MySQL高级应用
一、索引
1.1、什么是索引
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构,可以得到索引的本质,索引是一种数据结构。
你可以简单的理解为索引是排好序的快速查找数据结构
一般来说,索引本身也很大,不可能全部存储在内存中。因此索引往往以索引文件的形式存储在磁盘上,我们平成所说的索引,如果没有特别指明,都是B树(多路搜索树,并不一定是二叉树)结构组织的索引。
1.2、索引的数据结构
-
BTREE
B树(Balance Tree多路平衡查找树)
-
Hash索引
-
full-text全文索引
-
R-Tree索引
1.3、索引的分类
-
单值索引
即一个索引只包含单个列,一个表可以有多个单列索引
-
唯一索引
索引的值必须唯一,但允许有空值
UNIQUE KEY
-
复合索引
即一个索引包含多个列
基本语法
创建索引
CREATE [UNIQUE] INDEX indexName ON mytable(col1,col2,clo3...)
删除
DROP INDEX [indexName] ON mytable
查看
SHOW INDEX FROM table_name\G
1.5、EXPLAIN关键字
1.5.1、概述
使用EXPLAIN关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的。分析你的查询语句或是表结构的想能瓶颈。
1.5.2、作用
- 表的读取顺序
- 数据读取操作的操作类型
- 哪些索引可以使用
- 那些索引被实际使用
- 表之间的引用
- 每张表有多少行被优化器查询
1.5.3、EXPLAIN + SQL语句
执行计划包含的信息
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cz6AhFgP-1581135809953)(C:\Users\ZC\Desktop\MySQL高级应用\QQ截图20200207034033.png)]
在上图中,就是我们使用了EXPLAIN关键字后,查询出的结果。
下面我们一一来介绍下他们都代表什么含义。
1.5.4、EXPLAIN性能指标参数
1.5.4.1、id
- select查询的序列号,包含一组数字。表示查询中执行select自重或操作表的顺序。
- 其中共有三种情况:
- d相同,执行顺序由上至下。
- id不同,如果是子查询,id的序号会递增。id的值越大,优先级越高。越先执行。
- id相同不同,同时存在
1.5.4.2、select_type
分类:
-
simple :
简单的select查询,查询中不包含子查询或者UNION
-
primary :
按照主键查询
-
SUNQUERY:
子查询
-
DERIVED:
衍生查询,在from列表中包含的子查询被标记为DERIVED(衍生)MySQL会递归执行这些子查询,把结果放在临时表里。
-
UNION:
若第二个SELECT出现在UNION之后,则被标记为UNION,若UNION包含在FROM子句的子查询中,外层SELECT将被标记为:DERIVED
-
UNION RESULT:
从UNION表获取结果的SELECT
1.5.4.3、table
显示这一行的数据是关于哪张表的
1.5.4.4、type
显示查询使用了何种索引类型
从最好到最差依次为:
system > const > eq_ref > ref > range >index > ALL
- system:
表只有一行记录,这是const类型的特列
-
const:
按索引字段的值进行条件查询
-
eq_ref:
唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见于主键或唯一索引扫描。
- ref:
非唯一性索引扫描,返回匹配某个单独值得所有行。
本质上也是一种索引访问,它返回所有匹配某个单独值的行,然而,它可能会找到多个符合条件的行,所以他应该属于查找和扫描的混合体。
- range:
范围查询,比如id字段上存在索引。
select * from user where id < 10
以上sql就是range类型的查询。
也就是说当我们查询的时候,它会把所有的id拿出来筛选小于10的数据。
- index:
select id from user
id字段存在索引,遍历索引树。所以就是index类型。效率比全表扫描略高。
- ALL:
全表扫描,没有用到索引。
一般我们再查询时,建议类型一般在range级别以上。
1.5.4.5、possiable_keys
显示可能应用在这张表中的索引,一个或者多个。
查询涉及到的字段上所存在索引,则该索引将被列出。单不一定被查询实际使用
1.5.4.5、key
实际使用的的索引,如果为null,则没有使用索引
查询中若使用了覆盖索引,则该索引和查询的select字段重叠
1.5.4.5、key_len
查询索引字段的长度
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JnKGzZ3L-1581135809954)(C:\Users\ZC\Desktop\QQ截图20200208064617.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-riZ4L7K4-1581135809954)(C:\Users\ZC\Desktop\QQ截图20200208064825.png)]
如果查询的字段为varchar类型
因为一般情况下我们使用utf-8编码,每个字符占3个字节
那么key_len = 3 (utf-8) * 该字段最大长度 + 1(允许为null) + 2(varchar类型会空出两个字节存储该字段的长度)
所以上图 63 = 3 * 20 + 1 + 2;
通过以上分析,我们设计数据库表的时候,设置字段的最大长度也会影响数据库查询的性能。所以通常以够用为原则。尽量不要设置成最大长度。
1.5.4.6、key_len
显示索引的那一列被使用了,如果是常量则为const
1.5.4.7、rows
每次查询的行数
1.5.4.7、Extra
- Using filesort:
我们先来创建一张表
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-P1VK9wGC-1581135809954)(C:\Users\ZC\Desktop\QQ截图20200208074240.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zHT2h67o-1581135809955)(C:\Users\ZC\Desktop\QQ截图20200208074342.png)]
为这三个字段创建一个联合索引
然后查询
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gAQ7sxfP-1581135809955)(C:\Users\ZC\Desktop\QQ截图20200208075147.png)]
我们可以清楚的看到在extra字段中出现了一个using filesort .
这是什么意思呢,就是说我们在查询出结果后使用了order by字段 ,所以在查询出所有的结果后,又会对它重新进行一次排序,所以就出现了using filesort这个信息。然后重新排序会对查询效率有严重影响。所以往往我们在查询时,应尽量避免重新排序。
怎么解决呢?我们可以充分的利用索引来实现
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-m2zR3m5E-1581135809956)(C:\Users\ZC\Desktop\QQ截图20200208075256.png)]
将排序条件换一个位置,这样就没有了,查询条件一一对应索引的顺序,这样查询出来的结果正好是排好序的结果,所以就不会再次排序了。这里的重点就是充分利用索引。所以我们在建立复合索引时,尽量考虑好顺序问题。比如name,age的先后顺序,利于排序时充分利用索引。
-
using temporary:
这个信息跟上面差不多
例如:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EOyH6Y9J-1581135809956)(C:\Users\ZC\Desktop\QQ截图20200208082137.png)]
EXPLAIN SELECT name from test_index where name in ('小明','小李') GROUP BY age上述查询中即出现了using temporary,也出现了Using filesort,可以说效率很低,没有充分利用索引。
而using temporary的意思就是在查询出结果后,按年龄进行分组时,又重新分配了临时空间去分组。
解决的办法还是充分利用索引
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-v3UpMTi2-1581135809956)(C:\Users\ZC\Desktop\QQ截图20200208082624.png)]
EXPLAIN SELECT name from test_index where name in ('小明','小李') GROUP BY name,age
即按复合索引顺序加上索引字段即可。
如何注意索引优化:
1.sql语句的优化
2.创建索引时,要尽量考虑到索引的使用,复合索引在建立和使用时,尽量考虑在用户应用查询时,常用的排序方向和字段组合顺序。
1.6、索引失效问题
在查询时,我们应尽量避免索引失效问题
- 在查询时,尽量使用全值匹配,特别是在使用复合索引时。
- 最佳左前缀法则: 如果索引了多列,要遵守最左前缀法则,指的是查询从索引的最左前列开始,不跳过索引中间的列
- 不在索引上做任何操作(计算,函数,自动或手动类型转换),会导致索引失效转向全表扫描。
- 存储引擎不能使用索引中范围条件最右边的列,范围条件右侧索引会全部失效。
- 尽量使用覆盖索引(只访问索引的查询(索隐列和查询列一直)),尽量避免 select * 操作。
- mysql 在使用 != 或<>时有时候无法使用索引会导致全表扫描。
- 注意null/not null对索引可能的影响
- like 以通配符开头,mysql索引会失效变成全表扫描。
- 字符串不加单引号索引会失效
- 尽量避免使用or关键字,使用or也会导致索引失效。
二、MySQL的锁
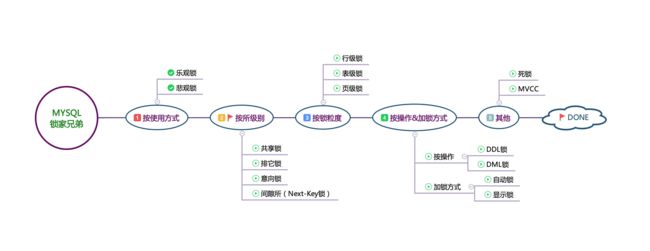
2.1、悲观锁和乐观锁
- 悲观锁(Pessimistic Lock):
悲观锁的特点是先获取锁,再进行业务操作,即“悲观”的认为获取锁是非常有可能失败的,因此要先确保获取锁成功再进行业务操作。通常所说的“一锁二查三更新”即指的是使用悲观锁。通常来讲在数据库上的悲观锁需要数据库本身提供支持,即通过常用的select … for update操作来实现悲观锁。当数据库执行select for update时会获取被select中的数据行的行锁,因此其他并发执行的select for update如果试图选中同一行则会发生排斥(需要等待行锁被释放),因此达到锁的效果。select for update获取的行锁会在当前事务结束时自动释放,因此必须在事务中使用。
这里需要注意的一点是不同的数据库对select for update的实现和支持都是有所区别的,例如oracle支持select for update no wait,表示如果拿不到锁立刻报错,而不是等待,mysql就没有no wait这个选项。另外mysql还有个问题是select for update语句执行中所有扫描过的行都会被锁上,这一点很容易造成问题。因此如果在mysql中用悲观锁务必要确定走了索引,而不是全表扫描。
-
乐观锁(Optimistic Concurrency Control)
在关系数据库管理系统里,乐观并发控制(又名“乐观锁”,缩写“OCC”)是一种并发控制的方法。它假设多用户并发的事务在处理时不会彼此互相影响,各事务能够在不产生锁的情况下处理各自影响的那部分数据。在提交数据更新之前,每个事务会先检查在该事务读取数据后,有没有其他事务又修改了该数据。如果其他事务有更新的话,正在提交的事务会进行回滚。乐观事务控制最早是由孔祥重(H.T.Kung)教授提出。
高并发环境下的库存超卖问题:
在高并发情况下,多个人同时抢购一个库存时,由于数据库的读写操作可以并行执行的原因,会导致在修改库存是,库存不足,出现超卖现象。用锁将查询库存的操作和写入库存的操作互斥。
悲观锁解决库存问题:在查询时,将查询语句加入一个行所,和库存更新的语句互斥,可以保证在查询时库存不被修改。
乐观锁解决库存问题: 在查询时,加入一个版本字段,每次更新,同时查询和更新版本字段,如果版本字段发生变化,则sql语句不会执行成功。
select num,version from sku where skuId = ?
update sku set num - 1,version = version + 1 where skuId = ? and version = version

2.2、共享锁和排他锁
按对数据的操作类型划分(读、写)划分,锁分为共享锁和排他锁
- 共享锁:
针对同一份数据,多个读操作之间可以同时进行,而不会互相影响
-
排他锁:
当前写操作没有完成时,他会阻断其他共享锁和排他锁。
2.3、表锁和行锁
- 表锁
1.在偏读型数据库中使用表锁。如MyISM数据库。
加锁命令:
lock TABLE user READ;
这时该表已经加上了一个读锁,也就是共享锁。共享锁与排他锁(写锁)互斥。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dFkJROHc-1581135809958)(C:\Users\ZC\Desktop\QQ截图20200208102525.png)]
当我们进行了写操作之后,可以发现该该表正在处理中,并没有马上提交
UNLOCK TABLES;
只有在解锁命令执行之后,数据才会进行更新。
lock table user write
加写锁命令。
写锁与读锁和其他写锁都会互斥。
特征:
读和读可以共享
读和写阻塞
写和写阻塞
- 行锁
我们所熟知的事务就是基于行锁
例如:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OTEbsypH-1581135809958)(C:\Users\ZC\Desktop\QQ截图20200208104523.png)]
开启事务,并更新一条数据
再继续更新该条数据
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Av5qzrul-1581135809958)(C:\Users\ZC\Desktop\QQ截图20200208104644.png)]
正在等待,就是因为该条数据没有提交事务,被加了行锁。
只有在事务提交之后,该条语句才会执行。
加行锁的方式:
select name from user where id = 1 for update
这时其他事务就不能查询和修改该条数据
查询时加行锁,避免查询和更新同时发生,导致读到的数据发生不可重复读。
行锁可以让读读互斥,可以避免在查询数据时,数据已经被修改的情况发生。
2.4、锁的常见问题
1.在无索引操作时,注意锁的升级(行锁会升级为表锁)
间隙锁:
当我们用范围条件而不是相等条件时检索数据时,并请求共享或排他锁时,InnoDB会给符合条件的已有数据记录的索引项加锁,对于键值在条件范围内,但并不存在的记录,叫做“间隙”,InnoDB也会对这个“间隙”加锁,这种锁的机制就是所谓的间隙锁(Next-key锁)。
例如:
update user set name = '张三' where id > 1 and id < 5
insert into user (id,name) values(2,'李四')
在一个事务中,如果进行了范围查询,则该范围内的所有数据都会被锁定,即使范围内有些数据并不存在,比如id为2的数据并不存在,但是也会插入失败。
优化:
- 尽可能让所有数据检索都通过索引来完成,避免无索引行锁升级为表锁。
- 合理设计索引,尽量缩小锁的范围
- 尽可能较少检索条件,避免间隙锁
- 尽量控制事务大小,减少锁定资源量和时间长度
- 尽可能降低事务隔离级别
页锁
开销和加锁时间介于表锁和行锁之间,会出现死锁,锁粒度介于表锁和行锁之间,并发度一般。
2.5、死锁

死锁一般是事务相互等待对方资源,最后形成环路造成的。与多线程死锁类似。
解决方案:
(1)在应用中,如果不同的程序会并发存取多个表,应尽量约定以相同的顺序来访问表,这样可以大大降低产生死锁的机会。
(2)在程序以批量方式处理数据的时候,如果事先对数据排序,保证每个线程按固定的顺序来处理记录,也可以大大降低出现死锁的可能。
(3)在事务中,如果要更新记录,应该直接申请足够级别的锁,即排他锁,而不应先申请共享锁,更新时再申请排他锁,因为当用户申请排他锁时,其他事务可能又已经获得了相同记录的共享锁,从而造成锁冲突,甚至死锁。
如果出现死锁,可以用mysql> show engine innodb status\G命令来确定最后一个死锁产生的原因。返回结果中包括死锁相关事务的详细信息,如引发死锁的SQL语句,事务已经获得的锁,正在等待什么锁,以及被回滚的事务等。据此可以分析死锁产生的原因和改进措施。
总结:MySQL innodb引擎的锁机制比myisam引擎机制复杂,但是innodb引擎支持更细粒度的锁机制,当然也会带来更多维护的代价;然后innodb的行级别是借助对索引项加锁实现的,值得注意的事如果表没有索引,那么就会上表级别的锁,同时借助行级锁中gap锁来解决部分幻读的问题。只要知道MySQL innodb中的锁的机制原理,那么再解决死锁或者避免死锁就会很容易!