Occupancy-Map-Based Rate Distortion Optimization for Video-Based Point Cloud Compression - 论文翻译
基于占有图的视频点云压缩率失真优化
原论文地址: https://ieeexplore.ieee.org/document/8803233
该算法/技术的研究背景
点云是一组三维点,每个点都与一些属性(如颜色、反射等)关联。由于点云具有渲染对象或场景的能力,因此点云可以用于许多场景,例如3D沉浸式临场感、虚拟现实和一些其他应用程序。然而,点云特别是动态点云(DPC)的巨大规模阻碍了这种有前途的媒体格式的使用。例如,对于具有300帧的DPC,每个帧具有100万个点,每个点具有30和24位来表示几何体和属性,原始大小可以大到2GB。因此,迫切需要对DPC进行有效的压缩。
孤立点不仅尺寸大,而且由于形状不规则,使得点云难以压缩。目前用于DPC压缩的方法大致可以分为两类:基于3D的方法和基于视频的方法。
基于三维的方法压缩原始域中的点云。通常,第一帧的几何图形将使用八叉树或二叉树与四叉树组合进行压缩。一些变换如图傅立叶变换(GFT)和区域自适应层次变换(RAHT)或基于层的预测被用来压缩属性。对于帧间,Queiroz和Chou提出将帧划分为多个立方体,并进行基于平移运动模型的运动估计,以找到相应的立方体。Mekuria等人进一步引入迭代最近点代替平移运动模型,提高了编码效率。然而,基于3D的图像压缩方案无法充分利用不同视图之间的相关性,使得压缩比难以满足要求
基于视频的方法,利用高效视频编码(HEVC)等成熟的视频压缩方案,将三维点云投影到二维空间,充分利用相互关系。例如,Schwarz 和 He等人提出用圆柱投影或立方体投影将点云投影到二维视频中,并用HEVC对二维视频进行压缩。然而,由于三维空间中的点遮挡,这种方法可能会丢失大量的点。为了解决这个问题,Mammou等人建议将点云逐块投影到二维视频,以增加投影点的数量。然后使用HEVC对投影的视频进行压缩,并赢得了MEPG动态点云压缩方案的竞争。这种基于视频的方法将在以下部分中称为基于面片(一小块二维平面 patch )的点云压缩。然而,投影视频的许多未占用像素不利于重建视频的质量,如果它们以与占用像素相同的质量进行编码,将导致比特的严重浪费。未占用的像素在时域中甚至不连续,这可能导致更多的比特浪费。
这篇文章的作者提出,利用基于占有图的率失真优化(RDO)来解决这一问题。当块的全部或部分未占用时,在RDO处理中仅考虑未占用像素的速率而不是速率失真(RD)代价。这种方案不仅适用于模式决策过程,而且也适用于样本自适应偏移(SAO)过程。在该方案下,未占用的像素将以很差的质量进行编码以节省比特率,而占用的像素将以与原始方案相同的质量进行编码以保证重建点云的质量。作者认为,这是第一个尝试设计特定RDO算法来提高点云压缩效率的工作。
该算法/技术解决什么问题
在基于面片的点云压缩方法中,首先将三维点云投影到其边界盒中生成多个面片。然后对所有的面片进行适当的填充,形成几何和属性框架。首先将包括占用图、2D帧中的面片位置等信息发送给解码器,然后利用HEVC对几何和属性视频进行编码。在有损点云压缩中,为了在比特率和精度之间取得更好的折衷,将占用图无损地编码为4×4块。

图1给出了未占用像素设置为0的典型帧。从图1中我们可以清楚地看到,在不同的面片中有许多未占用的像素。除了帧底的未占用像素(帧下半部分未占用的绿色区域)易于利用帧内预测进行编码外,不同块之间的未占用像素可能要花费大量比特。由于这些未占用的像素对重建点云的质量没有影响,因此所花费的比特是完全无用的,这可能会严重降低压缩性能。另外,在基于面片的点云压缩方案下,可以在几何和属性视频之前对占用图进行编码,这使得我们可以利用这类信息来改进几何和属性压缩。因此,本文提出了一种基于占有图的RDO算法来解决未占用像素点的问题。
该算法/技术的详细描述
1.算法描述
在HEVC参考软件的默认编码器中,编码参数P包括块的模式、运动和残差由RD代价J确定。

其中Di![]() 是每个像素的失真,R是块的比特率,N是块中的像素数。在RDO过程中,Di
是每个像素的失真,R是块的比特率,N是块中的像素数。在RDO过程中,Di![]() 是指定位置i的原始像素和重建像素之间的平方差。然而,这样的优化问题以同等重要性对待占用的像素和未占用的像素,这可能会显著降低点云压缩的性能。
是指定位置i的原始像素和重建像素之间的平方差。然而,这样的优化问题以同等重要性对待占用的像素和未占用的像素,这可能会显著降低点云压缩的性能。
在所提出的解决方案中,在(1)中加入失真掩模(distortion mask)来处理RDO过程中的未占用像素。
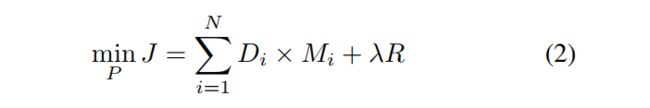
其中,当当前像素被占用时 Mi ![]() 为1,当当前像素未被占用时 Mi
为1,当当前像素未被占用时 Mi![]() 为0 。然后将此公式应用于模式内决策、模式间决策和SAO过程中,以获得良好的性能。
为0 。然后将此公式应用于模式内决策、模式间决策和SAO过程中,以获得良好的性能。
对于帧内预测,模式决策过程可分为3个阶段:粗帧内模式选择、帧内模式决策、帧内剩余四叉树决策。
在第一阶段中,使用原始信号和预测信号之间的绝对变换差(SATD)之和作为失真D ,使用Luma帧内预测方向的比特率作为比特率R,在这一阶段中,目的是获得能够提供更精确预测块的多个候选。由于本阶段不考虑剩余比特,因此我们不能仅考虑部分像素来计算失真,因为失真可以被视为剩余比特率的指示器。在不考虑总剩余比特率的情况下,我们可以选择剩余比特过多的候选预测模式,这不利于RD性能的提高。在第二和第三阶段,考虑到总比特率,我们将(2)应用于模式决策和剩余四叉树过程。
对于帧间预测,模式选择可分为两种模式:2N×2N合并/跳过模式和其他模式,包括2N×2N高级运动矢量预测模式和所有其他模式。对于2N×2N合并/跳过模式,所有的合并候选者使用全RDO,其计算原始信号和重建信号之间的平方差(SSD)之和作为失真,而包括报头和剩余的总比特作为比特率。因此,公式(2)直接应用于2N×2N合并/跳过模式。对于其他模式,RDO过程大致可分为两个阶段:整数/分数运动估计(ME)或合并以确定预测和残差确定。在整数ME处理中,以原始信号与预测信号的绝对差之和(SAD)作为预测,以运动矢量(MV)的位作为比特率。在分数ME或合并过程中,原始信号和预测信号之间的SATD被用作预测,MV或合并索引的比特被用作比特率。由于在这两种情况下都没有考虑剩余比特率,因此我们不能只考虑部分像素来计算失真。在残渣测定中,当使用全RDO时,在RDO过程中使用式(2)。
在SAO过程中,首先针对不同类型的边缘偏移和频带偏移计算原始像素和重构像素之间的偏移。然后,对于每个CTU,我们将使用RDO从这些类型的偏移中选择来确定SAO类型。从上面的描述中,我们知道不同类型SAO的偏移量是影响RDO过程的关键。然而,在模式决策过程中,基于占用图的RDO对一些未占用的像素进行编码,其比特率很低且质量较差。如果我们统计所有像素之间的偏移量,未占用的像素将占据大部分偏移量,因为它们的失真要大得多。这样,每种类型的SAO的偏移对于占用的像素将非常不准确,但是对于未占用的像素将非常准确,这可能导致在每个CTU的RDO处理期间,在恢复未占用的像素的同时降低占用像素的质量的严重比特开销。因此,我们没有显式地改变SAO的RDO过程,而是改变统计过程来获得偏移量。我们将只根据原始信号和重建信号之间占用的像素来计算偏移量。然后RDO进程将自动选择使用占用块的偏移,而不使用未占用块的偏移。

图2示出了基于占用图的RDO和原始RDO之间的重构帧比较。从图2和图1可以看出,大多数被占用的像素保持不变,这意味着在所提出的算法下重建的点云将具有与原始RDO几乎相同的质量。从图2中的红色矩形中,我们可以看到,由于我们可以专注于为被占像素找到更合适的MV,因此可以以更好的质量重建一些被占像素。从图2和图1中,我们还可以看到许多未占用的像素从绿色矩形中以非常差的质量编码。其中一些只是直接从时间共定位位置复制来保存比特率。因为它们不会对点云的重建质量产生任何影响,所以节省一些比特率有利于整体性能。
2.实验结果
在基于视频的点云压缩(V-PCC)参考软件和相应的HEVC参考软件中实现了该算法,并与V-PCC锚进行了比较。我们测试V-PCC通用测试条件中定义的所有五个DPCs。在所有的帧内和随机访问情况下,我们都测试了有损几何有损属性,以显示该算法在帧内和帧间的优点。为了节省编码时间,我们对所有的DPCs进行了32帧的测试,这可以很好地代表整个序列。我们还遵循V-PCC-CTC中定义的速率点,并使用BD速率对各种算法进行比较。对于几何体的BD率,我们报告以点对点误差(D1)和点对平面误差(D2)作为质量度量的结果。对于属性,提供了Luma、Cb和Cr的结果。给出了V-PCC和HEVC参考软件的编译码复杂度。
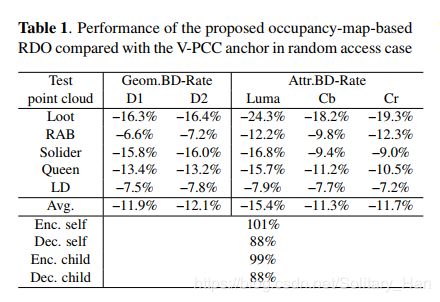
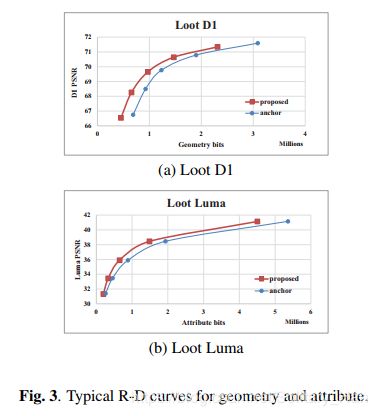
表1显示了在随机访问情况下,与V-PCC锚相比,基于占用图的RDO的性能。从表1可以看出,与D1和D2的V-PCC锚相比,基于占用图的RDO的性能平均提高了10.9%和11:3%。我们还可以看到,所提出的算法可以分别为Luma、Cb和Cr平均节省15.0%、9.2%和10.4%的比特率。该算法明显地证明了该算法可以通过忽略未占用像素的失真而显著地节省比特率。有时,由于在搜索合并候选者列表的候选者时只考虑了所占像素的失真,因此所提出的算法也可以导致对所占像素的稍微更好的预测。我们还展示了两个随机存取情况下的示例R-D曲线,其几何和属性如图3所示。从图3中,我们还可以清楚地看到,所提出的算法可以为几何和属性带来非常显著的比特率节省。
该算法只输出V-PCC编码器的占用图信息,对V-PCC编解码器本身没有显著影响。然而,对于HEVC编码器,由于运动估计和运动补偿过程都得到了显著的简化,所提出的算法可以大大节省编码器和解码器的时间。对于编码器,不需要搜索太多的合并候选和MVs,特别是对于未占用的像素,这样可以降低编码复杂度。对于解码器,更多的块将选择零运动矢量,这将导致更少的插值操作,并节省解码复杂度。
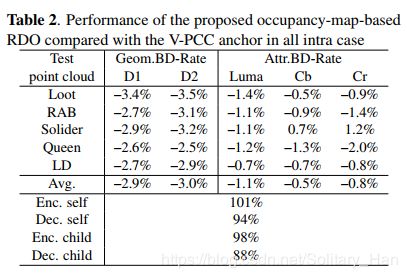
表2显示了在所有内部情况下,与V-PCC锚相比,基于占用图的RDO的性能改进。从表2可以看出,所提出的基于占用图的RDO算法对D1和D2的性能分别平均提高了1.9%和2.1%。该算法对Luma、Cb和Cr的性能分别平均提高了0.9%、0.2%和0.3%。该算法的性能是相当明显的,但并没有案例间那么显著。由于我们不能改变第3节中提到的粗略帧内预测方向过程,我们主要改变的只是最终的帧内预测方向和剩余四叉树。与可以影响合并候选者的MV和分区确定的帧间情况相比,该算法在帧内的变化要小得多。
对该算法/技术的讨论,评价,创新点是什么
为了防止基于视频的点云压缩(VPCC)方案中未占用像素上的比特率浪费,本文提出在速率失真优化过程中只考虑未占用像素的速率而不考虑速率失真代价的思路,并将该思想应用于帧内预测、帧间预测和样本自适应偏移处理。并且将该算法在V-PCC和相应的高效视频编码参考软件中实现。