python爬虫scrapy框架入坑(二):初试Scrapy
主要参考的网上文章:1、https://www.cnblogs.com/Infi-chu/p/8999851.html
2、https://www.jianshu.com/p/99eb3b693653
本文博主还是使用的PyCharm Terminal 运行的命令,直接使用cmd也是可以的
项目创建:
scrapy startproject 项目名
本文项目名为:ivenspider,生成项目结构如下(红圈中的内容):
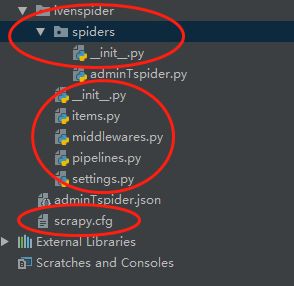
scrapy.cfg:项目的配置文件
items.py:定义了Item数据结构,所有Item的定义都可以放在这里Items是用来加载爬取内容的容器,和Python中的字典有些相似,同时提供额外的功能)
pipelines.py:定义了Item Pipeline的实现
settings.py:定义了项目的全局配置
middlewares.py:定义了spider 中间件和downloader中间件
spiders:每一个爬虫的实现,每一个爬虫对应一个文件
Items是用来加载爬取内容的容器,和Python中的字典有些相似,同时提供额外的功能
创建爬虫:
scrapy genspider spider名称 网站域名 (本文命令:crapy genspider adminTspider quotes.toscrape.com)
创建后会生成一个包含文件名的spider类,其中有三个属性和一个方法
三个属性:
name 每个项目唯一的名字
allow_domains 允许爬取的域名
start_urls 在启动时爬取的URL列表
一个方法:
parse() 默认情况下,被调用start_urls里面的链接 构成的请求完成下载执行后,返回的响应就会作为唯一的参数
传递给这个函数。这个方法是负责解析返回的响应、提取数据或进一步生成要处理的请求
分析并获取所需内容Scrapy Selectors
Selectors 支持一下四种方式
- xpath(): 返回一个selector列表,每一项表示一个 xpath 参数表达式选择的节点
- css(): 返回一个selector列表,每一项表示一个 css 参数表达式选择的节点
- extract(): 返回一个字符串列表,为使用正则表达式抓取出来的内容
- re(): 返回一个字符串列表,为使用正则表达式抓取出来的内容
class AdmintspiderSpider(scrapy.Spider):
name = 'adminTspider'
allowed_domains = ['quotes.toscrape.com']
start_urls = ['http://quotes.toscrape.com/page/1/']
def parse(self, response):
for quote in response.xpath('//div[@class="quote"]'):
item = QuoteItem()
item['text'] = quote.xpath('span[@class="text"]/text()').extract_first()
item['auth'] = quote.xpath('span/small/text()').extract_first()
yield item
Scrapy为每个url建立scrapy.Request对象
执行每个requests
将返回的response对象当作参数传给parse()方法。
parse():
取每一个class为quote的div,遍历
在div中取class为text和author的span的正文。
extract_first(): 返回selector列表的第一项。
QuoteItem为资定义的目标文件
class QuoteItem(scrapy.Item):
text = scrapy.Field()
auth = scrapy.Field()
执行爬虫:
在项目根目录下执行 scrapy crawl adminTspider
保存到文件quotes.json
scrapy crawl adminTspider -o quotes.json
利用scrapy crawl命令执行爬虫时,数据输出到文件时会保存原始的编码,比如中文会保存为\uXXXX格式。
如果想保存中文字符串,需要在添加参数:-s FEED_EXPORT_ENCODING=utf-8
scrapy crawl adminTspider -o quotes.json -s FEED_EXPORT_ENCODING=utf-8
使用管道pipelines
如果想存入到数据库或筛选有用的Item,此时需要用到我们自己定义的Item Pipeline
我们一般使用Item Pipeline做如下操作
清理HTML数据
验证爬取数据,检查爬取字段
查重并丢弃重复内容
将爬取结果保存到数据库
settings.py 添加配置
ITEM_PIPELINES = {
'ivenspider.pipelines.IvenspiderPipeline': 300,
}
指定用来处理数据的 Pipeline 类,后面的数字代表执行顺序,取值范围是 0-1000 range.
数值小的 Pipeline 类优先执行
import json
import codecs
class IvenspiderPipeline(object):
def __init__(self):
self.file = codecs.open('adminTspider.json', 'wb', encoding='utf-8')
def process_item(self, item, spider):
proxys = {'text': item['text'], 'auth': item['auth']}
line = json.dumps(dict(proxys),ensure_ascii=False) + "\n"
self.file.write(line)
return item
def close_spider(self, spider):
self.file.close()
Pipeline 类会在 process_item 方法中处理数据,然后在结束时调用 close_spider 方法,因此我们
需要自定义这两个方法做相应的处理。
- 在 process_item() 方法处理完成后要返回 item 供后面的 Pipeline 类继续操作
- 记得在 close_spider() 中释放资源
使用Pipeline 存储数据,爬虫启动命令为scrapy crawl quotes