Kubernetes 系列之 Kubernetes 数据卷
一、Kubernetes 数据卷准备阶段
1 概述
在 Docker 中就有数据卷的概念,当容器删除时,数据也一起会被删除,想要持久化使用数据,需要把主机上的目录挂载到 Docker 中去,在 K8S 中,数据卷是通过 Pod 实现持久化的,如果 Pod 删除,数据卷也会一起删除,k8s 的数据卷是 docker 数据卷的扩展,K8S 适配各种存储系统,包括本地存储 EmptyDir,HostPath, 网络存储(NFS,GlusterFS,PV/PVC)等。
我们以部署 MySQL8 为例,采用 NFS + PV/PVC 网络存储方案实现我们的 Kubernetes 数据持久化。
2 什么是 NFS
NFS 是 Network File System 的简写,即网络文件系统,NFS 是 FreeBSD 支持的文件系统中的一种。NFS 基于 RPC (Remote Procedure Call) 远程过程调用实现,其允许一个系统在网络上与它人共享目录和文件。通过使用 NFS,用户和程序就可以像访问本地文件一样访问远端系统上的文件。NFS 是一个非常稳定的,可移植的网络文件系统。具备可扩展和高性能等特性,达到了企业级应用质量标准。由于网络速度的增加和延迟的降低,NFS 系统一直是通过网络提供文件系统服务的有竞争力的选择 。
2.1 NFS 原理
NFS 使用 RPC (Remote Procedure Call) 的机制进行实现,RPC 使得客户端可以调用服务端的函数。同时,由于有 VFS 的存在,客户端可以像使用其它普通文件系统一样使用 NFS 文件系统。经由操作系统的内核,将 NFS 文件系统的调用请求通过 TCP/IP 发送至服务端的 NFS 服务。NFS 服务器执行相关的操作,并将操作结果返回给客户端。
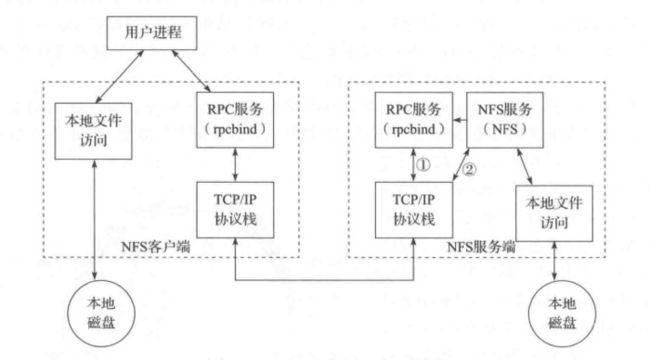
2.2 NFS 服务主要进程
- rpc.nfsd:最主要的 NFS 进程,管理客户端是否可登录
- rpc.mountd:挂载和卸载 NFS 文件系统,包括权限管理
- rpc.lockd:非必要,管理文件锁,避免同时写出错
- rpc.statd:非必要,检查文件一致性,可修复文件
2.3 NFS 的关键工具
- 主要配置文件:
/etc/exports - NFS 文件系统维护命令:
/usr/bin/exportfs - 共享资源的日志文件:
/var/lib/nfs/*tab - 客户端查询共享资源命令:
/usr/sbin/showmount - 端口配置:
/etc/sysconfig/nfs
2.4 NFS 服务端配置
在 NFS 服务器端的主要配置文件为 /etc/exports 时,通过此配置文件可以设置共享文件目录。每条配置记录由 NFS 共享目录、NFS 客户端地址和参数这 3 部分组成,格式如下:
[NFS 共享目录] [NFS 客户端地址 1 (参数 1, 参数 2, 参数 3……)] [客户端地址 2 (参数 1, 参数 2, 参数 3……)]
- NFS 共享目录:服务器上共享出去的文件目录
- NFS 客户端地址:允许其访问的 NFS 服务器的客户端地址,可以是客户端 IP 地址,也可以是一个网段 (192.168.141.0/24)
- 访问参数:括号中逗号分隔项,主要是一些权限选项
2.4.1 访问权限参数
| 序号 | 选项 | 描述 |
|---|---|---|
| 1 | ro | 客户端对于共享文件目录为只读权限。默认 |
| 2 | rw | 客户端对于共享文件目录具有读写权限 |
2.4.2 用户映射参数
| 序号 | 选项 | 描述 |
|---|---|---|
| 1 | root_squash | 使客户端使用 root 账户访冋时,服务器映射为服务器本地的匿名账号 |
| 2 | no_root_squash | 客户端连接服务端时如果使用的是 root,那么也拥有对服务端分享的目录的 root 权限 |
| 3 | all_squash | 将所有客户端用户请求映射到匿名用户或用户组(nfsnobody) |
| 4 | no_all_squash | 与上相反。默认 |
| 5 | anonuid=xxx | 将远程访问的所有用户都映射为匿名用户,并指定该用户为本地用户(UID=xxx) |
| 6 | anongid=xxx | 将远程访问的所有用户组都映射为匿名用户组账户,并指定该匿名用户组账户为本地用户组账户(GUI=xxx) |
2.4.3 其它配置参数
| 序号 | 选项 | 描述 |
|---|---|---|
| 1 | sync | 同步写操作,数据写入存储设备后返回成功信息。默认 |
| 2 | async | 异步写提作,数据在未完全写入存储设备前就返回成功信息,实际还在内存, |
| 3 | wdelay | 延迟写入选项,将多个写提请求合并后写入硬盘,减少 I/O 次数, NFS 非正常关闭数据可能丢失。默认 |
| 4 | no_wdelay | 与上相反,不与 async 同时生效,如果 NFS 服务器主要收到小且不相关的请求,该选项实际会降低性能 |
| 5 | subtree | 若输出目录是一个子目录,则 NFS 服务器将检查其父目录的权限。默认 |
| 6 | no_subtree | 即使输出目录是一个子目录, NFS 服务器也不检查其父目录的权限,这样可以提高效率 |
| 7 | secure | 限制客户端只能从小于 1024 的 TCP/IP 端口连接 NFS 服务器。默认 |
| 8 | insecure | 允许客户端从大于 1024 的 TCP/IP 端口连接服务器 |
3 安装 NFS 服务端
由于 NFS 是一套分布式文件系统,我们k8s 集群里边的Master 作为我们 NFS 服务端(有服务资源的话需要另起一台服务器或者虚拟机),配置如下
| 主机名 | IP | 系统 | CPU/内存 | 磁盘 |
|---|---|---|---|---|
| kmaster-01 | 192.168.190.165 | centos7 | 2核2G | 20G |
- 创建一个目录作为共享文件目录
mkdir -p /usr/local/kubernetes/volumes
- 给目录增加读写权限
chmod a+rw /usr/local/kubernetes/volumes
- 安装 NFS 服务端
yum -y update
yum -y install nfs-utils
-
配置 NFS 服务目录,打开文件
vi /etc/exports,在尾部新增一行,内容如下
/usr/local/kubernetes/volumes:作为服务目录向客户端开放- *:表示任何 IP 都可以访问
- rw:读写权限
- sync:同步权限
- no_subtree_check:表示如果输出目录是一个子目录,NFS 服务器不检查其父目录的权限
/usr/local/kubernetes/volumes *(rw,sync,no_subtree_check,no_root_squash)
- 重启服务,使配置生效
#配置生效
exportfs -r
#查看生效
exportfs
#启动rpcbind、nfs服务
systemctl restart rpcbind && systemctl enable rpcbind
systemctl restart nfs && systemctl enable nfs
#查看 RPC 服务的注册状况
rpcinfo -p localhost
4 安装 NFS 客户端
安装客户端的目的是验证是否可以上传文件到服务端,安装命令如下
yum -y install nfs-utils
systemctl start nfs && systemctl enable nfs
- 创建 NFS 客户端挂载目录
mkdir -p /usr/local/kubernetes/volumes-mount
- 将 NFS 服务器的
/usr/local/kubernetes/volumes目录挂载到 NFS 客户端的/usr/local/kubernetes/volumes-mount目录
mount 192.168.190.164:/usr/local/kubernetes/volumes /usr/local/kubernetes/volumes-mount
- 使用
df命令查看挂载信息
df
# 输出如下
Filesystem 1K-blocks Used Available Use% Mounted on
udev 977556 0 977556 0% /dev
tmpfs 201732 1252 200480 1% /run
/dev/mapper/ubuntu--vg-ubuntu--lv 19475088 5490916 12971848 30% /
tmpfs 1008648 0 1008648 0% /dev/shm
tmpfs 5120 0 5120 0% /run/lock
tmpfs 1008648 0 1008648 0% /sys/fs/cgroup
/dev/loop0 90624 90624 0 100% /snap/core/6964
/dev/loop1 93184 93184 0 100% /snap/core/6350
/dev/sda2 999320 214252 716256 24% /boot
tmpfs 201728 0 201728 0% /run/user/0
# 有此输出表示挂载成功
193.192.168.141.140:/usr/local/kubernetes/volumes 19475200 5490944 12972032 30% /usr/local/kubernetes/volumes-mount
5 验证 NFS 服务
- 测试文件上传
ip addr > /usr/local/kubernetes/volumes-mount/test.txt
- 查看
/usr/local/kubernetes/volumes目录下是否有test.txt文件,有则表示成功
6 取消 NFS 客户端挂载
注意: 不要直接在挂载目录下执行,否则会报错
umount /usr/local/kubernetes/volumes-mount
二、Kubernetes 数据卷现阶段
1. 概述
存储管理与计算管理是两个不同的问题。Persistent Volume 子系统,对存储的供应和使用做了抽象,以 API 形式提供给管理员和用户使用。要完成这一任务,我们引入了两个新的 API 资源:Persistent Volume(持久卷) 和 Persistent Volume Claim(持久卷消费者)。
Persistent Volume(PV)是集群之中的一块网络存储。跟 Node 一样,也是集群的资源。PV 跟 Volume (卷) 类似,不过会有独立于 Pod 的生命周期。这一 API 对象包含了存储的实现细节,例如 NFS、iSCSI 或者其他的云提供商的存储系统。Persistent Volume Claim (PVC) 是用户的一个请求。跟 Pod 类似,Pod 消费 Node 的资源,PVC 消费 PV 的资源。Pod 能够申请特定的资源(CPU 和内存);Claim 能够请求特定的尺寸和访问模式(例如可以加载一个读写,以及多个只读实例)
2. PV 与 PVC
PV 是集群的资源。PVC 是对这一资源的请求,也是对资源的所有权的检验。PV 和 PVC 之间的互动遵循如下的生命周期。
- 供应: 集群管理员会创建一系列的 PV。这些 PV 包含了为集群用户提供的真实存储资源,它们可利用 Kubernetes API 来消费。
- 绑定: 用户创建一个包含了容量和访问模式的持久卷申请。Master 会监听 PVC 的产生,并尝试根据请求内容查找匹配的 PV,并把 PV 和 PVC 进行绑定。用户能够获取满足需要的资源,并且在使用过程中可能超出请求数量。如果找不到合适的卷,这一申请就会持续处于非绑定状态,一直到出现合适的 PV。例如一个集群准备了很多的 50G 大小的持久卷,(虽然总量足够)也是无法响应 100G 的申请的,除非把 100G 的 PV 加入集群。
- 使用: Pod 把申请作为卷来使用。集群会通过 PVC 查找绑定的 PV,并 Mount 给 Pod。对于支持多种访问方式的卷,用户在使用 PVC 作为卷的时候,可以指定需要的访问方式。一旦用户拥有了一个已经绑定的 PVC,被绑定的 PV 就归该用户所有了。用户的 Pods 能够通过在 Pod 的卷中包含的 PVC 来访问他们占有的 PV。
- 释放: 当用户完成对卷的使用时,就可以利用 API 删除 PVC 对象了,而且他还可以重新申请。删除 PVC 后,对应的卷被视为 “被释放”,但是这时还不能给其他的 PVC 使用。之前的 PVC 数据还保存在卷中,要根据策略来进行后续处理。
- 回收: PV 的回收策略向集群阐述了在 PVC 释放卷的时候,应如何进行后续工作。目前可以采用三种策略:保留,回收或者删除。保留策略允许重新申请这一资源。在持久卷能够支持的情况下,删除策略会同时删除持久卷以及 AWS EBS/GCE PD 或者 Cinder 卷中的存储内容。如果插件能够支持,回收策略会执行基础的擦除操作(
rm -rf /thevolume/*),这一卷就能被重新申请了。
3. 定义 PV
3.1 持久卷插件
持久卷是以插件方式实现的,目前支持的插件如下:
- GCEPersistentDisk
- AWSElasticBlockStore
- NFS(我们采用的是该方案)
- iSCSI
- RBD (Ceph Block Device)
- Glusterfs
- HostPath (单节点测试使用)
- 本地持久卷
3.2 YAML 配置
创建一个名为 nfs-pv-mysql.yml 的配置文件
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs-pv-mysql
spec:
# 设置容量
capacity:
storage: 5Gi
# 访问模式
accessModes:
# 该卷能够以读写模式被多个节点同时加载
- ReadWriteMany
# 回收策略,这里是基础擦除 `rm-rf/thevolume/*`
persistentVolumeReclaimPolicy: Recycle
nfs:
# NFS 服务端配置的路径
path: "/usr/local/kubernetes/volumes"
# NFS 服务端地址
server: 192.168.141.140
readOnly: false
# 部署
kubectl create -f nfs-pv-mysql.yml
# 删除
kubectl delete -f nfs-pv-mysql.yml
# 查看
kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
nfs-pv-mysql 5Gi RWX Recycle Available 29m
3.3 配置说明
3.3.1. Capacity(容量)
一般来说,PV 会指定存储容量。这里需要使用 PV 的 capcity 属性。目前存储大小是唯一一个能够被申请的指标,今后会加入更多属性,例如 IOPS,吞吐能力等。
3.3.2. AccessModes(访问模式)
只要资源提供者支持,持久卷能够被用任何方式加载到主机上。每种存储都会有不同的能力,每个 PV 的访问模式也会被设置成为该卷所支持的特定模式。例如 NFS 能够支持多个读写客户端,但是某个 NFS PV 可能会在服务器上以只读方式使用。每个 PV 都有自己的一系列的访问模式,这些访问模式取决于 PV 的能力。访问模式的可选范围如下:
- ReadWriteOnce:该卷能够以读写模式被加载到一个节点上
- ReadOnlyMany:该卷能够以只读模式加载到多个节点上
- ReadWriteMany:该卷能够以读写模式被多个节点同时加载
在 CLI 下,访问模式缩写为:
- RWO:ReadWriteOnce
- ROX:ReadOnlyMany
- RWX:ReadWriteMany
另外,一个卷不论支持多少种访问模式,同时只能以一种访问模式加载。例如一个 GCE Persistent Disk 既能支持 ReadWriteOnce,也能支持 ReadOnlyMany。
3.3.3 RecyclingPolicy(回收策略)
当前的回收策略可选值包括:
- Retain:人工重新申请
- Recycle:基础擦除(
rm-rf/thevolume/*) - Delete:相关的存储资产例如 AWS EBS,GCE PD 或者 OpenStack Cinder 卷一并删除
目前,只有 NFS 和 HostPath 支持 Recycle 策略,AWS EBS、GCE PD 以及 Cinder 卷支持 Delete 策略。
3.3.4 阶段(Phase)
一个卷会处于如下阶段之一:
- Available:可用资源,尚未被绑定到 PVC 上
- Bound:该卷已经被绑定
- Released:PVC 已经被删除,但该资源尚未被集群回收
- Failed:该卷的自动回收过程失败
4. 定义 PVC
创建一个名为 nfs-pvc-mysql-myshop.yml 的配置文件
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: nfs-pvc-mysql-myshop
spec:
accessModes:
# 需要使用和 PV 一致的访问模式
- ReadWriteMany
# 按需分配资源
resources:
requests:
storage: 1Gi
# 部署
kubectl create -f nfs-pvc-mysql-myshop.yml
# 删除
kubectl delete -f nfs-pvc-mysql-myshop.yml
# 查看
kubectl get pvc
5. 部署 MySQL8
注意: 要确保每台 Node 都安装了 NFS 客户端,
apt-get install -y nfs-common
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: mysql-myshop
spec:
replicas: 1
template:
metadata:
labels:
name: mysql-myshop
spec:
containers:
- name: mysql-myshop
image: mysql
# 只有镜像不存在时,才会进行镜像拉取
imagePullPolicy: IfNotPresent
ports:
- containerPort: 3306
# 同 Docker 配置中的 environment
env:
- name: MYSQL_ROOT_PASSWORD
value: "123456"
# 容器中的挂载目录
volumeMounts:
- name: nfs-vol-myshop
mountPath: /var/lib/mysql
volumes:
# 挂载到数据卷
- name: nfs-vol-myshop
persistentVolumeClaim:
claimName: nfs-pvc-mysql-myshop
---
apiVersion: v1
kind: Service
metadata:
name: mysql-myshop
spec:
ports:
- port: 3306
targetPort: 3306
type: LoadBalancer
selector:
name: mysql-myshop
6. 解决权限问题
当你使用 kubectl create -f 部署后,你会发现 Pod 状态为 Error,容器无法正常启动的情况,我们可以使用 kubectl logs 看到一条日志
chown: changing ownership of '/var/lib/mysql/': Operation not permitted
解决方案是在 NFS 服务端配置中增加一个参数 no_root_squash,即将配置修改为:/usr/local/kubernetes/volumes *(rw,sync,no_subtree_check,no_root_squash)
7. 测试运行
部署成功后可以使用 kubectl get service 查看我们 MySQL 的运行端口,再使用连接工具连接会报如下错误
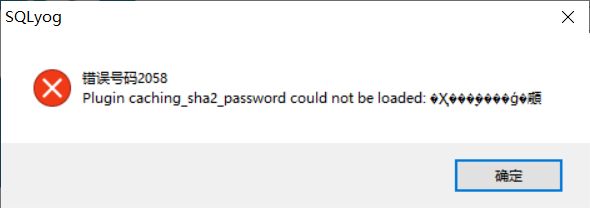
意思为无法使用密码的方式登录,在 Docker 部署时我们可以在 YAML 中配置相关参数解决这个问题;下一节我们讲解在 Kubernetes 中采用 ConfigMap 的方式配置 MySQL
8. 附:ImagePullPolicy
支持三种 ImagePullPolicy
- Always: 不管镜像是否存在都会进行一次拉取
- Never: 不管镜像是否存在都不会进行拉取
- IfNotPresent: 只有镜像不存在时,才会进行镜像拉取
注意
- 默认为
IfNotPresent,但:latest标签的镜像默认为Always - 拉取镜像时 Docker 会进行校验,如果镜像中的 MD5 码没有变,则不会拉取镜像数据
- 生产环境中应该尽量避免使用
:latest标签,而开发环境中可以借助:latest标签自动拉取最新的镜像