一样的钱,6倍的性能,就问你心不心动
“百度BigSQL可为用户提供高性能的即席查询服务,它需要大内存在计算节点本地缓存热数据,以减少DFS I/O对查询性能的影响。我们使用来自英特尔的傲腾持久内存,在缓存质量得到保证的同时,极大地提升了集群的处理能力,获得了明显的TCO收益。”
——百度资深系统工程师黎世勇
在近年来全球数据规模指数级增长的大背景下,如何满足用户对服务响应时间的要求成为了摆在众多企业,特别是科技企业面前的严峻挑战。别看只是响应晚一秒钟,但企业很有可能流失数以万计的客户,因此没有哪家企业敢对客户体验掉以轻心。
这也是顶级互联网企业百度面临的苦恼。用黎世勇的话说,客户体验是我们的第一KPI,响应时间是客户体验好不好最直接的体现之一。为此,百度这些年一直在寻找、尝试、开发更好的技术来改善用户体验。
本文要讲的百度联合英特尔进行的一系列技术创新,便是其为用户获得更好体验不断努力的一个缩影。
01
软硬一起抓
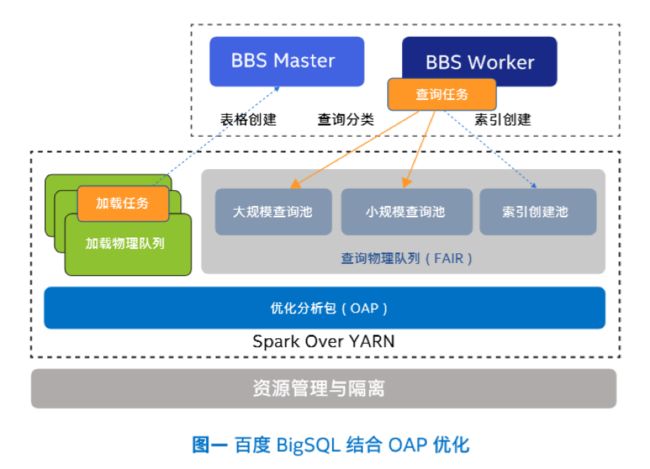
Apache Spark是大规模数据处理的快速通用计算引擎,当前应用极其广泛。Spark SQL模块是Apache Spark专门为大型数据中心结构化数据处理开发的功能模块。百度BigSQL数据处理平台基于Spark SQL开发,在性能上做了很多优化,开发了不少新功能。
交互式查询能力就是BigSQL在性能优化方面体现非常明显的一个例证。关于交互式查询的重要性,相信不用多解释了,服务响应快不快,跟它紧密相关。为实现次秒级的交互式查询响应,百度和英特尔在软硬两个层面都下了不少功夫。
软件层面,百度联合英特尔开展了Spark平台优化分析包(OAP)项目合作。其中,OAP 能很好地利用列式数据以及选定列上的用户定义索引,提高数据检索效率。与此同时,OAP还采用了细粒度的内存数据缓存策略,以此来消除磁盘和网络中的 I/O 瓶颈,将性能最大化。
硬件层面,百度与英特尔合作,利用英特尔傲腾持久内存替代部分DRAM,部署更具成本效益的解决方案。
百度内部测试显示,与使用传统纯内存的解决方案相比,使用傲腾持久内存可有效提高OAP的缓存性能及成本效益,大幅提升业务成效,例如帮助百度即席查询服务图灵减少工作负载、降低平均查询延时等。
具体如何实现的呢?两步走。
02
把常用的数据放在更快的存储里
OAP的核心是使用索引和缓存技术来加快交互式查询响应的速度。
当查询具有非常特定的筛选条件时,OAP可以在符合条件的列上创建索引。通过与列数据文件并排创建与存储完整的B+Tree索引,OAP可快速搜索B+Tree 索引来识别目标行,同时跳过后端存储(例如HDFS)上不必要的数据扫描。由于索引文件与原始数据文件保持分离,在创建或删除索引时均无需重写原始数据文件。
在此基础之上,OAP还借助缓存来优化索引和数据访问进程。通过将索引和数据缓存在内存中,来提升索引加载和数据扫描速度,缩短从分布式文件系统读取时磁盘和网络的I/O时间。此外,通过将索引和数据单独缓存,其缓存清除和内存空间管理实现了彼此独立。
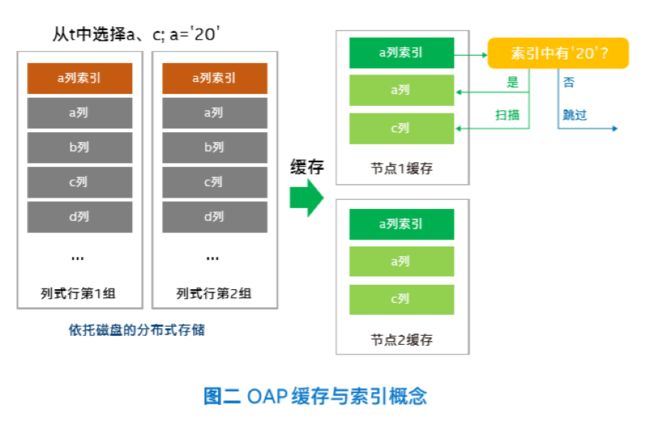
由于采用列式缓存,OAP 只需缓存查询所需的列。基于最近最少使用(LRU)策略,当缓存达到最大容量时,那些最近最少使用的数据项将被淘汰,为缓存最新数据释放空间。依照该策略,BigSQL启用了一个高级缓存管理器,可以主动填充热点列,并清除缓存中不再需要的列。
03
让更快的存储空间再大一点
显而易见,OAP的本质是将热数据放在更快的内存中,从而起到加速的目的。但由此也带来了新的问题:一、内存是不可能无限扩展的,二、超过一定内存容量后,成本是呈指数级上涨的。
这也是硬件层面采用傲腾持久内存的根本出发点。众所周知,傲腾持久内存是一种将高容量、经济实用性和数据持久性相结合的突破性技术,其拥有两大特点:一、大容量和更低的成本,二、适合顺序读。
进一步展开,傲腾持久内存拥有两种工作模式:内存模式和应用直接访问模式。在“内存模式”下,应用程序能利用傲腾持久内存作为扩展的易失性系统内存,无需重新编写软件,而DRAM将起到缓存的作用。在“应用直接访问模式”下,经过专门改进的应用程序可获得更大的持久性容量。
鉴于OAP缓存具有索引和输入数据的特定目的,因此OAP采用了“应用直接访问模式”。
为更好地利用傲腾持久内存代替 DRAM,英特尔还对OAP进行了扩展,加入内存管理器插件,并采用支持傲腾持久内存的内存管理器。这样一来,用户可以在DRAM和傲腾持久内存间自由切换,甚至两者兼用,例如使用 DRAM 缓存索引,而使用傲腾持久内存缓存数据。
除此之外,为确保傲腾持久内存与百度独特的OS环境无缝集成,百度还与英特尔在硬件、操作系统和库等领域进行了一系列合作优化。
04
6倍性能提升
为验证OAP项目及傲腾持久内存的性能表现,百度分两步进行了多次评估和内部测试:第一步是决策支持基准测试,第二步真实查询测试。
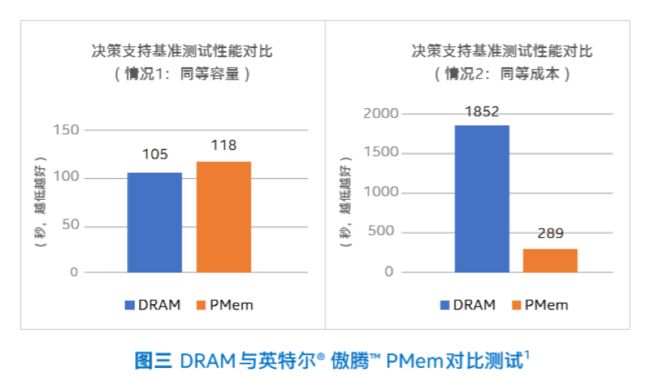
在决策支持基准测试中,首先将数据集大小控制为1TB,并使用相同容量的DRAM和傲腾持久内存。测试结果表明,两者都能容纳所有的缓存数据,傲腾持久内存的性能略微低于 DRAM(11.7%),但成本却明显更低。
当数据集达到 3TB,且使用相同成本的DRAM和傲腾持久内存时,前者的容量已不足以缓存所有数据。相比之下,傲腾持久内存不仅能缓存所有的数据,性能也超出DRAM 高达 6 倍。
此时的 DRAM 性能较差是因为:当数据规模大大超过缓存容量时,DRAM 需要频繁地从后端存储读取数据,由此延长了响应时间。决策支持基准测试清楚的表明,在成本相同的情况下,傲腾持久内存可提供比DRAM更高的容量和更出色的性能。
测试的第二阶段使用百度线上业务的真实查询数据,依然基于以上两种情况,但方法略有不同。在第一种情况下,DRAM和傲腾持久内存被设置为缓存50%的常用数据列, 此时PMem的缓存速度仅比DRAM低约12%,但由于成本优势更为显著,因此整体性价比更高。
在第二种情况下(即DRAM和傲腾持久内存成本相同),只有傲腾持久内存拥有足够容量来缓存所有热点数据,且性能较DRAM高出22%,同时避免了30%不要的底层系统I/O请求。
数据不会说谎,在百度BigSQL 中用傲腾持久内存取代DRAM显然是更具成本效益的缓存解决方案。目前,百度已在BigSQL中成功部署了傲腾持久内存,并以此为基础优化了百度即席查询服务图灵。在傲腾持久内存的加持下,图灵集群的工作负载降低了30%,平均查询延时降低了20%,每个傲腾持久内存服务器实例Spark/OAP的性能提高了50%,而成本仅增加了20%。
05
傲腾,还有更多用武之地
除了为Spark SQL输入数据提供缓存加速外,傲腾持久内存高容量和高带宽的优势还能在基于Spark的机器学习和深度学习场景中发挥更大作用,因为这些场景要求在规模庞大的数据集上反复进行多次计算。另外,Spark shuffle可以通过优化,使用RDMA技术访问远程节点上的傲腾持久内存并将其用作随机存储,进一步减少随机延迟并提高性能。
未来,百度也将与英特尔携手为Spark进行一系列更深度的优化。
事实上,不仅是Spark,包括Redis、Oracle、Aerospike等或开源、或商业软件通过使用傲腾持久内存都有不同程度的性能提升、成本下降,无数的客户已经从中受益。
总结全文,数字世界正在来临,数据爆炸式增长给企业带来了新的挑战,当下企业不仅要有能力处理大量增长的数据,而且要更快速的处理这些数据。这是傲腾的价值所在,提供更快速度的同时,还让你负担得起。
