测试两个浮点型数据相加是否大于1
以下代码只是使用了单层网络进行计算,并未使用 偏移量;随机梯度下降等更深层次的概念。
如果训练集数据大小过大时,需要使用随机梯度下降的方式来加快训练时间。
学习率如果设置过小,会显著增加训练时间;如果过大,又会无法找到全局最优解。
#
"""
二分法测试
原始数据:随机生成[2]数组
目标数据:数组[0]+[1]的结果如果大于等于1,则为1;否则为0。see:get_result
"""
import tensorflow as tf
from numpy import random
TRAIN_SIZE = 1000 # 训练数据大小
VALIDATE_SZIE = 200 # 验证数据大小
TEST_SIZE = 2000 # 测试数据大小
def get_result(t):
# 根据数据创建结果。数据和>=1,结果=1;否则=0
return [[1] if (m[0] + m[1]) >= 1 else [0] for m in t]
SOURCE = random.rand(TRAIN_SIZE, 2) # 训练原始数据集
RESULT = get_result(SOURCE) # 训练结果数据集
V_X = random.rand(VALIDATE_SZIE, 2) # 校验原始数据集
V_Y = get_result(V_X) # 校验结果数据集
T_X = random.rand(TEST_SIZE, 2) # 测试原始数据集
T_Y = get_result(T_X) # 测试结果数据集
X = tf.placeholder(tf.float32, shape=[None, 2], name='input') # 原始数据占位符
Y = tf.placeholder(tf.float32, shape=[None, 1], name='output') # 输出数据占位符,用来与计算输出数据比较,得出损失值
HIDDEN_SIZE = 500 # 隐藏层数量
def init_weight(shape):
return tf.Variable(tf.random_normal(shape, stddev=0.01))
W_1 = init_weight([2, HIDDEN_SIZE]) # 隐藏层1
W_OUTPUT = init_weight([HIDDEN_SIZE, 1]) # 输出层
OUTPUT = tf.matmul(tf.nn.sigmoid(tf.matmul(X, W_1)), W_OUTPUT) # 原始数据通过隐藏层计算结果
_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=OUTPUT, labels=Y)) # 损失值
_train = tf.train.GradientDescentOptimizer(0.05).minimize(_loss) # 计算方法
STEPS = 30001 # 训练轮次
with tf.Session() as sess:
sess.run(tf.global_variables_initializer()) # 首先初始化所有数据
for i in range(STEPS):
# 个人水平有限,这里没有采用批次的方式进行训练
sess.run(_train, feed_dict={X: SOURCE, Y: RESULT})
if i % 1000 == 0:
# 每1000轮时,使用校验数据计算损失值
_cost = sess.run(_loss, feed_dict={X: V_X, Y: V_Y})
print("经过 {:>5d} 轮训练,使用 校验数据集 测试损失值为:{}。".format(i, _cost))
if i % 5000 == 0:
# 每5000轮,使用测试数据集直接判断结果,输出结果正确率
_out = [[1] if m > 1 else [0] for m in sess.run(OUTPUT, feed_dict={X: T_X})]
_s = len([1 for i in range(len(T_Y)) if T_Y[i] == _out[i]])
print('经过 {:>5d} 轮训练,使用 测试数据集进行测试,{}(正确数量)/{}(总数据量)={:.2%}'.format(i, _s, len(T_Y), _s / len(T_Y)))输出内容如下:
经过 0 轮训练,使用 校验数据集 测试损失值为:0.6941196322441101。
经过 0 轮训练,使用 测试数据集进行测试,987(正确数量)/2000(总数据量)=49.35%
经过 1000 轮训练,使用 校验数据集 测试损失值为:0.6805213689804077。
经过 2000 轮训练,使用 校验数据集 测试损失值为:0.538556694984436。
经过 3000 轮训练,使用 校验数据集 测试损失值为:0.2825967073440552。
经过 4000 轮训练,使用 校验数据集 测试损失值为:0.1842319369316101。
经过 5000 轮训练,使用 校验数据集 测试损失值为:0.14281019568443298。
经过 5000 轮训练,使用 测试数据集进行测试,1808(正确数量)/2000(总数据量)=90.40%
经过 6000 轮训练,使用 校验数据集 测试损失值为:0.12008533626794815。
经过 7000 轮训练,使用 校验数据集 测试损失值为:0.10553856194019318。
经过 8000 轮训练,使用 校验数据集 测试损失值为:0.0953076109290123。
经过 9000 轮训练,使用 校验数据集 测试损失值为:0.08765047043561935。
经过 10000 轮训练,使用 校验数据集 测试损失值为:0.08166348189115524。
经过 10000 轮训练,使用 测试数据集进行测试,1905(正确数量)/2000(总数据量)=95.25%
经过 11000 轮训练,使用 校验数据集 测试损失值为:0.07682867348194122。
经过 12000 轮训练,使用 校验数据集 测试损失值为:0.07282623648643494。
经过 13000 轮训练,使用 校验数据集 测试损失值为:0.06944723427295685。
经过 14000 轮训练,使用 校验数据集 测试损失值为:0.06654875725507736。
经过 15000 轮训练,使用 校验数据集 测试损失值为:0.0640294998884201。
经过 15000 轮训练,使用 测试数据集进行测试,1928(正确数量)/2000(总数据量)=96.40%
经过 16000 轮训练,使用 校验数据集 测试损失值为:0.06181534752249718。
经过 17000 轮训练,使用 校验数据集 测试损失值为:0.05985085666179657。
经过 18000 轮训练,使用 校验数据集 测试损失值为:0.058093465864658356。
经过 19000 轮训练,使用 校验数据集 测试损失值为:0.05651006102561951。
经过 20000 轮训练,使用 校验数据集 测试损失值为:0.055074337869882584。
经过 20000 轮训练,使用 测试数据集进行测试,1936(正确数量)/2000(总数据量)=96.80%
经过 21000 轮训练,使用 校验数据集 测试损失值为:0.053765200078487396。
经过 22000 轮训练,使用 校验数据集 测试损失值为:0.05256548896431923。
经过 23000 轮训练,使用 校验数据集 测试损失值为:0.05146101117134094。
经过 24000 轮训练,使用 校验数据集 测试损失值为:0.05044003576040268。
经过 25000 轮训练,使用 校验数据集 测试损失值为:0.0494927316904068。
经过 25000 轮训练,使用 测试数据集进行测试,1949(正确数量)/2000(总数据量)=97.45%
经过 26000 轮训练,使用 校验数据集 测试损失值为:0.048610806465148926。
经过 27000 轮训练,使用 校验数据集 测试损失值为:0.047787100076675415。
经过 28000 轮训练,使用 校验数据集 测试损失值为:0.047015562653541565。
经过 29000 轮训练,使用 校验数据集 测试损失值为:0.04629102721810341。
经过 30000 轮训练,使用 校验数据集 测试损失值为:0.04560888186097145。
经过 30000 轮训练,使用 测试数据集进行测试,1952(正确数量)/2000(总数据量)=97.60%tf.nn.sigmoid
sigmoid(x, name=None)。计算 x 元素的 S函数 形式。
计算方式:y = 1 / (1 + exp(-x))。
相当于 numpy 中的 np.scipy.special.expit
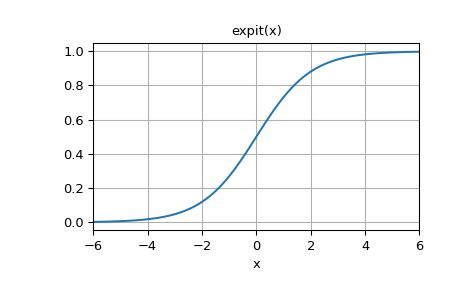
tf.nn.sigmoid_cross_entropy_with_logits
sigmoid_cross_entropy_with_logits(_sentinel=None, labels=None, logits=None, name=None) 。计算 logits 的 S形 交叉熵。
logits和labels必须具有相同的类型和形状。