实习面经-京东广告部门-数据研发
面试部门–京东广告部门
笔者目前研二网络空间安全硕士在读,按照实验室往年的惯例,这个寒假过后就要准备投实习岗位了(当然是越早准备越好)。我们实验室今年1.10号以后就可以回家了,那会儿看到一位同学发的推荐贴,就试着投了下京东的广告部门。很快就接到部门leader电话,约定1.15下午面试,其实这个时间是可以商量的,要是觉得自己准备的不是太充分,可以往后顺延。
学习路程
简要说下自己的学习路程。
现阶段使用Python最多,在研一第一学期主要熟悉了hadoop大数据平台,第二学期对平台上的一些组件有了一定了解,如:Spark,HDFS,Hive;第三学期学习Spark编程。由于Spark使用Scala编写,有时为了追踪源码,学习模仿高手的编程方法及习惯,这就要求学习Spark需得掌握Scala语言。当然Spark对于Java,Python也是支持的,只是用Java语言来编写有点繁琐,而部分Api Python并不支持。
许多读者可能并不了解Scala语言,这里简单提一下。
Scala的设计者---- 马丁·奥德斯基设计这门语言的初衷是想人民在高效、简洁、轻松的环境下来写代码,也就是有事没事来写写代码放松(这和国内的996不符合,生活太累了)。Scala语法细碎,灵活,将函数当做“一等公民”来对待,同时几乎支持Java所有的接口,也是将编译后的字节码放在JVM上运行。语法细碎使得学习成本较高,当然也正是这些语法使得scala异常强大。想要深入了解Spark,很有必要学习下Scala,毕竟市面上的许多教材及课程都是用Scala讲解。
面试过程
谈项目
直接从项目聊起,谈所用过的算法
1.谈一谈xgboost与随机森林算法有何不同?
面试官忽略我的第一个项目,直接问第二个和算法相关。后来得知他们部门比较注重算法。
其实我本身对算法不是很熟悉,一般只是拿过来用。
2.数据集如何划分?项目中所用的某一个算法与同类算法相比,效果如何?
答:一般我们会将数据集划分为训练集和测试集,训练集用来训练一个模型,测试集用来判断训练出的模型的准确率。第二个问题不怎么会,试着回来了下。
与Spark相关
3.熟悉Spark中哪些算子?问了join属于哪一类算子。
答:总体上分为转化算子和行动算子。熟悉常几个用的算子,如:map,flatMap,groupByKey,reduceByKey;count,collect,take,reduce。
这一块是Spark的核心计算部分,需要熟悉。
4.遇到数据倾斜如何处理?
不熟悉。和面试官简单的聊了下,给了些提醒,还是不能很好的回答。完事后查了下,记录下来争取弄明白。
Spark在计算过程中会将数据读到多个分区来处理,若大部分数据跑到某一个分区,导致分区内的数据不均匀,容易使得数据倾斜。
如“木桶原理”一样,总的计算时间取决于运行时间最长的分区,数据倾斜是Spark运算要尽力避免的问题。
解决方案
5.缓存机制?
答:cache 和persist。若如果追踪到源码cache方法也是调用的persist。persist方法中的参数选择空间更大,如:

6.一个分区如何转换为多个分区?
答:常见的三种方案要熟悉。集合创建;外部数据集创建;RDD转换。
7.谈一谈宽依赖与窄依赖以及stage划分。
答:窄依赖指的是每一个父RDD的Partition最多被子RDD的一个Partition使用,窄依赖我们形象的比喻为独生子女;
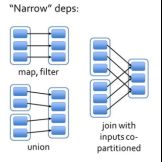
宽依赖指的是多个子RDD的Partition会依赖同一个父RDD的Partition,会引起shuffle,总结:宽依赖我们形象的比喻为超生
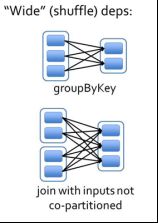
遇到宽依赖会划分一个阶段:

8.运行Spark程序后计算机资源耗费如何?
这个根据自己的实际了解的情况答就行,在我们使用spark-submit提交程序时肯定会进行相关配置。如:spark-submit --executor-cores 8 --class com.spark.learning.SparkTraining WordCount-1.0-SNAPSHOT.jar
- yarn 模式提交
spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client ./spark-examples_2.11-2.4.3.jar 100
- local模式
spark-submit --class org.apache.spark.examples.SparkPi ./spark-examples_2.11-2.4.3.jar 100
若是看过相关源码,那是最好的了。
与数据结构相关
- 说一下常用的排序算法
冒泡、简单选择、直接插入排序,希尔排序,堆排序,归并排序,快速排序;
了解时间复杂度及空间复杂度
这是重点,不管在哪儿面都绕不开,需要熟练掌握。
与Linux相关
需要熟悉常用的指令。
10. 问了一些常用的命令;
如:将一个文件的前n行数字进行排序
cat命令用过没?
笔试题
- 题目:跳台阶。
讲清楚思路,然后写。
1)递归完成
这时会问,该方法的效率如何。还有没其他方法呢?答:循坏完成。
2)循坏
分析两种方法的时间复杂度,给出判断。
注:他们是广告部门,主要用的是召回,排序算法;本想着重问算法方面的知识储备。
全程大约不到70min,聊的还行,比我想象中要好得多,毕竟第一次面。不论结果如何,权当攒一次经验。接下来还得在面其他的,我也会记录下不同的面试题型及问题与大家分享。
从一名不羁的码农开始
