part3 正文:
上文说到,tf model server 搭建完成,这时距离真正的应用可以说完事具备只差东风,本节主要讲述概要的第四部分,推荐系统sever对dnn model server的client。本文主要从TFrecords,数据结构,python对dnn model server的client,以及推荐系统server对model server的client,三个方面来进行阐述。
(1)准备知识点之TFrecords。
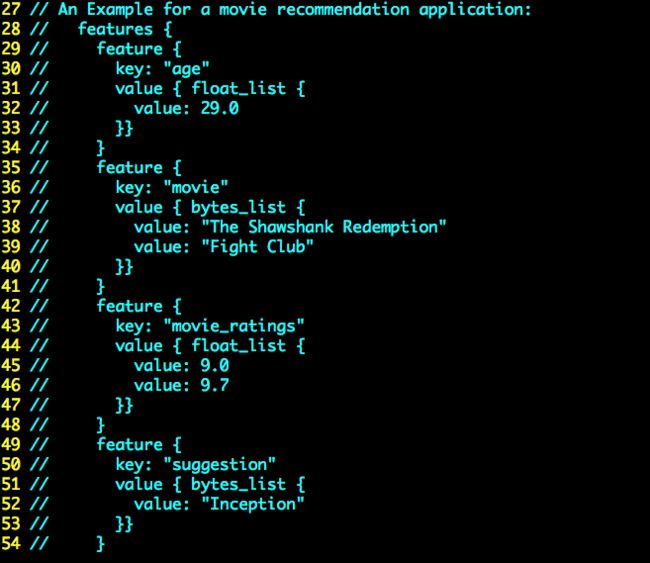
TensorFlow 提供了一种统一的格式来存储数据,这就是TFrecord。这样的好处就是避免了我们自己在trainmodel 和应用model时候使用自己定义的数据结构来通信,可维护性非常差。TFrecord文件中的数据都是通过tf.train.Example PB格式存储的,具体可以参见git clone --recurse-submodules https://github.com/tensorflow/serving后serving/tensorflow/core/example/example.proto,serving/tensorflow/core/example/feature.proto 这两个proto文件里面有Example数据结构的定义,以及具体的case。将两个文件里的定义merge一下,如下图1所示。也就是说构造一个Example 实例只需要构造一个Features,而构造Features只需要构造一个key是string,value 是Feature的map。而Feature就相对简单。就是BytesList,FloatList,Int64List其中之一,分别对应string类型的特征,float类型的特征,以及int型特征。同样BytesList,FloatList,Int64List的定义也在serving/tensorflow/core/example/feature.proto中。每一个Example就是一个训练的实例。大家要对这个概念清晰。说到这里可能大家依然不能知道,我用python怎么构造一个Example,或者我用java如何构造一个Example。下面会在讲述client时候直接上代码。图2附proto文件中Example的一个具体例子,看完之后相信就可以基本明白如何构造。featureMap里面value就是训练model时候每一维特征值。key就是这个特征对应的名字,可以随便取,只要能和train的时候对应好就可以。

(2)python 对Dnn model server的client。
在搭建tf model server的过程中,需要及时测一下,所搭的server是否是ok可用的,那么就需要client。为什么首先要讲python对model server的client,因为在搭建tf serving的时候,官网给出的tutorial 中,有一个简易的minist数字识别的server与client的 testcase。请参考https://www.tensorflow.org/serving/serving_basic。以及下图3.

在我将model export出,启动了服务后,通过/serving/tensorflow_serving/apis/prediction_service.proto, /serving/tensorflow_serving/apis/predict.proto查看到通信的Request需要构造,第一部分ModelSpec定义在/serving/tensorflow_serving/apis/predict.proto,不再粘贴有三个成员变量 1是modelname,和export时候对应就可以2.是model version可以不指定,默认最新的model version加载。3是signature_name这个和export时候一样就可以。第二部分key string,通过注释可以看到默认情况下都是“inputs”,value是TensorProto。TensorProto的定义在/serving/tensorflow/core/framework/tensor.proto中,这里也不再贴图而是简述一下.TensorProto有很多成员变量,但是有一些是不需要的下面只说一些必须的。1.DataType,需要说明这个Tensor的数据类型,这里用的string,是将上文介绍的Example序列化成的string。2.tensor_shape,因为tensor其实可以理解成一个list,所以这里就是list size,用算法的术语说就是有多少个训练实例。3.从定义的repeated的各种类型中,选取合理的一种类型,这里选repeated bytes string_val=8. 上述信息填充完整TensorProto就填充完整了。第三部分output_filter 通过看注释,说的是当不定义时候所有的input tensor 会被返回,这是符合我们的要求的。所以这里不用指定。

解读完这个之后我们就可以写代码了。这里特别感谢大神https://github.com/MtDersvan/tf_playground/blob/master/wide_and_deep_tutorial/wide_and_deep_basic_serving.md,在这里简单写的model export的方法以及server client如果构造输入的request,还包括如何写到build文件里,供bazel的编译。在从github上看到这个的时候突然想到了姚明06年fiba世锦赛评价王治郅的话,“彷佛在沙漠里待了10天后的第一口水”。上面提到的git链接里只给出了预测一个实例的代码,下面截图给出多个实例预测的一个demo。feature_dict 也就是根据自己训练模型的时候使用的特征构造的feature。构造完就可以编译bazel build //tensorflow_serving/example:wide_and_deep_client,然后运行bazel-bin/tensorflow_serving/example/wide_and_deep_client --model=wide_and_deep --server=ip:port. 如果能返回正常的结果证明测试过程已经全部走通。另外关于grpc的python client与java client的通信细节与使用等这里不做阐述,默认都会。如需参考,请参考:https://grpc.io/。

(3)推荐server对tf model server的client。
由于我们的推荐引擎server是用java书写的,所以需要将/serving/目录下的所有proto文件全部生成java的api文件也就是从*.proto=>*.java, 然后将这些java导入我们的java 工程。当然还需要利用protoc-gen-grpc-java把 /server/tensorflow_serving/apis/prediction_service.proto 生成一个java的通信文件。来完成grpc的通信。具体步骤请参考下面。
1.由于tf server 是采用的grpc通信,所以需要编译protobuffer文件产出我们需要的client api,完成client代码的编写与通信。
2.因为在操作protoc 生成java过程中需要把 serving 目录下的文件夹文件夹移动,所以为了不破坏成产环境,可以cp 一份serving_bak,专门生成client端api,而且如果你是之前安装了tensorflow的话,可能这里你不运行/server/tensorflow/configure 等安装步骤,这个时候发现 有两层tensorflow目录 /server/tensorflow/tensorflow 直接拷贝出一层就可以,木啥大问题。
3.cp -r serving serving_bak
4.由于java 很多工程都是在特定的package下,比如我们的在compay_name.recommend 下,所以在运行protoc生成api之前,我们需要改变一下.proto 文件的java package. 所有的proto文件在"tensorflow_serving/apis/", "tensorflow/core/example/", "tensorflow/core/framework/", "tensorflow/core/protobuf/","tensorflow/core/lib/core/", 其中tensorflow_serving/apis/下的所有proto没有 option java_package = ""这一行。所以我们直接添加 option java_package = "compay_name.recommend.tensorflow.serving"。其余文件夹下的proto原来就有option java_package = ""这一行,所有在原来的基础上添加上这里的前缀compay_name.recommend就可以了。自己写个脚本就可以,我的脚本就不公布到这里了。这个过程不是壁垒。
5.运行一下由proto 生成java的脚本,见图5.最后将这些文件放倒java项目的目录结构见图6
6.运行生成通信文件protoc --plugin=protoc-gen-grpc-java=插件路径 --grpc-java_out=hh --proto_path=. tensorflow_serving/apis/prediction_service.proto

番外介绍一下protoc和protoc-gen-grpc-java的安装,凌晨4点的北京也不是白见的。安装protobuf,按照这个网址https://github.com/google/protobuf/tree/master/src,首先clone下来源码问题然后一步步操作问题不大。安装的版本是3.3.0
然后是安装protoc-gen-grpc-java 首先clonehttps://github.com/grpc/grpc-java.git,其次cd compiler, 然后../gradlew java_pluginExecutable 然后../gradlew test很容易就成功了。但是我在编译过程中出现了一个问题/usr/bin/ld: cannot find -lstdc++,然后搜百度,google,可能是软链坏了,然后重新ln -s,重新装gcc,g++,写Helloworld.cpp,换机器重新搞环境都不行,不知不觉搞了两个多小时,一看表。4点了。郁闷的睡了,第二天起来之后好好读了Build文件build.gradle,发现了是依赖的静态libstdc++。这才抱着试试看的态度,yum installlibstdc++48-static.x86_64,装了一下这个static,发现ok了。

上述所有工作搞完之后就进入了代码的书写阶段,需要在maven项目中引入下图的一些依赖。这些从grpc的官网上都能看到。当然还有一个tensorflow的一些基础包。

从生成的java api可以看出,每一种数据结构,都是有一个builder。想生成这种数据结构需要先生成这个数据结构的builder。然后build一下就生成了相应的数据结构。话不多说。直接上代码。下图中是构建request的过程。tensorProto是由许多个实例序列化成string够成的。在图10中,我们看到docid,userid 和三个打了马赛克的特征是string类型的。也就是需要embeding的特征。不同的任务特征需要仔细筛选这里就不误导大家了所以打了马赛克。


参考:
引用1。https://github.com/MtDersvan/tf_playground/blob/master/wide_and_deep_tutorial/wide_and_deep_basic_serving.md
完成于20170830,如转载请注明出处。