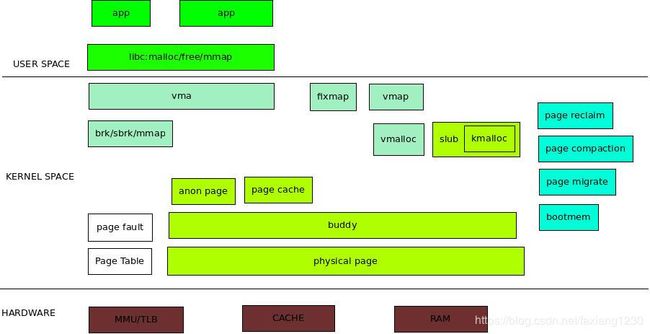
浅析linux内存管理
物理内存和虚拟内存
现代的操作系统中进程访问的都是虚拟内存,而虚拟内存到物理内存的转换是由系统默默完成的。首先来扒一扒它的历史,直接使用物理内存效率岂不是更高,何必加一个中间层?
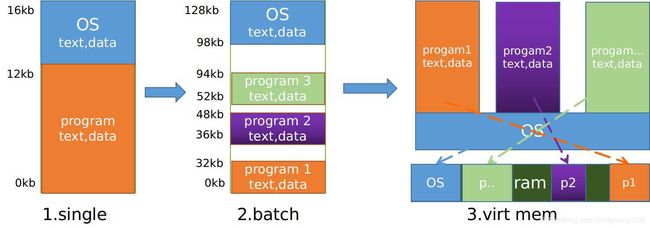
在计算机早期,物理内存的容量是K级别的,计算机中只运行了一个程序,OS就是一个简单的库,编写语言还是汇编,尽一切可能缩小程序的规模来节省内存。这时候一个程序独占整个计算机,图1.
后来有了多道程序,在计算机中运行多个程序,这样cpu可以轮换着服务多个程序的执行,计算机仍然非常昂贵,这样一个计算机服务多个程序,相当于成本降低了。此时每个程序划分出来一块内存,所有的程序全部在内存中等待cpu分配给它运行,图2
程序多了就存在一些问题:
1.程序A能访问程序B的数据,可能是无意间错误访问了,需要提供程序间数据的隔离
2.程序增多,需要手工分配运行空间,每次更换程序都需要重新分配,重新给链接地址,能不能自动分配地址
之后就发明了虚拟内存地址空间的概念,每个程序运行时都有自己的虚拟地址空间,并且独享全部的地址空间;程序之间不能直接互相访问数据,进程间通信需要通过专门的方式:套接字,信号量,共享内存等等,这些都需要OS内核的参与;内核负责维护虚拟地址空间并且在切换程序运行的时候切换到对应进程的地址空间,内核可以访问进程的数据,后来为了安全性加了一些限制条件,也不能随意访问进程的地址空间。
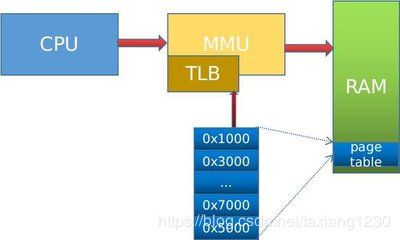
 虚拟地址空间到地址空间的转换是通过MMU(Memory Management Unit)来完成的,CPU访问内存的地址请求发送给MMU,是虚拟地址,CPU是看不到物理内存的,MMU将地址转换成物理地址,也就是VA->PA的转换。
虚拟地址空间到地址空间的转换是通过MMU(Memory Management Unit)来完成的,CPU访问内存的地址请求发送给MMU,是虚拟地址,CPU是看不到物理内存的,MMU将地址转换成物理地址,也就是VA->PA的转换。
其中MMU转换依赖页表,页表是一系列页表项的数组,每个页表项保存着物理页的地址,页表项在页表中的索引表示虚拟地址,页表项存在于物理内存中,MMU可以看到物理内存,切换进程的时候从物理内存中加载页表,这时候是页表的物理地址,这样不会存在鸡和蛋谁先谁后的问题。而MMU每次做地址转换不能总是去访问物理内存拿到页的对应关系,访问RAM的速度和CPU速度相差太大,所以MMU中做了一个页表的缓存TLB(Translation Lookaside Buffer),不过它的存储大小是有限的,只能存储一部分页表项,需要相应的算法例如LRU来决定哪部分页表项能够缓存在TLB中。
 MMU除了完成VA->PA的转换之外,还负责一些权限的检查。现在典型的页划分为4K,在32bit系统上我们表示页的地址的时候后12bit是空的,只需要前面20bit就可以表示页帧的地址,MMU在取任意的32bit地址的时候分成两个步骤:1.将虚拟地址分为虚拟页地址和业内地址;2.虚拟页地址就是在页表中的索引,获得页表项中物理页的地址;3.将物理页地址和页内偏移合成真正的物理地址
MMU除了完成VA->PA的转换之外,还负责一些权限的检查。现在典型的页划分为4K,在32bit系统上我们表示页的地址的时候后12bit是空的,只需要前面20bit就可以表示页帧的地址,MMU在取任意的32bit地址的时候分成两个步骤:1.将虚拟地址分为虚拟页地址和业内地址;2.虚拟页地址就是在页表中的索引,获得页表项中物理页的地址;3.将物理页地址和页内偏移合成真正的物理地址
| 虚拟地址 | 转换过程 | 物理地址 |
|---|---|---|
| 0x12345678 | 虚拟页地址:0x12345000 + 页内偏移:0x678 页表page table[0x12345] = 0xabcde000 ->页帧地址 物理地址=0xabcde000+0x12345 |
0xabcde678 |
而每一个页表项是占据4个字节,物理页的地址也是只占据20bit,剩余的12bit可以用来做其他用途,其中有两个关于权限控制的:_PAGE_BIT_RW和_PAGE_BIT_USER,分别控制读写权限和内核是否有读写权限。
当权限错误或者虚拟地址没有对应的物理页时会出发异常,异常触发后内核可以尝试修复异常,也就是缺页中断,借助这个时机实现了COW,页的按需分配,swap in等功能。
物理内存
物理内存通常是按照zone来管理的,通常有DMA,DMA32,NORMAL,HIGHMEM。其中DMA zone的范围一般是0-32M,因为早期的DMA引擎的寻址范围是16位,它看不到32M以上的物理地址,0-32M的地址就是为了旧的DMA设备预留的物理空间,平时尽量不要使用这一部分地址空间以免DMA设备访问的时候没有物理内存空间给它用,不过现在的DMA设备基本上都已经很少只支持16bit的空间的,一般都是32bit的,DMA32位的就是给这一部分设备用的,DMA zone的范围是由DMA设备的寻址范围决定的,DMA设备如果都支持64bit寻址,也没必要保留DMA/32 zone了。DMA引擎一般访问连续的物理内存时是最高效的,CPU只需要一次请求就能完成连续的一片内存的读写操作,不需要频繁的中断要求CPU参与DMA活动,所以一般DMA需要分配连续的内存。不过目前高级的DMA设备可能配备了IOMMU,和MMU一样能够完成VA->PA的转换,IOMMU也需要页表一样的东西来保存虚拟和物理地址的对应关系,减少了对连续物理内存的依赖。
而HIGHMEM目前基本上只在32bit系统上才有的,经典的虚拟地址空间划分为1:3,即内核空间在3-4G范围,用户空间在0-3G范围,这样内核最多只能线性映射1G的内存,当访问多于1G内存的时候它已经没有虚拟地址进行映射了,所以为了在内核中能够访问更多的内存,它预留出了128M的虚拟地址空间段来进行动态映射,所以物理内存高于896M的部分称之为HIGHMEM,这部分纯粹是因为虚拟地址空间不足才有的概念。如果虚拟地址空间划分为2:2,那么1G+896M以上的物理内存才称为HIGHMEM。目前64bit系统上内核能够使用的虚拟地址空间完全充足,不再有HIGHMEM的概念了。
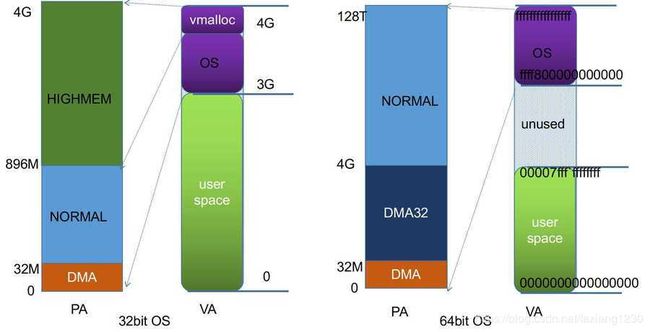 32bit系统中,内存小于1G内核可以直接线性映射,不过还是需要留出来一部分虚拟地址空间来做io map,所以典型的是只线性映射0-896M.
32bit系统中,内存小于1G内核可以直接线性映射,不过还是需要留出来一部分虚拟地址空间来做io map,所以典型的是只线性映射0-896M.
vmalloc区域预留出一部分虚拟地址空间,因为这部分是页表来维护的,和用户空间的地址空间映射相同,不要求物理内存连续.除了物理内存它还可以做io映射,动态访问io寄存器等.
在最高端的部分预留出来一小块地址空间来做固定映射,顾名思义,这部分的虚拟地址空间的用途是不变的,不能用来做其他用途,有点类似于线性映射,不同的是在内核启动的时候动态将物理内存绑定映射,之后还可以解除映射,重新映射等.例如FIX_TEXT_POKE1用来在修改text段内容指令的时候使用,修改指令时映射到FIX_TEXT_POKE1地址,修改完成后解除映射.
当物理内存>4G时,32bit系统上已经无法访问>4G的内存,x86发明了一种方法PAE(Physical Address Extension),通过动态窗口的方式能够访问更高地址的物理内存,它最多可以寻址64Gb RAM .这允许进程A使用第一个4G的内存,而进程B使用下一个4G的内存。总共使用了超过4G的物理内存,但是单个进程使用的内存总量仍然限制为4G.
刚开始看内存管理的时候,我就担忧,如果物理内存总共512M,内核全部线性映射了,用户程序岂不是没的用了?
内核线性映射只是说它可以不创建页表就可以直接使用,但是不代表它已经全部使用了,用户程序需要内存的时候仍然可以从这里拿.根据内存的相对稀有程度,一般HIGHMEM
如果HIGHMEM不能够满足的话,那就需要从NORMAL zone中给他分配,最后实在没办法了再从DMA zone中给他分配.
内核线性映射访问不代表已经使用了,只是可以直接通过线性偏移进行VA->PA转换
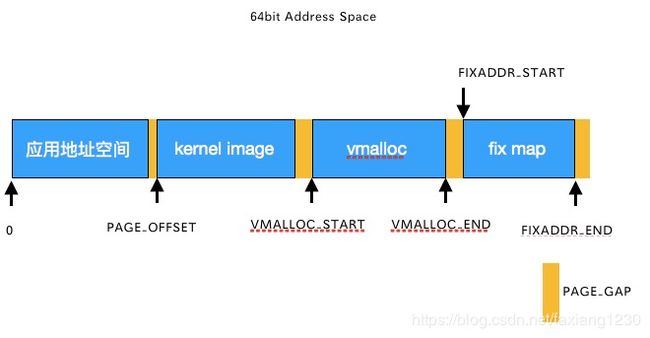
而在64bit位系统上,首先HIGHMEM区域肯定是不需要存在了,目前内核实际使用了48bit的地址空间,其中内核空间0xffff8000 00000000->0xFFFFFFFF FFFFFFFF共计128T,可以线性映射所有的物理内存.其他的和32bit系统上基本上保持相同.
上面这些ZONE是地址空间的原因和限制存在的,但是他们并不是直接的物理内存分配管理器,而是buddy系统.
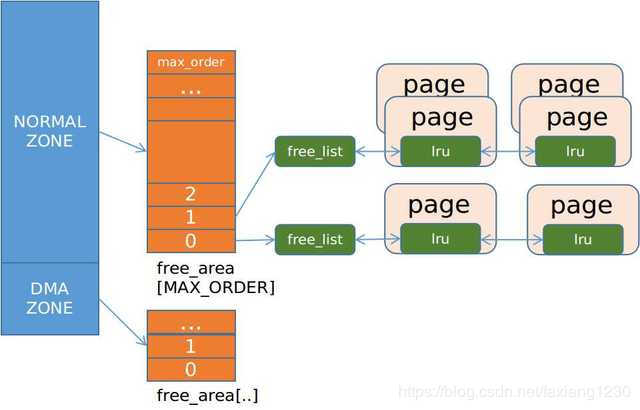
buddy系统
buddy系统最大的特点是简单,数据结构简单,管理对象简单,其次它能较好的进行连续页管理.Buddy算法主要是解决外部碎片问题,每个zone都有buddy管理器来管理着可用的页面,按照2的幂级(order)大小排成链表队列,存放在free_area数组。
zone到buddy的管理:
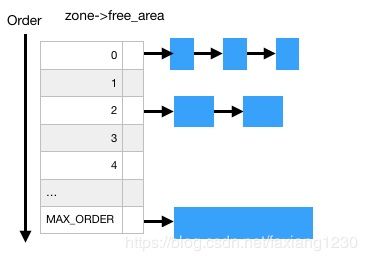
-
buddy拆分:
申请多个物理页的时候,要求页数是2^order.首先会遍历zone->free_area[order]尝试找到空闲的页.存在空闲页的话直接从链表上移除,更新统计数据.如果没有空闲页了,就继续尝试从zone->free_area[order+1]中找空闲页,如果空闲的话则拆分,一部分返回给申请者,另外一部分挂到zone->free_area[order]上. -
buddy合并:
释放2^order个页时,会尝试和相邻的页合并,合并的策略是找相同order的连续页:page ^ (1 << order),如果当前page=8,order=1,则寻找8^(1<<1)也就是page=10. 而如果page=10,order=1,它需要和10^(1<<1)也就是page=8合并,说明在order=2层次上page=8和page=10是buddy,组成一个新的2^(order +1)的连续区域.
为什么不和前面的page=6合并呢?如果page=8和它合并,原本page=6和page=4是一对buddy,现在page=6和page=8组合成一个新的区域,前面6个页就无法组合成2^order形式,后面的页也无法组成2^order中形式,最终拆乱之后就无法组成最完美的状态.
合并完之后还会尝试向上继续合并2^(order +2),上一级page的页帧号计算方式:Parent page = page & ~(1 << order),直至最终到达2^max_order的区域管理。
Buddy的2的幂级管理方式目前是最简单的,管理页的申请释放状态,还提供连续页管理的能力。
slab分配器
内核的很多操作通常都是小对象的分配,大小通常远小于1页,它们会在系统生命周期内进行无数次分配。直接使用buddy时,最小的单元是页,会造成很大的页内浪费。slab 缓存分配器通过对类似大小(远小于1page)的对象进行缓存而提供小内存的申请释放管理,从而避免了常见的内部碎片问题。slab机制是基于buddy算法的,前者是对后者的细化,解决页内部碎片问题。
常见的slab分配器有三种:slab,slub,slob。slab是最早发明的,也是其他两种分配器的代名词,但是它太复杂了,很难维护,管理数据占用的空间页比较大,所以后来发明了简化版的slub分配器,这是目前PC上默认的分配器。而嵌入式系统上内存有限,内存对象使用有限,有了进一步简化的slob分配器,代码总共只有600多行,不提供本地CPU高速缓存和本地节点管理。
slab使用方式通常有两种:kmalloc和kmem_cache,kmalloc提供了一些常用的内置大小的对象的管理,对象大小范围也非常广:8,16,32...8192,这种方式简化了api,降低了使用者的难度,不过因为很多地方同时从一个对象池中获取/释放对象,必然会增加管理锁的冲突概率。而kmem_cache这种方式提供了专有对象的管理,它和kmalloc的对象管理方式是相同的,都是slab分配器来管理,只不过存储的对象用途专一,申请和释放中锁冲突概率较小,但是它需要使用者主动创建和销毁kmem_cache。kmem_cache的一个使用技巧是能够探测module中的内存泄露,module创建kmem_cache并且所有的对象都存储在其中,当卸载的时候销毁kmem_cache,如果存在内存泄露,kmem_cache会销毁失败。
下面简单看一下slub分配器的管理:
一个slub通常是是由一个或多个页组成,也就是我们常说的slub对象,它是页的组合。
kmem_cache的主要管理数据结构:
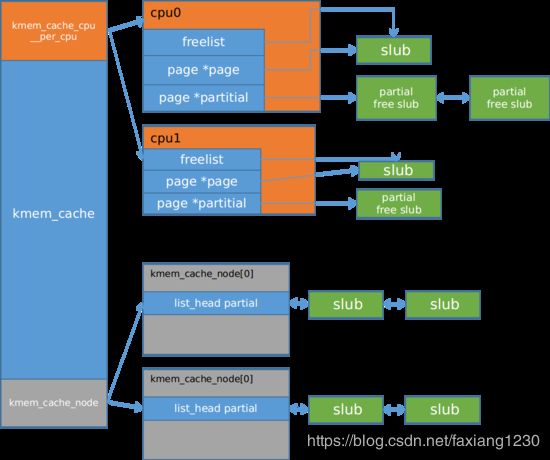 1.每个cpu上都有对应的slub缓存kmem_cache_cpu,这样能够避免申请资源的时候竞争,提高本地的缓存命中率
1.每个cpu上都有对应的slub缓存kmem_cache_cpu,这样能够避免申请资源的时候竞争,提高本地的缓存命中率
其中的page指向当前正在使用的slub对象,能够快速的从当前slub中申请到对象,如果当前的slub为空的时候,先从partial中获取一个slub对象。
partial中存放着一些部分空的slub对象
freelist指向当前可用的对象
2.在NUMA系统中,每个节点有自己的slub对象管理,两个链表:partial中挂着部分满的slub对象
slub中对于小内存对象的管理:
一部分用来存放使用的对象,另外在它的尾部还有一个空闲指针,下图是一个slub中对象多次申请释放之后freelist之间的关系。其中object_size是对象真实大小,但是之后是一个ptr,是一个指针,需要进行对齐8字节,即offset=align(object_size, sizeof(void *))。
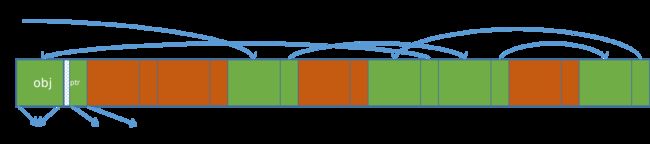 1.对象的申请
1.对象的申请
申请的位置优先级:cpu_slab->page —> cpu_slab->partial ----> node->list_partial -------> alloc slub from buddy
1.直接在cpu_slab->page中申请,更新freelist指向下一个空闲对象
2.当前slub已经用完了,即cpu_slab->freelist为空,那从cpu_slab->partial中取下一个部分满的slub到cpu_slab->page中,当前全满的slub就不维护了,和buddy只维护可用内存一样
3.cpu_slab->partial中也没有可用的slub了,则开始从node->list_partial中获取,一次获取的slub中空闲对象要超过cpu_partial/2
4.如果node->list_partial中也为空则从buddy中获取页组成slub放到node->list_partial中,首先尝试获取oo->order个页,如果没有那么多空闲内存,则少申请一点min->order个页
通过kmem_cache_create初始化之后,它的cpu_slab->page,cpu_slab->partial和node->list_partial全部为空,即上面第4种情况。
2.对象的释放
1.如果对象所在的slab不是全满状态,则直接释放,更新freelist。
2.如果对象所在的slub是全满状态,释放后slub就变成了部分满状态,将该slab挂到cpu_slab->partial中。
3.如果对象所在的slub在释放该slub后变成全空,系统首先会检查node部分空链表中slub缓冲区的个数,如果node部分空链表中slub缓冲区数量小于kmem_cache中的min_partial,则将这个空闲slab缓冲区放入node部分空链表中。否则释放此空闲slab,将其占用页框返回伙伴系统中。
内存碎片化
当机器长时间运行后,就会出现内存碎片问题,虽然有内存可用但是不符合要求,例如现在有16个页,但是没有连续的2个页,申请连续的2个页时就没有满足条件的内存.
物理内存碎片化问题是无法避免的,在理论上是无法彻底解决的,只能进行规避延缓,通常是通过预防碎片化的方式来规避这个问题.
将物理内存通过zone管理,将buddy进一步划分成几种类型:
- 不可移动页面 UNMOVABLE:在内存中位置必须固定,无法移动到其他地方,核心内核分配的大部分页面都属于这一类。
- 可回收页面 RECLAIMABLE:不能直接移动,但是可以回收,因为还可以从某些源重建页面,比如文件映射的数据属于这种类别,kswapd会按照一定的规则,周期性的回收这类页面。
- 可移动页面 MOVABLE:可以随意的移动。属于用户空间应用程序的页属于此类页面,它们是通过页表映射的,因此我们只需要更新页表项,并把数据复制到新位置就可以了,当然要注意,一个页面可能被多个进程共享,对应着多个页表项。
防止碎片化的方法就是把这三种类型的页帧放在不同的链表上,避免不同类型页面相互干扰。
考虑这样的情形,一个不可移动的页面位于可移动页面中间,那么我们移动或者回收这些页面后,这个不可移动的页帧阻碍着我们获得更大的连续物理空闲空间。
在分配物理内存时秉承的原则是如果有页面则尽量提供,进行划分只是尽量避免干扰,但是如果一个类型的页面已经耗尽的情况下,则会选择在其他类型的页面中尝试分配,目标就是使系统尽量正常运行。下面的fallbacks定义了适用于大部分情况下的不同类型页之间的备用关系,例如我们要申请UNMOVABLE的页面,如果没有这种类型的页面则依次从RECLAIMABLE–>MOVABLE–>RESERVE中获取.
static int fallbacks[MIGRATE_TYPES][4] = {
[MIGRATE_UNMOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_MOVABLE, MIGRATE_RESERVE },
[MIGRATE_RECLAIMABLE] = { MIGRATE_UNMOVABLE, MIGRATE_MOVABLE, MIGRATE_RESERVE },
#ifdef CONFIG_CMA
[MIGRATE_MOVABLE] = { MIGRATE_CMA, MIGRATE_RECLAIMABLE, MIGRATE_UNMOVABLE, MIGRATE_RESERVE },
[MIGRATE_CMA] = { MIGRATE_RESERVE }, /* Never used */
#else
[MIGRATE_MOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_UNMOVABLE, MIGRATE_RESERVE },
#endif
[MIGRATE_RESERVE] = { MIGRATE_RESERVE }, /* Never used */
#ifdef CONFIG_MEMORY_ISOLATION
[MIGRATE_ISOLATE] = { MIGRATE_RESERVE }, /* Never used */
#endif
};
在系统启动的时候,将所有的页面都是MOVABLE类型的,当初次使用时该类型的zone不存在,从MOVABLE类型中获取到尽可能多的页面并转换成该类型的页面,这样可以防止该类型的页面申请污染了MOVABLE的页面.
小结
zone分类主要是各种物理内存的稀有程度不同,而zone内的MIGRATE类型主要是为了防止内存碎片,buddy才是直接的页管理,直接使用页会有很多页内剩余空间闲置,发明了slab/slub,这就是内核中基础的物理内存管理.
应用层一般使用malloc系列的api来申请内存,其实glibc通过brk/mmap创建虚拟内存映射空间,实际访问的时候发生缺页中断真正分配物理内存,这时候是直接从buddy中获取空闲页来映射到进程中,之后才能操作的.应用程序对于物理内存无感,它只能看得到虚拟地址空间,这是由虚拟内存块管理的.
虚拟内存
启用MMU之后,每个进程都有自己独立的地址空间,但是空间那么大,它是用不完的,大部分只是使用一小部分的地址空间.前面我们说页表项记录映射关系,一方面页帧不能过大,这样很容易产生许多的页内空间浪费,另一方面是页不能太小,我们知道每一个页都有一个page的管理对象,这样会使page对象占据的内存激增,所以目前选取了4k作为一个比较通用的页大小.如果是一维页表项存储所有的对应关系,即有4G/4k=1M个页表项,每个进程的页表都需要占据1M * sizeof(void *)空间,系统启动1k个进程系统的内存就消耗光了. 开发人员通过多级页表的方式来减少页表实际占用的内存(多级页表的划分也是一个折中问题),这样就需要另外的数据来管理真实的虚拟内存地址空间,也就是下面的主题.

 一个进程的虚拟地址空间由mm_struct管理,主要管理的资源有页表pgd和虚拟内存区域vm_area_struct,页表就是一大堆页表项的数组,而vm_area_struct代表一块具有相同权限的区间,通过
一个进程的虚拟地址空间由mm_struct管理,主要管理的资源有页表pgd和虚拟内存区域vm_area_struct,页表就是一大堆页表项的数组,而vm_area_struct代表一块具有相同权限的区间,通过/proc/pid/maps看到的内容就是需要维护的属性:
head /proc/self/maps
55d4c0e27000-55d4c0e2f000 r-xp 00000000 08:07 787059 /bin/cat
55d4c102e000-55d4c102f000 r--p 00007000 08:07 787059 /bin/cat
地址区间:`55d4c0e27000-55d4c0e2f000`开始地址->结束地址,边界是页对齐的
权限:`rwxp `,总共有读,写,执行,是否共享
地址偏移:`00007000`,如果当前区间映射的文件,这里标明是区间开始位置对应的文件偏移,以页对齐的
设备号:`08:07`,如果当前区间映射的文件,所在存储设备的设备号
inode:`787059`,如果当前文件不属于匿名内存,那就是相关文件的inode号,也有可能是伪文件系统中的inode号
文件路径:`/bin/cat`,如果当前区间映射的文件,文件的路径名
其中地址区间和权限是vm_area_struct基本的管理数据,此外还需要记录它的数据从哪里来的:磁盘上的文件,还是只是在内存中的堆数据.
mm_struct管理vm_area_struct使用了红黑树,链表两种方式管理,红黑树结构是查找比较快,链表适宜顺序遍历,红黑树结构中以起始地址作为key管理,而链表也是按照地址顺序存储的.
单纯的虚拟地址空间管理很简单,但是一扯上物理内存问题就多了,尤其是在用户地址空间中的故事,也就是下面缺页异常中处理的主要场景。
- 面向应用程序的lazy内存模式,用户程序分配程序使用malloc api来申请内存,它是glibc的封装,通过sbrk/mmap向内核申请,起始就只是创建对应的vm_area_struct插入到mm_struct中,而在实际使用的时候不存在对应的页表项,发生缺页异常,这时候又来查询vm_area_struct的范围和权限,符合要求的地址才会真正分配物理内存和设置页表项.这样一种按需分配的方式欺骗了应用程序,程序看到申请内存成功了,其实只是给了一个白条,没准实际使用的时候物理内存消耗光了兑换不了白条.
- 将进程中不常用的物理内存swap到硬盘,折腾出来更多的物理内存给系统使用,而使用这部分swap出去的数据时候再重新分配内存,将swap区域弄回来,重建页表.普通进程的私有数据还好,只需要修改它的页表项,但是如果是多个进程间的共享匿名数据区域要swap区域,就需要找到引用当前内存的所有进程,通过anon_vma来找到引用该物理内存的所有虚拟地址区域
- 内核vmalloc区域的管理,通过vmalloc创建的内存是通过vm_area_struct管理的,分配一块可用的vm_area_struct,之后申请N个页帧,之后做虚实映射,其中做映射的时候只将对应的页表项更新到了init_mm中对应的pgd中.当实际使用的时候发现当前进程的页表中没有该地址,发生缺页异常,之后查询是否是vmalloc区域,如果是,然后再将init_mm中的页表更新到当前进程的页表中.
而我们注意到一个进程有两个mm_struct:active_mm和mm,每个进程都有自己的内存描述符,地址空间又分为用户地址空间和内核地址空间,当处于用户状态时没有权限访问内核地址空间,在内核状态中只能通过copy_from_user/copy_to_user标准的api访问用户空间地址。所有进程共享同一份内核地址空间也就是她们内核部分的页表是相同的,另外一个特殊之处是内核线程,它通常只能访问内核地址空间。不同的进程有不同的地址空间,在进程切换的时候需要切换页表来切换到正确的地址空间上,但是对内核线程来说是没有意义的,而且所有进程共享同一份内核空间,所以催生出了上面两个mm_struct,前者代表当前正在使用的,而mm是普通应用进程特有的,内核线程的mm=NULL,当从普通进程切换到内核线程时,使用当前进程的active_mm,并且enter_lazy_tlb免除flush TLB的抖动。
小结:mm_struct是进程地址空间管理结构,vm_area_struct对应着一段一段的虚拟内存区域,而在某个地址上进行读写执行操作是否非法,vm_area_struct中记录这这个信息,围绕着缺页异常和vm_area_struct才能完成一些复杂功能.
进程的虚拟内存管理
用户空间程序一般使用malloc/free来申请和释放内存,但是当申请成功的时候说的是成功申请到了一块虚拟内存.此时分配的虚拟内存还没有对应的物理内存,当第一次访问虚拟内存的时候会发生缺页异常,从buddy系统中实际分配物理页并重新映射到虚拟内存.
malloc并不是一个系统调用,它的后端主要是brk和sbrk,mmap.当申请小于128KB时使用sbrk/brk分配内存,当申请大鱼128KB时使用mmap来申请内存.
brk/sbrk/mmap申请的内存区域最小单元也是物理页帧的大小,用户程序申请的内存对象一般比较小,一方面会有大量的虚拟地址浪费(虽然它比较浪费),实际上使用的时候分配物理内存,此时就会造成真正的内存页内空间浪费,另一方面是经常的系统调用开销比较大.所以目前glibc采用了类似于slab的方式,一次性从内核中申请大块内存,然后将内存分成不同大小的内存块,用户申请时,从内存中选择一块相近的内存块分配出去,只不过glibc不知道自己管理的是虚拟内存.
因为内核对应用存在一定的欺骗性,所以进程的内存有些一些不同的数据来进行统计它的消耗:
参考链接:https://lwn.net/Articles/230975/
| 指标 | 全称 | 含义 | 等价 |
|---|---|---|---|
| USS | Unique Set Size | 物理内存 | 进程独占的内存 |
| PSS | Proportional Set Size | 物理内存 | PSS= USS+ 按比例包含共享库和可执行文件 |
| RSS | Resident Set Size | 物理内存 | RSS= USS+ 包含共享库和可执行文件 |
| VSS | Virtual Set Size | 虚拟内存 | VSS= RSS+ 未分配实际物理内存 |

图中展示了几个进程的信息和资源统计
1./bin/bash执行了两次,启动了两个进程1044,1045,两个进程中共享libc和bash的文本段,进程有私有的heap段
2./bin/cat执行了一次,启动了进程1054,进程中的文本段映射了cat,私有的heap段,共享了libc库
3.libc在进程1044,1045,1054中共享同一份物理内存.
4.bash在进程1044,1045中共享
VSS是单个进程全部可访问的地址空间,其大小可能包括还尚未在内存中驻留的部分和没有进行任何内存页和文件映射部分。对于确定单个进程实际内存使用大小,VSS用处不大,但是一般来说VSS的增长趋势和其他几个RSS的增长趋势基本相同。
RSS是单个进程实际占用的内存大小,RSS不太准确的地方在于它包括该进程所使用共享库全部内存大小。对于一个共享库,可能被多个进程使用,实际该共享库只会被装入内存一次。
PSS相对于RSS计算共享库内存大小是按比例的。3个进程共享,该库对PSS大小的贡献只有1/3。
USS是单个进程私有的内存大小,即该进程独占的内存部分。USS揭示了运行一个特定进程在的真实内存增量大小。如果进程终止,USS就是实际被返还给系统的内存大小。
他们几个之间的关系:VSS>RSS>PSS>USS,一般来说任何一个指标过高都应该值得注意,其中USS尤其需要注意,它的不正常增高往往代表内存泄露.
缺页异常管理
缺页异常是mmu发生异常,有两种情况,一种是找不到虚拟地址对应的物理地址,一种是权限有问题的。MMU发生异常之后,1.会设置错误信息,2.将发生异常的地址放入cr2寄存器中,之后会上报给内核,允许软件来检查异常并尝试修复这个异常,如果异常不能修复最后只能oops了.
软件来修复异常的时候也是检查两方面:
1. 地址合法吗,即页表项中没有合法的物理地址,但是VMA中包括了改地址
2. 权限正确吗,即页表项中有对应的物理地址,但是pte中权限和操作权限不符,但是符合VMA中的权限
按照触发异常的地址来划分内核空间地址异常和用户空间地址异常:
| 异常地址所在地址空间 | 合法异常种类 | 异常处理 |
|---|---|---|
| 用户空间地址 | 1.地址异常:栈的自然增长,brk/mmap(malloc),匿名页被swap出去了,缺页 2.权限错误:fork的COW |
向进程发异常信号 |
| 内核地址空间 | 1.vmalloc区域页表没有同步 | oops |
用户空间地址:
1.栈的缺页异常:目前大部分系统栈空间默认都是配置成向下自然增长,随着栈帧的叠加,不停的sub $0xN,%rsp操作,当栈底超过了目前栈空间后,并没有显示的申请虚拟地址空间,这时候就会触发地址异常。此时栈所在的VMA中和addr的关系是vm_start > addr && vm_end > addr,而不是vm_start < addr && vm_end > addr,下面就是扩充栈所在的VMA,转化为vm_start < addr && vm_end > addr正常情况,之后会实际分配内存。
2.缺页地址发生在堆区且是第一次使用,即使用mmap/sbrk申请内存,只是插入了对应的VMA,当第一次读该区域时,触发mmu异常,此时也并没有为其分配物理内存而是将它映射到一个全局可见的全是0的页。只有写的时候才真正为其分配物理页并重建页表
3.缺页地址对应的是文件或者设备文件时,他们的处理时一样的,在缺页异常中调用VMA->vm_operation_struct->fault,普通文件默认是:,设备是驱动提供的:,他们会返回创建页表映射。
4.缺页地址对应的是堆区,但是因为长时间不使用被swap out出去了
进程的用户地址空间通过页表进行映射的,它并不知道后端的物理内存是否连续。当内存紧张时系统会选择将进程长时间不使用的物理内存进行回收,映射普通文件的区域可以将该区域对应的脏页进行回写,使用时可以再次分配内存,加载磁盘上文件内容重建页表;映射设备的区域不占据物理内存所以不对其进行回收;而进程中的堆栈是匿名的,没有对应的后备存储,此时可以将一个分区或者文件挂载成swap分区,为匿名内存创建后备存储,和普通文件的page cache对应的swap cache,核心就是没有条件创造条件将物理内存腾出来,将匿名内存写到swap中并且设置页表项swap信息。当再次使用已经swap out的数据时就会触发缺页异常,重新将swap out的数据从后备存储中加载进来。
内核空间地址:
使用vmalloc可以使用不连续的物理内存但是通过动态创建页表映射来获得连续的虚拟内存,vmalloc区域和内核中线性映射区域是不同的,前者需要动态创建页表,而后者在系统初始化完成后就不再改变。此时存在一个问题,所有进程看到的应该是相同的内核地址空间,所以理论上在vmalloc时需要修改所有进程页表中对应的内核部分,这种方式代价太大,采用了按需同步页表的方式,当新创建的vmalloc区域时,只修改了init_mm中的页表映射,进程没有对应的页表项,之后第一次vmalloc区域时,访问触发MMU异常,在handle_mm_fault中校验属于有效的vmalloc区域,此时从init_mm中同步相应的页表。
访问权限异常只有一种情形:进程fork时的COW机制
进程fork创建一个新的进程,同时子进程也有独立的地址空间。早期会复制父进程中所有内存相关的:mm_struct,VMA和页表项,但是大部分子进程不再执行exec加载新的程序,父子进程共享大部分地址空间和数据,而且复制过程的代价相当昂贵,所以发明了COW机制,fork的时候只复制mm_struct和vma,公用一份页表,同时将所有页表项都修改成只读属性。当父子进程中任意一个开始写数据的时候,因为权限异常触发MMU异常。在缺页异常处理中对比VMA中的读写属性为RW,此时就认为是COW,1.重新分配物理页并拷贝原始页内容到新的物理页中,2,修正新的页表项属性 3,修正旧的页表项属性
缺页异常中能够修复的情况如上所述,当无法修复异常的时候,对用户空间地址的访问造成的错误向该进程投递SIGSEGV信号,对内核空间地址访问造成的异常触发oops。
而内核开发人员从缺页异常的修复代价角度又划分了major和minor两种。
minor指的是只分配物理内存而不发生IO,而major指的是既分配物理内存又发生IO操作,而访问内存和磁盘的速度差了近千倍,所以major类异常耗时会更长。
内存回收
kernel在分配内存时,可能会涉及到多个zone,分配会尝试从zonelist第一个zone分配,如果失败就会尝试下一个低级的zone(这里的低级仅仅指zone内存的位置,实际上低地址zone是更稀缺的资源)。我们可以想像应用进程通过内存映射申请Highmem 并且加mlock分配,如果此时Highmem zone无法满足分配,则会尝试从Normal进行分配。这就有一个问题,来自Highmem的请求可能会耗尽Normal zone的内存,而且由于mlock又无法回收,最终的结果就是Normal zone无内存提供给kernel的正常分配,而Highmem有大把的可回收内存无法有效利用。
因此针对这个case,使得Normal zone在碰到来自Highmem的分配请求时,可以通过lowmem_reserve声明:可以使用我的内存,但是必须要保留lowmem_reserve[NORMAL]给我自己使用。
同样当从Normal失败后,会尝试从zonelist中的DMA申请分配,通过lowmem_reserve[DMA],限制来自HIGHMEM和Normal的分配请求。
内存api
| alloc_page | 从buddy中申请物理页 |
|---|---|
| kmalloc | 从内置固定size的slab中申请对象 |
| vmalloc | 申请非连续页,并返回虚拟地址 |
| kmap/kunmap | 根据page临时映射虚拟地址 |
| sys_sbrk/sys_mmap | 用户程序申请虚拟空间 |
| iomap | 为IO设备映射vmalloc区域地址 |
内存调试
内存践踏:这种情况下经常发生在写时越界问题,可能是在栈上越界,也有可能是堆上数据越界,也有可能是野指针导致的数据错乱。
这种情况一般可以在对象上下边界加上特定的magic数字来判定是否发生连续写导致的越界问题,例如内核slab的red zone,当错误发生后检查magic有没有被破坏可以探测这种行为。
从现场的特征上来分辨,栈上越界写导致的错误,当使用backtrace查看堆栈时可能会发现堆栈不符合代码逻辑,无法理解.这种是栈上存放返回地址的数据被写坏了;
发生在堆区域的写越界问题,当通过gdb或者crash读内存信息时会看到对象的数据不合理,但是堆栈显示是正常的。
对象重用:内核中的这种问题更加常见,特别是引用计数异常引起的对象重用问题。假设CPU0上routine 0中正在使用obj1并且对其增加引用计数,CPU1上routine 1中正在使用obj1但是并未增加对其引用,之后CPU0上routine0不再使用obj1并决定对其进行销毁返回给slab中.之后CPU2上routine 2从slab中申请一个对象得到了obj1的地址并对其进行修改操作,接下来CPU1上routine 1就会发现obj1的数据很奇怪。内核中很多的BUG_ON,WARNING_ON设计时和用户空间的assert一样,断言错误的时候主动引起系统崩溃来使开发者注意,而断言错误发生很多都是由对象引用计数问题引起的对象重用.
这种没有好的解决方法,只能对修改对象引用的位置进行统计和日志记录来排查问题.
内存泄露:使用C/C++编程的痼疾,稍有不注意就会发生内存泄漏问题,相对应的也有很多工具来解决这个问题:valgrind --tool=memcheck --leak-check=full,address santinizer,内核的SLAB_DEBUG,KASAN等.除了内核支持的工具之外,还可以自己封装调试接口,例如对自己代码中的kmalloc/kfree统计.
内存泄漏和对象重用在内核中仅一线之差,对象一直不释放就是内存泄漏,正在使用中就提前释放并且被重用就是对象重用问题。
重复释放:问题一般发生在用户空间中,在内核中对象的释放一般是通过引用计数来表示当前引用的,最后一个引用释放时进行对象释放,接下来对这个对象释放一般都是有BUG_ON的检查,重复释放当场就会触发BUG_ON,WARNING_ON;而用户空间重复释放问题比较容易查找,一般有glibc自带的扩展功能mcheck,它目前基本是默认打开的;另外还可以使用其他的tcmalloc,dmalloc等第三方调试库