2019LeetCode第10场双周赛&&第157场周赛
2019LeetCode第10场双周赛
5079. 三个有序数组的交集
题目描述
给出三个均为 严格递增排列 的整数数组 arr1,arr2 和 arr3。
返回一个由 仅 在这三个数组中 同时出现 的整数所构成的有序数组。
示例:
输入: arr1 = [1,2,3,4,5], arr2 = [1,2,5,7,9], arr3 = [1,3,4,5,8]
输出: [1,5]
解释: 只有 1 和 5 同时在这三个数组中出现.
提示:
1 <= arr1.length, arr2.length, arr3.length <= 1000
1 <= arr1[i], arr2[i], arr3[i] <= 2000
题解1
寻找三个有序数组的交集,如果arr1的某元素能同时在arr2和arr3中找到,则该元素属于交集。因为arr1,arr2,arr3三个数组都是有序的,在arr2和arr3中找arr1中的元素可用二分查找。c++中STL有binary_search。
代码1
class Solution {
public:
vector<int> arraysIntersection(vector<int>& arr1, vector<int>& arr2, vector<int>& arr3) {
vector<int>res;
for(int i = 0; i < arr1.size(); ++i){
if(binary_search(arr2.begin(), arr2.end(), arr1[i]) && binary_search(arr3.begin(), arr3.end(), arr1[i])){//二分查找
res.push_back(arr1[i]);
}
}
return res;
}
};
题解2
因为题中规定数组中的元素在区间[1, 2000]中且每个元素最多只出现一次(由严格递增排列得出),则可以用标记法。将三个数组扫描一遍,统计元素出现的次数,出现次数为3,则表示同时出现在三个数组中
代码2
class Solution {
public:
vector<int> arraysIntersection(vector<int>& arr1, vector<int>& arr2, vector<int>& arr3) {
vector<int>res;
vector<int>mark(2000 + 5, 0);
//统计元素在三个数组中出现的次数
for(int i = 0; i < arr1.size(); ++i){
++mark[arr1[i]];
}
for(int i = 0; i < arr2.size(); ++i){
++mark[arr2[i]];
}
for(int i = 0; i < arr3.size(); ++i){
++mark[arr3[i]];
}
for(int i = 1; i <= 2000; ++i){
if(mark[i] == 3){//出现三次,表示在三个数组中同时存在
res.push_back(i);
}
}
return res;
}
};
5080. 查找两棵二叉搜索树之和
题目描述
给出两棵二叉搜索树,请你从两棵树中各找出一个节点,使得这两个节点的值之和等于目标值 Target。
如果可以找到返回 True,否则返回 False。
示例 1:
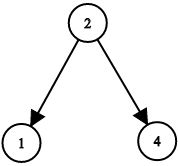
输入:root1 = [2,1,4], root2 = [1,0,3], target = 5
输出:true
解释:2 加 3 和为 5 。
示例 2:
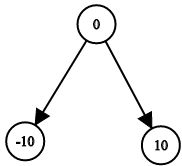
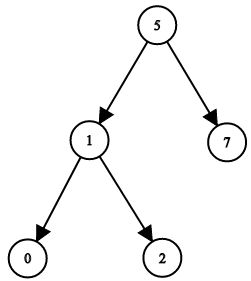
题解1
遍历左边的二叉搜索树,判断能否在右边二叉树中找到节点使val1 + val2 = target。其中在二叉搜索树寻找某元素时,可结合二叉搜索树的特点进行二分查找。
代码1
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
bool mySearch(TreeNode* root, int target){//在二叉搜索树中查找某元素
if(root == NULL){
return false;
}
else{
if(root->val == target){
return true;
}
else if(root->val > target){
return mySearch(root->left, target);
}
else{
return mySearch(root->right, target);
}
}
}
bool twoSumBSTs(TreeNode* root1, TreeNode* root2, int target) {
if(root1 == NULL){
return false;
}
//找到返回true,否则继续在左子树和右子树中寻找
if(mySearch(root2, target - root1->val)){
return true;
}
else{
return twoSumBSTs(root1->left, root2, target) || twoSumBSTs(root1->right, root2, target);
}
}
};
5081. 步进数
题目描述
如果一个整数上的每一位数字与其相邻位上的数字的绝对差都是 1,那么这个数就是一个「步进数」。
例如,321 是一个步进数,而 421 不是。
给你两个整数,low 和 high,请你找出在 [low, high] 范围内的所有步进数,并返回 排序后 的结果。
示例:
输入:low = 0, high = 21
输出:[0,1,2,3,4,5,6,7,8,9,10,12,21]
题解1
首先明确一点,如公式(1):
n u m = a 1 a 2 … … a n a n + 1 = a 1 ∗ 1 0 n + a 2 ∗ 1 0 n − 1 + … … + a n ∗ 10 + a n + 1 (1) num = a_1a_2……a_na_{n + 1} = a_1 * 10^n + a_2 * 10^{n - 1} + …… + a_n * 10 + a_{n + 1}\tag{1} num=a1a2……anan+1=a1∗10n+a2∗10n−1+……+an∗10+an+1(1)
若num是步进数,则 a 1 , a 1 a 2 , a 1 a 2 a 3 , … … , a 1 a 2 … … a n a_1, a_1a_2,a_1a_2a_3,……,a_1a_2……a_n a1,a1a2,a1a2a3,……,a1a2……an都是步进数。即用步进数可以生成新的步进数,有点类似欧拉筛选。
借用上面的例子,num是步进数,则如公式(2)
n e x t 步 进 数 = { n u m ∗ 10 + 1 ( i f a n + 1 = 0 ) n u m ∗ 10 + 8 ( i f a n + 1 = 9 ) n u m ∗ 10 + a n + 1 + 1 和 n u m ∗ 10 + a n + 1 − 1 ( o t h e r ) (2) next步进数 = \begin{cases} num * 10 + 1&(if&a_{n + 1} = 0)\\ num * 10 + 8&(if&a_{n + 1} = 9)\tag{2}\\ num * 10 + a_{n + 1} + 1 &和&num*10 + a_{n + 1} - 1&(other) \end{cases} next步进数=⎩⎪⎨⎪⎧num∗10+1num∗10+8num∗10+an+1+1(if(if和an+1=0)an+1=9)num∗10+an+1−1(other)(2)
代码1
class Solution {
public:
map<int, bool>my_map;
vector<int> countSteppingNumbers(int low, int high) {
vector<int>res;
int i = 0;
while(i <= high){
if(i >= 0 && i <= 10){//1-10都是步进数
my_map[i] = true;
++i;
if(i == 11){
++i;
}
}
else if(i == 12){//12也是步进数
my_map[i] = true;
++i;
}
else{
for(auto iter = my_map.begin(); iter != my_map.end(); ++iter){//用已有的步进数去找到下一个步进数
int tmp = iter->first;
int bitNum = tmp % 10;
i = tmp * 10;
if(bitNum == 0){
my_map[i + 1] = true;
i = i + 1;
}
else if(bitNum == 9){
my_map[i + 8] = true;
i = i + 8;
}
else{
my_map[i + bitNum - 1] = true;
my_map[i + bitNum + 1] = true;
i = i + bitNum + 1;
}
if(i > high){//当i超过high,跳出循环
break;
}
}
}
}
auto iter1 = my_map.lower_bound(low);//找到for循环的起点
auto iter2 = my_map.upper_bound(high);//找到for循环的终点的下一个
//!!直接从0开始循环,会超时!!
for(auto iter = iter1; iter != iter2; ++iter){
res.push_back(iter->first);
}
return res;
}
};
2019LeetCode第157场周赛
5213. 玩筹码
题目描述
数轴上放置了一些筹码,每个筹码的位置存在数组 chips 当中。
你可以对 任何筹码 执行下面两种操作之一(不限操作次数,0 次也可以):
将第 i 个筹码向左或者右移动 2 个单位,代价为 0。
将第 i 个筹码向左或者右移动 1 个单位,代价为 1。
最开始的时候,同一位置上也可能放着两个或者更多的筹码。
返回将所有筹码移动到同一位置(任意位置)上所需要的最小代价。
示例 1:
输入:chips = [1,2,3]
输出:1
解释:第二个筹码移动到位置三的代价是 1,第一个筹码移动到位置三的代价是 0,总代价为 1。
示例 2:
输入:chips = [2,2,2,3,3]
输出:2
解释:第四和第五个筹码移动到位置二的代价都是 1,所以最小总代价为 2。
提示:
1 <= chips.length <= 100
1 <= chips[i] <= 10^9
题解1
理解题意后很简单的。
对于筹码有2种操作:向左或向右移2个单位长度,代价为0。这句话意味着,同处奇位置的筹码都可以0代价移到同一位置,同处偶位置的筹码也可以0代价移到同一位置。并且你可以0代价使奇位置的筹码与偶位置的筹码相邻。
最后你只1堆或2堆筹码,1堆的话,就不用移了,答案是0;2堆的话,只需要将少的那堆移到多的那堆即可。所需代价等于少的那堆筹码的个数。
代码1
class Solution {
public:
int minCostToMoveChips(vector<int>& chips) {
int cnt1= 0, cnt2 = 0;//cnt1统计奇位置筹码个数,cnt2统计偶位置筹码个数
for(int i = 0; i < chips.size(); ++i){
if(chips[i] & 1){
++cnt1;
}
else{
++cnt2;
}
}
return min(cnt1, cnt2);//返回较少的
}
};
5214. 最长定差子序列
题目描述
给你一个整数数组 arr 和一个整数 difference,请你找出 arr 中所有相邻元素之间的差等于给定 difference 的等差子序列,并返回其中最长的等差子序列的长度。
示例 1:
输入:arr = [1,2,3,4], difference = 1
输出:4
解释:最长的等差子序列是 [1,2,3,4]。
示例 2:
输入:arr = [1,3,5,7], difference = 1
输出:1
解释:最长的等差子序列是任意单个元素。
示例 3:
输入:arr = [1,5,7,8,5,3,4,2,1], difference = -2
输出:4
解释:最长的等差子序列是 [7,5,3,1]。
提示:
1 <= arr.length <= 10^5
-10^4 <= arr[i], difference <= 10^4
题解1
第一次尝试,暴力求解,时间复杂度 o ( n 2 ) o(n^2) o(n2),超时。
采用动态规划,map[num]表示以num结尾的等差子序列的最大长度,则对于以arr[i]结尾的结尾的等差序列的最大长度为
m a p [ a r r [ i ] ] = m a x ( m a p [ a r r [ i ] ] , m a p [ a r r [ i ] − d i f f e r e n c e ] + 1 ) map[arr[i]] = max(map[arr[i]], map[arr[i] - difference] + 1) map[arr[i]]=max(map[arr[i]],map[arr[i]−difference]+1)
具体见公式(3)
m a p [ a r r [ i ] ] = { 1 i f ( i = 0 ) m a x ( m a p [ a r r [ i ] ] , m a p [ a r r [ i ] − d i f f e r e n c e ] + 1 ) i f ( i ≠ 0 ) (3) map[arr[i]] = \begin{cases} 1&if(i =0)\\ max(map[arr[i]], map[arr[i] - difference] + 1)&if(i\ne0)\tag{3} \end{cases} map[arr[i]]={1max(map[arr[i]],map[arr[i]−difference]+1)if(i=0)if(i=0)(3)
代码1
class Solution {
public:
map<int, int>my_map;
int longestSubsequence(vector<int>& arr, int difference) {
int len = arr.size(), num;
int res = 1;
if(len == 0){
return 0;
}
else{//以第1个元素结尾的等差子序列长度为1
my_map[arr[0]] = 1;
}
for(int i = 1; i < len; ++i){
int num = arr[i] - difference;
if(my_map.find(num) != my_map.end()){
int tmp = my_map[num] + 1;
if((my_map.find(arr[i]) != my_map.end() && my_map[arr[i]] < tmp) || my_map.find(arr[i]) == my_map.end()){
my_map[arr[i]] = tmp;
if(tmp > res){//更新子序列的最长长度
res = tmp;
}
}
}
else{
if(my_map.find(arr[i]) == my_map.end()){
my_map[arr[i]] = 1;
}
}
}
return res;
}
};
5215. 黄金矿工
题目描述
你要开发一座金矿,地质勘测学家已经探明了这座金矿中的资源分布,并用大小为 m * n 的网格 grid 进行了标注。每个单元格中的整数就表示这一单元格中的黄金数量;如果该单元格是空的,那么就是 0。
为了使收益最大化,矿工需要按以下规则来开采黄金:
每当矿工进入一个单元,就会收集该单元格中的所有黄金。
矿工每次可以从当前位置向上下左右四个方向走。
每个单元格只能被开采(进入)一次。
不得开采(进入)黄金数目为 0 的单元格。
矿工可以从网格中 任意一个 有黄金的单元格出发或者是停止。
示例 1:
输入:grid = [[0,6,0],[5,8,7],[0,9,0]]
输出:24
解释:
[[0,6,0],
[5,8,7],
[0,9,0]]
一种收集最多黄金的路线是:9 -> 8 -> 7。
示例 2:
输入:grid = [[1,0,7],[2,0,6],[3,4,5],[0,3,0],[9,0,20]]
输出:28
解释:
[[1,0,7],
[2,0,6],
[3,4,5],
[0,3,0],
[9,0,20]]
一种收集最多黄金的路线是:1 -> 2 -> 3 -> 4 -> 5 -> 6 -> 7。
提示:
1 <= grid.length, grid[i].length <= 15
0 <= grid[i][j] <= 100
最多 25 个单元格中有黄金。
题解1
dfs,暴力搜索,注意收集黄金的起点不一定从(0, 0)
代码1
class Solution {
public:
bool mark[20][20];//标记是否开采过
int res, len, len1;
int dir[4][2] = {{-1, 0}, {0, 1}, {1, 0}, {0, -1}};//定义开采的四个方向
void dfs(vector<vector<int>>& grid, int x, int y, int cnt){//dfs
cnt = cnt + grid[x][y];
if(cnt > res){
res = cnt;
}
mark[x][y] = true;
for(int i = 0; i < 4; ++i){//四个方向开采
int next_x = x + dir[i][0];
int next_y = y + dir[i][1];
if(next_x >= 0 && next_x < len && next_y >= 0 && next_y < len1 && !mark[next_x][next_y] && grid[next_x][next_y]){//网格内,未开采且有黄金
dfs(grid, next_x, next_y, cnt);
}
}
mark[x][y] = false;//恢复环境(尝试所有路径)
}
int getMaximumGold(vector<vector<int>>& grid) {
res = 0;
len = grid.size(), len1 = grid[0].size();
for(int i = 0; i < len; ++i){
for(int j = 0; j < len1; ++j){//尝试路线的不同起点
if(grid[i][j]){//
memset(mark, false, sizeof(mark));
dfs(grid, i, j, 0);
}
}
}
return res;
}
};
5216. 统计元音字母序列的数目
题目描述
给你一个整数 n,请你帮忙统计一下我们可以按下述规则形成多少个长度为 n 的字符串:
字符串中的每个字符都应当是小写元音字母(‘a’, ‘e’, ‘i’, ‘o’, ‘u’)
每个元音 ‘a’ 后面都只能跟着 ‘e’
每个元音 ‘e’ 后面只能跟着 ‘a’ 或者是 ‘i’
每个元音 ‘i’ 后面 不能 再跟着另一个 ‘i’
每个元音 ‘o’ 后面只能跟着 ‘i’ 或者是 ‘u’
每个元音 ‘u’ 后面只能跟着 ‘a’
由于答案可能会很大,所以请你返回 模 10^9 + 7 之后的结果。
示例 1:
输入:n = 1
输出:5
解释:所有可能的字符串分别是:“a”, “e”, “i” , “o” 和 “u”。
示例 2:
输入:n = 2
输出:10
解释:所有可能的字符串分别是:“ae”, “ea”, “ei”, “ia”, “ie”, “io”, “iu”, “oi”, “ou” 和 “ua”。
示例 3:
输入:n = 5
输出:68
提示:
1 <= n <= 2 * 10^4
题解1
假设n = i时以"a"结尾的字符串个数为 x i x_i xi个,"e"结尾的字符串个数为 y i y_i yi个,"i"结尾的字符串个数为 z i z_i zi个,"o"结尾的字符串个数为 m i m_i mi个,"u"结尾的字符串个数为 n i n_i ni个。
则由题得,n = i + 1时,以"a"结尾的字符串个数为 y i + z i + n i y_i+z_i+n_i yi+zi+ni个,"e"结尾的字符串个数为 x i + z i x_i+z_i xi+zi个,"i"结尾的字符串个数为 y i + m i y_i+m_i yi+mi个,"o"结尾的字符串个数为 z i z_i zi个,"u"结尾的字符串个数为 z i + m i z_i + m_i zi+mi个。
具体如公式(4)。
{ x 1 = y 1 = z 1 = m 1 = n 1 = 1 i f ( i = 1 ) x i + 1 = y i + z i + n i , y i + 1 = x i + z i , z i + 1 = y i + m i , m i + 1 = z i , n i + 1 = z i + m i i f ( i + 1 ≠ 1 ) (4) \begin{cases} x_1 = y_1 = z_1 = m_1 = n_1 = 1&if(i = 1)\\ x_{i + 1}= y_i+z_i+n_i,y_{i + 1} = x_i+z_i,z_{i+1}=y_i+m_i,\\m_{i + 1}=z_i,n{i+1}=z_i + m_i&if(i+1\ne1)\tag{4} \end{cases} ⎩⎪⎨⎪⎧x1=y1=z1=m1=n1=1xi+1=yi+zi+ni,yi+1=xi+zi,zi+1=yi+mi,mi+1=zi,ni+1=zi+miif(i=1)if(i+1=1)(4)
代码1
/*
类似斐波拉契数列
- 其中注意计算过程中对每一个数(x, y, z, m, n)都要取模,不然会溢出。
- 数据类型用long long int,int在加法的过程会溢出。
*/
#define MOD 1000000007
class Solution {
public:
int countVowelPermutation(int n) {
vector<long long>v1(5, 1), v2(5, 1);
long long sum = 0;
if(n == 1){
return 5;
}
else{
for(int i = 2; i <= n; ++i){
v2[0] = (v1[1] + v1[2] + v1[4]) % MOD;
v2[1] = (v1[0] + v1[2]) % MOD;
v2[2] = (v1[1] + v1[3]) % MOD;
v2[3] = v1[2] % MOD;
v2[4] = (v1[2] + v1[3]) % MOD;
v1.assign(v2.begin(), v2.end());
}
for(auto num:v1){
sum = (sum + num) % MOD;
}
return sum;
}
}
};
欢迎加入LeetCode周赛交流群
