《java面试宝典》四 一文了解ArrayList源码及扩容
目录
前言:
每日一面:
1.ArrayList简介?
2.ArrayList源码分析
2.1 ArrayList底层是数组,为什么可以无限存放数据?
无参构造方法:
有参构造方法:
Get方法:
add插入方法
Remove方法
前言
社长,一个爱学习,爱分享的程序猿,始终相信,付出总会有回报的。知识改变命运,学习成就未来。爱拼才会赢!
程序猿学社的GitHub,已整理成相关技术专刊,欢迎Star:。
https://github.com/ITfqyd/cxyxs
社长,4年api搬运工程师,之前做的都是一些框架的搬运工作,做的时间越长,越发感觉自己技术越菜,有同感的社友,可以在下方留言。现侧重于java底层学习和算法结构学习,希望自己能改变这种现状。
为什么大厂面试,更侧重于java原理底层的提问,因为通过底层的提问,他能看出一个人的学习能力,看看这个人的可培养潜力。随着springboot的流行,大部分的开发,起步就是springboot。也不看看springboot为什么简单?他底层是如何实现的。为什么同样出来4年,工资差别都很大?这些问题都值得我们深思(对社长自己说的)。
api工程师,顶天了,最多达到某些公司中级工资上限,很难突破高级这道坎。希望我们大家成就更好的自己。回想起往事,不会后悔。
每日一面:
面试官隔壁小王:说说一个ArrayList为什么可以无限插入数据,他底层是如何实现的?
社长:心想,幸好我之前有了解过,ArrayList,知道他是如何扩容的。在jdk8中,Array默认开辟的长度是10。下一次需要扩容的长度=长度+长度>>1。
面试官隔壁小王:不错。
后面进行各种切磋,最后社长还是没有通过面试。

随着18年各个大厂人员的不断变动,最近两年有过面试经历的朋友,应该深有感触,会发现面试越来越难。这就要求我们对底层的基础,得越来越扎实。如果你现在正在面试中级,可以深入学习一下底层。而不是停用在简单的使用阶段,应该像小时候一样的纯真,多问问一万个为什么。抱着砸破锅问到底的心思,这样,你必比别人多一些优势。面试的优势,就是这样一点一点的积累起来的。
1.ArrayList简介?
ArrayList底层是通过数组的方式来存储的。
特点:
查询效率高,增删效率低,线程不安全,多线程过程中,需要根据某些业务场景,合理使用,一般都是使用的ArrayList。如果想要线程安全就用vector,但是一定要记住,不可能要求性能高,又要安全,这是不可能的,只能两者取其一。
因为ArrayList是基于索引(index)的数据结构,它使用索引在数组中搜索和读取数据是很快的。ArrayList获取数据的时间复杂度是O(1),但是要删除数据却是开销很大的,因为这需要重排数组中的所有数据。
通过图,我们了解一下ArrayList的删除,实现的方式。假如需要删除B,CDE都要移动,如果数据量很大,删除的效率能高到哪里去。新增类似

举一个简单的例子,让我们理解一下,ArrayList的查询数据为什么快,例如我们LinkList链表存储方式,只知道上一个和下一个的位置。换到现场场景。假设。我们去一点点喝奶茶,我们是不是要排队,假设我们要找3号,我们想都不用想,直接跑到第五个位置,类似于ArrayList。假设都不排长队,在一片不算小的区域内,大家都只知道上一个的编号,和下一个人的编号。我们需要找3号,是不是只能先找到1号,再通过1号找到2号,通过2号再找到3号,类似于链表结构。
2.ArrayList源码分析

通过这段代码,我们可以知道ArrayList,底层是通过数组的方式实现的。而arrayList为什么可以存放各种类型,实际上就是这个的数据类型是object决定的。
咦,有一些好奇宝宝,可能会问,transient是什么?我怎么从来没有见过。
有些时候像银行卡号这些字段是不希望在网络上传输的,transient的作用就是把这个字段的生命周期仅存于调用者的内存中而不会写到磁盘里持久化。具体情况,根据业务具体设计。
2.1 ArrayList底层是数组,为什么可以无限存放数据?
大家都知道数组的长度是有限的,而ArrayList底层就是通过数组的方式实现,难怪我们不觉得奇怪。他是如何实现自动扩容的。

实际上,ArrayList的扩容,就是在原来的基础上重新创建一个新的,更大的数组,在jdk1.8中数组的长度默认是10,下次扩容的长度为老数组长度+(老数组长度>>1),先给大家说说“>>1”,实际上就是右移一位,这样老数组的长度就为10+10/2=15。大家可以记住一个口诀。左移乘,右移除,值为对应2的n次方,n表示移动的位数。
2.1.1ArrayList的构造方法
Idea中输入快捷键Alt+7 查看类中所有方法
无参构造方法:

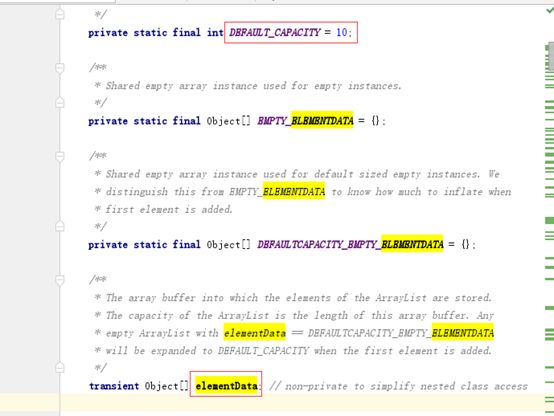
实际上,就是创建一个空的数组,注意,默认长度为10
有参构造方法:

通过这段代码可以看出看出,如果传过来的长度大于0,创建指定长度的数组,如果为0,则创建默认长度为10的数组。小于0,则报错。我们项目过程中,经常遇到一些类似于Illegal Capacity的异常。如果你对底层熟悉,一看到这种报错,就知道是什么原因造成的。你现在还觉得底层源码分析,没有用吗?
2.1.1.1 Get方法:


首先先检查索引下标,不是在对应的区间内,如果当前的索引大于实际上长度,则提示IndexOutOfBoundsException,看到这个报错是不是又觉得很熟悉。所以不要觉得看源码,看不懂,慢慢来,遇到一些不熟悉的,百度查查一些用法。注意:不用全部了解,知道一个大概就行,主要是理解他的一个思想。
2.1.2 add插入方法

ensureCapacityInternal看名称就知道是确保容量够不够,我们再来看看他做了什么工作

注意:重点来了,grow方法
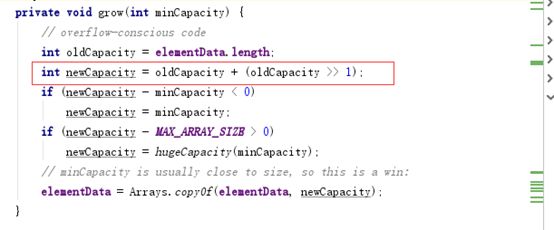
默认容量是10,假设,已经满了,需要开始扩容。新的长度=10+5=15
Arrays.copyOf就是把数组完美的copy。所以,扩容的一个主要思想,就是创建一个新的数组,把老数组的值移植过去。再赋值给老数组。
注意:jdk 1.6左右的版本,这里扩容的算法不是右移。从1.7左右就改成右移方式。做了一定的优化。老算法长度=(老数组长度*3)/2+1 假设数据长度为10,老算法长度为16。具体为什么换成位这种算法,还没有搞明白?
Remove方法
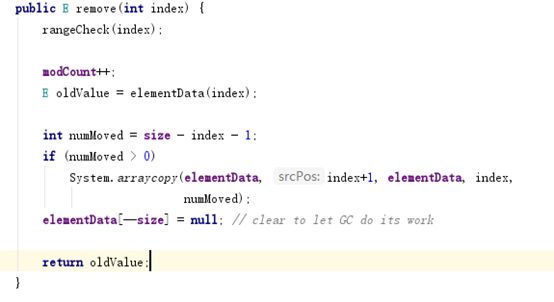
下面说说删除的逻辑。假设有4个数
我们想要删除索引为1的值.3和4都需要向前移动一个位置,假设我们的数组很大,每一个都需要移动位置,就这种方式,就觉得删除的性能高不到哪里去。
当然arrayList还有很多的方法,我这里只是想告诉他们,查看源码没有我们想象中的难。
后记
程序猿学社的GitHub,欢迎Star:
https://github.com/ITfqyd/cxyxs
觉得有用,可以点赞,关注,评论,留言四连发。