达梦数据库DCA学习笔记
达梦数据库DCA学习笔记
- 表、视图、索引
表、视图、索引
本文是这个新建账号的第一篇文章,旨在针对达梦DCA学习进行一个简单的记录。
表、试图、索引是数据库的核心高频使用功能,节选此节作为记录。
1.1 模式
模式:一组数据对象的集合,在创建用户的时候,就会生成一个跟用户同名的模式
1.2 表
达梦支持的表:默认的表(索引组织表),堆表,临时表,分区表,外部表等
如何规划表?
–命名:字符开头a-z,0-9,$#_
–数据类型:int,char,varchar,date,clob,blob,number等
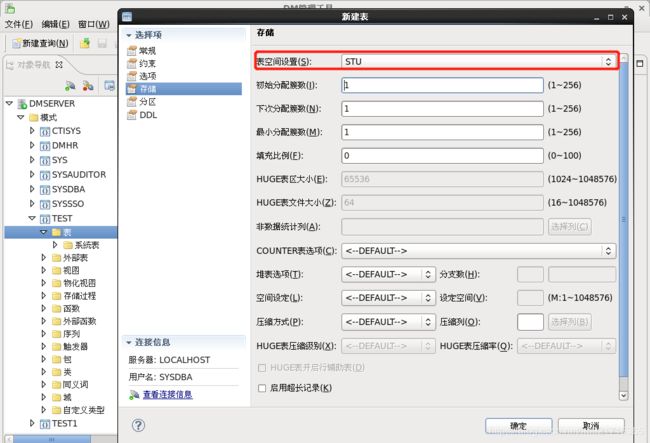
–存储位置:自己规划的表空间,未指定则是默认空间
–约束:非空,唯一,主键,检查,外键
–注释:comment
-
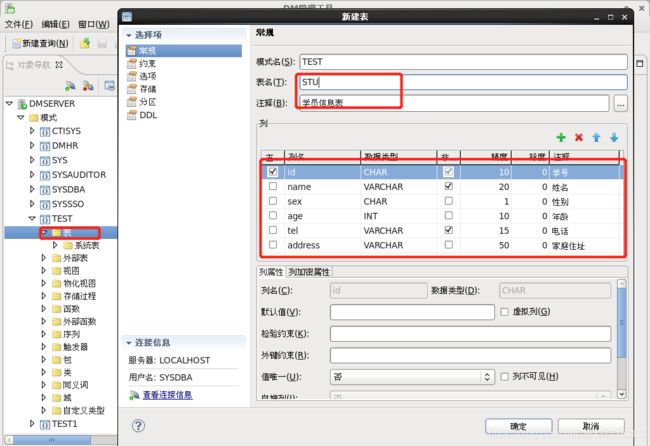
案例1:规划一张学员信息表
表名:STU
列:学号(id,char(10)),姓名(name,varchar(20)),性别(sex,char(1)),
年龄(age,int),电话(tel,varchar(15)),家庭住址(address,varchar(50))
表空间:STU
约束:主键–学号,非空–姓名,电话
备注:学员信息表

// 创建的SQL
create table "TEST"."STU"
(
"id" CHAR(10) not null ,
"name" VARCHAR(20) not null ,
"sex" CHAR(1),
"age" INT unique ,
"tel" VARCHAR(15) not null ,
"address" VARCHAR(50),
primary key("id")
)
storage(initial 1, next 1, minextents 1, fillfactor 0, on "STU")
;
comment on table "TEST"."STU" is '学员信息表';
comment on column "TEST"."STU"."id" is '学号';
comment on column "TEST"."STU"."name" is '姓名';
comment on column "TEST"."STU"."sex" is '性别';
comment on column "TEST"."STU"."age" is '年龄';
comment on column "TEST"."STU"."tel" is '电话';
comment on column "TEST"."STU"."address" is '家庭住址';
// 查看表结构
SQL> desc test.stu;
行号 NAME TYPE$ NULLABLE
---------- ------- ----------- --------
1 id CHAR(10) N
2 name VARCHAR(20) N
3 sex CHAR(1) Y
4 age INTEGER Y
5 tel VARCHAR(15) N
6 address VARCHAR(50) Y
SQL> sp_tabledef(‘TEST’,‘STU’); #区分大小写
行号 COLUMN_VALUE
1 CREATE TABLE “TEST”.“STU” ( “id” CHAR(10) NOT NULL, “name” VARCHAR(20) NOT NULL, “sex” CHAR(1), “age” INT, “tel” VARCHAR(15) NOT NULL, “address” VARCHAR(50), CLUSTER PRIMARY KEY(“id”), UNIQUE(“age”)) STORAGE(ON “STU”, CLUSTERBTR) ;
SQL> select dbms_metadata.get_ddl(‘TABLE’,‘STU’,‘TEST’);
行号 DBMS_METADATA.GET_DDL(‘TABLE’,‘STU’,‘TEST’)
1 CREATE TABLE “TEST”.“STU”
(
“id” CHAR(10) NOT NULL,
“name” VARCHAR(20) NOT NULL,
“sex” CHAR(1),
“age” INT,
“tel” VARCHAR(15) NOT NULL,
“address” VARCHAR(50),
CLUSTER PRIMARY KEY(“id”),
UNIQUE(“age”)) STORAGE(ON “STU”, CLUSTERBTR) ;
// 如何查看表在哪个表空间
SQL> select table_name,tablespace_name from dba_tables where table_name=‘STU’;
行号 TABLE_NAME TABLESPACE_NAME
1 STU STU
// 如何查看表有哪些约束
SQL> select table_name,constraint_name,constraint_type from dba_constraints where table_name=‘STU’;
行号 TABLE_NAME CONSTRAINT_NAME CONSTRAINT_TYPE
1 STU CONS134218775 P
2 STU CONS134218774 U
-
案例2:创建表的时候指定约束
SQL> create table test.t2(id int); SQL> alter table test.t2 modify id int not null; // 上面两条语句等价于 SQL> create table test.t3(id int not null); // 唯一约束 SQL> create table test.t4(id int unique); // 主键约束 SQL> create table test.t5(id int primary key); SQL> create table test.t6(id int);
SQL> alter table test.t6 add constraint t6_pri primary key(id);
// 检查约束
SQL> create table test.t8(id int);
SQL> alter table test.t8 add constraint t9_check check(id>=5);
SQL> create table test.t7(id int check(id>=5));
// 外键约束
SQL> create table test.t9(sid int primary key,pid int);
SQL> create table test.t10(id int primary key, sid int foreign key references test.t9(sid));
// 增加备注
SQL> comment on column test.t2.id is ‘编号’;
如何导入数据
- start语句
[dmdba@localhost ~]$ pwd
/home/dmdba
[dmdba@localhost ~]$ cat q.sql
insert into test.t2 values(1);
insert into test.t2 values(2);
insert into test.t2 values(3);
[dmdba@localhost ~]$ disql sysdba/dameng123
SQL> start /home/dmdba/q.sql
SQL> insert into test.t2 values(1);
SQL> select * from test.t2;
行号 ID
1 1
2 2
3 3
- bin/dts工具


-
如何去维护表
// 增加/删除列 SQL> alter table test.t2 add name varchar(20) default 'eason'; SQL> alter table test.t2 drop name; // 启用和禁用约束: SQL> alter table test.t9 disable constraint CONS134218782; SQL> alter table test.t9 enable constraint CONS134218782; // 删除表 SQL> drop table test.t2
1.3 视图
分类:简单视图、复杂视图、物化视图
注:简单视图和复杂视图不占用磁盘空间
-
创建视图
SQL> create view v1 as select * from dmhr.employee;
SQL> select * from v1 limit 2;
行号 EMPLOYEE_NAME JOB_ID
1 马学铭 11
2 程擎武 21
查看视图
SQL> select view_name,text from dba_views where view_name='V1';
行号 VIEW_NAME TEXT
---------- --------- -----------------------------------------------
1 V1 SELECT EMPLOYEE_NAME,JOB_ID FROM DMHR.EMPLOYEE
修改视图
SQL> create or replace view v1 as select employee_name from dmhr.employee;
SQL> select view_name,text from dba_views where view_name=‘V1’;
行号 VIEW_NAME TEXT
1 V1 SELECT EMPLOYEE_NAME FROM DMHR.EMPLOYEE
删除视图
SQL> drop view v1;
1.4 序列
-
创建序列
SQL> create sequence s1 2 start with 1 3 increment by 1 4 maxvalue 10 5 nocache 6 nocycle; -
序列的应用
SQL> create table test.t11(id int primary key);
SQL> insert into test.t11 values(s1.nextval);
SQL> insert into test.t11 values(s1.nextval);
SQL> select * from test.t11;
行号 ID
1 1
2 2
1.5 同义词
表或视图的别名,分为普通同义词(相当于私用同义词)和公共同义词(所有用户都可以使用,只有sysdba可以创建)
-
创建同义词
// 公共同义词 SQL> create public synonym ss1 for dmhr.employee; // 普通同义词 SQL> create synonym ss2 for dmhr.employee; -
修改同义词
SQL> create or replace synonym ss2 for dmhr.employee; -
删除同义词
SQL> drop public synonym ss1; SQL> drop synonym ss2;
1.6 索引
达梦的分类:二级索引,唯一索引,复合索引,函数索引,分区索引等
默认的表是索引组织表,利用rowid创建一个默认的索引,所以我们创建的索引是二级索引
-
查看索引
SQL> select table_name,index_name from dba_indexes where table_name='T11'; 行号 TABLE_NAME INDEX_NAME ---------- ---------- ------------- 1 T11 INDEX33555483 -
索引的作用
加快表的查询,对数据库做DML操作的时候,数据库会自动维护索引。索引是一棵倒置的树,使用索引,就是对这个索引树进行遍历。 建立索引的规则: 1、经常查询的列 2、连接条件列 3、谓词经常出现的列(where) 4、查询是返回表的一小部分数据 不适合创建索引的情况: 1、列上有大量的null 2、列上的数据有限(例如:性别) -
创建索引
// 1.规划索引表空间 // 2.表的数据是无须的,索引的数据是有序的 案例:复制dmhr.employee为emp,给employee_id建立所以
// 建立表
SQL> create table test.emp as select * from dmhr.employee;
// 建立表空间
SQL> create tablespace indx datafile ‘/dm7/data/DAMENG/indx01.dbf’ size 32;
// 建立索引
SQL> create index ind_mep on test.emp(employee_id) tablespace indx;
查询索引
SQL> select table_name,index_name from dba_indexes where table_name='EMP';
行号 TABLE_NAME INDEX_NAME
---------- ---------- -------------
1 EMP INDEX33555484
2 EMP IND_MEP
维护索引
// 重建索引
SQL> alter index ind_emp rebuild;
// 删除索引
SQL> drop index ind_emp;
2019.12.24 Link