Java集合(详细介绍版:Map,List,HashMap,Hashtable,HasSet,TreeMap)
集合与数组
1.数组:存储基本数据类型,存储对象的一种容器,但是数组的长度固定,在对象未知数量不建议使用;
2.集合:只能存储对象,对象类型可以不一样,长度也可以变化;
集合的实现
1:Collection接口是集合类的根接口,Java没有提供这个接口直接的实现类,但是却让其被继承产生的两个接口,List,Set。
2:Map是java.util包中的另外一个接口,他和Collection接口没有关系,是相互独立的,都是属于集合的一部分。Map是以key-value键值对的方式存储数据,不能包含重复的key,但是可以有相同的value;
3:Iterator接口会被所有的集合类实现,它是一个用于遍历集合中元素的接口,主要有三种方法:
(1):hasNet()是否有下一个元素;
(2):next()返回下一个元素;
(3):remover()删除当前元素;
List,Set,Map的对比(图片描述)
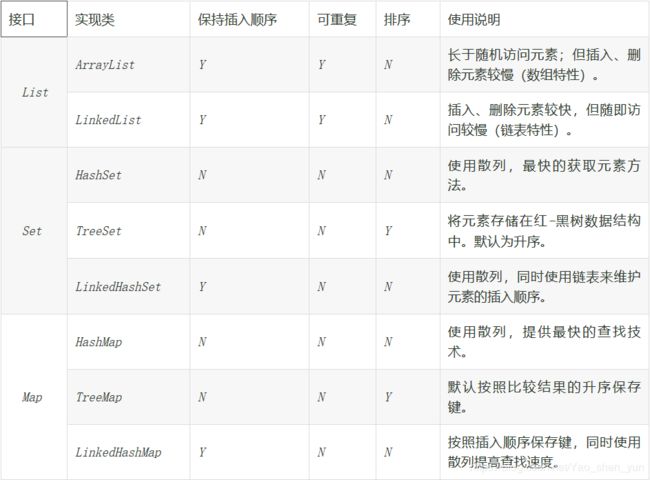
List(有序可重复)
List里面存放的数据是有序的,同时也可以是重复的,List所关注的是索引,它拥有一系列和索引相关的放方法,查询速度快。但是往list里进行增删的时候,会伴随这后面的数据而移动,所以效率会相对而言比较低;
ArrayList
ArrayList底层是基于数组的,在初始化ArrayList时会构建空数组(Object【】 elementDat={})。ArrayList存储数据是无序的,按照添加数据的先后顺序进行排列,ArrayList提供了sort排序方法;
add:ArrayList初始化默认存储长度为10,当真正对其添加数据时才会被分配空间,当存储空间不足时,每次按照1.5倍通过copeOf的方式扩容。
remover:有两种方式,按照下标remover(int index);remover(Object o)遍历数组,获取第一个相同的元素,获取该元素的下标,在调用system.arraycopy将index之后的元素向前移动;
LinkedList
LinkedList底层是基于链表,它是一个双向链表,每个节点维护了一个prev和next指针。同时对于这个链表维护了frist和last指针,first指向第一个元素,last指向最后一个元素。LinkedList是一个无序的链表,按照插入的先后顺序排序。
add:addFirst,addLast,addAll,add;
remove:removeFirst,removeLast,removeFirstOccurrence,remove;
List遍历:(四种常见方式)
(1):Iterator 迭代输出,使用最多的方式;
Iterator it1 = list.Iterator();
while(it1.hasNext()){
system.out.println(it1.next() );
}
(2):ListIterator 是Iterator的子接口,用于输出List中的内容;
for(Iterator it2 = list.iterator();it2.hasNext() ){
system.out.println(it2.next() )
}
(3):foreach JDK1.5以后提供的遍历方法,遍历数组或者集合;
for(String value :list){
system.out.println(value);
}
(4):经常见到的for循环遍历
for(int i = 0;i < list.size(); i++){
system.out.println(list.get(i) );
}
set(无序不可重复,值不相同)
set里存放的数据是无序的,不能重复的,集合中的数据不按照特定的方式排序,只是简单的把数据添加到集合中,可以使用迭代器遍历,有排序方法SortedSet;
HashSet
HashSet是基于hashMap实现的,是对hashMap做了一次简单的封装,而且只使用了hashMap的key来实现各种特性。
HashSet不允许重复,允许null值,为非线程安全;
Map(键唯一,值不唯一,可以有重复的值)
Map集合是以键值对的方式存储数据(key-value),键不能重复,但是值可以有重复。根据键得到值,对map集合遍历时先得到键的set集合,在对set集合进行遍历,得到相应的值;子接口有(HashMap,Hashtable,LinkedHashMap,TreeMap);
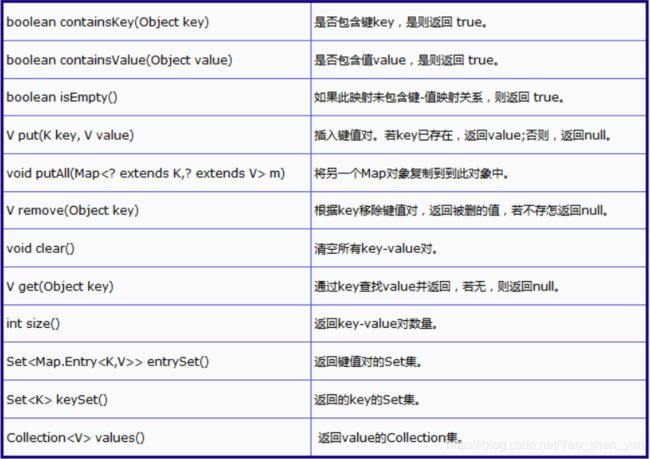
Map的常用方法:
HashMap
HashMap实现了Map接口,Map接口对键值对进行映射。TreeMap保存了数据的排序顺序,而HashMap则不能。HashMap允许一个键为null,值随意。HashMap是非线程安全(synchronized)的,但collection框架提供的方法能够保证HashMap Synchronized,这样多个线程访问HashMap时,能保证只有一个线程能修改HashMap;(下一章讲一下HashMap的工作原理以及一些经常被问答的面试题)HashMap的详细介绍:HashMap的详细介绍
Hashtable
Hashtable和HashMap类似,不允许有空的键和值,是HashMap的线程安全版,支持线程同步,任何时候只能有一个线程去修改Hashtable,因此也导致了HashTable效率相比较HashMap低。
LinkedHashMap
LinkedHashMap保存了数据的插入顺序,在使用Iterator遍历时,先得到的肯定是第一次插入的数据,遍历时会比HashMap慢,有HashMap的全部特性;
TreeMap
基于红黑二叉树的NavigableMap的实现,非线程安全,不允许有null,key不可以重复,value允许有重复,存入TreeMap的数据要实现Comparable,会按照排序后的顺序迭代数据,两个相比较的key不得抛出classCastException。主要用于存入数据的时候对数据进行自动排序,遍历时按照排序好的顺序进行输出;
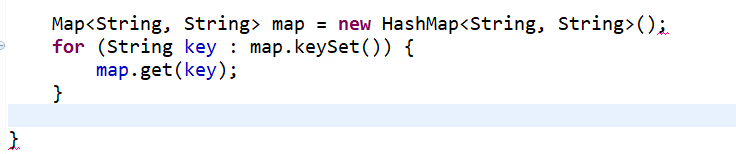
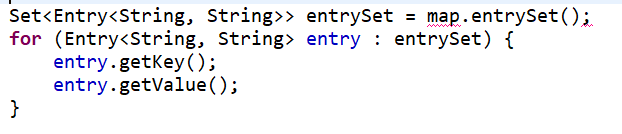
Map的四种遍历方式


- for each map.entrySet();
- 显示调用map.entrySet()的集合迭代器;
- for each map.keySet(),在调用get获得;
- for each map.entrySet()用临时变量保存map.entrySet();
总结
vector和ArrayList
- vector是线程同步,也是线程安全的,而ArrayList是线程异步,非线程安全的。如果不考虑的线程安全问题,建议使用ArrayList,效率会更高;
- 如果集合中的数据大于当下集合数组的长度时,vector增长率为目前数组长度的100%,而ArrayList的增长率为50%。如果在集合中使用数据量比较大的话,建议使用vector;
- vector和ArrayList底层实现都是基于数组,在查找指定位置的数据时,效率相差无几,但是又由于vector为线程安全,同ArrayList相比较慢一些,vector和ArrayList在进行增删的时候效率会比较低;
ArrayList和LinkedList
- ArrayList底层基于动态数组,而LinkedList底层基于链表的数据结构;
- 随机访问get和set,ArrayList效率高于LinkedList,因为LinkedList要移动指针;
- 对于增删操作,LinkedList效率更好,因为ArrayList底层是数组,增删需要移动数据(对单条数据进行操作效率高),LinkedList进行增删只是移动指针;
HashMap和Hashtable
- HashMap几乎可以等价于Hashtable,除了HashMap是非线程安全(synchronized)的,并可以接受一个null键,多个null值,但是Hashtable却不行;
- Hashtable是线程安全的(synchronized),多个线程可以共享一个Hashtable。而HashMap如果没有正确使用Synchronized的话,则多个线程不能共享一个HashMap。Java5提供了ConcurrentHashMap,它是Hashtable的替代,比Hashtable的替代性更好;
- 另一个却别是HashMap的迭代器(Iterator)是fail-fast迭代器,而Hashtable的迭代器(enumerator)迭代器不是fail-fast的。所以当其他线程改变了HashMap的结构时(增删操作),将会抛出ConcurrentModificationException,但是迭代器本身的remover()方法移除元素则不会抛出ConcurrentModificationException异常。
- 由于Hashtable是线程安全也是synchronized,所以在单线程环境下比HashMap要慢。如果不需要同步,只需要单一线程,使用HashMap要比Hashtable性能更好;
- HashMap同步方法:Map map = Collections.synchronizeMap(hashMap);