LeetCode刷题笔记(Java)---更新至218题
文章目录
- 201. 数字范围按位与
- 202. 快乐数
- 203. 移除链表元素
- 204. 计数质数
- 205. 同构字符串
- 206. 反转链表
- 207. 课程表
- 208. 实现 Trie (前缀树)
- 209. 长度最小的子数组
- 210. 课程表 II
- 211. 添加与搜索单词 - 数据结构设计
- 212. 单词搜索 II
- 213. 打家劫舍 II
- 214. 最短回文串
- 215. 数组中的第K个最大元素
- 216. 组合总和 III
- 217. 存在重复元素
- 218. 天际线问题
201. 数字范围按位与
给定范围 [m, n],其中 0 <= m <= n <= 2147483647,返回此范围内所有数字的按位与(包含 m, n 两端点)。

- 解答
public static int rangeBitwiseAnd(int m, int n) {
int offset = 0;
while (m != n) {
m >>= 1;
n >>= 1;
offset++;
}
return m << offset;
}
-
分析
1.寻找m,n的公共前缀。相同的部分返回即可。
-
提交结果
202. 快乐数
编写一个算法来判断一个数 n 是不是快乐数。
「快乐数」定义为:对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和,然后重复这个过程直到这个数变为 1,也可能是 无限循环 但始终变不到 1。如果 可以变为 1,那么这个数就是快乐数。
如果 n 是快乐数就返回 True ;不是,则返回 False 。
- 解答
public boolean isHappy(int n) {
while (n != 1) {
if (n == 4 || n == 16 || n == 37 || n == 58 || n == 89 || n == 145 || n == 42 || n == 20)
return false;
int tmp = 0;
while (n > 0) {
tmp += Math.pow(n % 10, 2);
n = n / 10;
}
n = tmp;
}
return true;
}
-
分析
1.当一个数字进入某个循环则是不快乐的数,
这个循环就是4 → 16 → 37 → 58 → 89 → 145 → 42 → 20 → 4
2.所以当遇到以上的数字直接返回false。 -
提交结果
203. 移除链表元素
删除链表中等于给定值 val 的所有节点。

- 解答
public static ListNode removeElements(ListNode head, int val) {
if (head == null) return head;//头为空直接返回
while (head != null && head.val == val) head = head.next;//删掉头部和val相同的所有元素
if (head == null) return head;
ListNode p = head.next;
ListNode pre = head;
while (p != null) {//遍历剩余链表
if (p.val == val) {//删除值为val的元素
pre.next = p.next;
p = pre.next;
} else if (p.next != null) {
pre = p;
p = p.next;
} else break;
}
return head;
}
-
分析
1.头为空直接返回
2.第一个while用于删掉头部和val值相同的结点
3.先后两个指针遍历链表用于删除值为val的结点。 -
提交结果

204. 计数质数
统计所有小于非负整数 n 的质数的数量。

- 解答
public static int countPrimes(int n) {
boolean[] prims = new boolean[n];
Arrays.fill(prims, true);
for (int i = 2; i * i < n; i++) {
if (prims[i]) {
for (int j = i * i; j < n; j = j + i) {
prims[j] = false;
}
}
}
int res = 0;
for (int i = 2; i < n; i++) {
if (prims[i]) res++;
}
return res;
}
-
分析
1.使用埃拉托色尼筛选法
将质数的倍数标记为不是质数
2.给定数字n。只需要判断前sqrt(n)能不能被n整除即可,所以外层循环从2-sqrt(n)
3.内层循环存在着计算冗余,例如计算2的倍数的时候 4,6,8,10,12均不是质数
计算3的倍数的时候6,9,12不是质数,其中6,12在计算2的倍数的时候已经出现了,为了减少计算的冗余,内存循环的起始位置为i*i -
提交结果

205. 同构字符串
给定两个字符串 s 和 t,判断它们是否是同构的。
如果 s 中的字符可以被替换得到 t ,那么这两个字符串是同构的。
所有出现的字符都必须用另一个字符替换,同时保留字符的顺序。两个字符不能映射到同一个字符上,但字符可以映射自己本身。

- 解答
//方法一
public static boolean isIsomorphic(String s, String t) {
int len = s.length();
HashMap<Character, Character> map = new HashMap<>();
for (int i = 0; i < len; i++) {
if (!map.containsKey(s.charAt(i)) && map.containsValue(t.charAt(i)) ||
map.containsKey(s.charAt(i)) && map.get(s.charAt(i))!=(t.charAt(i)))
return false;
else map.put(s.charAt(i),t.charAt(i));
}
return true;
}
//方法二
-
分析
1.方法一用map来记录映射关系
2.有两种情况会返回false当map中键中不存在字符s.charAt(i)),但value中存在t.charAt(i) 当map中键中存在字符s.charAt(i)),但对应的value和t.charAt(i)不相同3.方法二用两个数组来记录字符出现的位置。
若两个字符对应出现的位置和之前的不一样,则说明已经存在着其他的映射关系 -
提交结果
方法一

方法二

206. 反转链表
反转一个单链表。

- 解答
//方法一
public ListNode reverseList(ListNode head) {
if(head==null || head.next==null)return head;
ListNode h = head;
ListNode pre = head;
ListNode p = head.next;
while (p!=null){
pre.next = p.next;
p.next = h;
h = p;
p = pre.next;
}
return h;
}
//方法二
public ListNode reverseList(ListNode head) {
if (head == null || head.next == null) return head;
ListNode p = reverseList3(head.next);
head.next.next = head;
head.next = null;
return p;
}
-
分析
1.定义三个指针来辅助反转
h始终指向链表的头
p始终指向要反转的结点
pre始终指向要反转的结点的前一个结点
2.然后遍历链表,修改相应的结点关系即可。
3.方法二使用递归。相当于从原来链表的末尾开始反转链表。 -
提交结果
方法一

方法二

207. 课程表
你这个学期必须选修 numCourse 门课程,记为 0 到 numCourse-1 。
在选修某些课程之前需要一些先修课程。 例如,想要学习课程 0 ,你需要先完成课程 1 ,我们用一个匹配来表示他们:[0,1]
给定课程总量以及它们的先决条件,请你判断是否可能完成所有课程的学习?

- 解答
public boolean canFinish(int numCourses, int[][] prerequisites) {
int[] inTable = new int[numCourses];
List<List<Integer>> lists = new ArrayList<>();
Queue<Integer> queue = new LinkedList<>();
//新建一个空的邻接表
for (int i = 0; i < numCourses; i++) {
lists.add(new ArrayList<>());
}
//遍历边,计算每个点的入度,并且将结点表示在邻接表中
for (int i = 0; i < prerequisites.length; i++) {
inTable[prerequisites[i][0]]++;
lists.get(prerequisites[i][1]).add(prerequisites[i][0]);
}
//遍历所有的结点,将入度为0的结点加入到队列中
for (int i = 0; i < numCourses; i++)
if (inTable[i] == 0) queue.add(i);
//广度优先搜索
while (!queue.isEmpty()) {
int num = queue.poll();
numCourses--;
for (int cur : lists.get(num))
if (--inTable[cur] == 0) queue.add(cur);
}
return numCourses == 0;
}
-
分析
1.入度为0的点表示没有先修课程
2.入度为0的点删除,将其关联的课程入度减少1.
最后比较是有还有结点剩余。 -
提交结果
208. 实现 Trie (前缀树)
实现一个 Trie (前缀树),包含 insert, search, 和 startsWith 这三个操作。

- 解答
class Trie {
private boolean is_string=false;
private Trie[] next;
private final int number = 26;
public Trie(){
next = new Trie[number];
}
public void insert(String word){//插入单词
Trie root=this;
char w[]=word.toCharArray();
for(int i=0;i<w.length;++i){
if(root.next[w[i]-'a']==null)root.next[w[i]-'a']=new Trie();
root=root.next[w[i]-'a'];
}
root.is_string=true;
}
public boolean search(String word){//查找单词
Trie root=this;
char w[]=word.toCharArray();
for(int i=0;i<w.length;++i){
if(root.next[w[i]-'a']==null)return false;
root=root.next[w[i]-'a'];
}
return root.is_string;
}
public boolean startsWith(String prefix){//查找前缀
Trie root=this;
char p[]=prefix.toCharArray();
for(int i=0;i<p.length;++i){
if(root.next[p[i]-'a']==null)return false;
root=root.next[p[i]-'a'];
}
return true;
}
}
-
分析
1.用树的边表示字符
一个结点对应26个字母。即需要一个26大小的数组。
2.插入的操作,就是从根结点遍历,若当前结点的字母数组中该字符还没有结点,则将该字符添加。若已有,则根据字母数组得到下一个结点。
3.查找操作,遍历树,寻找字符匹配,若有字符没有则返回false。若找到了匹配的字符串,则要判断最后一位字符上的标识位是否表明这是一个原先添加的字符串。
4.查找前缀和查找操作类似。 -
提交结果
209. 长度最小的子数组
给定一个含有 n 个正整数的数组和一个正整数 s ,找出该数组中满足其和 ≥ s 的长度最小的连续子数组,并返回其长度。如果不存在符合条件的连续子数组,返回 0。

- 解答
public int minSubArrayLen(int s, int[] nums) {
int left = 0;
int minLen = Integer.MAX_VALUE;
int sum = 0;
for (int i = 0; i < nums.length; i++) {
sum += nums[i];
while (sum >= s) {
minLen = Math.min(minLen, i - left + 1);
sum -= nums[left];
left++;
}
}
return minLen != Integer.MAX_VALUE ? minLen : 0;
}
-
分析
1.双指针
left初始化指向数组首位,i指向子数组的末尾
2.遍历数组
每次遍历先计算子数组的和
若当前的子数组的和大于s的时候
一个while循环来修改left指针
计算当前的left和i之间子数组的长度。和原来的minLen进行比较,保留更小的。
然后移动left 将sum减去原来left指向的数值。
3.这样数组中的每一位最多只会被访问两次,加入sum中一次,删去一次。 -
提交结果

210. 课程表 II
现在你总共有 n 门课需要选,记为 0 到 n-1。
在选修某些课程之前需要一些先修课程。 例如,想要学习课程 0 ,你需要先完成课程 1 ,我们用一个匹配来表示他们: [0,1]
给定课程总量以及它们的先决条件,返回你为了学完所有课程所安排的学习顺序。
可能会有多个正确的顺序,你只要返回一种就可以了。如果不可能完成所有课程,返回一个空数组。


- 解答
public static int[] findOrder(int numCourses, int[][] prerequisites) {
int[] res = new int[numCourses];
int index = 0;
int[] inTable = new int[numCourses];
//计算所有结点的入度
for (int[] prerequisite : prerequisites) {
inTable[prerequisite[0]]++;
}
Queue<Integer> queue = new LinkedList<>();
//遍历结点
for (int i = 0; i < numCourses; i++) {
//找到入度为0的点
if (inTable[i] == 0) {
queue.add(i);//入队
while (!queue.isEmpty()) {//队不空
int num = queue.poll();
res[index++] = num;//添加到上课顺序表上
// 修改相关结点的入度
for (int[] prerequisite : prerequisites) {
if (prerequisite[1] == num) {
inTable[prerequisite[0]]--;
//若有结点更新后 入度为0,则入队
if (inTable[prerequisite[0]] == 0) {
queue.add(prerequisite[0]);
inTable[prerequisite[0]] = 1;//这一步是为了避免外层for循环再一次访问他
}
}
}
}
}
}
return index == numCourses ? res : new int[]{};
}
-
分析
1.首先根据关链表,计算出所有结点的入度
2.遍历所有结点,找到入度为0的点将其入队
3.若队不空,则每次从队中取出一个,表示上课的顺序。
将相关联的结点入度-1.若更新后发现其入度为0,则将其入队
4.入度为0的点入队后,将其入度设置为非0,是为了避免外层循环再一次访问他,再次将它入队 -
提交结果
211. 添加与搜索单词 - 数据结构设计
设计一个支持以下两种操作的数据结构:
void addWord(word)
bool search(word)
search(word) 可以搜索文字或正则表达式字符串,字符串只包含字母 . 或 a-z 。 . 可以表示任何一个字母。

- 解答
public class WordDictionary {
WordNode root;
/**
* Initialize your data structure here.
*/
public WordDictionary() {
root = new WordNode();
}
/**
* Adds a word into the data structure.
*/
public void addWord(String word) {
WordNode p = root;
//遍历字符串
for (int i = 0; i < word.length(); i++) {
//判断当前结点下是否已有这一位字符,若没有则添加
if (!p.map.containsKey(word.charAt(i))) {
WordNode node = new WordNode();
//若是末尾字符,则将标示位置为true
if (i == word.length() - 1) node.isEnd = true;
p.map.put(word.charAt(i), node);
} else {
//若已存在该字符,并且是末尾字符,则将标示位置为true
if (i == word.length() - 1) {
WordNode node = p.map.get(word.charAt(i));
node.isEnd = true;
}
}
//p下移动
p = p.map.get(word.charAt(i));
}
}
/**
* Returns if the word is in the data structure. A word could contain the dot character '.' to represent any one letter.
*/
public boolean search(String word) {
return equal(word, root, 0);
}
//回溯来遍历整一颗树
public boolean equal(String word, WordNode node, int depth) {
boolean flag = false;
if (depth == word.length() && node.isEnd) return true;
if (depth >= word.length()) return false;
HashMap<Character, WordNode> map = node.map;
for (Character character : map.keySet()) {
if (character == word.charAt(depth) || word.charAt(depth) == '.') {
flag = equal(word, map.get(character), depth + 1);
if (flag) return flag;
}
}
return flag;
}
class WordNode {
boolean isEnd;
HashMap<Character, WordNode> map;
WordNode() {
isEnd = false;
map = new HashMap<>();
}
}
}
-
分析
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-z9dOA2Qz-1593307480202)(evernotecid://EF499CBE-6F21-456C-AADA-9EC15B7F974E/appyinxiangcom/26462351/ENResource/p835)]
1.如图构建一颗树,红圈表示是字符串末尾字符。
2.用到结点的数据结构就是
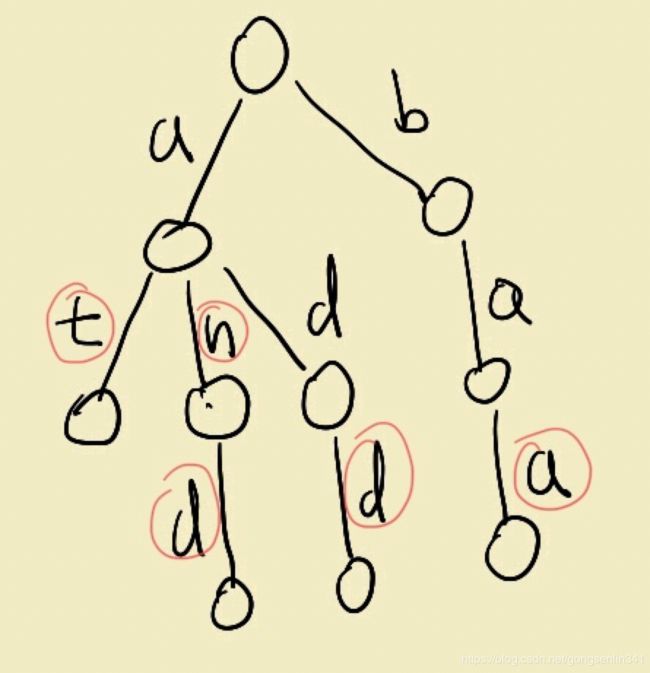
标示位isEnd表示是否是末尾字符
HashMap -
提交结果
212. 单词搜索 II
给定一个二维网格 board 和一个字典中的单词列表 words,找出所有同时在二维网格和字典中出现的单词。
单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母在一个单词中不允许被重复使用。

提示:
你需要优化回溯算法以通过更大数据量的测试。你能否早点停止回溯?
如果当前单词不存在于所有单词的前缀中,则可以立即停止回溯。什么样的数据结构可以有效地执行这样的操作?散列表是否可行?为什么? 前缀树如何?如果你想学习如何实现一个基本的前缀树,请先查看这个问题: 实现Trie(前缀树)。
- 解答
public List<String> findWords(char[][] board, String[] words) {
List<String> res = new ArrayList<>();
//判断每个单词
for (String word : words)
if (exist2(board, word)) {
res.add(word);
}
return res;
}
public boolean exist2(char[][] board, String word) {
int rows = board.length;
if (rows == 0) {
return false;
}
int cols = board[0].length;
for (int i = 0; i < rows; i++) {
for (int j = 0; j < cols; j++) {
if (existRecursive(board, i, j, word, 0)) {
return true;
}
}
}
return false;
}
private boolean existRecursive(char[][] board, int row, int col, String word, int index) {
if (row < 0 || row >= board.length || col < 0 || col >= board[0].length) {
return false;
}
if (board[row][col] != word.charAt(index)) {
return false;
}
if (index == word.length() - 1) {
return true;
}
char temp = board[row][col];
board[row][col] = '$';
boolean up = existRecursive(board, row - 1, col, word, index + 1);
if (up) {
board[row][col] = temp;
return true;
}
boolean down = existRecursive(board, row + 1, col, word, index + 1);
if (down) {
board[row][col] = temp;
return true;
}
boolean left = existRecursive(board, row, col - 1, word, index + 1);
if (left) {
board[row][col] = temp;
return true;
}
boolean right = existRecursive(board, row, col + 1, word, index + 1);
if (right) {
board[row][col] = temp;
return true;
}
board[row][col] = temp;
return false;
}
-
分析
1.寻找一个单词在board中是否存在。
2.遍历words,之后就是79题的解法 -
提交结果
213. 打家劫舍 II
你是一个专业的小偷,计划偷窃沿街的房屋,每间房内都藏有一定的现金。这个地方所有的房屋都围成一圈,这意味着第一个房屋和最后一个房屋是紧挨着的。同时,相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。
给定一个代表每个房屋存放金额的非负整数数组,计算你在不触动警报装置的情况下,能够偷窃到的最高金额。

- 解答
public static int rob3(int[] nums) {
if(nums.length == 0) return 0;
if(nums.length == 1) return nums[0];
return Math.max(myRob(Arrays.copyOfRange(nums, 0, nums.length - 1)),
myRob(Arrays.copyOfRange(nums, 1, nums.length)));
}
private static int myRob(int[] nums) {
int pre = 0, cur = 0, tmp;
for(int num : nums) {
tmp = cur;
cur = Math.max(pre + num, cur);
pre = tmp;
}
return cur;
}
-
分析
1.因为首尾相连,所以只要考虑除去尾的数组中寻找最高金额,和除去头部的数组中寻找最高金额。
2.再返回两个结果中较大者 -
提交结果

214. 最短回文串
给定一个字符串 s,你可以通过在字符串前面添加字符将其转换为回文串。找到并返回可以用这种方式转换的最短回文串。

- 解答
public String shortestPalindrome(String s) {
String r = new StringBuilder(s).reverse().toString();
int n = s.length();
int i = 0;
for (; i < n; i++) {
if (s.substring(0, n - i).equals(r.substring(i))) {
break;
}
}
return new StringBuilder(s.substring(n - i)).reverse() + s;
}
-
分析
1.将原字符串反转,for循环找到前n-i个字符构成回文字符串
2.原字符串之前加上第n-i个字符之后的字符串反转,即可构成回文字符串 -
提交结果

215. 数组中的第K个最大元素
在未排序的数组中找到第 k 个最大的元素。请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。

- 解答
public int findKthLargest(int[] nums, int k) {
Arrays.sort(nums);
return nums[nums.length-k];
}
-
分析
排序后返回倒数第k个
-
提交结果

216. 组合总和 III
找出所有相加之和为 n 的 k 个数的组合。组合中只允许含有 1 - 9 的正整数,并且每种组合中不存在重复的数字。
说明:
所有数字都是正整数。
解集不能包含重复的组合。

- 解答
public List<List<Integer>> combinationSum3(int k, int n) {
List<List<Integer>> res = new ArrayList<>();
backtrack(res,new ArrayList<>(),n,k,1,0);
return res;
}
public void backtrack(List<List<Integer>> res,List<Integer> tmp,int n,int k,int begin,int sum){
if(tmp.size()>k)return;
if(sum == n && tmp.size()==k){
res.add(new ArrayList<>(tmp));
return;
}
for(int i = begin;i<10;i++){
tmp.add(i);
backtrack(res,tmp,n,k,i+1,sum+i);
tmp.remove(tmp.size()-1);
}
}
-
分析
1.回溯实现,每次遍历的起点begin是上一层递归的后一位避免重复数字。
2.递归出口两个,
一个是tmp中的数字个数大于k退出。
另一个是sum等于n的时候并且tmp中数字的个数等于k的时候,将tmp添加到res中 -
提交结果

217. 存在重复元素
给定一个整数数组,判断是否存在重复元素。
如果任意一值在数组中出现至少两次,函数返回 true 。如果数组中每个元素都不相同,则返回 false 。

- 解答
public boolean containsDuplicate(int[] nums) {
Set<Integer> set = new HashSet<>();
for(int i=0;i<nums.length;i++){
if(set.contains(nums[i]))
return true;
set.add(nums[i]);
}
return false;
}
-
分析
1.利用set唯一的性质
2.遍历数组,判断当前数字是否在set中出现。是的话返回true,否则返回false。 -
提交结果

218. 天际线问题
城市的天际线是从远处观看该城市中所有建筑物形成的轮廓的外部轮廓。现在,假设您获得了城市风光照片(图A)上显示的所有建筑物的位置和高度,请编写一个程序以输出由这些建筑物形成的天际线(图B)。

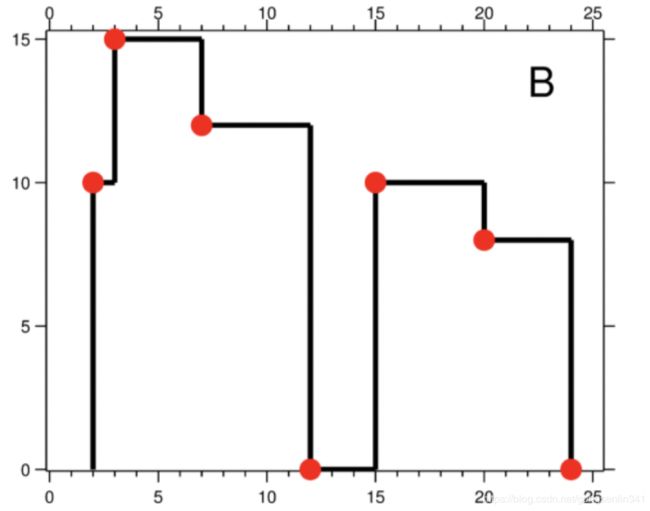
每个建筑物的几何信息用三元组 [Li,Ri,Hi] 表示,其中 Li 和 Ri 分别是第 i 座建筑物左右边缘的 x 坐标,Hi 是其高度。可以保证 0 ≤ Li, Ri ≤ INT_MAX, 0 < Hi ≤ INT_MAX 和 Ri - Li > 0。您可以假设所有建筑物都是在绝对平坦且高度为 0 的表面上的完美矩形。
例如,图A中所有建筑物的尺寸记录为:[ [2 9 10], [3 7 15], [5 12 12], [15 20 10], [19 24 8] ] 。
输出是以 [ [x1,y1], [x2, y2], [x3, y3], … ] 格式的“关键点”(图B中的红点)的列表,它们唯一地定义了天际线。关键点是水平线段的左端点。请注意,最右侧建筑物的最后一个关键点仅用于标记天际线的终点,并始终为零高度。此外,任何两个相邻建筑物之间的地面都应被视为天际线轮廓的一部分。
例如,图B中的天际线应该表示为:[ [2 10], [3 15], [7 12], [12 0], [15 10], [20 8], [24, 0] ]。
说明:
任何输入列表中的建筑物数量保证在 [0, 10000] 范围内。
输入列表已经按左 x 坐标 Li 进行升序排列。
输出列表必须按 x 位排序。
输出天际线中不得有连续的相同高度的水平线。例如 […[2 3], [4 5], [7 5], [11 5], [12 7]…] 是不正确的答案;三条高度为 5 的线应该在最终输出中合并为一个:[…[2 3], [4 5], [12 7], …]
- 解答
public List<List<Integer>> getSkyline(int[][] buildings) {
List<List<Integer>> res = new ArrayList<>();
PriorityQueue<int[]> pq = new PriorityQueue<>((a,b) -> a[0]!=b[0] ? a[0]-b[0]:a[1]-b[1]);
for(int[] building:buildings){
pq.offer(new int[]{building[0],-building[2]});
pq.offer(new int[]{building[1],building[2]});
}
TreeMap<Integer,Integer> heights = new TreeMap<>((a,b)-> b-a );
heights.put(0,1);
int height = 0;
int left = 0;
while(!pq.isEmpty()){
int[] arr = pq.poll();
if(arr[1] < 0){
heights.put(-arr[1],heights.getOrDefault(-arr[1],0)+1);
}else{
heights.put(arr[1],heights.get(arr[1])-1);
if(heights.get(arr[1])==0)heights.remove(arr[1]);
}
int maxHeight = heights.keySet().iterator().next();
if(maxHeight != height){
left = arr[0];
height = maxHeight;
res.add(Arrays.asList(left,height));
}
}
return res;
}
-
分析
1.将矩阵的左右端点加入到优先级队列中,优先级队列根据给定的比较器,每次从队头取出的都是最小的元素。
2.左端点,用高度为负表示
3.创建一个treeMap用于记录已遍历的端点高度。
4.while循环,当优先级队列不为空,则取出队头元素。
若是左端点,则将key为高度,value为原来这个key对应的value+1,
若是右端点,则将key为高度,value为原来这个key对应的value-1。并且当value为0,则将其从树中删除,表示该高度的左右端点已经遍历过。
之后判断此时树中的最大高度maxHeight
若最大高度和当前记录的最大高度不一致,则记录left=arr[0],height=maxHeight,将left,maxHeight加入到res中。 -
提交结果
