
}
return result;
}
/**
* 该方法用于确认参数字节 aByte 是否为一个 UTF-8 编码的起始字节, 返回值说明,
* -1:字节 aByte 非起始字节,
* 1:起始字节,类型为 1,对应字符占 1 个字节空间(实为 ASCII 字符)
* 2:起始字节,类型为 2,对应字符占 2 个字节空间
* 3:起始字节,类型为 3,对应字符占 3 个字节空间
* 4:起始字节,类型为 4,对应字符占 4 个字节空间
*/
public static int getType(byte aByte) {
int type = 0b11110000 & aByte; // ‘0b11110000’ 为十进制数 240 的二进制表示
if (0 <= type && type < 128) {
return 1;
} else if (128 <= type && type < 192) {
return -1;
} else if (192 <= type && type < 224) {
return 2;
} else if (224 <= type && type < 240) {
return 3;
} else if (240 <= type && type < 248) {
return 4;
}
return -1;
}
}
- 既然上面有了一个简单的解码器,再加一个编码器也不会多余,下面是一个简单的 UTF-8 编码器实现(其中的位运算必须要细心,容易出错):
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
/** 简单的 UTF-8 编码器(实际应用中,可能必须要注意/处理无效字符 即无效 unicode code-point 的情况) */
public class UTF_8_encoder {
/** 输出文件 */
private static final String filePath = "C:/Users/jokee/Desktop/data-for-test.txt";
public static void main(String[] args) throws IOException {
String text = "\u13A0,\u1B93,\u1D83,\u1F00,\u1F10,\u1910\nwo我爱wo家ya,wo爱北京天安门a,\nhei,今天又下雨了ne";
int[] cs = new int[text.length()];
for(int i = 0;i < text.length();i++) {
cs[i] = text.charAt(i);
}
// do encoding
Bytes bytes = doEncoding(cs, cs.length);
// write to file
FileOutputStream writer = new FileOutputStream(new File(filePath));
writer.write(bytes.bytes, 0, bytes.length);
writer.close();
System.out.println("done.");
}
/** 将字符数组 chars 中的数量为 charsLength 的字符进行编码 */
public static Bytes doEncoding(int[] chars, int charsLength) {
Bytes bytes = null;
if (chars != null && (charsLength = Math.min(chars.length, charsLength)) > 0) {
int aChar = 0;
int type = 0;
/** 定义一个足够容量的字节缓存区:假设每个字符都是占用 4 个字节 */
bytes = new Bytes(4 * charsLength);
for(int i = 0;i < charsLength;i++) {
aChar = chars[i];
type = getType(aChar);
switch(type) {
case 1:
bytes.add((byte)aChar);
break;
case 2:
{
int code = 0b1100000010000000;
code |= (aChar & 0b111111);
code |= ((aChar & 0b11111000000) << 2);
bytes.add((byte)(code >> 8));
bytes.add((byte)code);
}
break;
case 3:
{
int code = 0b111000001000000010000000;
code |= (aChar & 0b111111);
code |= ((aChar & 0b111111000000) << 2);
code |= ((aChar & 0b1111000000000000) << 4);
bytes.add((byte) (code >> 16));
bytes.add((byte) (code >> 8));
bytes.add((byte) code);
}
break;
case 4:
{
int code = 0b11100000100000001000000010000000;
code |= (aChar & 0b111111);
code |= ((aChar & 0b111111000000) << 2);
code |= ((aChar & 0b111111000000000000) << 4);
code |= ((aChar & 0b111000000000000000000) << 6);
bytes.add((byte) (code >> 24));
bytes.add((byte) (code >> 16));
bytes.add((byte) (code >> 8));
bytes.add((byte) code);
}
break;
default:
// nothing to do.
}
}
}else {
// 返回一个空的字节缓存区
bytes = new Bytes(0);
}
return bytes;
}
/**
* 返回值表示一个字符 aChar 的编码空间(即 需占用的字节数),返回值如下 4 种:
*
1,表示使用 1 个字节编码字符 aChar 对应的数值
*
2,表示使用 2 个字节编码字符 aChar 对应的数值
*
3,表示使用 3 个字节编码字符 aChar 对应的数值
*
4,表示使用 4 个字节编码字符 aChar 对应的数值
* 如果 aChar 是无效的 UTF-8 字符,可选择抛出异常:IllegalArgumentException,或忽略
*/
public static int getType(int aChar) {
if (!Character.isValidCodePoint(aChar)) {
// throw new IllegalArgumentException(aChar + " is invalid code point");
return 0;
}
if(0 <= aChar && aChar <= 127) {
// a char of ascii
return 1;
}else if(128 <= aChar && aChar <= 2047) {
return 2;
}else if(2048 <= aChar && aChar <= 65535) {
return 3;
}else if(65536 <= aChar && aChar <= 2097151) {
return 4;
}else {
// throw new IllegalArgumentException(aChar + " is invalid code point");
return 0;
}
}
/** 组合一个字节缓存区 bytes 及其 长度值 length */
public static class Bytes {
private int length;
private final int capacity;
private byte[] bytes;
public Bytes(int capacity) {
this.length = 0;
this.capacity = capacity;
this.bytes = new byte[capacity];
}
/** 向该缓存区中添加一个字节 */
public void add(byte aByte) {
if (length < capacity) {
bytes[length++] = aByte;
}else {
throw new ArrayIndexOutOfBoundsException("当前缓存区已满,capacity = length is " + capacity);
}
}
public int getLength() {
return length;
}
public byte[] getBytes() {
return bytes;
}
public int getCapacity() {
return capacity;
}
}
}