JAVA实现UDP反向代理
用JAVA实现TCP协议的反向代理非常容易,只用不到100行代码就能搞定,每一个连接只需两个Socket,3条线程,进行输入流与输出流之间互相读写就可以了,可以承载所有TCP协议层以上的流量,比如HTTP(s),FTP,sFTP,邮件,即时通讯等等。其效果和HAProxy或者Nginx的TCP反向代理差不多,而且如果客户端的并发数比较大的情况,还可以使用JAVA的NIO和AIO框架,降低服务器资源的开销。
对于UDP协议来说,它是无连接无状态的点对点协议,所以与TCP协议比起来会有很大的不同,主要体现在:TCP是有链接协议,所以当有很多个客户端访问代理程序时,代理会转发他们的请求给服务器端,服务器响应数据给代理程序后,代理程序清楚的知道这个响应应该发给哪个客户端,并将数据发送回去。其逻辑如下
1、客户端发起一个Socket,绑定端口50000,目标地址为代理服务器8080。代理程序开启ServerSocket,绑定端口8080,于是一条客户端5000到代理端8080的连接就建立起来,客户端Socket通过OuputStream把数据发送给代理端的InputStream。
2、服务端监听到连接建立之后,立即new Socket,绑定51000端口,目标端口为真实服务器的80端口,于是一条代理服务器50000到真实服务器80的连接就建立起来。
3、然后代理服务器新建两个线程,一条将客户端的连接的InputStream写入到真实服务器连接的OutputStream,另一条线程将服务端连接的InputStream写入到客户端连接的OutputStream,就完成了一次代理转发。
在这个过程中,客户端开放了一个端口50000,代理程序开放两个端口8080和51000,真实服务器开放了一个端口80
如果有n个客户端,那么每个客户端也只开放一个端口,代理程序开放1+n个端口,真实服务器始终开放一个端口。
如果有n个客户端,每个客户端建立m条并发连接,那么每个客户端开放m个端口,代理程序开放1+m*n个端口,真实服务器开放一个端口。
从上面可以看出,对于TCP来说,每一条连接使用不同的端口进行区分,当一条连接建立起来时,客户端会监听一个49000以上的端口,代理端使用代理端口与其连接,但是代理端建立的与真实服务器的连接也会在代理端开放一个49000以上的端口,这个端口号和客户端开放的端口号一般是不同的。这样一来,在上面的例子中,服务端发送到代理端51000的数据包很自然的被代理端转发给客户端50000端口,一一映射不会出错。即使再多的客户端连接也不会混淆。
但是UDP协议是无连接的协议,它也可以仿照TCP协议的转发方式进行工作,过程如下
1、客户端发起一个DatagramSocket,绑定端口50000,目标地址为代理服务器的53端口。代理程序也new 一个 DatagramSocket,监听53端口。于是客户端就可以向代理端发送数据包了。
2、代理端收到数据包之后,有两个选择,第一是用接收客户端数据包的DatagramSocket把这个数据包发送到真实服务器,不过这样就没法再接收客户端发来的后续数据包了,所以一般情况下,代理程序会new DatagramSocket,把刚刚收到的DatagramPacket修改一下目标地址发送给真实的服务器。
3、现在代理端又有两个选择了,由于UDP不像TCP那样有流的概念,所以我们无法拿到输入输出流,只能操作数据包,而且是单向的操作数据包。一个方案是用刚刚向真实服务器发包的DatagramSocket接收服务端返回的数据包,另一个方案是不接受数据包继续转发下一个数据包。
第一个方案我们可以接收到服务器的返回数据,缺点是没法再利用这个DatagramSocket发送第二个数据包了,第二种方案可以流畅的转发客户端的数据包到服务端,不过客户端就收不到服务端的响应了。
所以此时,我们需要根据业务需求制定相关的转发策略了,这里我主要分为了两种类型
1、DNS型转发:客户端发送一个数据包需要服务端马上返回一个数据包实现业务逻辑,比如DNS。单个数据包最大为65536字节,某些环境下还会更小。
2、P2P隧道转发:客户端向服务端发送一连串的多个数据包,并且服务端也向客户端发送多个数据包,数据包收发并不是一问一答的关系,而是发送和接收同时进行。
逻辑上来说第一种方式是第二种方式的子集,只不过为了节约资源开销,第一种方式在服务端返回数据包以后立即关闭Socket,从而节约内存和网络资源。有些应用比如OpenVPN的udp模式就没有应答的概念,而是输入和输出像流一样同时进行。从代码实现上来说,第二种方式比较容易实现一些,首先建立两个DatagramSocket,一个监听在本地端口,用于接收客户端发来的数据包并转发真实服务器的响应;另一个把目的地址指向真实服务器,用于向真实服务器发送和接收数据包。在代理端的DatagramSocket通过receive()方法收到一个DatagramPacket之后,新建两个线程,一个负责接收客户端的数据包并向真实服务器发送数据包,另一个负责接收服务器发的数据包并修改目的地址发送给客户端。如此一来,通过两个DatagramSocket两个线程就实现了一个P2P的UDP转发隧道。
注意,UDP报文是没有FIN这种标识符的,所以代理服务器无法知道连接是否被主动关闭,只能通过超时时间去判断,所以为了连接保活,需要客户端定时发送心跳包。另外,如果端口是固定的话也可以让代理服务器建立永久的转发通道,只不过这样资源开销比较大,不适合高并发的场景。
上面的两种方式都面临一个问题,就是并发访问的问题。所谓并发访问就是代理服务器反向代理了一个端口,然后有不止一个客户端链接这个端口,或者一个客户端调用了多个程序并发访问该端口,那么如果代码上不做处理就会引起UDP数据包传递的混乱。
举个例子,比如客户端A向DNS反向代理发送了一个DNS请求,还没收到返回消息的时候客户端B也发出了一个DNS请求,这时代理服务器收到了真实服务器发来的客户端A请求的响应,由于UDP是无连接协议,所以此时代理服务器并不知道应该把数据包发到哪去。不向TCP那样获取到Socket之后直接写流就可以了。所以需要我们用JAVA代码去维护一个路由表。也就是说,当用户A请求DNS的时候,记录下A的源IP和端口号,然后new DatagramSocket向真实服务器发出请求,然后再用这个DatagramSOcket的receive()去接收返回数据包,然后按照刚才记录的A的ip和端口把数据发送回去,同理如果多个客户端来请求,那么就需要new 多个DatagramSOcket并记录每个请求的源IP和端口。如果多个客户端复用同一个DatagramSocket向真实服务器发送消息,虽然可以把数据包发送出去,但是收到响应以后你就无从获知是哪个客户端请求的了,所以这样做就会导致数据包错发的问题,会出现把客户端A请求DNS的响应错发给B,B本来请求的是www.csdn.com的IP,但是代理却发给它www.baidu.com的IP,这是和TCP最大的区别。如下图黄色图标标出的请求和相应信息,就发生了这种错乱:
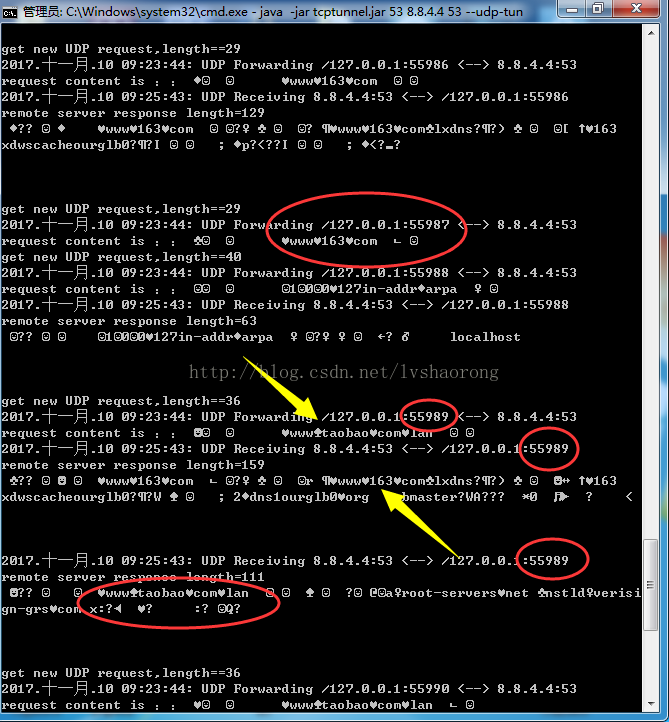
总结一下过程如下
1、一个客户端发出一个DNS请求到代理服务器53端口,开放端口50000监听返回值。代理端使用两个DatagramSocket,一个监听53端口,与客户端收发数据,另一个开放51000端口用来与真实服务器收发数据。真实服务器只开放一个53端口
2、n个客户端各发出一个DNS请求,每个客户端都开放50000端口监听返回数据,代理端使用1+n个DatagramSocket,开放53和另外n个UDP端口,并在内存中记录好每个客户端的源IP和端口,第一个DatagramSocket用来和所有客户端收发数据,后n个用来和真实服务器收发数据。
3、n个客户端都同时发出m个DNS请求,每个客户端开放50000,50001,50002...接收返回数据,代理端使用1+m*n个DatagramSocket,开放53和m*n个UDP端口,记录好每一个请求的源IP和端口,第一个DatagramSocket用来和所有客户端收发数据,后m*n个用来和真实服务器收发数据。
总的来说,有一点很重要,那就是同一会话使用同一个DatagramSocket,不同的会话使用不同的DatagramSocket,每一个UDP有两个会话,其中客户端和代理服务器的会话是所有客户端公用一个DatagramSocket,就像TCP里面的ServerSocket,代理服务器和真实服务器之间每个会话使用不同DatagramSocket,就像TCP里面为每个连接new的SOcket对象。当真实服务器响应了数据之后,一定要弄清楚该数据是发给哪个客户端的,而辨别的要点就是端口号,将代理端开放的端口和客户端发送的端口做一一映射的关系表,就不会错乱了。
关于Java实现UDP反向代理隧道的源代码可以看这里:https://github.com/AlexZhuo/java-tcp-tunnel
打成Jar包并且把Main.java设为主类,然后执行下面语句(JRE 1.7以上版本)
单个数据包收发(一发必有一收)
java -jar tcptunnel-0.1.0.jar 53 8.8.8.8 53 --udp-dns多个数据包收发(流式发送)
java -jar tcptunnel-0.1.0.jar 7000 xxx.xxx.xxx.xxx 9999 --udp-tun