fork()之后都会做哪些复制,什么是写时拷贝,父子进程文件偏移量是否一致?????
首先我们先来回忆一下fork()函数:
函数头文件:#include
函数原型:pid_t fork(void);其中pid_t是一个宏定义:#define pid_t int
返回值:
fork函数调用一次返回两次:
在父进程中返回生成子进程的id(因为父进程不止拥有一个子进程)
在子进程返回一个整数0(因为子进程只有一个父进程,可以通过调用getppid()得到父进程的进程ID)
当然,如果创建失败,则返回-1;
复制内容:
传统的fork函数之后会做这样的举动:
例:
现在有一个进程1,在它的虚拟地址空间有:.text .data .bss heap stack
相应,内核会为这几个部分分配各自的物理空间。
我们现在用fork给进程1创建子进程,名为进城2
--->现在子进程开始复制这几个部分,也就是虚拟地址空间:
--->为子进程的这几个部分分配物理块:
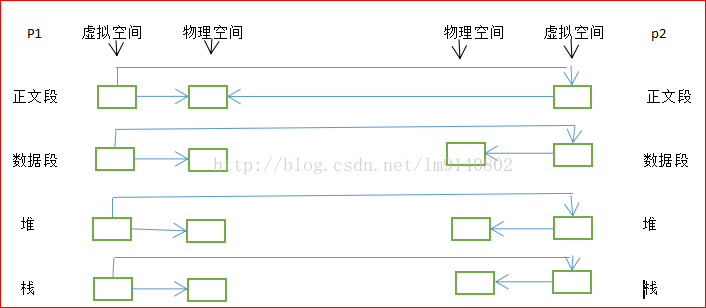
可以看出:fork()之后会进行数据段,堆区,栈区的复制(.text共享)当然还有打开的文件描述符。
大家可以看到:传统的fork系统调用直接把所有的资源复制给新创建的进程,这种实现过于简单
并且效率低下,因为它拷贝的数据也许并不共享,如果这时子进程执行exec函数系统调用,那么
拷贝也就没有什么意义了。
所以呢:::::接下来就有了一个新的技术叫写时拷贝:
fork()之后父进程的虚拟空间拷贝给子进程,在虚拟空间与物理页表建立映射的过程中使用了写时拷贝
使得子进程共享父进程的物理空间,当父子进程其中一个对该区域进行写入时,子进程复制一个新的
物理页表并建立映射,使得父子进程相互独立,同时节省了很多物理内存。子进程和父进程拥有相同
的相互独立的虚拟空间(不同的进程都拥有自己独立的虚拟地址空间),
但是却没有复制物理页表
写时拷贝:
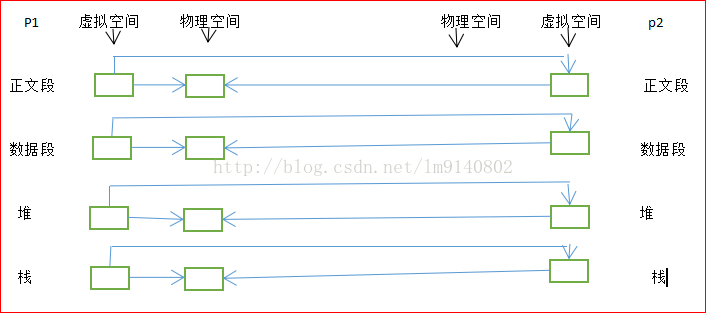
在网上看到这样几句话分享给大家:
fork()之后exec之前两个进程用的是相同的物理空间(当然我们上面已经说过了),子进程的代码段,数据段
堆栈都是指向父进程的物理空间(物理页面为只读模式),也就是说,两者的虚拟空间不同,但对应的物理
空间是一样的,如果不是exec,内核会为子进程的数据段,堆,栈分配物理空间,而代码段继续共享父进程
的物理空间,而如果是因为exec,由于两者的代码不同,子进程的代码段也会分配到独立的物理空间。
接下来我们再来看一下vfork函数,看看vfork函数和fork函数有什么区别呢??????
vfork函数的做法更加简单粗暴,内核连子进程的虚拟空间也不创建了,直接共享了父进程的虚拟空间,也就间接
的共享了物理空间,保证子进程先运行,在它调用exec或exit之后父进程才可能被调度。

接下来呢还有一个问题就是父进程打开的文件指针位置在子进程里面是否一样??????
父进程的打开文件指针存放在PCB中,PCB被复制到子进程中后,子进程对应相应的文件描述符也能对文件
进行操作,该描述符指向同一个文件表项,文件表项引用计数加1;
打开文件的内核数据结构
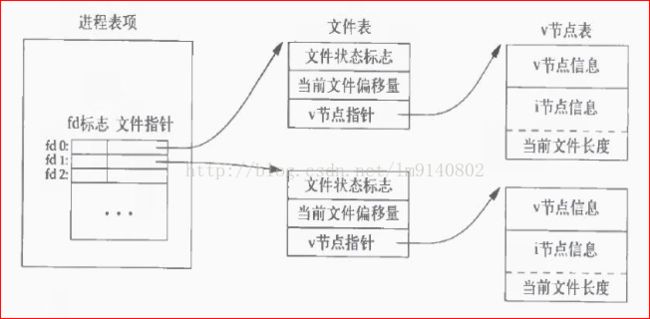
两个独立进程各自打开同一个文件
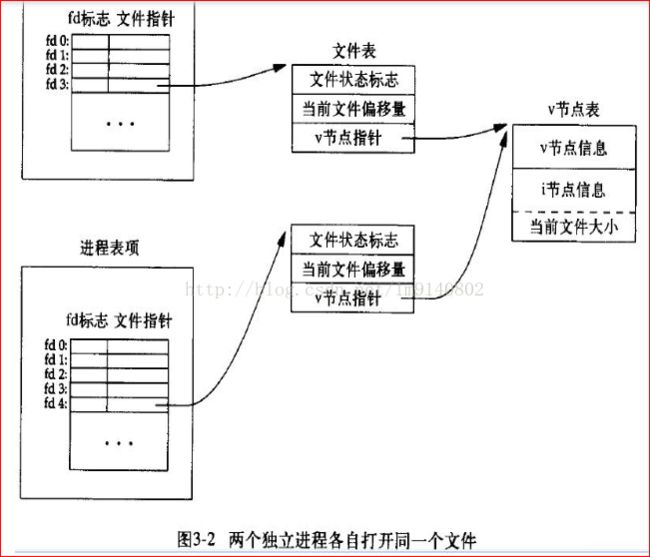
注:此图中可以看出,对于同一个文件,打开该文件的每个进程都得到一个文件表项,但对一个给定的文件只有一个v节点表项。
而每个进程都有自己的文件表项的一个理由是:使每个进程都有它自己的对该文件的当前偏移量。
注:文件描述符标志的作用域:只在一个进程中
文件状态标志的作用域:任何进程中的所有描述符都可指向同一个文件状态标志。
父子进程的每一个相同的打开文件描述符共享一个文件表项
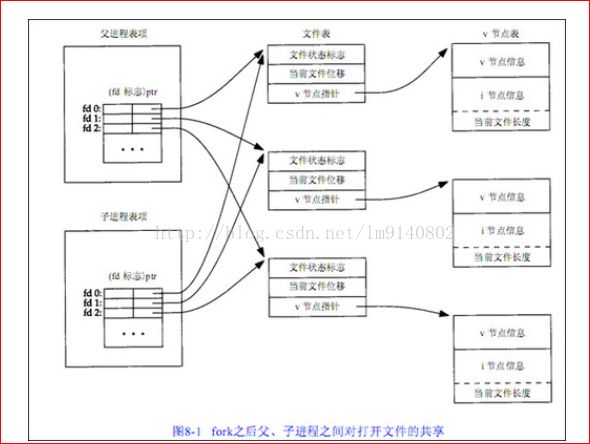
注:文件表项只有在所有引用它的fd(即文件描述符)全部关闭的情况下才会真正关闭,5如果子进程关闭父、子进程共享的文件描述符后父进程仍可以使用对应的文件表项。