计算机体系结构学习 --- RISC-V(一)
计算机体系结构学习 --- RISC-V(一)
1、Instructions for making decisions
条件语句实际上有6种类型,最基本的有两种:
beq rs1,rs2,L1 //若rs1=rs2,那么跳转到L1 bne rs1,rs2,L1 //若rs1!=rs2,那么跳转到L1
这两个指令都是关于有符号数的等于和非等于的关系,但是大小比较除了这样的关系之外,还有大于,小于等于这样的关系,因此有:
若与中均为补码,且和相比,更小,那么就取该分支若,采取该分支
若与中均为无符号数,且和相比,更小,那么就取该分支同理,若和均为无符号数,,采取该分支
条件语句的运用范围非常广泛,包括Loops(循环),Bounds check shortcut(索引检查),Case/Switch statement(用于Case/Switch)等等;
(1)Loops:
举一个例子,以C语言为例:
while(save[i] == k)
i += 1;
我们设save数组的base地址存在x25,i:x22,k:x24;那么就有assembly programmable language为:
Loop:
slli x10,x22,3 //i*8
add x10,x10,x25 //x25+x10,确定新save[i]的地址
ld x9,0(x10) //将save[i]的值读入x9寄存器中
bne x9,x24,EXIT //若x9==x24,就跳转EXIT
addi x22,x22,1 //i+1
beq x0,x0,LOOP //非条件跳转,一定会返回LOOP处
EXIT:
其中,条件语句外的简单语句被称为basic block。编译中要做的第一件事就是将程序打平成basic block的形式,后面会说到。
(2)Bounds check shortcut:
这是一种特别的情况,例如如下代码:
bgeu x20,x11,IndexOutofBounds //若x20 >= x11,或者x20<0的话,那么就可以将branch引向索引越界
(3)Case/Switch statement:
利用branch address table/branch table(选择条件序列的地址表),程序只要索引到表中,再分支到对应的sequence中即可;其中,branch table是存放着双字地址的表格;
条件语句包含跳转含义,而实行跳转还有无条件跳转语句,RISC-V中提供了两种无条件条件语句,包括jalr和jal。
2、Supporting Procedures in Computer Hardware
(1)对于程序中包含两种特殊跳转,procedure/function,过程/函数;关于过程和函数的执行流程略。
其中用于分配procedure的32位寄存器有x10-x17,用于存储返回值。而x1是用于返回原来地址的寄存器。
在过程语句和函数语句中,有两种无条件跳转,分别为jal(jump-and-link instrcution),这个语句使用方式如下:
jal x1,ProcedureAdress //跳转到ProcedureAdress处,并将原来程序的地址写入x1
而jalr用于返回原来的地址,如下所示:
jalr x0,0(x1) //无条件跳转回原来的程序地址,用于跳转caller程序
用于存储当前地址的寄存器,称为PC(program counter)。在连续执行的情况下,用jal实现,每次返回的地址设为PC+4,再存入x1即可。或者有jal x0,Label,即无条件跳转至Label处,但是不返回任何值作为存储。
其中,有一个很关键的一点是,就是寄存器值是有限的,我们有的时候需要不止8个寄存器,此时我们使用stack(堆栈)对需要返回的地址和要用到的值进行存储。这样的过程称为spil registers to memory。特别注意的是堆栈的地址是从高到低的。
堆栈是一种last-in-first-out的队列。在使用堆栈时,我们需要一个堆栈指针sp(stack pointer),通常是x2。
举一个典型例子,以C语言程序为例:
long long int leaf_example(long long int g,long long int h,long long int i,long long int j)
{
long long int f;
f = (g+h)-(i+j);
return f;
}
设g,h,i,j分别分到了寄存器x10,x11,x12,x13中,temp变量分到x20中,(g+h)分到x5,(i+j)分到x6中,其中,x20,x5,x6要被保存下来,将结果转为RISC-V的汇编语言,即为:
addi sp,sp,-24 sd x5,16(sp) sd x6,8(sp) sd x20,0(sp) add x5,x10,x11 //x5中存储的是g+h add x6,x12,x13 //x6中存储的是i+j sub x20,x5,x6 //x20为f addi x10,x20,0//将f的值放入x10中传递回去 ld x20,0(sp) ld x6,8(sp) ld x5,16(sp) addi sp,sp,24 //删除这个堆栈
但是如果堆栈中的每一个值都需要被保存的话,是没有必要的,尤其对于一个leaf procedure而言,有些temp是不用被保存的。
因此32个寄存器被分为两组:
对于函数相互调用的情况下, 有x1会互相冲突,此时需要将x1也保存下来。
x3可以设为global pointer。
有的时候,为了方便的获取堆栈中的值,我们还会设置一个frame pointer,fp,存在x8中,令其一直指向堆栈的栈顶。
(2)内存分配,内存分配是一个很重要的概念。数据,程序等等在计算机内存中存放按照由高到低分别为stack,dynamic data,static data,text,reserved的顺序。而stack由上向下,其余由下向上。text中存入的是program code。
具体使用后面讨论编译器的时候会说。
3、Communicating with people
我在第38周的周报中已经讨论过这个问题,就是关于加载值的字长的问题,后面还会再说到。字长通过不同的指令可以加载byte,halfwords,doublewords,words四种。
4. RISC-V Addressing for wide immediates and Addresses
(1)这里涉及到一个问题就是当需要加载的立即数不止12bit长度的时候,我们没有办法使用ld这样的命令。我们采用一种新型的指令,lui(load upper immediate)。这种指令不是ld这种I-type,而是U-type,事实上,U-type只有lui这一种命令。其可以用于加载20-bit立即数。其余12bit用0填充。
例如我们需要将一个64-bit的立即数放入寄存器x19中,则有 0000 0000/0000 0000/0000 0000/0000 0000/0000 0000/0011 1101/0000 1001/0000 0000。
使用lui将下划线的值存入x19中,即有
lui x19,976
这时再使用
addi x19,x19,1280 //0000 1001 0000 0000
即可获得正确的64bit的值。
(2) 对于bne这种判断语句,为SB-type,它有12bit的立即数,为了可以获得所有的地址值,因此其求地址的方法是PC-relative addressing。
由于SB-type这样的格式提供一个符号位,因此可以向前和向后进行跳转12bit。
其格式如下所示,以
bne x10,x11,2000
为例:
| imm[12] | imm[10:5] | rs2 | rs1 | funct3 | imm[4:1] | imm[11] | opcode |
|---|---|---|---|---|---|---|---|
| 0 | 111110 | 01011 | 01010 | 001 | 1000 | 0 | 1100111 |
但是因为bne这样的语句只可以跳转到偶数地址上。
但是PC-relative addressing 仅仅针对的是12bit内相关的地址,因此在地址位于12bit之外的情况,我们需要有一种可以跳转的格式:
beq x10,x0,L1 //在x10 == 0的时候,就跳转到L1处,假设L1非常远,则有 => bne x10,x0,L2 jal x0,L1 L2: //即若x10 != 0就跳转到L2处,否则就用L1跳到别的地方去
(3)对于jal语言,为UJ-type。它可以跳转到20-bit之外的地址。此时有UJ-type的格式为:
以
jal x0,2000
为例,有
| imm[20] | imm[10:1] | imm[11] | imm[19:12] | rd | opcode |
|---|---|---|---|---|---|
| 0 | 111101000 | 0 | 00000000 | 00000 | 1101111 |
(4) RISC-V addressing mode summary
对于RISC-V的不同汇编指令进行研究可以发现,RISC-V有四种寻址求值方式,分别为
直接去立即数作为操作数,例如移位指令取寄存器的值作为操作数,例如指令函数从内存中获得的类型计算地址为
RISC-V机器语言的格式有6种:
R-type -- add,sub,sll,or,and,...lr.d,sc.d等
I-type -- 取指指令,addi,slli等
S-type -- 存储指令
SB-type -- 条件执行语句
U-type -- lui加载语句
UJ-type -- jal 语句
5、Parallelism and instructions: Synchronization
由于存在data race情况,因此我们需要同步机制,synchronization mechanisms。通常可以采用lock和unlock用于实现只有一个processor可运行的区域,叫做mutual exclusion,互斥机制。
对于同步机制,典型操作就是原子操作,atomic operation。原子操作的含义是多线程中操作不会被线程调度机打断操作,操作一旦开始就会一直运行到结束,中间不会换到另一个线程。
有一种典型的原子操作命令就是lr.d和sc.d(load-reserved doubleword和store-reserved doubleword),这两者命令若lr.d的内存在sc.d工作之前被修改,那么sc.d会失败且不向内存中写值。而sc.d不仅在内存中存储值,若成功将某个寄存器值改为0,否则为非0值。 // 0表示可以访问和修改,1表示已有程序在使用
sc.d 涉及三种寄存器,分别是hold the address,whether the atomic operation failed or succeed,value to be stored in memory if it is succeed.
例如有程序:
again: lr.d x10,(x20) //将x20值放入x10中 sc.d x11,x23,(x20) //将x23值放入x20中,并将成功与否返回x11中 bne x11,x0,again //判断存储是否成功 addi x23,x10,0 //若成功,将x10的值放入x23中。 //从而实现x20和x23的swap
6、Translating and Starting a Program
这样一个过程实际就是C语言在外存中(disk/flash memory)中存储,转为一个可以在计算机上跑的程序。
转换过程分为4步,以C语言为例,对于一个C program而言,先通过Compiler将高级语言(x.c文件)转为Assembly language program(x.s文件),再通过Assembler转为o文件,o文件和library库一起通过Linker转为可执行文件(x.exe文件)。可执行文件再通过Loader加载到内存中去。
(1)Assembler转换成的结果为o文件,o文件中包括object file header,用于描述object file的其他文件的大小和位置,text segment中包含机器码,static data segment中包含程序中所用到的数据,relocation information写入的是当程序加载入memory时指令与数据的地址,symbol table中包含一些外界参量的未被定义的label,而debugging information中用于描述C与机器码之间的编译情况。
(2) 通过Linker实现了一个可执行文件,这样一个可执行文件的主要工作是为代码和数据分配真实的内存地址。将多个object文件连接在一起。
(3) Loader将可执行文件从外部的disk通过操作系统读入内存,并开始使用。
(4)其中,library的链接可以分为静态和动态,静态容易导致disk-level waste,而动态易导致memory-level waste。关于动态链接库,Dynamically Linked Libraries(DLLs),第一次library routines被调用的时候,需要经过branches to the dynamic linker/loader,而当动态加载器/连接器被找到后,那么就需要重新布局,改变某些地址。当routine被找到后,就回到原来的地点。而再次调用的时候,就会被直接调用。
(5) 对java而言,这样的过程有所不同,java的目的是可以安全的在任何电脑上运行,因此java的编译与C不同,java直接编译成一种解释语言,称为java bytecode,通常这一步没有任何优化。通过解释器,将java bytecodes与java library routines链接在一起,通过解释器获得machine codes,这种软件解释器,称为Java virtual machine(JVM),可以执行Java bytecode。
所谓的解释器,interpreter,就是仿真指令集的程序,其中,interpreter的一部分是可携带的,但是因为使用解释器导致没有使用loader和linker快。一般java程序会比C程序慢10倍左右。
因此,java有另一种实时解释器,称为JIT,Just In Time Compiler。
7、A C Sort Example to Put it all together
这部分再次强调了C语言转为汇编的过程,且有,程序的运行时间是唯一可以正确衡量表现性能的指标,而像CPI(clocks per instruction)这种单位指令所需要的时钟周期的标准都会因为在不同指令集下程序规模不同,且每一个指令所需要的时钟周期不同而导致衡量的不准确。
8、Arrays versus Pointer
可以说指针是C语言中一个非常关键的内容,因为指针可以加快程序的运行,而数组和它相比,在数据规模较大的时候速度降低不止几个量级。对于指针而言,其中存放的是某一个变量的地址,*p_a = &a,对指针的调用可以是 :/ *p_a,相当于取到了a的值,而实际上,指针可以指向数组,在学习C语言的时候,指针数组和数组指针也是两个非常容易混淆的概念。个人在使用的时候其实非常不喜欢使用数组指针。
因为数组指针的定义是这样的,int (*p_a)[20],在使用(/ *p_a)[0]..就是表示数组中的值,非常别扭。因此我在对数组进行操作的时候还是会使用普通指针。
如果从汇编语言的角度来看,实际上,使用指针可以减少对于数组地址的求解,从而减少循环中的计算过程,提高效率。详细的过程略。
按照书中所说,现在很多编译器可以代替我们完成指针的优化。
9、Advanced Material : Compiling C and Interpreting Java
补充一个知识:Java这种属于object-oriented language。而非以actions/data vs logic。
(1)首先要了解C的编译器的一般组成:
一个编译器通常有四步组成。
第一步为The front end,通常也分为四个部分,scanning(对程序中的字符进行扫描,区分names,reserved,words,operators,punctuation symbols,number等等),parsing(用于建立abstract syntax tree语义抽象树),semantic analysis(语义分析,可以用于检查type等等,用于形成symbol table),generation of the intermedia representation,最后生成一个中间表达)。中间表达和汇编语言已经非常相似,但是其默认可以使用无限的寄存器和资源。
实际上,在第一步之后,后面的操作与语言本身无关。
第二步为High-level optimizations,通常这一步进行loop-unrolling的优化。
第三步为Local and Global Optimizations,包含common subexpression elimination,constant propogation,copy propogation,dead store elimination 和 strength reduction。
其中,common subexpression elimination这样的步骤中会减少某些不必要的寄存器使用,例如x[i] = x[i]+4,目标地址的x[i]就不需要再次计算。
global code optimization,有两种非常重要的分别是 code motion 和 induction variable elimination,code motion就是将循环中某些一直重复的值从循环中提出来,从而使循环变得简洁,而 induction variable elimination 则是减少数组寻址方式,增加指针寻址。
具体关于local 和global的优化是如何实现的我就没有仔细看。
第四步中,code generator一般进行寄存器分配事项。
10、Fallacy and pitfalls:
既然可以写汇编语言以获得高效表达,那么我们为什么不使用汇编语言呢?
作者谈到,软件工程的公理之一就是if you write more lines, coding takes longer。且汇编语言难以debugging。
11、Arithmetic for Computers:
计算机的运算可以说是计算机可以完成程序的执行的非常关键的部分,对于地址的计算等等都是基于运算进行的。因此我们需要解决的问题包括计算机如何进行算术运算,硬件如何工作,如何让算术密集型程序跑的更快等等。
12、Addition and Subtraction:
对于计算机而言,加法和减法实质上是一样的。
对于计算机而言,有溢出的问题。有规律如下,异号相加不会溢出,同号相减不会溢出。对于加法而言,64-bit+64-bit,结果应该用65-bit去表示,因此相当于缺少符号位。溢出的情况有四种,分别是正数相加结果为负,负数相加结果为正,正减负得负,负减正得正。
(1) 关于ALU的实现方法,计算机设计者要考虑如何处理计算溢出的问题,实际上,关于两个补数的运算考虑得更多一些;
13. Multiplication
可以看到,使用的是128bit的寄存器存放Multiplicand,并放在低位上,使用64bit存放Multiplier,使用128bit存放Product。Multiplicand左移,Multiplier右移。这样的过程重复64次后,就可以得到结果了。
对于这样的结构,我们可以进行优化,得到如下的结构:
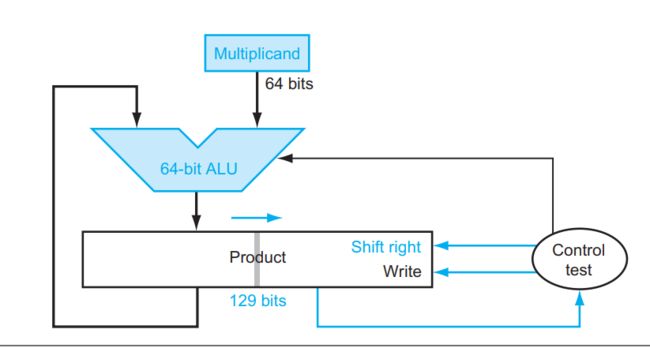
如图所示,我们将mulitplier放入product中的右边,每次与multiplicand相乘后将结果写入Product的左边,最后就可以得到正确的结果。
(2)对于RISC-V而言,对于乘法的指令有四种,分别为mul,mulh,mulhu,mulhsu。其中,mul得到的结果是64-bit product,mulh获得两个有符号数乘积的高64位,mulhu和mulshu以此类推。
(3)书中提到的faster multiplication我不是很明白。。但是我猜应该和Verilog的快乘是一个道理吧。。
14. Divison
除法出现的频率比乘法还要少,但是A’s law表示不能优化的指令就会影响最后的结果,因此我们也需要对除法进行研究。
对于除法而言,有除数(Divisor),被除数(Dividend),商(Quotient)和余数(Remainder),这四者的关系不再赘述。
可以看到,我们有被除数放在Remainder中,Divisor放在128bit的左边,每次将Divisor 与Remainder相减,若值小于0,就加回去,若大于0,那么就令Quotient左移的一位为0,这样的过程进行65次就可以了。