Mastering_Rust(译):内存,生命周期和借用(完+1)
Rust让你,开发人员自己处理内存。 但是,它可以帮助您完成内存分配的抽象和语言支持。 它的生命周期,所有权和借用系统可能是您熟悉的C ++世界的概念。 Rust拥有所有这些,不仅仅是概念,而是语言以及编译时检查,使这一类最困难的运行时问题变得更容易编译。
本章将详细介绍Rust中的内存管理。 我们简要介绍了LLVM,Rust编译器使用的编译器框架及其中间表示代码。
本章涉及的主题是:
- LLVM
- 函数变量,堆栈
- 堆分配
- 移动,复制和克隆
- 所有权
- 借用
- 生命周期
- 通用类型框,Cell,RefCell,Rc
LLVM
Rust的编译器基于LLVM,这是一种编译器框架,可以更轻松,更强大地编写编译器。 其核心是一种称为IR的语言,简称为Intermediate Representation。 它是实际编程语言和机器特定汇编语言之间的中间立场。
使用LLVM为新语言实现编译器意味着为您的语言编写新的前端:一个程序,它接受用新语言编写的程序并输出LLVM IR代码。 LLVM本身包含几个目标体系结构的后端,这意味着新语言的开发人员将免费获得更多东西。
IR并不完全独立于目标机器,更不用说。 新的前端必须对目标体系结构做出一些选择,远远低于编写机器代码后端的情况。 让我们快速浏览一下IR代码的样子。 这是一个附加功能:
// add-1.ll
define i32 @add_unsigned(i32 %a, i32 %b) {
%1 = add i32 %a, %b
ret i32 %1
}
值是键入的,需要经常重复。 add_unsigned函数返回i32并获取两个i32参数,%a和%b。 然后,它为这些参数调用内部添加功能,并将答案存储在寄存器%1中。 然后返回该寄存器中的值。
接下来,我们将看到可以转换为哪种汇编程序代码。 如果你想运行这些llvm,你需要在本地安装llvm。 将IR转换为汇编程序的编译器称为LLVM静态编译器,其二进制文件通常为llc。 如果前面的代码在add.ll中,我们将运行以下代码:
llc -march=x86_64 add.ll
命令的输出保存在add.s.中 汇编程序代码是特定于目标的; 这就是它在Linux上的样子:
.text
.file "add.ll"
.globl add_unsigned
.align 16, 0x90
.type add_unsigned,@function
add_unsigned: # @add_unsigned
.cfi_startproc
# BB#0:
leal (%rdi,%rsi), %eax
retq
.Lfunc_end0:
.size add_unsigned, .Lfunc_end0-add_unsigned
.cfi_endproc
.section ".note.GNU-stack","",@progbits
很多样板,但实际功能包括leal和retq指令。 我们还可以从这段IR代码中验证我们可以为32位x86和ARM生成汇编代码。 只需将-march参数更改为x86或arm,函数代码将变为x86:
movl 4(%esp), %eax
addl 8(%esp), %eax
retl
对于ARM来说这是:
add r0, r0, r1
mov pc, lr
从一段Rust代码获取LLVM IR输出和相应的汇编器输出并不困难,尽管输出将包含更多的样板。 这是Rust中的一段简单代码:
// add-2.rs
fn add_one(a: u8) -> u8 {
let g = a + 255;
g
} f
n main() {
let x = 1;
let z = add_one(x);
let _ = z;
}
要从这段代码中获取IR,请使用rustc的–emit参数:
rustc --emit=llvm-ir add-2.rs
在这一点上重要的是不要优化代码,因为我们的程序非常简单,可能会完全优化掉。 不幸的是,结果代码相当大,并且充满了无趣的位。 不过,让我们来看几个有趣的。 如果您不完全理解这些,请不要担心,只需简单地浏览它们以便更熟悉语法。 首先,找到入口点,main:
// add-2.ll
define i64 @main(i64, i8**) unnamed_addr {
top:
%2 = call i64 @_ZN3std2rt10lang_start17h162055cb2e4b9fe7E(i8* bitcast (void ()* @_ZN4llvm4main17ha9d0e54b0b6fe
ret i64 %2
}
Rust编译器会破坏所有函数名称,但是我们可以在损坏的部分中看到函数名称。 例如:
@_ZN4llvm4main17ha9d0e54b0b6fe32aE
主要功能看起来像这样:
define internal void @_ZN4llvm4main17ha9d0e54b0b6fe32aE() unnamed_addr #0 {
entry-block:
%x = alloca i8
%z = alloca i8
store i8 1, i8* %x
%0 = load i8, i8* %x
%1 = call i8 @_ZN4llvm7add_one17h86509496e3ccd7f0E(i8 %0)
store i8 %1, i8* %z
ret void
}
在这里我们可以看到有两个堆栈分配(alloca指令)。 接下来,按照与相应Rust代码中几乎相同的顺序分配值。 最后,我们来看看add_one函数:
// add-2.ll
define internal i8 @_ZN4llvm7add_one17h86509496e3ccd7f0E(i8) unnamed_addr #0 {
entry-block:
%a = alloca i8
%g = alloca i8
store i8 %0, i8* %a
%1 = load i8, i8* %a
%2 = call { i8, i1 } @llvm.uadd.with.overflow.i8(i8 %1, i8 1)
%3 = extractvalue { i8, i1 } %2, 0
%4 = extractvalue { i8, i1 } %2, 1
%5 = icmp eq i1 %4, true
%6 = call i1 @llvm.expect.i1(i1 %5, i1 false)
br i1 %6, label %cond, label %next
next: ; preds = %entry-block
store i8 %3, i8* %g
%7 = load i8, i8* %g
ret i8 %7
cond: ; preds = %entry-block
call void @_ZN4core9panicking5panic17heeca72c448510af4E({ %str_slice, %str_slice, i32 }* noalias readonly dere
unreachable
}
在这里,Rust为简单的添加生成了相当多的额外代码。 原因主要是溢出检查:Rust在运行时检查整数溢出,因此相应的代码必须在那里。 LLVM内部函数uadd.with.overflow返回两个值,如果计算结束,则第二个值为true。
在接下来的部分中,我们将不再关注LLVM,而是随时查看生成的代码将会是什么样子。 查看程序的行为可能有点复杂,但是当您对细节感兴趣时,没有什么可以从实际的编译器输出中验证。
以下是您可以执行的一些练习:
1.使用rustc -O生成优化的LLVM IR代码。 你的代码怎么了?
2.在main中创建一个新的String值,并查看生成的IR代码类型。
3.添加println! 宏到你的代码。 它是如何影响IR代码的?
函数变量和堆栈
Rust的内存管理依赖于两个概念:堆栈和堆。 堆栈用于局部变量:函数中的所有let绑定都存储在堆栈中,作为值本身或作为对其他事物的引用。 它是一种极其快速和可靠的内存分配方案。 它很快,因为通过堆栈分配和释放内存只需要一条CPU指令:移动堆栈帧指针。 由于其简单性,它是可靠的:当函数完成时,通过将堆栈帧指针恢复到进入函数之前的位置来释放其所有堆栈内存。 这使得堆栈不那么通用,但是:堆栈中的东西没有办法比它的块寿命更长。
在使用Rust的日常工作中,不需要了解堆栈的含义,但它为两种不同的内存分配方案提供了良好的基础。
这是用于说明堆栈如何工作的第一个示例代码:
// stack-1.rs
fn f2(y: u8) -> u8 {
let x = 2 + y;
return x;
} f
n f1(x: u8) -> u8 {
let z = f2(5);
return z+x;
} f
n main() {
println!("f1(9) is {}", f1(9));
}
好的,那么当这个程序运行时堆栈中会发生什么? 为println的细节着色! 并关注堆栈的生存方式,它是这样的:
- main函数使用参数9调用f1,该参数位于堆栈中。 Stack现在是[9]。
2.我们输入f1,内存被保留并归零,以便从堆栈中进行z绑定。 Stack现在是[9,0]。
3.我们用参数5调用f2,它在堆栈上 - 现在是[9,0,5]。
4.我们输入f2,内存被保留用于堆栈的x绑定。 它被分配2 + 5。 堆栈现在是[9,0,5,7]。
- f2结束,返回值7,并释放其堆栈帧(包含[5,7])。 Stack现在是[9,0]。
6.返回f1,7分配给z。 Stack现在是[9,7]。
- f1结束,返回值9 + 7并释放其堆栈帧。 堆栈现在是空的。 要验证,这是运行此程序的输出:

您可能希望这段代码实际上不起作用,因为我们只是说堆栈中的东西不能超过它们的块。 您可能,特别是如果您习惯使用更高级别的语言,则将f2函数解释为实际从函数内部返回x变量。 相反,它实际上只是返回值的副本,这很好,因为x变量的副本与x变量不同。 具体来说,这是有效的,因为数字类型实现了复制特征。 更多关于这一点。
但是,如果我们明确地说我们想要返回对实际变量的引用,那么我们会遇到各种各样的麻烦。 &符号用于引用,因此我们尝试这样做的天真尝试可能如下所示:
// stack-2.rs
fn f1() -> &u8 {
let x = 4;
return &x;
} f
n main() {
let f1s_x = f1();
println!("f1 returned {:?}", f1s_x);
}
这是编译器的回复:

好的,让我们做编译器建议的事情,并将静态生命周期添加到return参数:
fn f1() → &'static u8
现在我们得到了我们正在寻找的更有趣的错误:

我们去! 编译器确认不应从函数返回局部变量(堆栈中分配的局部变量),因为它们在函数调用后不存在。 这没办法,所以Rust不允许这样做。
上一段代码大致相当于C中的这段代码:
/* stack-abuse.c */
#include
int* f1() {
int x = 4;
return &x;
} i
nt main() {
int *f1s_x = f1();
printf("f1 returned %d", *f1s_x);
}
即使它令人反感,这段代码也是有效的C.它会在运行时编译警告并崩溃到分段错误:
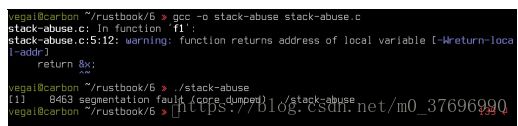
当然,真正的C程序中的内存访问问题并不是那么公然,但这很好地说明了这两种其他类似语言的某些差异:C允许有风险的代码,通过编译器启发式生成的警告来降低风险。 Rust拥有强大的生命周期系统,使风险更加遏制。
虽然堆栈简单而强大,但我们显然还需要更长寿命的变量:
1.使用您最喜欢的编程语言,以防它还没有Rust。 尝试找出它是否进行堆栈分配,以及是否有任何方法可以控制它。
2.每个进程都有一个有限的堆栈大小,由操作系统强制执行。 不同系统的大小各不相同,在Linux中通常大约为8MB。 想象一下,你可以通过几种方式使这个限制突破。
堆
堆用于更复杂和通用的内存分配方案。 堆中的值更加动态。 堆中的内存在程序的某个位置分配,在某个其他位置释放,并且这些点之间不必像堆栈那样存在严格的边界。 换句话说,堆中的值可能超出分配它的函数,但堆栈中的值可能不会。
请注意,存在一种称为堆的树状数据结构,但与编程语言实现相关的堆不同。 相反,我们现在讨论的堆只是编程语言中使用的动态分配内存池的通用术语,其设计可能有所不同。
Rust的堆由一个名为jemalloc的内存分配器提供,它为我们提供了良好的线性线程可伸缩性,或者由系统自己的分配器提供。 例如,在Linux上,这通常是glibc的malloc。
在进行二进制构建时,默认情况下会使用jemalloc分配器,而在进行库构建时,系统分配器是默认值。 这些默认值的原因是,在构建二进制文件时,编译器可以控制整个程序,因此它不必考虑外部实体并且可以选择更高效的jemalloc。 另一方面,库可以在构建库时不知道的不同情况下使用,因此使用系统分配器的选择更安全。
这种区别通常不是很重要,但是如果您需要覆盖这些默认值,可以使用功能标记并链接到特定的包中。 在代码中,模块的顶部需要如下所示:
#![feature(alloc_system)]
extern crate alloc_system;
这会强制使用系统分配器。 要强制jemalloc,你会说以下内容:
#![feature(alloc_jemalloc)]
#![crate_type = "dylib"]
extern crate alloc_jemalloc;
每次获得的值都不是原始值时,就会得到堆分配。 例如:
let s = String::new("foo")
String :: new将在堆中分配字符串并返回对它的引用。 该引用进入变量s,该变量在堆栈中分配。 堆中的字符串只要需要它就会生效:当s超出范围时,字符串也会这样做,然后删除它。
如果由于某种原因需要在堆中分配原始值,那么可以使用通用类型Box 。 它稍后会被提及。
内存安全
在许多现代语言中,堆栈和堆的用法都是从程序员中抽象出来的:您在代码中声明并使用变量,并根据使用模式分配它们。 通常,分配发生在堆中,某种形式的运行时垃圾收集负责解除分配。 最终结果是简单的内存安全性,但运行成本:分配决策自动发生,并且可能并不总是最适合您的程序。
相比之下,像C这样的低级系统编程语言没有任何东西可以隐藏程序员的这些细节,几乎没有安全性。 程序员可以通过以错误的顺序分配和解除分配,或者忘记取消分配来轻松地创建难以调试的错误。 此类错误会导致内存泄漏,以分段错误的形式发生硬崩溃,或者在最坏的情况下导致安全漏洞。 好处是专家C程序员可以绝对确定如何在程序中管理内存,因此可以自由地创建最佳解决方案。
这是C中的简单堆栈溢出:
// stack-overflow.c
int main() {
char buf[3];
buf[0] = 'a';
buf[1] = 'b';
buf[2] = 'c';
buf[3] = 'd';
}
这编译很好,甚至运行没有错误,但最后一次分配超过分配的缓冲区。 诸如此类的错误在实际代码中以不太明显的方式发生,并且经常导致安全问题。
现代C ++通过提供智能指针类型来防范与手动内存管理相关的一些问题,但这并不能完全消除它们。 此外,一些虚拟机(Java是最突出的例子)在其中有几十年的工作,以使垃圾收集高效,为大多数工作负载提供更好的性能。
Rust的卓越内存安全性有三大支柱:
1.没有空指针:如果某些东西可能什么都没有,可以安全地使用Option 。
2.任何类型的垃圾收集的可选库支持。
3.所有权,借用和生命周期:几乎所有内存使用的编译时验证。
首先,空指针被悲伤地称为Tony Hoare的“十亿美元错误”,他在1965年第一次实现它们。问题不是空指针本身,而是它们通常的实现方式:任何对象都可能是 赋值为null,但可以在不检查null的情况下使用这些对象。 大多数程序员都懒得检查所有用法,特别是当它强烈看起来不能为空时。 Rust的Option 允许空值,但使选择显式,并且不允许忽略空值。
这是一个愚蠢的模拟,以展示它是如何工作的。 想象一下Python中的一段代码,其中一个操作将在99%的时间内成功并返回一个对象。 剩下的1%我们只是忘记检查并让代码落空:
# meep.py
from random import random
class Meep:
def exclaim(self):
print("Holla!")
def probablyMakeMeep():
if random() > 0.1:
return Meep()
# implicitly returns None
while True:
meep = probablyMakeMeep()
meep.exclaim()
在使用未经检查的空指针的语言编写的程序中,这些类型的错误无处不在。 在Rust中,同样的问题也是可能的,但是您必须编写显式代码,说明您不关心空值,方法是使用我们之前看到的Option和Result类型的解包方法。
通过引用计数的原始垃圾收集已经通过Rc和Arc(“A”指的是原子,这意味着线程安全)泛型类型已经在标准库中。 对高级垃圾收集(Gc 类型)的支持正处于规划阶段,可能会在未来的某个时间点到达。
第三点是整章的核心。 所有权,生命周期和借用为我们提供了编译时检查的内存安全性,运行成本为零,无需收集垃圾。 我们将在接下来的三个部分中讨论其中的每一个。
所有权
使用let关键字时,可以创建临时变量绑定。 那些绑定将拥有它们绑定的东西。 当绑定超出范围时,绑定本身及其指向的任何内容都将被释放。 当一个块结束时:当{被一个}关闭时,就会超出范围。
这是一个例子
// blocks.rs
fn main() {
let level_0_str = String::from("foo");
{
let level_1_number = 9;
{
let level_2_vector = vec![1, 2, 3];
} // level_2_vector goes out of scope here
{
let level_2_number = 9;
} // level_2_number goes out of scope here
} // level_1_number goes out of scope here
} // level_0_str goes out of scope here
当然没有惊喜。 每个let绑定都在堆栈中分配,而非原始部分(这里是由vec!宏创建的String和Vector)在堆中。 这个编译得很好,虽然有警告,因为我们没有使用这些变量。
下一篇文章应该更有趣:
// multiple-owners.rs
fn main() {
let num1 = 1;
let num2 = num1;
let s1 = String::from("meep");
let s2 = s1;
println!("Number num1 is {}", num1);
println!("Number num2 is {}", num2);
println!("String s1 is {}", s1);
println!("String s2 is {}", s2);
}
这个看起来也很简单。 num2和s2都从num1和s1获取它们的内容。尽管如此,
这无法编译:
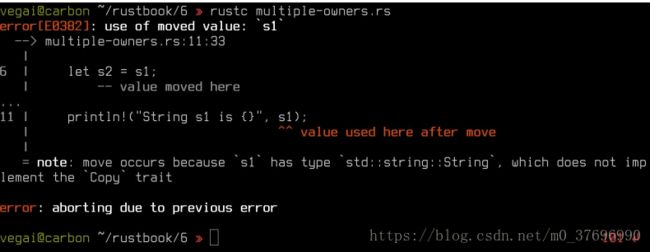
甚至更奇怪的是:num2绑定很好! 这是因为Rust中的类型根据类型本身的实现方式而有所不同:
- 所有类型都可以默认移动
- 实现复制特征的所有类型都是可复制的
正如您在编译器的帮助下所知,String类型不实现Copy trait,因此是可移动类型。 这意味着每次创建带有引用的新绑定时,原始值都将失效,无法再次使用。
复制特征(Copy trait)
当类型实现复制特征时(就像所有原始数字类型一样),每个新绑定都会导致值的新副本而不是移动。 这就是为什么之前的例子中的num2绑定很好的原因:它导致创建一个新的副本,并且num1保持不变并仍然可用。
高级编程语言做类似的事情,但隐藏实现幕后实际发生的事情。 例如,查看这些赋值操作,然后在Python中进行突变:
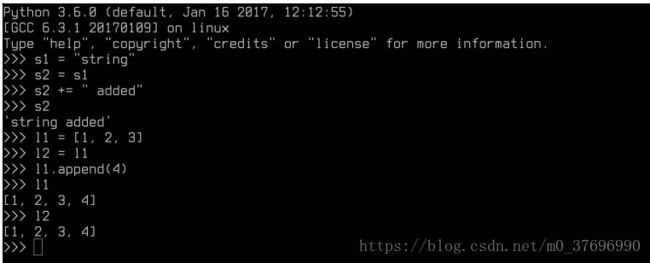
由于Python中的字符串是不可变的,因此赋值操作必须复制字符串,而变异才能生成第三个副本。 另一方面,Python列表是可变的,因此l1和l2将指向相同的列表,因此具有相同的内容。 每个python程序员都知道这些细节,因此它在实践中非常有效。 然而,由于零成本线程安全内存安全的目标,Rust没有这样的奢侈品。
如果我们真的想这样做,我们可以显式克隆String:
let s2 = s1.clone();
克隆要求该类型实现Clone特征,而Strings恰好这样做。 您可能想知道复制和克隆特征之间的区别是什么。 好问题! 以下是一些指导原则:
- 如果可以非常便宜地复制类型,即,通过简单地复制其中的位,可以为其实现复制特征。
- 如果类型仅依赖于在其上实现了Copy的其他类型,则可以为其实现Copy trait。
- 否则,可以使用克隆特征。 它的实施可能更昂贵。
- 复制特征隐式地影响赋值运算符=的工作方式。
- 克隆特征仅仅声明了一个克隆方法,需要显式调用。
决定是否使自己的外部可见类型服从复制特征需要一些考虑因为它如何影响赋值运算符。 如果在开发的早期阶段,您的类型是一个副本,然后您将其删除,它会影响分配该类型值的每个点。 您可以通过这种方式轻松破解API。
功能参数和模式
除了let表单之外,相同的移动和复制系统适用于其他变量绑定。 如果将参数传递给函数,则相同的规则有效:
// functions.rs
fn take_the_n(n: u8) {
} f
n take_the_s(s: String) {
} f
n main() {
let n = 5;
let s = String::from("string");
take_the_n(n);
take_the_s(s);
println!("n is {}", n);
println!("s is {}", s);
}
编译以熟悉的方式失败:
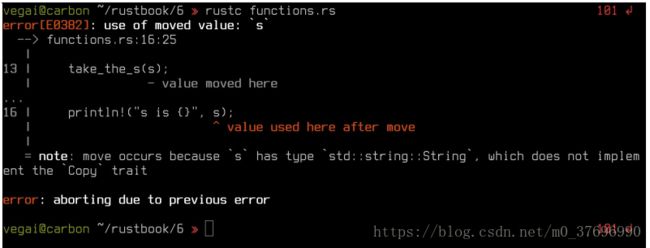
String类型未实现Copy trait,因此值的所有权将移至take_the_s函数。 当该函数的块结束时,该值的范围已完成并被释放。 因此,在函数调用之后不能再使用它。 这个简单的修复与之前类似:在函数调用站点添加.clone()调用:
take_the_s(s.clone());
因此,实际上您必须克隆所有未实现Copy特征的函数参数,甚至那些实现它的函数也会每次都被复制。 正如您可能想象的那样,零成本承诺并不顺利,而且非常尴尬。 这就是借用系统的用武之地。
以下是您可以执行的一些练习:
1.使用您喜欢的第二种编程语言,并尝试确定变量的所有权是否起任何作用。 也许幕后,隐藏?
2.编译器/解释器是否帮助编码器使用该语言来解决所有权问题,或者这一切都掌握在程序员手中?
借用
如您所见,在进行函数调用时移动所有权通常没有多大意义。 相反,您可以使用&符号将函数参数定义为借用引用。 我们可以修复前面的代码示例来传递编译器而不像这样克隆:
// functions-with-borrows-1.rs
fn take_the_n(n: &u8) {
} f
n take_the_s(s: &String) {
} f
n main() {
let n = 5;
let s = String::from("string");
take_the_n(&n);
take_the_s(&s);
println!("n is {}", n);
println!("s is {}", s);
}
请注意,&需要在呼叫站点和参数列表中使用。 与默认情况下变量绑定的方式类似,默认情况下引用是不可变的。
为了获得引用后面的实际值,使用星号运算符*。 例如,如果我们想让take_the_n也输出数字,它将如下所示:
fn take_the_n(n: &u8) {
println!("n is {}", *n);
}
要获得可变引用,您需要修改三件事:实际变量绑定,调用站点和函数参数列表。 首先,变量绑定必须是可变的:
let mut n = 5;
然后,该函数将更改为:
fn take_the_n(n: &mut u8) {
*n = 10;
}
呼叫站点需要更改为此表单:
take_the_n(&mut n);
再次,我们看到Rust中的所有内容都是明确的。 如果它们是特别危险的东西,它们就更加明确。 出于显而易见的原因,可变变量比不可变变量更危险,特别是当多线程发挥作用时。
有一些与借用引用相关的规则:
- 借用参考的寿命可能不会超过其所指的时间。 很明显,因为如果它这样做,将它指的是一个死的东西。
- 如果存在对事物的可变引用,则不允许同时对同一事物进行多个引用(可变或不可变)。
- 如果没有对事物的可变引用,则允许同时对同一事物进行任意数量的不可变引用。
这些规则在编译时由编译器的借用检查器验证。 让我们看看每个点的违规示例:
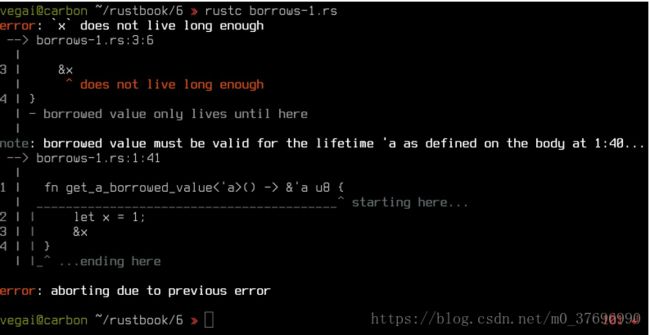
1.我们将有一个函数试图返回对函数退出时消失的值的引用:
// borrows-1.rs
fn get_a_borrowed_value<'a>() -> &'a u8 {
let x = 1;
&x
} f
n main() {
let value = get_a_borrowed_value();
}
是终身规范; 我们会在一分钟内找到那些人。 这无法通过借用检查器:
2.我们可以对任何东西进行任意数量的不可变引用:
// borrows-2.rs
fn main() {
let x=1;
let x1 = &x;
let x2 = &x;
println!("x1 says {}", *x1);
println!("x2 says {}", *x2);
}
这将按预期编译和运行。
3.如果存在对某事物的主动可变引用,则可能没有其他引用:
// borrows-3.rs
fn main() {
let mut x = 1;
{
let immut_x_1 = &x;
} {
let mut_x_1 = &mut x;
} l
et mut_x_2 = &mut x;
let immut_x_3 = &x;
}
这无法编译:

前两个借用并不重要,因为它们在块之后消失了,但是最后一次不可变借用打破了规则并破坏了代码。
该系统的动机主要是防止多线程情况下的可变误用。 允许许多不可变引用但只有一个可变引用的规则类似于分布式系统中的规则:多个只读锁很好,但即使单个写锁也会影响所有内容。
请注意,可变性或不变性完全在绑定级别定义。 也就是说,根据绑定的内容,值是可变的或不可变的。 这也适用于结构和枚举等内容:
要么他们所有的领域都是可变的,要么都不是。 但是,这不是整个故事,因为结构中的不可变字段可能是对其他内容的引用,虽然该引用不能更改,但它指向的内容可以。 Cell和RefCell类型特别利用了这一点,我们很快就会介绍它们。
请注意,与借用机制相比,此移动对于impl块也同样有效,尤其是它们的自身参数。 如果你定义一个将self作为非借用变量的方法,那意味着self的所有权移动到方法,当方法完成时,self会超出范围并被删除! 因此,除非您故意编写一个最终应该删除self的方法,否则请始终使用&self作为方法参数。
生命周期
Rust内存安全难题中的第三部分是生命周期。 如果你曾用C编程,你应该敏锐地意识到生命周期问题:每次你用malloc分配一些变量时,它应该有一个明确的所有者,并且所有者应该可靠地决定该变量的生命何时结束。 它没有在任何地方编纂; 而这是程序员的责任。
在Rust中,每个引用都附有生命周期。 生命周期定义了引用相对于其他引用的生存时间。 只要它能够,Rust编译器就会在没有程序员帮助的情况下通过一种名为life elision的机制来与它们交互。 然而,有时候它不能,然后它需要我们的帮助。
这是我们手动指定生命周期所需的所有地方的列表:
- 全局静态和常量
- 功能签名
- 结构和结构域
- impl签名
让我们来看看他们。
全局变量
我们在全局字符串切片之前已多次看到其中一个案例:
const MEEP: &'static str = "meep";
static SECOND_MEEP: &'static str = "meep2";
因为Rust的类型推断只是局部的,所以需要在这里指定生命周期,因此我们需要拼出所有全局变量的类型。 静态生命周期意味着这些值在程序启动时开始存在,并在程序执行时消失。 Rust程序中的所有文字字符串都是静态的,因为&'static str与&str的类型不同,如果我们没有在这里明确指定生命周期,我们会得到类型错误。
引用为函数参数
只要函数中有引用,无论是作为输入参数还是输出值,该引用都会获得生命周期。 在许多情况下,编译器能够找出唯一可能的生命周期,因此我们不必这样做。 换句话说,这两个功能签名是相同的:
fn f(x: &u8) → &u8
fn f<'a>(x: &'a u8) → &'a u8
当你第一次看到它时,我建议你很慢地查看生命周期语法。 一开始可能令人生畏,但它会变得更加容易。 第一次出现,就在函数名之后,是生命周期声明。 它说f函数包含生命周期’a’的参数。 在第二次出现时,我们说x的生命周期为’a’,第三次表示该函数返回具有相同生命期的值。 您可能会注意到语法类似于泛型类型语法,这不是偶然的:生命周期是一种泛型类型。
所以这一切都说明你不能返回一个函数的原始引用,除非你把这个引用作为参数引入函数。 此外,如果您引入多个引用,则需要指定要返回的生命周期。 换句话说,这不会飞:
fn f(x: &u8, y: &u8) → &u8
如果有多个引用和返回引用,则必须明确定义生命周期:
fn f<'a>(x: &'a u8, y: &'a u8) → &'a u8
结构和结构域
每当结构体中都有引用时,我们需要明确指定这些引用将存在多长时间。 语法类似于函数签名的语法:我们首先在struct line上声明生命周期名称,然后在字段中使用它们。
以下是最简单形式的语法:
struct Number<'a> {
num: &'a u8
}
我们在这里说的是num字段不能引用任何比struct Foo的封闭实例长得多的u8值。 我们再次明确地说,就像Rust的方式一样。
Impl签名
当我们为带有引用的结构创建impl块时,我们需要再次重复生命周期声明和定义。 例如,如果我们为我们定义的Foo结构做了一个实现
以前,语法如下所示:
// lifetime-structs.rs
impl<'a> Number<'a> {
fn get_the_number(&self) -> &'a u8 {
self.num
}f
n set_the_number(&mut self, new_number: &'a u8) {
self.num = new_number
}
Drop trait
Drop trait是你在其他语言中称为对象析构函数方法的东西。 它包含一个方法drop,当对象超出范围时会调用它。 这是按照严格的顺序完成的:后进先出。 也就是说,无论最后构建的是什么,都会被第一个破坏。 例如:
// drops.rs
struct Character {
name: String
} i
mpl Drop for Character {
fn drop(&mut self) {
println!("{} went away", self.name)
}
} f
n main() {
let steve = Character { name: "Steve".into() };
let john = Character { name: "John".into() };
}
输出如下:

如果需要,可以在此机制中为自己的结构放置清理代码。 对于清理不太明确的类型,例如使用引用计数值或垃圾收集器时,它尤其方便。
收集器类型
接下来,我们将看一些通用类型,通过它们可以控制堆中的内存分配是如何完成的。 类型如下:
- Box :这是最简单的堆分配形式。 该box拥有其中的值,因此可用于在结构内保存值或从函数返回它们。
- Cell :这为我们提供了实现Copy特征的类型的内部可变性。 换句话说,我们有可能获得多个可变引用。
- RefCell :这给了我们类型的内部可变性,而不需要复制特征。 使用运行时锁定以确保安全。
- Rc :这是用于参考计数。 每当某人获取新引用时它会递增计数器,当有人发布引用时递减计数器。 当计数器达到零时,该值将被删除。
- Arc :这是用于原子引用计数。 与之前的类型一样,但具有原子性以保证多线程的安全性。 以前类型的组合
(例如RefCell)。
Box
标准库中的通用类型box为我们提供了在堆中分配值的最简单方法。 如果您熟悉其他语言的装箱和拆箱概念,这是相同的。
Box本身不实现复制特征,这使其成为移动类型。 这意味着,与其他移动类型一样,如果您对现有Box进行新绑定,则先前的绑定将失效。
要获取新Box,请像处理任何其他容器类型一样:调用静态新方法。 获取值,请使用*运算符:
let boxed_one = Box::new(1);
let unboxed_one = *boxed_one;
复制类型的内部可变性 - Cell
如前所述,Rust通过同时仅允许一个可变引用,在编译时保护我们免受别名问题的影响。 但是,有些情况下限制太多,因为严格的借用检查,使我们知道的代码安全无法通过编译器。
内部可变性允许我们稍微改变借用规则。 标准库有两种通用类型:Cell和RefCell。 Cell是零成本的:编译器生成的代码类似于原始的可变引用。 关键是,正如我们之前看到的,多个可变引用是不可接受的。 Cell 要求封闭类型实现Copy trait。
因为Cell会使规则发生变化,所以在使用或看到Cell 时应该小心:可能有多个可变引用内部值。 当然,这意味着您从Cell读取的值可能会在您读取后发生变化。
cell通过三种方法工作:
- Cell :: new创建一个新的Cell,其值作为参数在里面给出
- get方法返回里面的值
- set方法用新值替换该值
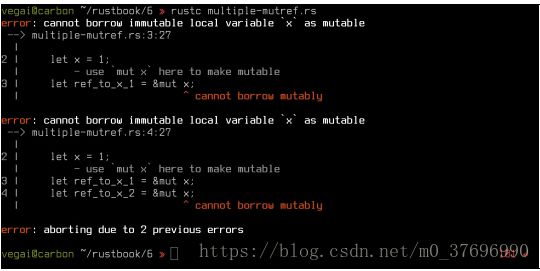
在最简单的形式中,我们可以将几个可变指针指向单个值:
fn main() {
let x = 1;
let ref_to_x_1 = &mut x;
let ref_to_x_2 = &mut x;
*ref_to_x_1 += 1;
*ref_to_x_2 += 1;
}
但是,当然,由于基本的借用检查,这不会编译:
您可以通过将值封装在Cell中并通过以下方式使用它来完成此工作:
// multiple-cells.rs
use std::cell::Cell;
fn main() {
let x = Cell::new(1);
let ref_to_x_1 = &x;
let ref_to_x_2 = &x;
ref_to_x_1.set(ref_to_x_1.get() + 1);
ref_to_x_2.set(ref_to_x_2.get() + 1);
println!("X is now {}", x.get());
}
这可以按照您的预期工作,唯一增加的成本是代码稍微尴尬。 但是,额外的运行时成本为零,并且对可变事物的引用仍然是不可变的。 在内部,这完全是由于内部值是复制类型的要求:Rust可以自由复制内部值而无需担心丢弃先前的值会导致问题。
移动类型的内部可变性-RefCell
如果您的非复制类型需要类似Cell的功能,RefCell可以提供帮助。 它在运行时为您使用读/写锁,这很方便,但不是零成本。 另一个区别是,虽然Cell允许您处理实际值,但RefCell会处理引用。 这意味着相同的可变借用限制实际上与原语一起使用引用绑定,但在运行时而不是编译时检查RefCell限制。
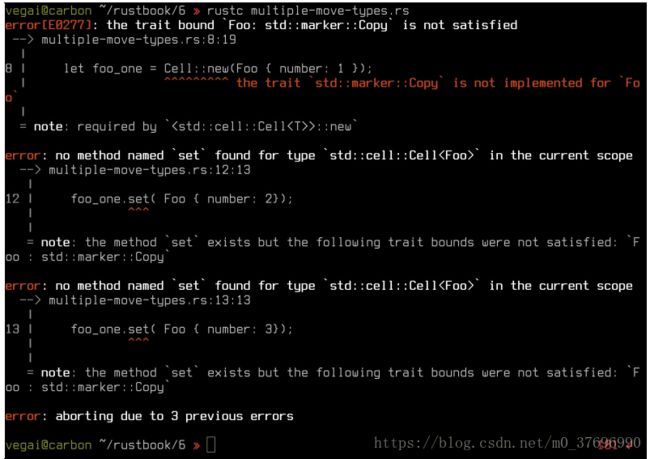
如果您尝试使用移动而不是副本的类型的Cell ,则会发生这种情况。 换句话说,对于不实现复制特征的类型:
// multiple-move-types.rs
use std::cell::Cell;
struct Foo {
number: u8
} f
n main() {
let foo_one = Cell::new(Foo { number: 1 });
let ref_to_foo_1 = &foo_one;
let ref_to_foo_2 = &foo_one;
foo_one.set( Foo { number: 2});
foo_one.set( Foo { number: 3});
}
引用编译器:
基本部件的RefCell API是两种借用方法:
- 借用方法采用新的不可变引用
- borrow_mut方法采用新的可变引用
让我们尝试将前面的代码转换为使用RefCells:
// multiple-move-types-with-refcell-1.rs
use std::cell::RefCell;
struct Foo {
number: u8
} f
n main() {
let foo_one = RefCell::new(Foo { number: 1 });
let mut ref_to_foo_1 = foo_one.borrow_mut();
let mut ref_to_foo_2 = foo_one.borrow_mut();
ref_to_foo_1.number = 2;
ref_to_foo_2.number = 3;
}
编译得很好,但这里有一个问题。 我们打破了那里只有一个可变参考规则,我们感到恐慌:

我们需要让借用绑定以某种方式消失,或者通过将它们封闭在块中或通过显式调用drop函数,就像我们在这里做的那样:
// multiple-move-types-with-refcell-2.rs
let mut ref_to_foo_1 = foo_one.borrow_mut();
ref_to_foo_1.number = 2;
drop(ref_to_foo_1);
let mut ref_to_foo_2 = foo_one.borrow_mut();
ref_to_foo_2.number = 3;
此版本运行没有错误。
内部可变性的实际用途
Cell和RefCell的示例已经过简化,您很可能不需要在实际代码中以该形式使用它们。 让我们来看看这些类型给我们带来的一些实际好处。
如前所述,绑定不是细粒度的:值是不可变的或可变的,如果它是结构或枚举,则包括其所有字段。 Cell和RefCell可以将不可变的东西变成可变的,允许我们将不可变结构的部分定义为可变的。
下面的代码使用两个整数和sum方法来扩充结构,以缓存求和的答案,并返回缓存的值(如果存在):
// interior-mutability.rs
use std::cell::Cell;
struct Point {
x: u8,
y: u8,
cached_sum: Cell>
} i
mpl Point {
fn sum(&self) -> u8 {
match self.cached_sum.get() {
Some(sum) => {
println!("Got from cache: {}", sum);
sum
},
None => {
let new_sum = self.x + self.y;
self.cached_sum.set(Some(new_sum));
println!("Set cache: {}", new_sum);
new_sum
}
}
}
} f
n main() {
let p = Point { x: 8, y: 9, cached_sum: Cell::new(None) };
println!("Summed result: {}", p.sum());
println!("Summed result: {}", p.sum());
}
运行此代码表明缓存正在运行,而无需使整个p变为可变!

除了使用具有自己结构的Cell类型之外,还有一个模式,我们将Cell / RefCell与另一个通常只使用不可变类型的泛型类型结合起来。 一个这样的例子是Rc 类型,我们将在下面讨论。
引用计数回收内存:Rc 和Arc
引用计数是一种简单的垃圾收集形式。 Rc的基本事件流程如下:
- 每当有人采用新的参考时,我们都会增加一个内部计数器
- 每次有人丢弃参考时,我们都会减少它
- 当内部计数器达到零时,没有人再引用该对象,因此可以将其丢弃
在引用计数容器中使用变量为我们提供了更大的实现灵活性:我们可以分发对值的引用,而无需精确跟踪引用何时超出范围。
Rc 主要通过两种方法使用:
- 静态方法Rc :: new生成一个新的引用收集容器(你应该开始识别一个模式!)
- clone方法增加强引用计数并发出新的Rc
引用计数系统支持两种引用:强(Rc )和弱(Weak )。两者都保留了每种类型的引用数量的计数,但只有当强引用为零时,才会释放值。这样做的动机是数据结构的实现可能需要多次指向同一个事物。例如,树的实现可能引用子节点和父节点,但是为每个这样的引用递增计数器将是不正确的。相反,对父引用使用弱引用不会破坏计数。
作为另一个例子,链接列表可以以这样的方式实现,即它通过引用计数将链接维护到下一个项目和前一个项目。但是,如果我们计算每个方向,计数将是不正确的。更好的方法是使用对一个方向的强引用和对另一个方向的弱引用。
让我们看看它是如何工作的。这是最糟糕的实际但最好的学习数据结构的最小实现:单链表:
// rc-1.rs
use std::rc::Rc;
#[derive(Debug)]
struct LinkedList {
head: Option>>
} #
[derive(Debug)]
struct LinkedListNode {
next: Option>>,
data: T
} i
mpl LinkedList {
fn new() -> Self {
LinkedList { head: None }
} f
n append(&self, data: T) -> Self {
LinkedList {
head: Some(Rc::new(LinkedListNode {
data: data,
next: self.head.clone()
}))
}
}
} f
n main() {
let list_of_nums = LinkedList::new().append(1).append(2);
println!("nums: {:?}", list_of_nums);
let list_of_strs = LinkedList::new().append("foo").append("bar");
println!("strs: {:?}", list_of_strs);
}
此链接列表由两个结构组成:LinkedList提供对列表的第一个元素和列表的公共API的引用,LinkedListNodes包含实际元素。 注意我们如何使用Rc并克隆每个附加的下一个数据指针。 让我们来看看附录中发生的情况:
- LinkedList :: new()为我们提供了一个新列表。 头是没有的。
我们在列表中附加1。 Head现在是包含1作为数据的节点,接下来是前一个头:None。
我们在列表中追加2。 Head现在是包含2作为数据的节点,接下来是前一个头,包含1作为数据的节点。
来自println的调试输出! 证实了这一点:

这是这种结构的一种相当功能的形式:每个附加只通过在头部添加数据来工作,这意味着我们不必使用引用,实际的列表引用可以保持不变。 如果我们想保持结构这么简单但仍然有一个双链表,那会有所改变,因为那时我们实际上必须改变现有的结构。
您可以使用降级方法将Rc 类型降级为Weak 类型,类似地,可以使用升级方法将Weak 类型转换为Rc 。 降级方法将始终有效。 相反,在弱引用上调用upgrade时,实际值可能已经被删除,在这种情况下,您将获得None。
所以让我们添加一个指向前一个节点的弱指针:
// rc-2.rs
use std::rc::Rc;
use std::rc::Weak;
#[derive(Debug)]
struct LinkedList {
head: Option>>
} #
[derive(Debug)]
struct LinkedListNode {
next: Option>>,
prev: Option>>,
data: T
} i
mpl LinkedList {
fn new() -> Self {
LinkedList { head: None }
} f
n append(&mut self, data: T) -> Self {
let new_node = Rc::new(LinkedListNode {
data: data,
next: self.head.clone(),
prev: None
});
match self.head.clone() {
Some(node) => {
node.prev = Some(Rc::downgrade(&new_node));
},
None => {
}
} L
inkedList {
head: Some(new_node)
}
}
} f
n main() {
let list_of_nums = LinkedList::new().append(1).append(2).append(3);
println!("nums: {:?}", list_of_nums);
}
append方法增长了一点:我们现在需要在返回新创建的头之前更新当前头的前一个节点。 这几乎足够好,但并不完全。 编译器不允许我们做顽皮的事情:
我们可以使append对self进行可变引用,但这意味着如果所有节点的绑定都是可变的,我们只能附加到列表中,从而迫使整个结构变得可变。 我们真正想要的是一种方法,使整个结构的一小部分变得可变,幸运的是我们可以用一个RefCell来做到这一点。
1.为RefCell添加一个RefCell:
use std::cell::RefCell;
2.在RefCell中的LinkedListNode中包装前一个字段:
// rc-3.rs
#[derive(Debug)]
struct LinkedListNode {
next: Option>>,
prev: RefCell>>>,
data: T
}
3.我们更改append方法以创建新的RefCell并通过RefCell可变借用更新prev参考:
// rc-3.rs
fn append(&mut self, data: T) -> Self {
let new_node = Rc::new(LinkedListNode {
data: data,
next: self.head.clone(),
prev: RefCell::new(None)
});
match self.head.clone() {
Some(node) => {
let mut prev = node.prev.borrow_mut();
*prev = Some(Rc::downgrade(&new_node));
},
None => {
}
} L
inkedList {
head: Some(new_node)
}
}
}
每当使用RefCell借用时,最好仔细考虑我们是否以安全的方式使用它,因为在那里犯错可能会导致运行时恐慌。 然而,在这个实现中,很容易看出我们只有单个借位,并且关闭块会立即丢弃它。
使用std :: mem检查内存使用情况
如果你对所有这些不同的收集器类型使用内存感兴趣,你不必猜测。 std :: mem模块包含用于在运行时检查的有用函数。 我们来看几个:
- size_of返回通过泛型类型给出的类型的大小
- size_of_val返回作为引用给出的值的大小
如果我们对某些前面的泛型类型的零成本声明持怀疑态度,我们可以使用这些函数来检查开销。 如果你还不熟悉size_of的调用样式可能有点奇怪:我们实际上并没有给它任何参数作为参数; 我们只是针对某种类型明确地调用它。 我们来看看一些尺寸:
// mem-introspection.rs
use std::cell::Cell;
use std::cell::RefCell;
use std::rc::Rc;
fn main() {
println!("type u8: {}", std::mem::size_of::());
println!("type f64: {}", std::mem::size_of::());
println!("value 4u8: {}", std::mem::size_of_val(&4u8));
println!("value 4: {}", std::mem::size_of_val(&4));
println!("value 'a': {}", std::mem::size_of_val(&'a'));
println!("value \"Hello World\" as a static str slice: {}", std::mem::size_of_val("Hello World"));
println!("value \"Hello World\" as a String: {}", std::mem::size_of_val("Hello World").to_string());
println!("Cell(4)): {}", std::mem::size_of_val(&Cell::new(84)));
println!("RefCell(4)): {}", std::mem::size_of_val(&RefCell::new(4)));
println!("Rc(4): {}", std::mem::size_of_val(&Rc::new(4)));
println!("Rc): {}", std::mem::size_of_val(&Rc::new(RefCell::new(4))));
}
以下是一些专门针对内存反射的练习:
1.尝试推断出上述每种类型的大小。
2.编译并运行代码。 了解你的猜测和现实之间的差异。
最后的练习
1.查找有关生命周期,借阅和所有权的博客文章。 读他们!
2.看一些更高级的项目; 看看数据结构,特别注意内存处理。 寻找Cells,RefCells和Rc。 寻找终身注释。
概要
Rust采用低级系统编程方法进行内存管理,具有类似C的性能。 它通过其内存所有权,借用和生命周期系统不需要垃圾收集器。 这些概念并不新鲜,但它们的组合和编纂以及它们给出的安全范围是。
我们在一个主题中涵盖了很多内容,对于一个新的Rust程序员来说,这可能是最重要的。 熟练掌握所有这些需要相当多的工作和各种不同的方法来解决问题。 本章的最后练习是更自由的形式,以便在这个研磨后给你一点喘息的空间。