Spark on Kubernetes PodTemplate 的配置
文章目录
- 1 Overview
- 2 PodTemplate
- 3 Example
- 4 Summary
1 Overview
本文主要讲 Apache Spark 在 on Kubernetes 的 PodTemplate 的问题,以及也会讲到 Spark Operator 里关于 PodTemplate 的问题,当然也会讲到 Apache Spark 2.2 on Kubernetes 那个 Fork 的版本,感兴趣的同学可以往下看看。
之前讲过 Apache Spark on Kubernetes 在配置 Pod 的时候的一些限制,比如针对 Pod 的调度,想加个 NodeSelector 或者 Tolerations。这在集群公用,或者有各种类型任务的集群里,是经常会遇到的情况,而在 Spark 2.x 里是很难做到的。
目前最新 Release 的版本 2.4.5 还没有支持通过 PodTemplate 来自定义 Pod 的配置,而社区的计划是在 Spark 3.0 的时候将这一 feature 完成,他支持的方式其实也比较简单,就是可以有一个 PodTemplate 的一个文件,去描述 Driver/Executor 的 metadata/spec 字段,这样当然就可以在模板文件里加入跟调度需要的一些字段了,
关于 PodTemplate 可以带来什么呢?比如说其实 Apache Spark 2.2 on Kubernetes 一开始是支持 initContainer 的,当时可以通过 spark.kubernetes.initcontainer.docker.image 来配置 Pod 的 initContainer 但是随着版本的演进,关于 initContainer 的代码已经去掉了,可以想象,如果只通过几个 SparkConf 来配置 initContainer 的话,这样限制实现太多了,SparkConf 的表达能力有限,如果都通过 spark.kubernetes.driver.label.* 这样的 SparkConf 来配置的话,既不灵活,也让 SparkConf 的配置数量急剧膨胀。
那么现在如果用户想通过 initContainer 做一些事情那可以怎么办?在 Spark 2.x 的版本里,应该是没有办法的,除非通过一些迂回的办法来实现原先你想通过 intContainer 达到的目标,比如说将一个文件提交下载到 Volume 并进行挂载这类操作,又或者直接去改下源码。
具体可以参考在 SPARK-24434 Support user-specified driver and executor pod templates 的相关讨论。不论 initContainer 的逻辑怎么样了,至少现在用户可以通过 PodTemplate 来自定义 Pod,当然包括定义需要的 initContainer,以及跟调度相关的一些字段。
2 PodTemplate
实际上,如果是在 Spark Operator 里,本身就支持 Pod Template 的配置 SparkPodSpec,也就是说,像 NodeSelector, Tolerations 之类的,可以在创建 CRD 对象的时候在 YAML 上添加上,比如下面的例子。
apiVersion: sparkoperator.k8s.io/v1beta2
kind: SparkApplication
metadata:
name: spark-pi
namespace: default
spec:
type: Scala
mode: cluster
image: gcr.io/spark/spark:v2.4.5
mainClass: org.apache.spark.examples.SparkPi
mainApplicationFile: local:///opt/spark/examples/jars/spark-examples_2.11-2.4.5.jar
nodeSelector:
key: value
所以之前的文章也有说过 Spark Operator 的配置上,会更加灵活。
而在 Apache Spark 3.0 中,PodTemplate 是需要在 spark-submit 阶段将模板文件加到 spark.kubernetes.driver.podTemplateFile 或者 spark.kubernetes.executor.podTemplateFile 里的。
大家都知道 Spark 在下载依赖文件的时候,可以通过 HTTP/HDFS/S3 等协议来下载需要的文件。但是读取 PodTemplate 的 API,目前只支持本地文件系统(当然要改成支持 http 也不是很复杂),SparkConf 的配置可能如下。
# template 在本地
spark.kubernetes.driver.podTemplateFile=/opt/spark/template.yaml
spark.kubernetes.executor.podTemplateFile=/opt/spark/template.yaml
关于 Apache Spark 3.0 是如何加载这些 PodTemplate 的文件,我们可以看看源码。在将 PodTemplate 文件加载到系统里的关键方法是是 KubernetesUtils.loadPodFromTemplate()。
def loadPodFromTemplate(
kubernetesClient: KubernetesClient,
templateFile: File,
containerName: Option[String]): SparkPod = {
try {
// 主要的还是利用 K8S 的客户端去 load 模板文件
// load 模板文件目前只能支持本地文件系统,因为底层调用的是 File 接口
val pod = kubernetesClient.pods().load(templateFile).get()
// 这里需要注意会从模板里把指定 Container 捞出来
// 目的主要是捞出来 Driver 和 Executor 容器
// 否则就是以第一个容器作为 Driver/Executor 的容器
selectSparkContainer(pod, containerName)
} catch {
case e: Exception =>
logError(
s"Encountered exception while attempting to load initial pod spec from file", e)
throw new SparkException("Could not load pod from template file.", e)
}
}
通过上述方法就可以利用 PodTemplate 来做一些 Pod 的定义了,避免了大量极其繁琐的 SparkConf 的配置。如果想在 Apache Spark 3.0 之前的版本去实现 NodeSelector/Toleration 这些操作,直接通过 SparkConf 是不行的。后面 Driver/Executor 的 Pod 构建就分别交给 KubernetesDriverBuilder 和 KubernetesExecutorBuilder 去做了。而在执行 spark-submit 的环境中,需要去读取 PodTemplate 文件,然后通过 ConfigMap 来挂载到 Driver/Executor Pod。当然了,我觉得这样还是不够灵活,因为 Executor 的 PodTemplate 也可以在 Spark 镜像里,不需要一定要在 spark-submit 的环境里,目前的做法,如果是使用本地文件的话,就必须在 spark-submit 的本地环境了,而我觉得没必要,不过我们还是可以改成通过 http 等方式,让本地可以读取到这些 PodTemplate 文件的,只是你还需要一个文件服务器去放这些 PodTemplate 的文件。
因为通过 PodTemplate 来引导定义的操作相对来说是比较前置的,所以有些属性,可能会被后面针对 Pod 的其他配置给 overwrite,在 Spark 的最新文档的 running-on-kubernetes,可以找到那些属性可能会被后置配置覆盖掉。
下面是关于 Spark Driver Pod 是怎么通过各种 Step 按顺序最后给构建出来的示意图。
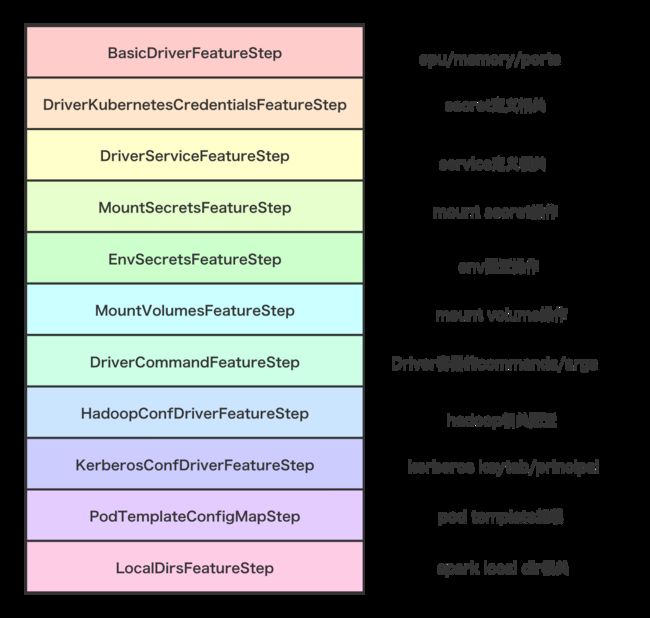
val features = Seq(
new BasicDriverFeatureStep(conf),
new DriverKubernetesCredentialsFeatureStep(conf),
new DriverServiceFeatureStep(conf),
new MountSecretsFeatureStep(conf),
new EnvSecretsFeatureStep(conf),
new MountVolumesFeatureStep(conf),
new DriverCommandFeatureStep(conf),
new HadoopConfDriverFeatureStep(conf),
new KerberosConfDriverFeatureStep(conf),
new PodTemplateConfigMapStep(conf),
new LocalDirsFeatureStep(conf))
val spec = KubernetesDriverSpec(
initialPod,
driverKubernetesResources = Seq.empty,
conf.sparkConf.getAll.toMap)
features.foldLeft(spec) { case (spec, feature) =>
val configuredPod = feature.configurePod(spec.pod)
val addedSystemProperties = feature.getAdditionalPodSystemProperties()
val addedResources = feature.getAdditionalKubernetesResources()
KubernetesDriverSpec(
configuredPod,
spec.driverKubernetesResources ++ addedResources,
spec.systemProperties ++ addedSystemProperties)
}
看完整个过程,可以发现,装配 Driver Pod 的步骤竟然如此复杂。这个设计也是延续了 Spark 2.2 on K8S 那个 Fork 的思路。
- 通过自定义镜像,将 PodTemplate 文件置入镜像的某个目录中,如
/opt/spark/template.yaml - 然后在 SparkConf 填入参数
spark.kubernetes.driver.podTemplateFile=/opt/spark/template/driver.yaml - 如果 Pod 里准备起其他容器,则需要在 SparkConf 指定 Driver Container 的名字,例如
spark.kubernetes.driver.podTemplateContainerName=driver-container
3 Example
下面给出一个例子,来给 Spark 的 Drvier/Executor 都加一个 initContainer,将 PodTemplate 文件 template-init.yaml 放在 /opt/spark 目录下,下面是 PodTemplate 的具体内容,就是加一个会 sleep 1s 的 initContainer。
apiversion: v1
kind: Pod
spec:
initContainers:
- name: init-s3
image: hub.oa.com/runzhliu/busybox:latest
command: ['sh', '-c', 'sleep 1']
SparkConf 需要加上
spark.kubernetes.driver.podTemplateFile=/opt/spark/template-init.yaml
spark.kubernetes.executor.podTemplateFile=/opt/spark/template-init.yaml
运行一个 SparkPi 的例子,spark-submit 命令如下。
/opt/spark/bin/spark-submit
--deploy-mode=cluster
--class org.apache.spark.examples.SparkPi
--master=k8s://https://172.17.0.1:443
--conf spark.kubernetes.namespace=demo
--conf spark.kubernetes.driver.container.image=hub.oa.com/public/spark:v3.0.0-template
--conf spark.kubernetes.executor.container.image=hub.oa.com/public/spark:v3.0.0-template
--conf=spark.driver.cores=1
--conf=spark.driver.memory=4096M
--conf=spark.executor.cores=1
--conf=spark.executor.memory=4096M
--conf=spark.executor.instances=2
--conf spark.kubernetes.driver.podTemplateFile=/opt/spark/template-init.yaml
--conf spark.kubernetes.executor.podTemplateFile=/opt/spark/template-init.yaml
--conf=spark.kubernetes.executor.deleteOnTermination=false
local:///opt/spark/examples/jars/spark-examples_2.12-3.0.0-SNAPSHOT.jar
100
运行结束,查看一下 Driver Pod 的 YAML 文件,发现 initContainer 已经加上,并且运行正常。
...
initContainers:
- command:
- sh
- -c
- sleep 1
image: hub.oa.com/runzhliu/busybox:latest
imagePullPolicy: Always
name: init
resources: {}
...
initContainerStatuses:
- containerID: docker://526049a9a78c4b29d4e4f7b5fcc89935d44c0605bcbf427456c7d7bdf39a6172
image: hub.oa.com/runzhliu/busybox:latest
lastState: {}
name: init
ready: true
restartCount: 0
state:
terminated:
containerID: docker://526049a9a78c4b29d4e4f7b5fcc89935d44c0605bcbf427456c7d7bdf39a6172
exitCode: 0
finishedAt: "2020-04-02T00:03:35Z"
reason: Completed
startedAt: "2020-04-02T00:03:34Z"
PodTemplate 文件里,有几个事情需要注意一下的,就是大小写要符合 Kubernetes 的规范,比如 Pod 不能写成 pod,initContainer 不能写成 initcontainer,否则是不生效的。
4 Summary
Apache Spark 3.0 支持 PodTemplate,所以用户在配置 Driver/Executor 的 Pod 的时候,会更加灵活,但是 Spark 本身是不会校验 PodTemplate 的正确性的,所以这也给调试带来了很多麻烦。关于 NodeSelector, Taints, Tolerations 等,这些字段在 Spark Operator 中设置,倒是比较方便的。