python自动化脚本常用方法小结
- API测试
1.框架常用模块
#unittest单元测试框架不仅可以适用于单元测试,还可以适用WEB自动化测试用例的开发与执行
#paramunittest是unittest实现参数化的一个专门的模块,可以传入多组参数,自动生成多个用例
#codecs专门用作编码转换
#configparser.ConfigParser 读取配置文件
#xlrd 读取excel信息
#threading 创建线程模块
#xml.etree.ElementTree 处理 XML 文档
#requests是python实现的简单易用的HTTP库
2.装饰器
@property 可以对应于某个方法, 希望能够像调用属性一样来调用方法
如果一个方法前面加了了装饰器,调用可以直接得到return的结果,并直接调用获得结果后的属性
@staticmethod 声明是一个静态方法
3.接口常用参数
content-type:请求响应的类型
form表单:application/x-www-form-urlencoded ;
json: application/json:
Token: ①:防止表单重复提交 ②:用来作身份验证
(1)客户端使用用户名跟密码请求登录;服务端收到请求,去验证用户名与密码
验证成功后,服务端会签发一个 Token,再把这个 Token 发送给客户端
(2)客户端收到Token后可以把它存储在 Cookie 里或者 Local Storage 里
(3)客户端之后向服务端请求资源的时候会带着服务端签发的 Token,服务端收到请求,然后去验证客户端请求里面带着的 Token,如果验证成功,就向客户端返回请求的数据,从而实现免密登录
User-Agent(UA 用户代理):当前操作系统和浏览器内核版本
4.Requests
请求:response = requests.post(url,headers,data, file,timeout)
解析json数据: response.json()
解析xml数据: from lxml import etree
page = etree.HTML(response .text)
对解析后的xml定位: page.xpath(xpath_str)
获取状态码: response.status_code
会话维持: ses= requests.Session()
res= ses.get(url,headers,data, file,timeout)
- 常用python知识点
1.类的常用调用

(1)在testloginxls中调用config类
初始化类对象 readconfig = config.config()
2.常用路径调用方法
#os.path.realpath(__file__)获取当前执行脚本的绝对路径
#os.path.split 按照路径将文件名和路径分割开(分割左边为目录路径,右边为文件名或空)
#os.path.join连接两个或多个路径,,如果连接路径不含/,则函数会自动加上
#os.path.dirname(path)接路径,返回目录所在目录
#os.path.abspath() 接路径,获取绝对路径目录
#os.getcwd() 获取当前绝对路径目录
os.path.dirname(os.path.dirname(os.path.dirname(__file__)))
3.打开文件方法
r 只读
r+ 读写(存在文件)
w 写入(存在文件时更新文件,原数据会不见;文件不存在,新建文件)
a 打开文件进行追加
wb+ 二进制读写
foo=open(R'D:\123.txt',mode='r+',encoding='utf-8',buffering=1)
读:read() readline() readlines()
- 先open,再read 即 foo.read()
- ConfigParser()打开 ,configparser.ConfigParser().read(ini文件)
写: foo.write()
关闭文件: foo.close()
重命名: os.rename(原文件名,现文件名)
删除文件: os.remove(文件名)
最常用的打开方法with: with open('sample.txt') as fp
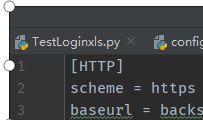
读取config文件
self.cf=configparser.ConfigParser()
self.cf.read()
self.cf.get("HTTP",scheme)
在congfig中写
self.cf.set("HTTP", name, value) http下回加上一行 name=value
4.Xlrd(表格)常用方法
workbook= xlrd.open_workbook(filename)# 打开xlsx表格文件
Sheet=workbook.sheet_by_name(sheet_name)#通过名称获取xlsx
nrows = Sheet.nrows #获取该sheet中的有效行数
ncols=Sheet.ncols #获取该sheet中的有效列数
row_values=Sheet.row_values #获取所有某一行数据组成的列表
col_value=Sheet.col_values #获取所有某一行数据组成的列表
5.Datetime和time
(1)datetime.datetime.now() 返回当前本地时间,
strftime() 将格式字符串转化为自定义格式
datetime.now().strftime("%Y%m%d%H%M%S")
(2)localtime() 格式化时间戳,如未添加任何时间,显示当前时间
strftime() 将格式字符串转化为自定义格式
time.strftime('%Y.%m.%d %H:%M:%S',time.localtime())
6.文件不存在创建
if not os.path.exists(resultPath):
os.mkdir(resultPath)
7.获取xml方法
import xml.etree.ElementTree as ET
解析后的xml文件内容
- tree=ET.ElementTree(file=filepath)
- tree=ET.parse(filepath)
获取某一tag的迭代器
(1)findall(match) #返回所有匹配的子元素列表,可以匹配tag或路径
(2)iter(tag=None) #以当前元素为根节点,创建树迭代器如果tag不为None,则以tag进行过滤
获取某一tag属性
例:for u in tree.findall('url') 获取标签数据
attrib 为包含元素属性的字典 v=u.attrib['name']
items() 返回(name,value)列表
get(key, default=None) 获取属性 v=u.get('name')
获取tag下所有子标签
getchildren 方法按照文档顺序返回所有子标签
例: url_list=[]
for c in u.getchildren() 获取子标签数据
url_list.append(c.text) 用c.text获取子标签内容,并存储于列表
8.常用正则表达式
() 分组,用列表返回值 , []中的一个或者多个字符被称为字符类,存放多个匹配值
{} 大括号代表重复数量,[a-z]{1,2}代表一到二个字母,这两个字母都在a到z的范围内
| 匹配两项之间的字符(and),用于查找多个不同值
\d 匹配一个Unicode数字 ,\D 匹配Unicode非数字
\s 匹配Unicode空白, \S 匹配Unicode非空白
\w 匹配Unicode单词字符, \W 匹配Unicode非单词字符
? 匹配前面的字符0次或1次,
+ 匹配前面的字符1次以上, * 匹配前面的字符任意次(包含0)
{m,n} 匹配前面的正则表达式至少m次,最多n次
#以第一个字符为;,空格,结尾为任意个空格的内容为分割条件
re.split(r'[;,\s]\s*', str) #切割
re.sub(正则,替换字符,字符串) #替换匹配项
re.findall(正则,字符串) #遍历匹配,会返回列表
fnmatch.fnmatch(str,’’正则) #检查字符串是否存在