这篇文章介绍prometheus和alertmanager的报警和通知规则,prometheus的配置文件名为prometheus.yml,alertmanager的配置文件名为alertmanager.yml
报警:指prometheus将监测到的异常事件发送给alertmanager,而不是指发送邮件通知
通知:指alertmanager发送异常事件的通知(邮件、webhook等)
报警规则
在prometheus.yml中指定匹配报警规则的间隔
# How frequently to evaluate rules.
[ evaluation_interval: | default = 1m ]
在prometheus.yml中指定规则文件(可使用通配符,如rules/*.rules)
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "/etc/prometheus/alert.rules"
并基于以下模板:
ALERT
IF
[ FOR ]
[ LABELS 其中:
Alert name是警报标识符。它不需要是唯一的。
Expression是为了触发警报而被评估的条件。它通常使用现有指标作为/metrics端点返回的指标。
Duration是规则必须有效的时间段。例如,5s表示5秒。
Label set是将在消息模板中使用的一组标签。
在prometheus-k8s-statefulset.yaml 文件创建ruleSelector,标记报警规则角色。在prometheus-k8s-rules.yaml 报警规则文件中引用
ruleSelector:
matchLabels:
role: prometheus-rulefiles
prometheus: k8s
在prometheus-k8s-rules.yaml 使用configmap 方式引用prometheus-rulefiles
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-k8s-rules
namespace: monitoring
labels:
role: prometheus-rulefiles
prometheus: k8s
data:
pod.rules.yaml: |+
groups:
- name: noah_pod.rules
rules:
- alert: Pod_all_cpu_usage
expr: (sum by(name)(rate(container_cpu_usage_seconds_total{image!=""}[5m]))*100) > 10
for: 5m
labels:
severity: critical
service: pods
annotations:
description: 容器 {{ $labels.name }} CPU 资源利用率大于 75% , (current value is {{ $value }})
summary: Dev CPU 负载告警
- alert: Pod_all_memory_usage
expr: sort_desc(avg by(name)(irate(container_memory_usage_bytes{name!=""}[5m]))*100) > 1024*10^3*2
for: 10m
labels:
severity: critical
annotations:
description: 容器 {{ $labels.name }} Memory 资源利用率大于 2G , (current value is {{ $value }})
summary: Dev Memory 负载告警
- alert: Pod_all_network_receive_usage
expr: sum by (name)(irate(container_network_receive_bytes_total{container_name="POD"}[1m])) > 1024*1024*50
for: 10m
labels:
severity: critical
annotations:
description: 容器 {{ $labels.name }} network_receive 资源利用率大于 50M , (current value is {{ $value }})
summary: network_receive 负载告警
配置文件设置好后,prometheus-opeartor自动重新读取配置。
如果二次修改comfigmap 内容只需要apply
kubectl apply -f prometheus-k8s-rules.yaml
将邮件通知与rules对比一下(还需要配置alertmanager.yml才能收到邮件)

通知规则
设置alertmanager.yml的的route与receivers
global:
# ResolveTimeout is the time after which an alert is declared resolved
# if it has not been updated.
resolve_timeout: 5m
# The smarthost and SMTP sender used for mail notifications.
smtp_smarthost: 'xxxxx'
smtp_from: 'xxxxxxx'
smtp_auth_username: 'xxxxx'
smtp_auth_password: 'xxxxxx'
# The API URL to use for Slack notifications.
slack_api_url: 'https://hooks.slack.com/services/some/api/token'
# # The directory from which notification templates are read.
templates:
- '*.tmpl'
# The root route on which each incoming alert enters.
route:
# The labels by which incoming alerts are grouped together. For example,
# multiple alerts coming in for cluster=A and alertname=LatencyHigh would
# be batched into a single group.
group_by: ['alertname', 'cluster', 'service']
# When a new group of alerts is created by an incoming alert, wait at
# least 'group_wait' to send the initial notification.
# This way ensures that you get multiple alerts for the same group that start
# firing shortly after another are batched together on the first
# notification.
group_wait: 30s
# When the first notification was sent, wait 'group_interval' to send a batch
# of new alerts that started firing for that group.
group_interval: 5m
# If an alert has successfully been sent, wait 'repeat_interval' to
# resend them.
#repeat_interval: 1m
repeat_interval: 15m
# A default receiver
# If an alert isn't caught by a route, send it to default.
receiver: default
# All the above attributes are inherited by all child routes and can
# overwritten on each.
# The child route trees.
routes:
- match:
severity: critical
receiver: email_alert
receivers:
- name: 'default'
email_configs:
- to : '[email protected]'
send_resolved: true
- name: 'email_alert'
email_configs:
- to : '[email protected]'
send_resolved: true
名词解释
Route
route属性用来设置报警的分发策略,它是一个树状结构,按照深度优先从左向右的顺序进行匹配。
// Match does a depth-first left-to-right search through the route tree
// and returns the matching routing nodes.
func (r *Route) Match(lset model.LabelSet) []*Route {
Alert
Alert是alertmanager接收到的报警,类型如下。
// Alert is a generic representation of an alert in the Prometheus eco-system.
type Alert struct {
// Label value pairs for purpose of aggregation, matching, and disposition
// dispatching. This must minimally include an "alertname" label.
Labels LabelSet `json:"labels"`
// Extra key/value information which does not define alert identity.
Annotations LabelSet `json:"annotations"`
// The known time range for this alert. Both ends are optional.
StartsAt time.Time `json:"startsAt,omitempty"`
EndsAt time.Time `json:"endsAt,omitempty"`
GeneratorURL string `json:"generatorURL"`
}
具有相同Lables的Alert(key和value都相同)才会被认为是同一种。在prometheus rules文件配置的一条规则可能会产生多种报警
Group
alertmanager会根据group_by配置将Alert分组。如下规则,当go_goroutines等于4时会收到三条报警,alertmanager会将这三条报警分成两组向receivers发出通知。
ALERT test1
IF go_goroutines > 1
LABELS {label1="l1", label2="l2", status="test"}
ALERT test2
IF go_goroutines > 2
LABELS {label1="l2", label2="l2", status="test"}
ALERT test3
IF go_goroutines > 3
LABELS {label1="l2", label2="l1", status="test"}
主要处理流程
-
接收到Alert,根据labels判断属于哪些Route(可存在多个Route,一个Route有多个Group,一个Group有多个Alert)
-
将Alert分配到Group中,没有则新建Group
-
新的Group等待group_wait指定的时间(等待时可能收到同一Group的Alert),根据resolve_timeout判断Alert是否解决,然后发送通知
-
已有的Group等待group_interval指定的时间,判断Alert是否解决,当上次发送通知到现在的间隔大于repeat_interval或者Group有更新时会发送通知
Alertmanager
Alertmanager是警报的缓冲区,它具有以下特征:
可以通过特定端点(不是特定于Prometheus)接收警报。
可以将警报重定向到接收者,如hipchat、邮件或其他人。
足够智能,可以确定已经发送了类似的通知。所以,如果出现问题,你不会被成千上万的电子邮件淹没。
Alertmanager客户端(在这种情况下是Prometheus)首先发送POST消息,并将所有要处理的警报发送到/ api / v1 / alerts。例如:
[
{
"labels": {
"alertname": "low_connected_users",
"severity": "warning"
},
"annotations": {
"description": "Instance play-app:9000 under lower load",
"summary": "play-app:9000 of job playframework-app is under lower load"
}
}]
alert工作流程
一旦这些警报存储在Alertmanager,它们可能处于以下任何状态:
-
Inactive:这里什么都没有发生。
-
Pending:客户端告诉我们这个警报必须被触发。然而,警报可以被分组、压抑/抑制或者静默/静音。一旦所有的验证都通过了,我们就转到Firing。
-
Firing:警报发送到Notification Pipeline,它将联系警报的所有接收者。然后客户端告诉我们警报解除,所以转换到状Inactive状态。
Prometheus有一个专门的端点,允许我们列出所有的警报,并遵循状态转换。Prometheus所示的每个状态以及导致过渡的条件如下所示:
规则不符合。警报没有激活。
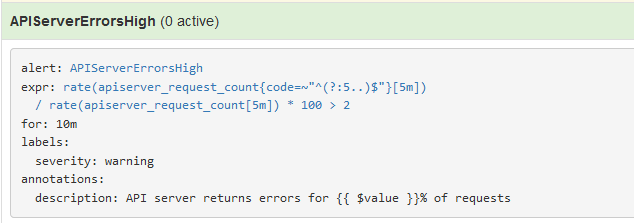
规则符合。警报现在处于活动状态。 执行一些验证是为了避免淹没接收器的消息。
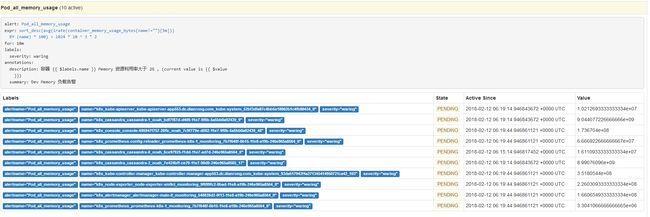
警报发送到接收者
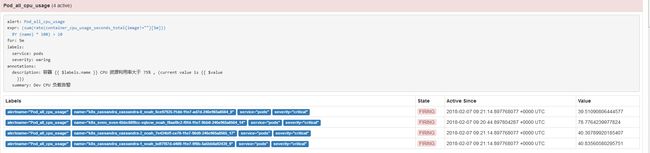
接收器 receiver
顾名思义,警报接收的配置。
通用配置格式
# The unique name of the receiver.
name:
# Configurations for several notification integrations.
email_configs:
[ -
pagerduty_configs:
[ -
slack_config:
[ -
opsgenie_configs:
[ -
webhook_configs:
[ -
邮件接收器 email_config
# Whether or not to notify about resolved alerts.
[ send_resolved:
# The email address to send notifications to.
to:
# The sender address.
[ from:
# The SMTP host through which emails are sent.
[ smarthost:
# The HTML body of the email notification.
[ html:
# Further headers email header key/value pairs. Overrides any headers
# previously set by the notification implementation.
[ headers: {
Slack接收器 slack_config
# Whether or not to notify about resolved alerts.
[ send_resolved:
# The Slack webhook URL.
[ api_url:
# The channel or user to send notifications to.
channel:
# API request data as defined by the Slack webhook API.
[ color:
[ username:
[ title:
[ title_link:
[ pretext:
[ text:
[ fallback:
Webhook接收器 webhook_config
# Whether or not to notify about resolved alerts.
[ send_resolved:
# The endpoint to send HTTP POST requests to.
url:
Alertmanager会使用以下的格式向配置端点发送HTTP POST请求:
{
"version": "2",
"status": "
"alerts": [
{
"labels":
Inhibition
抑制是指当警报发出后,停止重复发送由此警报引发其他错误的警报的机制。
例如,当警报被触发,通知整个集群不可达,可以配置Alertmanager忽略由该警报触发而产生的所有其他警报,这可以防止通知数百或数千与此问题不相关的其他警报。
抑制机制可以通过Alertmanager的配置文件来配置。
Inhibition允许在其他警报处于触发状态时,抑制一些警报的通知。例如,如果同一警报(基于警报名称)已经非常紧急,那么我们可以配置一个抑制来使任何警告级别的通知静音。 alertmanager.yml文件的相关部分如下所示:
inhibit_rules:- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['low_connected_users']
配置抑制规则,是存在另一组匹配器匹配的情况下,静音其他被引发警报的规则。这两个警报,必须有一组相同的标签。
# Matchers that have to be fulfilled in the alerts to be muted.
target_match:
[ : , ... ]
target_match_re:
[ : , ... ]
# Matchers for which one or more alerts have to exist for the
# inhibition to take effect.
source_match:
[ : , ... ]
source_match_re:
[ : , ... ]
# Labels that must have an equal value in the source and target
# alert for the inhibition to take effect.
[ equal: '[' , ... ']' ]
Silences
Silences是快速地使警报暂时静音的一种方法。 我们直接通过Alertmanager管理控制台中的专用页面来配置它们。在尝试解决严重的生产问题时,这对避免收到垃圾邮件很有用。
alertmanager 参考资料
抑制规则 inhibit_rule参考资料
https://www.kancloud.cn/huyipow/prometheus/527563