iOS内存扫描工具实现
由于不能告诉你的原因,我需要一个iOS下的,可以在指定App的内存中搜索字符串的工具。
找了一圈,发现一个比较接近的开源项目:rxmemscan,但是不支持搜索字符串,遂 修改 学习了一番。
又,修改后的源码在这里:https://github.com/liumazi/rxmemscan
环境搭建
运行环境
由于非越狱的iOS设备有诸多权限限制,首先需要对设备进行越狱,我使用的是CheckRa1n,越狱完成后,手机桌面会出现checkra1n图标,点开后可以进一步安装Cydia(越狱商店)。
开发环境
Theos是一个越狱开发工具包,在Mac上的安装方法请自行搜索。:)
然后,rxmemscan还使用了readline库,下载,拷贝到$THEOS/vendor目录,即可。
至此,进入rxmemscan目录,执行 $ make,应该就可以编译成功啦!
如果希望编译完直接安装到设备上,可以修改Makefile中的THEOS_DEVICE_IP为设备的局域网IP,再执行 $ make do FINALPACKAGE=1。
实现原理
Darwin
Darwin是macOS和iOS系统的类UNIX核心,架构图如下。而Darwin的核心是XNU,主要包括:Mach微内核、BSD层、libKern、I/O Kit。这里我们主要使用Mach/BSD层提供的底层API。
 图片来源 《Mac OS X and iOS Internals》
图片来源 《Mac OS X and iOS Internals》
任务端口
要使用Mach API操作另一个任务(进程),首先要调用task_for_pid,将BSD层的进程ID转换得到一个Mach的“任务端口”。(类似于Windows下OpenProcess获取进程句柄)
boolean_t rx_mem_scan::attach(pid_t pid) {
_target_pid = pid;
kern_return_t ret = task_for_pid(mach_task_self(), pid, &_target_task);
if (ret != KERN_SUCCESS) {
_trace("Attach to: %d Failed: %d %s\n", pid, ret, mach_error_string(ret));
return false;
}
reset();
return true;
}
虚拟内存
和其他操作系统类似,每一个Mach任务(进程)都有独立的虚拟内存空间,空间内又分为多个虚拟内存"区域"(VM Region),而每一个"区域"又分为若干"页",一个"页"的大小通常为4K或16K。"页"用于分页机制,以实现虚拟内存到物理内存的映射(地址转换)。分页机制是由处理器(按页表转换)和操作系统(维护页表)共同支持的。
使用XCode附带的Debug Memory Graph、VM Tracker,以及配合vmmap命令,可以不同程度地观察App的虚拟内存使用情况。
下面为VM Tracker截图(打开方式:Product -> Profile -> Allocations -> +VM Tracker)

高亮选中行对应 malloc(6 * 1024 * 1024);它占用一个1536页的MALLOC_LARGE区域(不同的MALLOC_XX区域用于满足不同尺寸的malloc()调用);图中几种Size的含义:
- Virtual — 虚拟内存占用,对于malloc()而言,就是它实际分配的虚拟内存大小
- Resident — 物理内存占用,已映射到物理内存或者说分配了物理内存的部分
- Dirty — 前者中不可丢弃的部分; 物理内存紧张时,Dirty页可能会被交换到外存或被压缩,非Dirty页可能会被丢弃
- Swapped — 被交换到外存或被压缩的部分;低版本设备默认不开启交换分区,但越狱后可手动设置
值得注意的是,调用malloc()之后,并没有立即为其分配物理内存,只有当访问其中内容而触发缺页中断时,操作系统才会进一步分配物理内存页,并建立映射关系(修改页表)。
另外,关于Dirty Size,和我想象中的有点不同,当使用循环读取所分配的数组,Resident Size会逐渐上升,这是理所当然的,但Dirty Size也会跟着上升,并且往往比Resident Size少一点,Why??可能需要仔细阅读XNU的源码才能找到答案。
VMMap
vmmap目前没有可直接运行于iOS下的版本,需要先在Debug Memory Graph中导出一个.memgraph文件(File -> Export Memory Graph...),再使用vmmap分析,如下图:
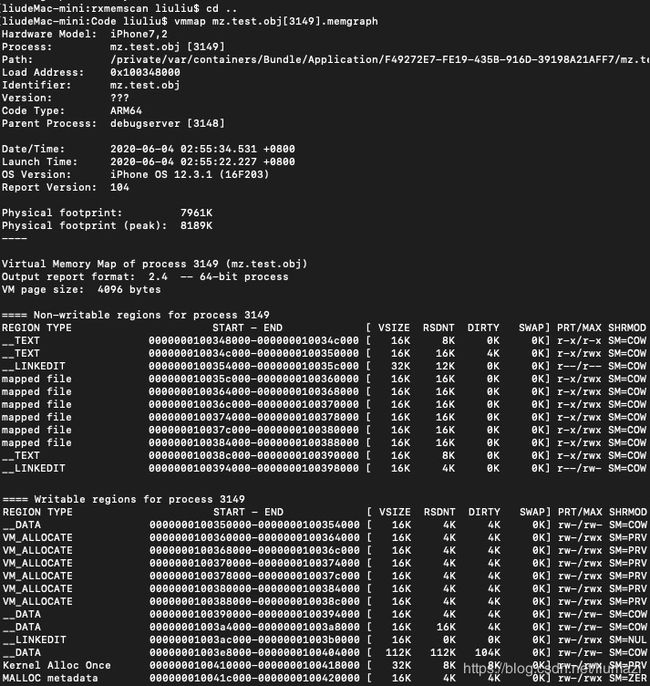
BTW,如果在XCode中使用模拟器(非真机)运行App,这个App其实是Mac上一个的进程哦,直接 $ vmmap pid 即可。
准备搜索
使用proc_pidinfo()函数(也可以用vm_region),找出目标进程虚拟内存空间中所有可写的区域,待用。
void rx_mem_scan::init_regions() {
struct proc_regioninfo region_info;
kern_return_t ret;
uint64_t addr = 0;
int count = 0;
_regions_p = new regions_t();
do {
if (addr) {
boolean_t writable = (region_info.pri_protection & VM_PROT_DEFAULT) == VM_PROT_DEFAULT;
if (writable) {
region_t region;
region.address = region_info.pri_address;
region.size = region_info.pri_size;
_regions_p->push_back(region);
count ++;
}
// printf("%016llx - %016llx, %d, %d\n", region_info.pri_address, region_info.pri_address + region_info.pri_size, writable, region_info.pri_user_tag);
}
ret = proc_pidinfo(_target_pid, PROC_PIDREGIONINFO, addr, ®ion_info, sizeof(region_info));
addr = region_info.pri_address + region_info.pri_size;
} while (ret == sizeof(region_info));
_trace("Writable region count: %d\n", (int)_regions_p->size());
}将所有区域信息打印出来,看起来和上面vmmap的输出是吻合的,其中pri_user_tag对应region type,定义见vm_statistics.h。
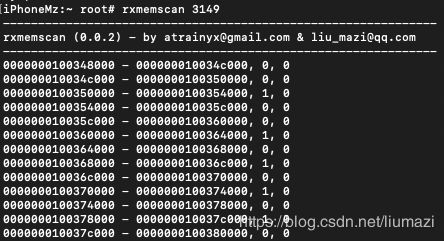
读取内存
使用vm_read_overwrite()函数,从目标进程"读取"内存。注意,这个函数与vm_read()不同,应该并没有做实际的数据拷贝,而是将region.address ~ region.address + region.size范围对应的所有映射状态同步给了region_data ~ region_data + region.size,对于Resident的部分,两个进程中不同的虚拟内存地址对应的应该是相同的物理内存地址。
inline kern_return_t rx_mem_scan::read_region(data_pt region_data, region_t ®ion, vm_size_t *read_count) {
kern_return_t ret = vm_read_overwrite(_target_task,
region.address,
region.size,
(vm_address_t) region_data,
read_count);
return ret;
}
搜索字符串
在目标进程虚拟内存空间中,依次读取所有可写的区域并且搜索。代码如下:
void rx_mem_scan::search_str(const std::string &str) {
int matched_count = 0;
long begin_time = get_timestamp();
for (uint32_t i = 0; i < _regions_p->size(); ++i) {
region_t region = (*_regions_p)[i];
vm_size_t raw_data_read_count;
data_pt region_data_p = new data_t[region.size];
kern_return_t ret = read_region(region_data_p, region, &raw_data_read_count);
if (ret == KERN_SUCCESS) {
//printf("Region address: %p, region size: %d, read count: %d\n", (void *)region.address, (int)region.size, (int)raw_data_read_count);
data_pt data_itor_p = region_data_p;
int str_len = str.length();
while (raw_data_read_count >= str_len) {
data_pt str_itor_p = (data_pt)str.c_str();
bool found = true;
int i = 0;
while (i < str_len)
{
if (data_itor_p[i] != str_itor_p[i])
{
found = false;
break;
}
++ i;
}
if (found)
{
++ matched_count;
while (i < 255 + str_len && i < raw_data_read_count)
{
if (0 == data_itor_p[i++]) // fast skip 0, for next compare
{
break;
}
}
int j = -1;
while (j > -256 && &data_itor_p[j] >= region_data_p && data_itor_p[j] >= 32) {
-- j;
}
char str_buff[256];
printf("\e[1;31mAddress: %p, string: \e[0m", data_itor_p);
memcpy(str_buff, &data_itor_p[j + 1], -j - 1);
str_buff[-j - 1] = 0;
printf("%s", str_buff);
printf("\e[0;32m%s\e[0m", str_itor_p);
memcpy(str_buff, &data_itor_p[str_len], i - str_len);
str_buff[i - str_len] = 0;
printf("%s\n", str_buff);
raw_data_read_count -= i;
data_itor_p += i;
} else {
raw_data_read_count -= 1;
data_itor_p += 1;
}
}
// free_region_memory(region);
} else {
printf("Region address: %p, region size: %d, read failed\n", (void *)region.address, (int)region.size);
}
delete[] region_data_p;
}
long end_time = get_timestamp();
printf("Result count: %d, time used: %.3f(s)\n", matched_count, (float)(end_time - begin_time)/1000.0f);
}
使用示例
$ ssh 远程登录到iPhone,$ ps 得到目标进程id,然后 $ rxmemscan pid,就可以愉快地搜索啦。。
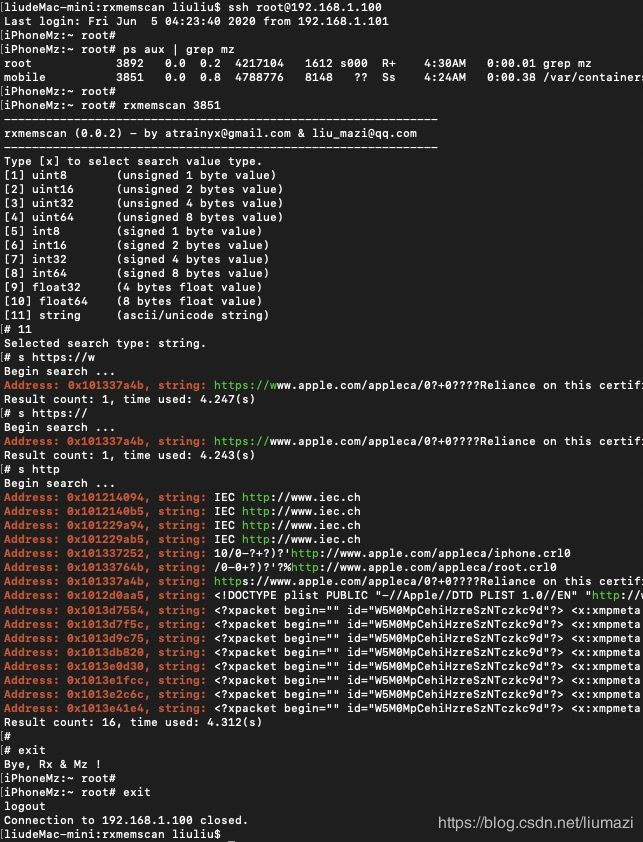
有待优化
由于目标进程中的虚拟内存区域应该也存在很多未实际映射(到物理内存或外存)的页,rx_mem_scan::search_str()中直接对整块区域进行搜索(访问),一方面可能会造成rxmemscan自身物理内存占用升高,一方面也白白耗费搜索时间。如果排除掉未映射的页,效率应该会有所提升吧。
参考资料
http://icetime.cc/2020/02/03/2020-02/关于iOS内存的深入排查和优化/
https://juejin.im/post/5a5e13c45188257327399e19
http://vlambda.com/wz_x6ylln0XQd.html
https://developer.apple.com/library/archive/documentation/Darwin/Conceptual/KernelProgramming/vm/vm.html
https://www.cnblogs.com/murongxiaopifu/archive/2020/02/24/12357406.html
https://github.com/apple/darwin-xnu
https://book.douban.com/subject/25870206/