深入理解Binder机制
文章目录
- Binder概述
- 组成
- ServiceManager
- java层proxy
- native层Proxy
- ServiceManager服务进程
- ProcessState与IPCThreadState
- 成为binder进程
- 管理BpBinder
- 开启binder主线程
- transact到onTransact
- Binder驱动
- 驱动加载
- 进程初始化过程
- binder_open
- binder_mmap
- 数据的跨进程传输
- 杂项命令的处理
- BINDER_WRITE_READ
- BC_TRANSACTION-发起跨进程通信
- 目标线程唤醒后的处理
- BC_REPLY-目标线程返回处理结果
- binder_ref与binder_node的因缘
- 后记
Binder概述
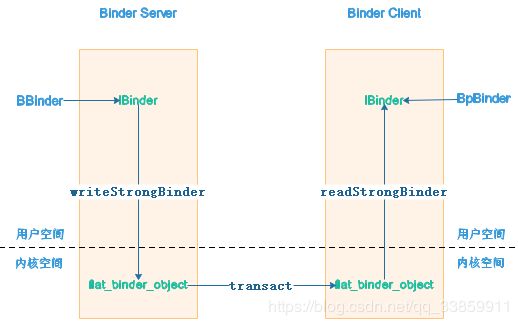
Binder其前身是由Be Inc.和Palm,Inc.开发的OpenBinder,而后Google将其带入Android系统作为主要的跨进程通信技术使用。Binder之所以能被Google青睐跟其优越的传输性能及安全性能是分不开的。在传输性能上,传统的linux系统IPC如Socket、管道、消息队列等在跨进程传输时数据会被拷贝2次,而Binder则只需一次拷贝就完成数据在client到server之间的传递。在安全性方面,传统IPC在数据传输期间的安全性依赖于上层协议确保,给了非法调用可乘之机,而Binder机制则从底层即内核态就确保传输者身份的安全和数据的精确传递。
从linux体系架构来看,代码在cpu中的运行区分为用户态和内核态(用户空间和内核空间),处于内核态运行的代码拥有最高的cpu特权级R0,这意味着此刻进程可以操控系统中的核心资源如I/O、外围设备、内存、时钟等,一般而言,上层应用程序都运行在用户态,是没有权力去操控这些核心资源的,而基于某些需要应用程序又需要获取操作系统核心资源的能力,此时就需要通过系统调用(system call)临时切换到内核态来操作核心资源。
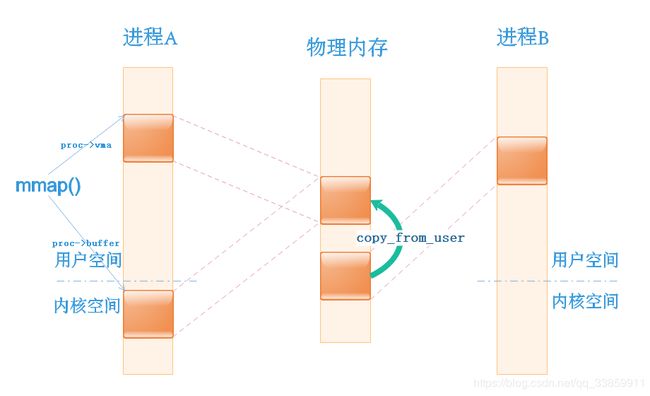
Android系统既然是由linux衍生而来,也遵循linux在内存管理方面的原则。出于进程安全的考虑,各个进程在用户空间层面上是非共享的,也就是说,A进程的虚拟地址(或者说地址指针)对于B进程来说毫无意义,这也就杜绝了进程间相互串改攻击的可能。而内核空间是可共享的,就为进程间通信提供了可能。

在上图中如果进程A想要和进程B进行通信,则进程A需要先把数据从进程A的用户空间通过系统调用的方式转到进程A的内核空间,而内核空间中的地址是共享的,进程B很容易就可得到进程A转到内核空间的数据,从而把数据转给进程B的用户空间,这样就完成了一次进程间通信。然而实际中的进程间的通信则更为复杂,不仅要考虑多进程间通信时如果能够精确定位目标进程/线程,还包括通信性能消耗、通信双方如何唤醒对方处理数据等,这部分须由运行在内核空间的程序来统一管理。当然,仅从以上图示中来看是无法印证篇首提到的binder一次拷贝就完成数据在进程间的传输的(如果仅通过system call,A用户空间->A内核空间==B内核空间->B用户空间这个过程至少有两次数据拷贝,在后边会对这一细节进行说明)。
在Android中,我们常说的Binder机制就类似于将进程A与B的通信过程具体化、规范化。当然,实际的系统中进程数量多得多,而binder的使用更不在少数,例如启动一个Activity,就需要同AMS、WMS等进行通信并经由surfaceflinger创建surface,最终在这些不同进程间相互配合下contentView才得以显示在屏幕上,这个过程就涉及到binder机制的使用。得益于其良好的封装,我们甚至无感知这期间发生了进程间的通信就可达到目标,这也是binder粘合剂这个名称的由来,它向上层应用程序屏蔽掉了进程间通信的繁杂过程,弱化了进程的概念,从而使开发者专注于业务处理,简化开发流程。
Binder机制在通信架构上采用了C/S的方式,server进程提供某项服务,而client进程需要使用这项服务。server为了client进程能够使用这项服务而在client进程提供了proxy代理,通过proxy代理client就能把需求传给server进行处理并返回处理结果。然而,不管应用上层的模式如何炫酷,从底层而言都绕不开内核空间来进行数据/信息共享才能达到进程间通信这一目的。即便从内核空间可以进行通信,也有两个棘手问题需要解决:一.如何精确制导找到目标服务所在进程?二.通信双方的数据协议如何定义?为了精确制导,server进程本身与server在client的proxy都经过了一定程度的包装,对于server进程本身而言,其在应用上层被包装成BBinder,在其内核空间被包装成binder_node;而对于server在client端的proxy来说,其在client的用户空间被包装成BpBinder,在client内核空间被包装成binder_ref。而制导就是通过内核空间中client的binder_ref与server的binder_node建立关联来完成的。在数据具体的传输上,binder机制的通信双方在应用上层采用Parcel作为封装,Parcel具有数据无关性的特点,只要C/S两端读写顺序要一致就可还原数据,而数据在内核空间的传输上则进一步封装为binder_write_read乃至binder_transaction_data。

组成
从组件角度来看,Binder机制共分为以下四个职责各不相同的组成部分:
- Binder Client
- Binder Server
- ServiceManager
- Binder驱动
这些组成部分原理上与同样基于C/S架构的TCP/IP互联网络其实有诸多相似之处。就我们使用浏览器登录百度进行搜索的过程来说,浏览器就相当于客户端,而百度远程后台就相当于服务端,学过计算机的朋友都知道,每台联网的计算机都需要分配不同ip地址来标识自己,但为什么我们登录百度却从不需要记住它的ip地址(事实上,因为ip地址动态分配,我们记住了也不一定有用)而仅需记住百度的域名就可以呢?这其实是因为DNS域名服务器帮我们管理了域名与ip地址之间的映射关系,我们只需要把域名报给DNS,而当DNS返回对应ip地址后浏览器就可自动连接此ip地址对应的计算机了。类比binder来说,就如同以下:
- Binder Client <—> 浏览器
- Binder Server <—> 服务器
- ServiceManager <—> DNS服务器
- Binder驱动 <—> 路由器
在client与server通信过程发生之前,Binder Server需要把自身的name(对应域名)与handle(对应ip地址)作为一组映射关系注册到ServiceManager(对应DNS服务器)中,然后Binder Client就可以通过name(域名)获取到Binder Server的handle(ip地址),进而与Binder Server完成接下来的通信。当然,在当前client进程与server进程首次通信之后,只要通信双方没有death(是否death,binder有对应的death recipient技术保证),后续的通信可以通过临时保存在client进程的server引用binder_ref进行而非每次通信都需要通过DNS获取目标进程的handle(ip地址)。要让Binder机制如同互联网络一样正常作用,还有一个关键,即ServiceManager(DNS域名服务器)必须有一个系统(全网)皆知的固定handle(ip地址),这个handle(ip地址)就是0,而且ServiceManager必须在整个系统使用binder进行进程间通信之前就准备好。
ServiceManager
java层proxy
在Android应用开发中,只要拥有Context,我们就可借助其启动一个新的Activity(startActivity)或者获取系统服务(getSystemService),但是Context的继承类ContextWrapper却只是一个委托类,其真正的实现是ContextImpl,而在ContextImpl中我们发现startActivity()中间通过Instrumentation类的execStartActivity()最终调用了ActivityManagerNative.getDefault().startActivity()方法。在ActivityManagerNative我们发现是通过ServiceManager.getService(name)获取activity服务进程的binder。
// frameworks/base/core/java/android/app/ActivityManagerNative.java
private static final Singleton<IActivityManager> gDefault = new Singleton<IActivityManager>() {
protected IActivityManager create() {
IBinder b = ServiceManager.getService("activity");
if (false) {
Log.v("ActivityManager", "default service binder = " + b);
}
IActivityManager am = asInterface(b);
if (false) {
Log.v("ActivityManager", "default service = " + am);
}
return am;
}
};
static public IActivityManager getDefault() {
return gDefault.get();
}
同样的,我们接着看ContextImpl的getSystemService(name)方法,会发现是从一个HashMap中获取的系统服务。
// frameworks/base/core/ava/android/app/ContextImpl.java
@Override
public Object getSystemService(String name) {
ServiceFetcher fetcher = SYSTEM_SERVICE_MAP.get(name);
return fetcher == null ? null : fetcher.getService(this);
}
而这个SYSTEM_SERVICE_MAP中的系统服务是在ContextImpl类加载时被放入map中的,在下边我们节选了几个有代表性的。
// frameworks/base/core/ava/android/app/ContextImpl.java
static {
//...
registerService(CONNECTIVITY_SERVICE, new ServiceFetcher() {
public Object createService(ContextImpl ctx) {
IBinder b = ServiceManager.getService(CONNECTIVITY_SERVICE);
return new ConnectivityManager(IConnectivityManager.Stub.asInterface(b));
}});
//...
registerService(LOCATION_SERVICE, new ServiceFetcher() {
public Object createService(ContextImpl ctx) {
IBinder b = ServiceManager.getService(LOCATION_SERVICE);
return new LocationManager(ctx, ILocationManager.Stub.asInterface(b));
}});
//...
}
在贴出了几段在日常开发中常用的代码段之后,我们可以发现在不知不觉中我们已经使用了Binder机制,其中都有通过ServiceManager.getService()获取Binder Server服务。而在上边组成部分我们已经说过,ServiceManager类比于互联网络中的DNS,负责管理Binder Server(服务器)的映射关系,上述的ServiceManager.getService()正是ServiceManager提供给Binder Client使用的接口之一,作用是通过告知ServiceManager我们Client需要获取服务的name以便ServiceManager根据其name与service(handle)的映射关系返回给Binder Client正确的Service(handle)。当然,犹衣服之有冠冕,木水之有本原,我们ServiceManager中的服务也并非凭空出现,多数的Service是在SystemServer的run方法中通过调用ServiceManager.addService()添加进去的,这里我们就不贴具体代码了,读者可自行查阅。
前边提到过,Binder机制是基于C/S架构,而此处的ServiceManager也不能跳脱,ServiceManager本身其实就是一个Binder Server,与普通Binder Server不同的是,ServiceManager负责管理系统中的Binder Server(实名server),既然如此,其也遵循着Binder机制基本规则。仅从java层来看,要想使用binder机制进行进程间通信,类结构一般类似以下关系:

在图示中,AIDL生成的binder与系统中binder从类结构来看有些许不同,但是原理上都是一致的(本质上来看,我们的server使用aidl构建binder也是需要写一个类继承Stub),ADIL或系统服务的类结构图的左半部分一般需由Binder Server重写,右半部分一般由Binder Client重写。图示中有两个细节需要注意:1.不管是Binder Server端还是Binder Client端,如果双方进程需要通信,那么应该遵循同样一份契约(类似两者之间的说明书)IXXXX;2.右半部分的Proxy代理的内部肯定拥有某种向Binder Server报告Binder Client端具体需求的能力。
既然ServiceManager也是Binder Server,那么它必须和使用它的Binder Client遵循同样一份契约,这就是IServiceManager接口。它的内容如下:
public interface IServiceManager extends IInterface
{
public IBinder getService(String name) throws RemoteException;
public IBinder checkService(String name) throws RemoteException;
public void addService(String name, IBinder service, boolean allowIsolated) throws RemoteException;
public String[] listServices() throws RemoteException;
public void setPermissionController(IPermissionController controller) throws RemoteException;
static final String descriptor = "android.os.IServiceManager";
int GET_SERVICE_TRANSACTION = IBinder.FIRST_CALL_TRANSACTION;//1
int CHECK_SERVICE_TRANSACTION = IBinder.FIRST_CALL_TRANSACTION+1;//2
int ADD_SERVICE_TRANSACTION = IBinder.FIRST_CALL_TRANSACTION+2;//3
int LIST_SERVICES_TRANSACTION = IBinder.FIRST_CALL_TRANSACTION+3;//4
int CHECK_SERVICES_TRANSACTION = IBinder.FIRST_CALL_TRANSACTION+4;//5
int SET_PERMISSION_CONTROLLER_TRANSACTION = IBinder.FIRST_CALL_TRANSACTION+5;//6
}
在以上接口方法中,getService()与addService()使用较为频繁,从方法具体含义来看,就是增删在ServiceManager中保存的Binder Server引用(其实只是Binder Server的handle值)的过程。那IServiceManager中的几个常量XXX_TRANSATION又有什么作用呢?从内核空间来看,即使在Client端这些接口方法(契约)的调用地址可以在内核空间完成从Binder Client到Binder Server的传递,那Binder Server或binder驱动也难以将这些地址与Server端对应的接口方法调用地址对应起来,而且也不满足binder机制的扩展性需求。所以一个好的办法就是Binder Client与Binder Server协商好各个接口方法的业务码,当Binder Client调用接口时,只需要告诉Binder Server该方法对应的业务码就行,即使复杂一点,如果方法带有参数,那么依旧可以把这些参数按照顺序打包在一起给Binder Server,这样一来,Binder Server很容易就知道Binder Client具体调用的方法及参数,从逻辑与实现难度上来说比前者好上不少,而这个业务码就是上边的XXX_TRANSATION。与系统服务需要自己定义各个接口的业务码不同的是,我们通常使用的AIDL生成的方式会自动帮我们生成各个接口业务码及参数的打包/解压顺序。同样的,IServiceManager中的descriptor也有其具体作用,当我们Binder Client与Binder Server进行通信时,需要把descriptor传入具体通信数据中,Binder Server需要拿传过来的descriptor校验当前通信,其作用上类似于访问服务器所需要的token。
回到本节最开始的话题,Binder Client通过ServiceManager.addService()和ServiceManager.getService()就可以和ServiceManager进程进行通信,显然的,我们需要进入ServiceManager.java中一探究竟,部分代码如下,不难发现ServiceManager.java中并无实质内容,其所有的接口方法都转给ServiceManagerNative来处理了。
// frameworks/base/core/java/android/os/ServiceManager.java
public final class ServiceManager {
private static IServiceManager sServiceManager;
private static HashMap<String, IBinder> sCache = new HashMap<String, IBinder>();
private static IServiceManager getIServiceManager() {
if (sServiceManager != null) {
return sServiceManager;
}
sServiceManager = ServiceManagerNative.asInterface(BinderInternal.getContextObject());
return sServiceManager;
}
public static IBinder getService(String name) {
try {
IBinder service = sCache.get(name);
if (service != null) {
return service;
} else {
return getIServiceManager().getService(name);
}
} catch (RemoteException e) {
Log.e(TAG, "error in getService", e);
}
return null;
}
public static void addService(String name, IBinder service) {
try {
getIServiceManager().addService(name, service, false);
} catch (RemoteException e) {
Log.e(TAG, "error in addService", e);
}
}
//...
}
看到ServiceManagerNative,隐隐然我们会回想到上边出现的java层binder类结构图示,认为就是我们ServiceManager进程。先不慌,我们接着看它的asInterface()方法。
// rameworks/base/core/java/android/os/ServiceManagerNative.java
public abstract class ServiceManagerNative extends Binder implements IServiceManager
{
static public IServiceManager asInterface(IBinder obj)
{
if (obj == null) {
return null;
}
IServiceManager in =
(IServiceManager)obj.queryLocalInterface(descriptor);
if (in != null) {
return in;
}
return new ServiceManagerProxy(obj);
}
//...
class ServiceManagerProxy implements IServiceManager {
public ServiceManagerProxy(IBinder remote) {
mRemote = remote;
}
//...
}
//...
}
显而易见,ServiceManagerNative.asInterface()方法是Binder Client进程获取ServiceManagerProxy的手段,事实也正是如此,回想我们从ServiceManager.getService追溯下来的代码,不一直都是站在Binder Client的角度嘛。ServiceManager的类结构图如下:
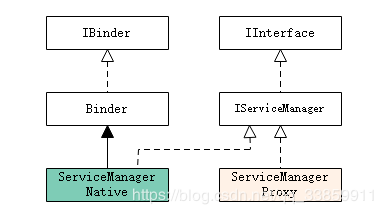
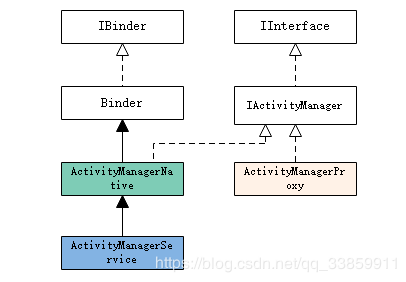
从ServiceManagerNative的命名角度来看,ServiceManagerNative或者其子类内部应该有ServiceManager服务端的逻辑才能满足上边图示中关于java层binder类结构图的描述,但事实并非如此,ServiceManagerNative类除了asInterface方法之外一无是处,且作为抽象类的ServiceManagerNative在Android系统中也并无任何子类,这说明在java层只实现了ServiceManager在Binder Client端的proxy逻辑。那么问题来了,ServiceManager作为一个Binder Server,更作为整个Binder机制的DNS关键角色,其作为Binder Server的具体实现在哪呢?实际上ServiceManager的java层binder类结构比较特殊,其作为Binder Server的逻辑是在native层实现的,并且作为native进程/system/bin/servicemanager单独存在。当然,抛开ServiceManager,其它大多数Binder Server的类结构图还是和之前图示相似。比如我们的ActivityManager:
在解释java层的binder类结构图示时,我们曾提到图示的两个重要细节,其中第二个细节是作为Binder Server在Binder Client端的代理Proxy,其内部肯定需要具备同Binder Server进行通信的能力,而在我们的ServiceManager代理中,这个能力就是其构造参数提供的,这个构造参数最终赋值为mRemote,也正合情合理。对应ServiceManagerProxy来说,其构造参数是BinderInternal.getContextObject()。
// frameworks/base/core/java/com/android/internal/os/BinderInternal.java
public class BinderInternal {
//...
/**
* Return the global "context object" of the system. This is usually
* an implementation of IServiceManager, which you can use to find
* other services.
*/
public static final native IBinder getContextObject();
//...
}
不难发现BinderInternal.getContextObject()通过了jni的方式由C++层实现,这说明在之前我们说的那句话‘在java层只实现了ServiceManager在Binder Client端的proxy逻辑’都有待商榷,更准确的来说,其Proxy核心逻辑是通过jni的方式由native层实现了。而在Android系统,注册native方法到Java VM中是通过AndroidRuntime.cpp的startReg()方法进行的,在startReg注册的gRegJNI数组中包含了Binder机制部分的jni方法register_android_os_Binder()。这个注册binder jni的具体实现在android_util_Binder.cpp中:
// frameworks/base/core/jni/android_util_Binder.cpp
int register_android_os_Binder(JNIEnv* env)
{
if (int_register_android_os_Binder(env) < 0)
return -1;
if (int_register_android_os_BinderInternal(env) < 0)
return -1;
if (int_register_android_os_BinderProxy(env) < 0)
return -1;
//...
return 0;
}
涉及到Binder机制的类诸如Binder.java、BinderProxy.java(Binder的内部类)、BinderInternal.java的native方法在此处都有register。此处我们暂且关心其int_register_android_os_BinderInternal实现。可见上边出现的BinderInternal类中的getContextObject()最终对应到native方法android_os_BinderInternal_getContextObject。
// frameworks/base/core/jni/android_util_Binder.cpp
static const JNINativeMethod gBinderInternalMethods[] = {
/* name, signature, funcPtr */
{ "getContextObject", "()Landroid/os/IBinder;", (void*)android_os_BinderInternal_getContextObject },
{ "joinThreadPool", "()V", (void*)android_os_BinderInternal_joinThreadPool },
{ "disableBackgroundScheduling", "(Z)V", (void*)android_os_BinderInternal_disableBackgroundScheduling },
{ "handleGc", "()V", (void*)android_os_BinderInternal_handleGc }
};
const char* const kBinderInternalPathName = "com/android/internal/os/BinderInternal";
static int int_register_android_os_BinderInternal(JNIEnv* env)
{
jclass clazz;
clazz = env->FindClass(kBinderInternalPathName);
//...
return AndroidRuntime::registerNativeMethods(env, kBinderInternalPathName,gBinderInternalMethods, NELEM(gBinderInternalMethods));
}
static jobject android_os_BinderInternal_getContextObject(JNIEnv* env, jobject clazz)
{
sp<IBinder> b = ProcessState::self()->getContextObject(NULL);
return javaObjectForIBinder(env, b);
}
在native方法中通过ProcessState类的getContextObject()获取到了一个IBinder,并将其转换为java对象。正是这个IBinder在java层被ServiceManagerProxy赋值成为了mRemote变量,而所有的契约方法调用都是通过mRemote.transact()与远程进行通信,所以我们有必要了解下mRemote到底是什么?在下边代码中我们发现通过getContextObject返回的最终是BPBinder(0)。在之前介绍Binder机制组成时,我们有提到过ServiceManager角色类似于互联网络的DNS,而这个"DNS"拥有全网皆知的一个固定ip地址(handle),此处亦可得到证明。
// frameworks/native/libs/binder/ProcessState.cpp
sp<IBinder> ProcessState::getContextObject(const sp<IBinder>& /*caller*/)
{
//获取svm,其handle=0
return getStrongProxyForHandle(0);
}
sp<IBinder> ProcessState::getStrongProxyForHandle(int32_t handle)
{
sp<IBinder> result;
AutoMutex _l(mLock);
//本地向量表中查询对应handle值的binder server,根据方法内部来看,其未找到则自动添加entry占位
//所以此处必有返回值!=null
handle_entry* e = lookupHandleLocked(handle);
if (e != NULL) {
IBinder* b = e->binder;
if (b == NULL || !e->refs->attemptIncWeak(this)) {
//handle=0应该是ServiceManager
if (handle == 0) {
//通过pingBinder确定ServiceManager服务是否存活,如果ServiceManager已经dead,那么返回空
Parcel data;
status_t status = IPCThreadState::self()->transact(
0, IBinder::PING_TRANSACTION, data, NULL, 0);
if (status == DEAD_OBJECT)
return NULL;
}
//每个代理都理解为一个BpBinder
b = new BpBinder(handle);
//同时把代理存放在进程向量表中
e->binder = b;
if (b) e->refs = b->getWeakRefs();
result = b;
} else {
//...
}
}
return result;
}
至此,我们对ServiceManager在java层应该已有了一个总体印象,ServiceManager作为Binder Server并未在java层实现,其作为Binder Client端的Proxy也是由java层经jni方式调用到native层,在native层由BpBinder(handle=0)负责与远程的ServiceManager Server通信。
native层Proxy
ServiceManager作为Android系统中Binder机制的’DNS’,其不仅仅供java进程获取Binder Server,native进程也应可以使用其获取,那么显然其在native层也有整套使用体系。在前边我们画了张java层binder类结构图示,而native层binder类结构图如下:

在native层binder架构图中,BnInterface与BpInterface都是模板类。
BpInterface模板一般由Binder Client使用,其作用与java层Proxy类似,在BpInterface通过继承BpRefBase同样聚合了一个mRemote变量,这样继承了BpInterface的子类就可通过mRemote与Binder Server进程进行通信,相信到了这里,读者应该已经明白mRemote其实就是BpBinder(handle)。
// frameworks/native/include/binder/IInterface.h
template<typename INTERFACE>
class BpInterface : public INTERFACE, public BpRefBase
{
public:
BpInterface(const sp<IBinder>& remote);
protected:
virtual IBinder* onAsBinder();
};
// frameworks/native/include/binder/Binder.h
class BpRefBase : public virtual RefBase
{
protected:
BpRefBase(const sp<IBinder>& o);
inline IBinder* remote() { return mRemote; }
inline IBinder* remote() const { return mRemote; }
//...
private:
IBinder* const mRemote;
//...
};
而BnInterface模板则一般由Binder Server使用,而且同BpInterface模板一样,BnInterface也要遵守契约接口IXXXX。因继承BnInterface的子类即是Binder Server,那么在BnXXXX中应该对契约接口IXXXX的方法进行重写,只有这样BnXXXX与其在Binder Client代理BPXXXX之间的方法调用才有意义。
template<typename INTERFACE>
class BnInterface : public INTERFACE, public BBinder
{
public:
virtual sp<IInterface> queryLocalInterface(const String16& _descriptor);
virtual const String16& getInterfaceDescriptor() const;
protected:
virtual IBinder* onAsBinder();
};
在native层binder架构图示中,不难发现有两个核心细节:1.native层Binder Server在Binder Client中的Proxy的核心是BpBinder(就是Proxy内部的mRemote);2.native层Binder Server端的核心BnXXXX继承自BBinder。同样而言,对java层来说,从之前的分析我们已经知道java层的Proxy核心最终对应到native层的BpBinder(对应其内部mRemote),对于java层的Binder Server来说有没有在native层中与BBinder有关联呢?事实确实如此!通常我们进行开发时,Binder Server不论是通过‘java层binder架构图’中的AIDL构建或系统服务的方式都需要继承自Binder,而在Binder默认构造方法中init是个native方法,这其实也就是说,Binder Server在创建时会调用init()。
// frameworks/base/core/java/android/os/Binder.java
public class Binder implements IBinder {
public Binder() {
init();
//...
}
//...
private native final void init();
}
关于Binder机制中jni的调用,在前边我们已提到过,在Android_util_Binder.cpp中也注册了Binder.java对应的native调用。即如下:
// frameworks/base/core/jni/android_util_Binder.cpp
static const JNINativeMethod gBinderMethods[] = {
/* name, signature, funcPtr */
//...
{ "init", "()V", (void*)android_os_Binder_init },
{ "destroy", "()V", (void*)android_os_Binder_destroy }
};
const char* const kBinderPathName = "android/os/Binder";
static void android_os_Binder_init(JNIEnv* env, jobject obj)
{
JavaBBinderHolder* jbh = new JavaBBinderHolder();
if (jbh == NULL) {
jniThrowException(env, "java/lang/OutOfMemoryError", NULL);
return;
}
ALOGV("Java Binder %p: acquiring first ref on holder %p", obj, jbh);
jbh->incStrong((void*)android_os_Binder_init);
env->SetLongField(obj, gBinderOffsets.mObject, (jlong)jbh);
}
当java层Binder Server创建时通过jni方式调用到native层方法android_os_Binder_init继而在native层创建了一个JavaBBinderHolder,可以预见的是这个JavaBBinderHolder必然持有了一个BBinder,这也从下边的代码中得到证实。那么我们就可以得出结论,每个java层的Binder Server都在native层有一个BBinder与之对应。更进一步来说,不管是java层或者native层,Binder Server中的BBinder与Binder Client中的BpBinder就类似于打电话时两端的话筒一样,是进程间通信的关键。正因此,我们回过头去看文章的第二张图应该有更深刻的理解。
// frameworks/base/core/jni/android_util_Binder.cpp
class JavaBBinderHolder : public RefBase{
public:
sp<JavaBBinder> get(JNIEnv* env, jobject obj)
{
AutoMutex _l(mLock);
sp<JavaBBinder> b = mBinder.promote();
if (b == NULL) {
b = new JavaBBinder(env, obj);
mBinder = b;
ALOGV("Creating JavaBinder %p (refs %p) for Object %p, weakCount=%" PRId32 "\n",
b.get(), b->getWeakRefs(), obj, b->getWeakRefs()->getWeakCount());
}
return b;
}
//...
private:
Mutex mLock;
wp<JavaBBinder> mBinder;
};
class JavaBBinder : public BBinder{
//...
};
经过上边的解释,我相信读者对native层Binder类结构已有些许了解,那么我们回到本小节最开始的问题,即如果我们开发的是一个native应用,那么又如何通过Binder机制来进行进程间通信呢?与java层对应的是,native层也可以通过ServiceManager获取其他Binder Server进而与之通信。在native层ServiceManager的核心类是IServiceManager.cpp。可以想象的是为了与‘DNS’通信,其必然也遵守着与java层同样的契约接口。当然,具体来说,这些所谓的契约接口,并非指的是方法名一定要一致,而是指相同功能的方法其对应的业务码以及方法参数打包方式一致。以下是native层的契约接口,如果您够细心的话,会发现对应方法的业务码完全一致的。
// frameworks/native/include/binder/IServiceManager.h
class IServiceManager : public IInterface
{
public:
//这个宏定义在/frameworks/native/include/binder/IInterface.h中,读者可自行查阅
DECLARE_META_INTERFACE(ServiceManager);
virtual sp<IBinder> getService( const String16& name) const = 0;
virtual status_t addService( const String16& name,
const sp<IBinder>& service,
bool allowIsolated = false) = 0;
//...
enum {
GET_SERVICE_TRANSACTION = IBinder::FIRST_CALL_TRANSACTION,
CHECK_SERVICE_TRANSACTION,
ADD_SERVICE_TRANSACTION,
LIST_SERVICES_TRANSACTION,
};
};
进入IServiceManager.cpp文件中,我们不难发现诸如BnServiceManager、BpServiceManager等与native层binder类结构相匹配的子类。所以我们不难可以勾勒出ServiceManager的native类结构,即如下图所示:
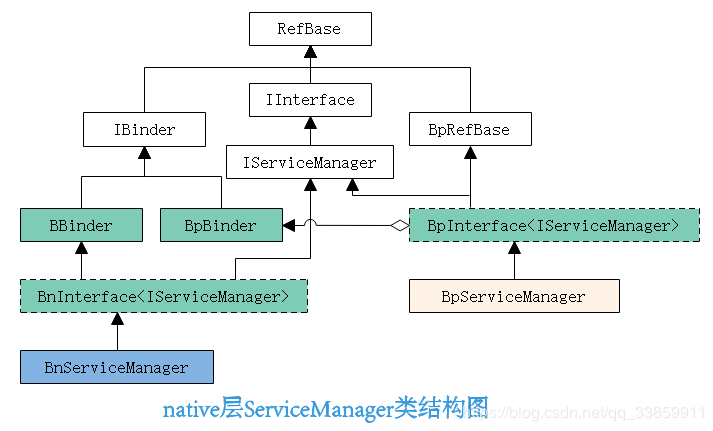
BpServiceManager的角色同java层ServiceManagerProxy一模一样,都是作为Binder Client端的代理存在,与ServiceManager服务端通信也是通过BpServiceManager内部mRemote变量(此处mRemote通过BpRefBase私有化,所以我们看到的是其remote()方法)进行的。而BnServiceManager也与java层的ServiceManagerNative一样,并没有对契约接口进行任何重写,这同样印证了之前所提到的,ServiceManager作为Binder Server的逻辑在系统其他地方单独处理了,具体在哪处理的,我在后边会有详细介绍。
在对native层ServiceManager在Binder Client端代理有了一定了解之后我们还有一点需要补充,这就是BpServiceManager是如何变成代理的?我们先来看IServiceManager.cpp中的获取ServiceManager的代码。
// frameworks/native/libs/binder/IServiceManager.cpp
sp<IServiceManager> defaultServiceManager()
{
if (gDefaultServiceManager != NULL) return gDefaultServiceManager;
{
AutoMutex _l(gDefaultServiceManagerLock);
while (gDefaultServiceManager == NULL) {
gDefaultServiceManager = interface_cast<IServiceManager>(
ProcessState::self()->getContextObject(NULL));
if (gDefaultServiceManager == NULL)
sleep(1);
}
}
return gDefaultServiceManager;
}
IMPLEMENT_META_INTERFACE(ServiceManager, "android.os.IServiceManager");
//...
如果是native应用想要获取ServiceManager在Binder Client的代理,从上述代码可知,仅需导入IServiceManager.h后调用defaultServiceManager()即可获取。但这和java层有不太一样,我们知道java层通过ServiceManagerNative.asInterface()就可获取ServiceManagerProxy,而在此处却并没有BpServiceManager这个代理的痕迹。BpServiceManager的获取涉及到一个模板方法及一个宏的调用,要弄明白BpServiceManager是如何成为在Binder Client端的代理,就要厘清这两者的作用才行。
依着defaultServiceManager()方法,我们看到gDefaultServiceManager是通过interface_cast()方法获取的,而这个方法实质上是个模板方法:
// frameworks/native/include/binder/IInterface.h
template<typename INTERFACE>
inline sp<INTERFACE> interface_cast(const sp<IBinder>& obj)
{
return INTERFACE::asInterface(obj);
}
依着defaultServiceManager()内部通过调用这个模板方法,实质上就是调用IServiceManager::asInterface(obj)。然而,在我们是不能直接搜索到该方法的。因为这个asInterface方法是通过宏定义生成的。上边贴出来的代码里defaultServiceManager()方法的下边我们就已经把这个宏给贴出来了。IMPLEMENT_META_INTERFACE这个宏的定义是在IInterface
.h中:
// frameworks/native/include/binder/IInterface.h
#define IMPLEMENT_META_INTERFACE(INTERFACE, NAME) \
const android::String16 I##INTERFACE::descriptor(NAME); \
const android::String16& \
I##INTERFACE::getInterfaceDescriptor() const { \
return I##INTERFACE::descriptor; \
} \
android::sp I##INTERFACE::asInterface( \
const android::sp& obj) \
{ \
android::sp intr; \
if (obj != NULL) { \
intr = static_cast( \
obj->queryLocalInterface( \
I##INTERFACE::descriptor).get()); \
if (intr == NULL) { \
intr = new Bp##INTERFACE(obj); \
} \
} \
return intr; \
} \
I##INTERFACE::I##INTERFACE() { } \
I##INTERFACE::~I##INTERFACE() { }
在这个宏的定义中,我们发现了asInterface()的身影,继而结合IServiceManager.cpp中IMPLEMENT_META_INTERFACE(ServiceManager, “android.os.IServiceManager”)就不难发现,IServiceManager的asInterface()这个方法最终返回的正是BpServiceManager,对应defaultServiceManager()来看,则是返回new BpServiceManager(new BpBinder(0))。
至此,关于ServiceManager在Binder Client端部分作为Proxy的解答就告一段落了。
ServiceManager服务进程
ServiceManager类比于互联网络中的‘DNS’,其首先是一个Binder Server,具有固定的handle,但却是Binder机制进程间进行通信的中流砥柱。从启动时序上来看,必然先于其它Binder Server/Binder Client。在前边我们隐隐提到,ServiceManager作为Binder Server其是个native进程,源码结构如下:

可见源码路径为/frameworks/native/cmds/servicemanager。作为native程序,其源码主要由binder.c及service_manager.c组成。我们进入其make文件:
//Android.mk
...
include $(CLEAR_VARS)
LOCAL_SHARED_LIBRARIES := liblog libselinux
LOCAL_SRC_FILES := service_manager.c binder.c/*编入的源码*/
LOCAL_CFLAGS += $(svc_c_flags)
LOCAL_MODULE := servicemanager/*生成的可执行程序名*/
include $(BUILD_EXECUTABLE)/*编译可执行文件*/
既然,这个servicemanager这个进程在启动时序上要优先于其他Binder Server。我们很容易就想到init.rc这个Android系统的可配置初始化文件,init.rc在linux init进程中就被解析执行。关于init.rc语法可参见我的文章Android Init Language语法概述。在on boot这个Actions最后会启动core类型的进程,其中就包括我们的servicemanager。
// /system/core/rootdir/init.rc
service servicemanager /system/bin/servicemanager
class core
user system
group system
critical
onrestart restart healthd
onrestart restart zygote
onrestart restart media
onrestart restart surfaceflinger
onrestart restart drm
在了解servicemanager(之前我们一般把其称之为ServiceManager服务,在本节为了研究方便,使用servicemanager描述作为Binder Server的‘DNS’native进程)是如何启动之后,我们进入其主函数中:
// frameworks/native/cmds/servicemanager/service_manager.c
int main(int argc, char **argv)
{
struct binder_state *bs;
bs = binder_open(128*1024);
//如果打开驱动失败则结束进程,方便重启
if (!bs) {
ALOGE("failed to open binder driver\n");
return -1;
}
//成为注册binder server的大管家,内部通过ioctl把获取的fd传给binder驱动
if (binder_become_context_manager(bs)) {
ALOGE("cannot become context manager (%s)\n", strerror(errno));
return -1;
}
//属于linux的安全模块,主要做权限鉴定
selinux_enabled = is_selinux_enabled();
sehandle = selinux_android_service_context_handle();
//...
//规定svc的handle值为0
svcmgr_handle = BINDER_SERVICE_MANAGER;
//进入循环
binder_loop(bs, svcmgr_handler);
return 0;
}
根据main函数代码来看,servicemanager启动过程主要分为以下三个部分:
- 打开binder驱动设备,做好进程初始化工作。对应方法为binder_open()。
- 设置servicemanager进程为Binder Server大管家(即类比‘DNS’)。对应方法为binder_become_context_manager()。
- 进入主循环,不断处理通信数据。对应方法为binder_loop()。

接下来我们从就着这三个部分一一展开。
在servicemanager程序启动后,其首先就调用了binder_open进行了进程的一些初始化工作:
// frameworks/native/cmds/servicemanager/binder.c
/* 负责open binder驱动获取fd,并mmap地址空间*/
struct binder_state *binder_open(size_t mapsize)
{
struct binder_state *bs;
struct binder_version vers;
bs = malloc(sizeof(*bs));
if (!bs) {
errno = ENOMEM;
return NULL;
}
//打开binder驱动,一个进程中只需打开一次即可
bs->fd = open("/dev/binder", O_RDWR);
//...
//获取binder内核驱动版本与binder native版本 比较是否一致
if ((ioctl(bs->fd, BINDER_VERSION, &vers) == -1) ||
(vers.protocol_version != BINDER_CURRENT_PROTOCOL_VERSION)) {
fprintf(stderr, "binder: driver version differs from user space\n");
goto fail_open;
}
bs->mapsize = mapsize;
//映射只读权限的地址空间,对同一块物理内存在驱动空间和用户空间做地址映射,这样两者即可操作同一内存区域
//地址空间大小不能超过4M
bs->mapped = mmap(NULL, mapsize, PROT_READ, MAP_PRIVATE, bs->fd, 0);
//...
return bs;
}
binder驱动通过misc_register()把自身注册为在/dev目录下名为binder的杂项驱动设备。而在此处则通过open()方法(System Call)打开驱动,在得到文件描述符fd后利用其查看当前在native层的Binder版本与linux内核中Binder驱动的版本是否一致。如果版本一致,则通过mmap()方法(System Call)映射128k大小的只读内存到进程空间。篇首我们提到Binder机制只需一次拷贝就可完成数据从Binder Client到Binder Server之间的传输,原因就是借助mmap()方法来完成用户空间和内核空间之间的内存映射,当然,具体如何mmap()我们在之后说到Binder驱动在细说。
而servicemanager的main函数中第二部分主要则是通过ioctl()方法(System Call)把当前进程设置为其它实名Binder Server(实质上只是binder引用)的管理者。
// frameworks/native/cmds/servicemanager/binder.c
int binder_become_context_manager(struct binder_state *bs)
{
return ioctl(bs->fd, BINDER_SET_CONTEXT_MGR, 0);
}
ioctl()最终通过System Call方式调用到binder驱动的binder_ioctl(),ioctl有些支持的命令我们已经见过,如上边代码BINDER_VERSION、BINDER_SET_CONTEXT_MGR等,而这些命令当中BINDER_WRITE_READ很重要,可谓Binder机制中进行进程间通信的核心命令。
| 命令 | 说明 |
|---|---|
| BINDER_WRITE_READ | 读写操作,用以从Binder驱动读取或写入数据 |
| BINDER_SET_CONTEXT_MGR | ServiceManager专用,目的是设置自己为Binder Server大管家(DNS),在整个Android系统中应只设置一次 |
| BINDER_SET_MAX_THREADS | 设置当前进程所支持的用于处理Binder请求最大线程数 |
| BINDER_THREAD_EXIT | 告知Binder驱动当前线程退出,方便Binder Driver释放与当前线程相关的资源 |
| BINDER_VERISON | 获取Binder Driver的版本号 |
第三部分则进入主循环binder_loop(),作为servicemanager中最为复杂的部分,其主要处理通过Binder驱动传过来的数据,这些数据可能来自于想要获知Binder Server(Binder Server引用)的Binder Client,也可能就是来自于某Binder Server。回想下在之前讲解ServiceManagerProxy的时候那些契约接口(getService/addService),其对应的业务码都会在主循环中有涉及。
// frameworks/native/cmds/servicemanager/binder.c
void binder_loop(struct binder_state *bs, binder_handler func)
{
int res;//result
struct binder_write_read bwr;
uint32_t readbuf[32];
//write size为0说明处理的不是write消息
bwr.write_size = 0;
bwr.write_consumed = 0;
bwr.write_buffer = 0;
//告诉binder驱动svm进入循环模式
readbuf[0] = BC_ENTER_LOOPER;
binder_write(bs, readbuf, sizeof(uint32_t));
//死循环
for (;;) {
//设置read的消息大小及存消息的buffer
bwr.read_size = sizeof(readbuf);
bwr.read_consumed = 0;
bwr.read_buffer = (uintptr_t) readbuf;
//读取binder驱动发送的消息,并把消息存到bwr中---阻塞式
res = ioctl(bs->fd, BINDER_WRITE_READ, &bwr);
if (res < 0) {
ALOGE("binder_loop: ioctl failed (%s)\n", strerror(errno));
break;
}
//对消息进行解析,read_consumed由binder驱动填入,表明使用buffer大小
res = binder_parse(bs, 0, (uintptr_t) readbuf, bwr.read_consumed, func);
if (res == 0) {
ALOGE("binder_loop: unexpected reply?!\n");
break;
}
if (res < 0) {
ALOGE("binder_loop: io error %d %s\n", res, strerror(errno));
break;
}
}
}
虽然从普通应用看来,binder机制主要通过Parcel打包数据,但真正与binder驱动打交道并实现进行进程间通信的数据结构实质上是binder_write_read。binder_write_read是结构体类型,其内部主要分为write与read两个组成部分,分别用于存放写入指令与读取指令,各部分所定义的变量名也恰到好处的体现其含义。在上边的代码中,我们可以看到在进行for循环前servicemanager通过BC_ENTER_LOOPER指令告知了binder驱动当前大管家要进入无限循环以等待请求。BC_ENTER_LOOPER是下边ioctl命令BINDER_WRITE_READ的众多子命令之一。
| BC_INCREFS BC_ACQUIRE BC_RELEASE BC_DECREFS |
这一组命令用于操作引用计数 |
| BC_INCREFS_DONE BC_ACQUIRE_DONE |
与上边一组命令相对,当BC_INCREFS和BC_ACQUIRE结束时发送 |
| BC_ATTEMPT_ACQUIRE BC_ACQUIRE_RESULT |
未实现 |
| BC_FREE_BUFFER | 用于Binder的buffer管理 |
| BC_TRANSACTION BC_REPLY |
是BINDER_WRITE_READ命令的关键子命令,Binder Client与Binder Server通信基本靠此完成 |
| BC_REGISTER_LOOPER BC_ENTER_LOOPER BC_EXIT_LOOPER |
用于设置当前binder looper的状态 |
| BC_REQUEST_DEATH_NOTIFICATION BC_CLEAR_DEATH_NOTIFICATION |
z这组命令江通知目标对象执行death操作,以及清除death notification,后者使用建立在前者的基础上 |
| BC_DEAD_BINDER_DONE | 与death操作相关联 |
在通知Binder驱动servicemanager即将进入无限循环后,接下来无疑就是在循环处理其他binder进程的请求,我们注意到分配给读取部分的read_buffer的大小为32*uint32_t即128个字节。这里请注意这个read_buffer并不是用来存放真正的通信数据的(显然在应用中通过Parcel打包的数据一般是不可能只有128字节大小的),read_buffer主要用来存放一些BINDER_WRITE_READ子命令及一些地址指针(真正传输的数据在指针指向的内存)的。只有明白了这一点,在之后对于Binder驱动中随处可见的copy_from_user、copy_to_user有更深刻的理解。当然,对于BINDER_WRITE_READ子命令来说,命名方式如BC_XXXX的子命令一般是写入命令,在BC_XXXX子命令进入Binder驱动中流转时会被转成BR_XXXX子命令到达目标端。例如我们的BC_TRANSACTION命令从ServiceManager代理端写入后经过Binder驱动后到达servicemanager时被转成了BR_TRANSACTION。所以在此处我们read_buffer作为读取部分接收到的都是以BR开头的命令。
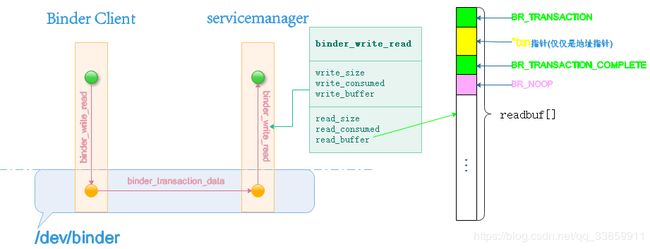
在binder_loop()进入循环后,就通过ioctl()方法(System Call)从Binder驱动读写消息(servicemanager在此处只读消息),因为ioctl()方法是阻塞式的调用(阻塞原理在Binder驱动内部),所以当收到Binder Client(相对于servicemanager作为Binder Server而言)传过来的消息之后就调用binder_parse()方法对消息内容进行解析。这些内容主要就是readBuf[]中的内容,他们由若干BINDER_WRITE_READ的子命令构成。
// frameworks/native/cmds/servicemanager/binder.c
int binder_parse(struct binder_state *bs, struct binder_io *bio,
uintptr_t ptr, size_t size, binder_handler func)
{
int r = 1;
uintptr_t end = ptr + (uintptr_t) size;
//一次可能读取多个cmd
while (ptr < end) {
//一个binder指令占位长度为unit32_t即4字节
uint32_t cmd = *(uint32_t *) ptr;
//取出指令后把地址顺延
ptr += sizeof(uint32_t);
#if TRACE
fprintf(stderr,"%s:\n", cmd_name(cmd));
#endif
switch(cmd) {
case BR_NOOP:
break;
case BR_TRANSACTION_COMPLETE:
break;
case BR_INCREFS:
case BR_ACQUIRE:
case BR_RELEASE:
case BR_DECREFS:
#if TRACE
fprintf(stderr," %p, %p\n", (void *)ptr, (void *)(ptr + sizeof(void *)));
#endif
//地址顺延2*4字节
ptr += sizeof(struct binder_ptr_cookie);
break;
case BR_TRANSACTION: {
//真正进行传输的数据格式binder_transaction_data指针
struct binder_transaction_data *txn = (struct binder_transaction_data *) ptr;
//end为整个buffer数据指针的长度
if ((end - ptr) < sizeof(*txn)) {
ALOGE("parse: txn too small!\n");
return -1;
}
//打印数据中可能携带的其他binder信息
binder_dump_txn(txn);
//func负责执行binder_transaction_data的具体业务
if (func) {
unsigned rdata[256/4];
struct binder_io msg;
struct binder_io reply;
int res;
//对reply初始化
bio_init(&reply, rdata, sizeof(rdata), 4);
//把txn中数据填充到msg中
bio_init_from_txn(&msg, txn);
//关键
res = func(bs, txn, &msg, &reply);
//回复驱动当前reply
binder_send_reply(bs, &reply, txn->data.ptr.buffer, res);
}
//地址顺延binder_transaction_data指针长度
ptr += sizeof(*txn);
break;
}
case BR_REPLY: {
struct binder_transaction_data *txn = (struct binder_transaction_data *) ptr;
if ((end - ptr) < sizeof(*txn)) {
ALOGE("parse: reply too small!\n");
return -1;
}
//打印数据中可能携带的其他binder信息
binder_dump_txn(txn);
//binder_parse传入的是bio的参数为0,也就意味着svm根本不处理BR_REPLY,直接跳过
if (bio) {
bio_init_from_txn(bio, txn);
bio = 0;
} else {
/* todo FREE BUFFER */
}
ptr += sizeof(*txn);
r = 0;
break;
}
case BR_DEAD_BINDER: {
//?
struct binder_death *death = (struct binder_death *)(uintptr_t) *(binder_uintptr_t *)ptr;
ptr += sizeof(binder_uintptr_t);
death->func(bs, death->ptr);
break;
}
case BR_FAILED_REPLY:
r = -1;
break;
case BR_DEAD_REPLY:
r = -1;
break;
default:
ALOGE("parse: OOPS %d\n", cmd);
return -1;
}
}
return r;
}
以上是servicemanager服务中的binder_parse()的完整代码,这些BINDER_WRITE_READ子命令(鉴于BR_XXXX是BC_XXXX的在经过Binder驱动中转换后的结构,所以此处暂理解其为BINDER_WRITE_READ子命令)抛开一些诸如空操作、引用计数、处理出错之外,真正值得关心的case也就只有BR_TRANSACTION。transaction从字面上理解是事务、业务,这是一个从Binder驱动层来看才会有准确含义的词,在Binder驱动中把进程与进程之间传递消息数据的过程看成一个事务,这个事务有不同的阶段,可能传递成功或者失败有点类似于SQL中事务的概念,其在Binder驱动中有个专门的词叫binder_transaction。而对于在Binder驱动中流转的进程间数据就成为一次binder_transaction中的数据即binder_transaction_data。而对应于上边BR_TRANSACTION的case来说就是处理这次事务的过程,其处理的数据内容就是binder_transaction_data。
// bionic/libc/kernel/uapi/linux/binder.h
struct binder_transaction_data {
union {
__u32 handle;//类似ip地址
binder_uintptr_t ptr;//指针
} target;//数据所传输的目标,如果
binder_uintptr_t cookie;//仅当ptr有值时成立,用以标识BBinder,cookie主要用于当death时释放cookie指向的BBinder内存。
__u32 code;//标识方法的业务码
__u32 flags;//用于标识当前传输是否为one way,即是否要在传输过程中阻塞线程,此flag主要由Binder驱动处理
pid_t sender_pid;//标识进程,由Binder驱动填入
uid_t sender_euid;//标识线程,由Binder驱动填入
binder_size_t data_size;//普通数据大小
binder_size_t offsets_size;//offsets区域大小
union {
struct {
binder_uintptr_t buffer;//普通数据
binder_uintptr_t offsets;//offsets区域,binder数据
} ptr;
__u8 buf[8];
} data;//总数据
}
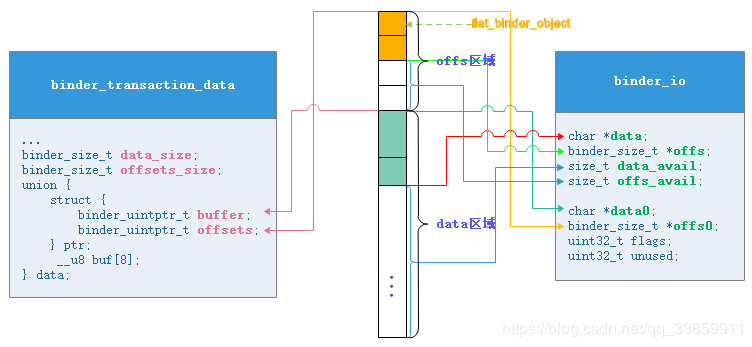
binder_transaction_data数据的区域主要是结构体ptr所指向的区域,buffer与offsets是地址指针,分别指向普通数据和binder数据(可见binder_transaction_data所传输的也只是传输控制指令和数据指针)。

在case:BR_TRANSACTION中,主要分为以下几个处理部分:
- 获取此次事务中要处理的binder_transaction_data数据。
- 对当前事务需要返回的reply进行初始化。
- 将数据binder_transaction_data填充到servicemanager进程真正处理的数据类型binder_io中去。
- 调用真正处理事务的方法func,即由沿途从servicemanager中传下来的函数svcmgr_handler来处理,处理结果会保存在reply中。
- 把处理结果reply通过Binder驱动返给Binder Client。
我们知道binder_transaction_data是在Binder驱动中流转的数据结构,其具有数据无关性,正因此,servicemanager在接收到数据(普通数据+binder数据)后把这些数据整理成binder_io结构。在bio_init_from_txn()中我们能很好的体会这种整理过程。从下边的代码可知,buffer区域整理成binder_io的data部分,而offsets部分整理成了binder_io的offs部分。
// frameworks/native/cmds/servicemanager/binder.c
void bio_init_from_txn(struct binder_io *bio, struct binder_transaction_data *txn)
{
bio->data = bio->data0 = (char *)(intptr_t)txn->data.ptr.buffer;
bio->offs = bio->offs0 = (binder_size_t *)(intptr_t)txn->data.ptr.offsets;
bio->data_avail = txn->data_size;
bio->offs_avail = txn->offsets_size / sizeof(size_t);
bio->flags = BIO_F_SHARED;
}
正如我们从上述代码中看到的那样,binder_io填充过程中填充了两套变量(带0和不带0),其中带0的变量用于记录data(buffer)区域和offs(offsets)区域的开始地址,而不带0的变量则记录了当前存入/取出的地址。对于bio_init_from_txn()方法内部来说其binder_io的赋值过程即是从binder_transaction_data中整理出数据的过程,也是记录初始数据地址和当前地址的过程。随着数据从binder_io中不断读取(或写入,我们上边的reply就是个写入数据的过程),data与offs变量逐渐往后偏移,data_avail及offs_avail也随之减小。
在完成了对需要处理的binder_io填充完毕后,接下来就是调用func()即svcmgr_handler方法处理这些binder_io数据。在svcmgr_handler首先对handle值及descriptor值进行检查。如果handle!=0或者Binder Client写入的descriptor不一致,则直接返回-1错误。接着根据不同的txn->code(业务码)处理不同的逻辑,对于各个case中的业务码与Binder Client中对应契约接口的业务码是一致的。
// frameworks/native/cmds/servicemanager/service_manager.c
int svcmgr_handler(struct binder_state *bs,
struct binder_transaction_data *txn,
struct binder_io *msg,
struct binder_io *reply)
{
//...
//此处判断当前收到的binder_transaction_data的传送目标是否是svm。
if (txn->target.handle != svcmgr_handle)
return -1;
//...
//获取描述符descriptor
s = bio_get_string16(msg, &len);
if (s == NULL) {
return -1;
}
//InterfaceToken比较 memcmp两者相等时返回0(false) sizeof返回的值的单位是字节,所以要/2,即2字节代表1字符
//简单而言,以下比较了描述符的长度与字符内容
if ((len != (sizeof(svcmgr_id) / 2)) ||
memcmp(svcmgr_id, s, sizeof(svcmgr_id))) {
fprintf(stderr,"invalid id %s\n", str8(s, len));
return -1;
}
//...
//业务码 ,此处只判断前4种业务码,在IServiceManager.java中有6种
switch(txn->code) {
case SVC_MGR_GET_SERVICE:
case SVC_MGR_CHECK_SERVICE:
//获取想要get/check的service名称
s = bio_get_string16(msg, &len);
if (s == NULL) {
return -1;
}
handle = do_find_service(bs, s, len, txn->sender_euid, txn->sender_pid);
//如果返回0则代表没有找到service
if (!handle)
break;
//把找到的service的handle值存入reply中
bio_put_ref(reply, handle);
return 0;
case SVC_MGR_ADD_SERVICE:
//获取需要添加的service名称
s = bio_get_string16(msg, &len);
if (s == NULL) {
return -1;
}
//获取handle,其被打包成flat_binder_object
handle = bio_get_ref(msg);
//是否允许隔离,在接下来的find/check过程需要以此判断某进程能否获取当前service
allow_isolated = bio_get_uint32(msg) ? 1 : 0;
if (do_add_service(bs, s, len, handle, txn->sender_euid,
allow_isolated, txn->sender_pid))
return -1;
break;
case SVC_MGR_LIST_SERVICES: {
//n为角标,从client传过来,每次只获取角标n的service。
uint32_t n = bio_get_uint32(msg);
if (!svc_can_list(txn->sender_pid)) {
ALOGE("list_service() uid=%d - PERMISSION DENIED\n",
txn->sender_euid);
return -1;
}
si = svclist;
while ((n-- > 0) && si)
si = si->next;
if (si) {
//只存入service名称,而不是存入flat_binder_object
bio_put_string16(reply, si->name);
return 0;
}
return -1;
}
default:
ALOGE("unknown code %d\n", txn->code);
return -1;
}
bio_put_uint32(reply, 0);
return 0;
}
各个被管理Binder Server在servicemanager都以svcinfo结构体的形式被添加到service_manager.c中的全局单向链表svclist中。我们可以通过do_find_service()向svclist查询对应name的handle值,也可通过do_add_service()往svclist中添加一组svcinfo。
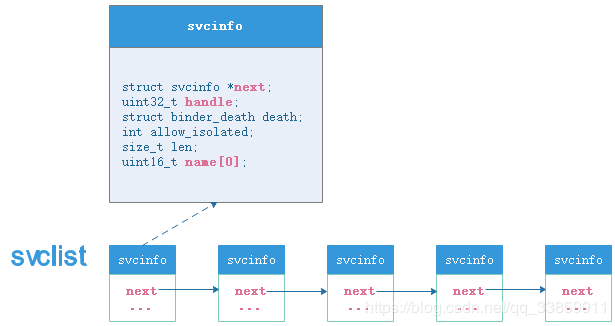
从业务逻辑上讲,svcmgr_handler()各种case分别干了以下几件事:
-
SVC_MGR_GET_SERVICE/SVC_MGR_CHECK_SERVICE。顾名思义,这两种业务码是用于查询svclist服务链表中是否存在指定name的Binder Server引用,如若存在则将其handle值通过bio_put_ref()方法打包成一个flat_binder_object结构体存入reply中。
-
SVC_MGR_ADD_SERVICE。此业务码根据传递过来的Binder服务数据(主要是name及通过bio_get_ref()取出的handle),把其name-handle作为一组映射关系打包成svcinfo后,放入到servicemanager所管理的单向链表svclist中去。
-
SVC_MGR_LIST_SERVICES。此业务码一般使用不多,是用于枚举servicemanager中已注册的所有Binder服务的name。需要注意的是,使用此方法需要传一个角标过来,且每次只返回此角标的对应的服务名称name回去。
可以看出,servicemanager的各个case中对业务码处理并不复杂,在这里我们也不细贴代码说明其查询、添加过程了。仅对其bio_get_ref()过程和bio_put_ref()及这两者牵扯到的数据如何包装的问题做下解释。这就不得不从Parcel数据到底如何存放开始说起。
在Parcel.cpp中针对我们进程间所传输的数据区分为普通业务数据和binder数据(flat_binder_object)两个区域,其分别对应为mData区域与mObjects区域。如以下:
// frameworks/native/include/binder/Parcel.h
class Parcel {
uint8_t* mData;//数据具体存储区域
size_t mDataSize;//数据区域总大小
size_t mDataCapacity;//当前数据区域总容量
mutable size_t mDataPos;//当前数据位置,用以标识依存数据最后位置
binder_size_t* mObjects;//binder数据指针存储区域
size_t mObjectsSize;//binder数据即flat_binder_object数量
size_t mObjectsCapacity;//mObjects容量
//...
}
Parcel中的mData区域不仅仅存放普通数据,同时也负责存放具体的flat_binder_object即binder数据,mObjects区域则负责存放被存放在mData区域的flat_binder_object结构体的地址指针。

// frameworks/native/libs/binder/Parcel.cpp
status_t Parcel::writeObject(const flat_binder_object& val, bool nullMetaData)
{
const bool enoughData = (mDataPos+sizeof(val)) <= mDataCapacity;//data是否有可用容量
const bool enoughObjects = mObjectsSize < mObjectsCapacity;//mObjects是否有可用容量
if (enoughData && enoughObjects) {//检查当前的数据区域及binder指针区域可用区域大小
restart_write:
*reinterpret_cast<flat_binder_object*>(mData+mDataPos) = val;
// Need to write meta-data?
if (nullMetaData || val.binder != 0) {
mObjects[mObjectsSize] = mDataPos;//mDataPos实质上就是flat_binder_object存放的起始地址指针
acquire_object(ProcessState::self(), val, this);
mObjectsSize++;//数量加一
}
// remember if it's a file descriptor
if (val.type == BINDER_TYPE_FD) {
if (!mAllowFds) {
return FDS_NOT_ALLOWED;
}
mHasFds = mFdsKnown = true;
}
return finishWrite(sizeof(flat_binder_object));
}
if (!enoughData) {//如果data可用区域不够,则调用growData扩容
const status_t err = growData(sizeof(val));
if (err != NO_ERROR) return err;
}
if (!enoughObjects) {//如果mObjects区域不够,则调用realloc扩容
size_t newSize = ((mObjectsSize+2)*3)/2;
binder_size_t* objects = (binder_size_t*)realloc(mObjects, newSize*sizeof(binder_size_t));
if (objects == NULL) return NO_MEMORY;
mObjects = objects;
mObjectsCapacity = newSize;
}
goto restart_write;
}
此处我们暂且不管普通数据是如何存放到mData区域的,只看binder数据。我们知道写入binder数据是通过Parcel.cpp中的writeStrongBinder()完成的,其最终会调用上边代码中的writeObject()写入到mData中。从具体流程来看,代码中先判断是否有足够的mData区域及mObjects区域存放flat_binder_object和其地址指针,如果没有则分别调用growData()和realloc()进行扩容,扩容之后restart_write重新写入数据,随后通过强转赋值给mData+mDataPos并在mObjects中记录flat_binder_object在mData域中的相对位置mDataPos,而后mObjects计数器mObjectsSize自增并且通过finishWrite()让mDataPos位置往后移动binder数据大小。这就完成了binder数据在mData区域中的存储。
很显然,之前贴出的Parcel.h中的作为记录mData区域与mObjects区域的这些关键变量都需要传递给接收方,不然接收方拿着mData和mObjects也不知道解析规则。这两个区域在进程间流转图如下,流转到servicemanager中对应于binder_io结构体来说就是data区域与offs区域。

在了解binder_io结构体的data及offs区域原理之后,我们再去看binder.c中充斥着的各种bio_get_XXXX()及bio_put_XXXX()就不难理解了。就如在BR_TRANSACTION中所涉及的Parel初始化那段来说,其初始化过程就是在256字节大小的区域中除分配给offs区域4个地址指针(16字节)大小的区域外都分配给了mData区域。当然,接下来我们挑重点,仅对svcmgr_handler方法所涉及到的bio_put_ref()与bio_get_ref()进行解读。
先看分支SVC_MGR_GET_SERVICE/SVC_MGR_CHECK_SERVICE所涉及到的bio_put_ref()。
// frameworks/native/cmds/servicemanager/binder.c
void bio_put_ref(struct binder_io *bio, uint32_t handle)
{
struct flat_binder_object *obj;
//如果handle!=0
if (handle)
obj = bio_alloc_obj(bio);
else
obj = bio_alloc(bio, sizeof(*obj));
if (!obj)
return;
obj->flags = 0x7f | FLAT_BINDER_FLAG_ACCEPTS_FDS;
obj->type = BINDER_TYPE_HANDLE;
obj->handle = handle;
obj->cookie = 0;
}
static struct flat_binder_object *bio_alloc_obj(struct binder_io *bio)
{
struct flat_binder_object *obj;
//在mData区域中分配flat_binder_object大小的区域
obj = bio_alloc(bio, sizeof(*obj));
//如果offs还有可用区域
if (obj && bio->offs_avail) {
bio->offs_avail--;//offs区域可用容量减一
*bio->offs++ = ((char*) obj) - ((char*) bio->data0);//此处对flat_binder_object地址复制给offs区域下个空区域
return obj;
}
bio->flags |= BIO_F_OVERFLOW;
return NULL;
}
bio_put_ref()方法核心是bio_alloc_obj()方法,在bio_alloc_obj()中我们可以看见其先向mData区域申请了sizeof(*obj)大小的区域作为flat_binder_object的存放位置,并在减少offs区域可用容量后把obj(即flat_binder_object)所在的相对地址赋给offs区域的第一个空区域保存。当然,最后bio_alloc_obj()方法会返回申请的obj并在bio_put_ref()中填入诸如handle等信息。
对应的,bio_get_ref()方法则刚好相反,其内部具体是通过在bio_get_obj()中先判断当前的data相对地址是否与offs区域中某个指针地址一致,如果一致则说明接下来的data区域中的数据时binder数据(flat_binder_object),接着通过bio_get()从data区域中取出对应的binder数据。bio_get_ref()方法具体如下,请读者细细体会。
// frameworks/native/cmds/servicemanager/binder.c
uint32_t bio_get_ref(struct binder_io *bio)
{
struct flat_binder_object *obj;
obj = _bio_get_obj(bio);
if (!obj)
return 0;
//一般而言,不会是BINDER_TYPE_BINDER,因为有此标识意味着是在服务内获取当前服务
if (obj->type == BINDER_TYPE_HANDLE)
return obj->handle;
return 0;
}
static void *bio_get(struct binder_io *bio, size_t size)
{
size = (size + 3) & (~3);
if (bio->data_avail < size){
bio->data_avail = 0;
bio->flags |= BIO_F_OVERFLOW;
return NULL;
} else {
void *ptr = bio->data;
bio->data += size;
bio->data_avail -= size;
return ptr;
}
}
static struct flat_binder_object *_bio_get_obj(struct binder_io *bio)
{
size_t n;
size_t off = bio->data - bio->data0;
/* TODO: be smarter about this? */
for (n = 0; n < bio->offs_avail; n++) {
if (bio->offs[n] == off)
//从对应的mData区域中取出flat_binde_object大小的区域
return bio_get(bio, sizeof(struct flat_binder_object));
}
bio->data_avail = 0;
bio->flags |= BIO_F_OVERFLOW;
return NULL;
}
在svcmgr_handler处理完具体的查询/添加binder服务引用之后,接下来就是返回对应业务处理结果,这些结果已经保存在binder_io类型的reply中,而我们binder_send_reply()就是把reply中的数据根据binder_io与binder_transaction_data对应数据结构重新填入,并以固定格式的结构体通过ioctl()系统调用把结果通过binder驱动返回给Binder Client。
ProcessState与IPCThreadState
成为binder进程
从本章开始阶段就讨论过,进程间的通信需要通过内核空间才能做到,对于Binder进程(无论是Binder Client还是Binder Server)来说,其首要任务必然是打通任督二脉同运行于内核空间的Binder驱动建立联系,这是整个通信的前提。同时我们回忆下servicemanager是如何打通任督二脉的,即其在进入无限循环binder_loop()之前,刨除掉其专用的成为Binder Server大管家的方法binder_become_context_manager()之外,就是首先调用的binder_open()了,不难发现其核心是:1.open()打开Binder驱动,2.mmap()进行内存地址映射。那么对应的我们想要成为Binder进程只需照葫芦画瓢即可,这个工作就是在ProcessState完成的。
ProcessState在本章之前的小节中已经出现过,其是进程单例实现,主要用于为上层(java层+native层)提供IPC服务,获取ProcessState通常通过其self()方法完成。
// frameworks/native/libs/binder/ProcessState.cpp
sp<ProcessState> ProcessState::self()
{
Mutex::Autolock _l(gProcessMutex);
if (gProcess != NULL) {
return gProcess;
}
gProcess = new ProcessState;
return gProcess;
}
可见,self()方法调用时先检查gProcess全局变量是否为空,如果空的话则调用ProcessState构造方法。
// frameworks/native/libs/binder/ProcessState.cpp
ProcessState::ProcessState()
: mDriverFD(open_driver())//打开binder驱动,并赋值给mDriverFD。
, mVMStart(MAP_FAILED)
, mManagesContexts(false)
, mBinderContextCheckFunc(NULL)
, mBinderContextUserData(NULL)
, mThreadPoolStarted(false)//是否打开PoolThread
, mThreadPoolSeq(1)
{
//如果binder驱动打开成功,则mDriverFD应大于0.
if (mDriverFD >= 0) {
#if !defined(HAVE_WIN32_IPC)
mVMStart = mmap(0, BINDER_VM_SIZE, PROT_READ, MAP_PRIVATE | MAP_NORESERVE, mDriverFD, 0);
if (mVMStart == MAP_FAILED) {
ALOGE("Using /dev/binder failed: unable to mmap transaction memory.\n");
close(mDriverFD);
mDriverFD = -1;
}
#else
mDriverFD = -1;
#endif
}
LOG_ALWAYS_FATAL_IF(mDriverFD < 0, "Binder driver could not be opened. Terminating.");
}
static int open_driver()
{
int fd = open("/dev/binder", O_RDWR);
if (fd >= 0) {
fcntl(fd, F_SETFD, FD_CLOEXEC);
int vers = 0;
status_t result = ioctl(fd, BINDER_VERSION, &vers);
if (result == -1) {
ALOGE("Binder ioctl to obtain version failed: %s", strerror(errno));
close(fd);
fd = -1;
}
if (result != 0 || vers != BINDER_CURRENT_PROTOCOL_VERSION) {
ALOGE("Binder driver protocol does not match user space protocol!");
close(fd);
fd = -1;
}
size_t maxThreads = 15;
result = ioctl(fd, BINDER_SET_MAX_THREADS, &maxThreads);
if (result == -1) {
ALOGE("Binder ioctl to set max threads failed: %s", strerror(errno));
}
} else {
ALOGW("Opening '/dev/binder' failed: %s\n", strerror(errno));
}
return fd;
}
在ProcessState构造方法中,我们需要注意其成员变量的初始化赋值过程。成员变量mDriverFD是用于记录Binder驱动的文件描述符,其在构造函数中通过调用open_driver()被赋值。从以下open_driver()可知,其方法内部首先open()打开了/dev/binder/驱动节点,在确定Binder驱动的版本与当前native层Binder版本一致之后,通过ioctl()为当前进程设置了最大Binder线程数量为maxThreads即15。
之后则在构造方法内部通过mmap()完成对用户空间地址与内核空间地址的映射,映射地址空间大小为BINDER_VM_SIZE,从定义来看是1M-8k大小。关于mmap到底干了什么,后边讲解到Binder驱动时会详细介绍。
// frameworks/native/libs/binder/ProcessState.cpp
#define BINDER_VM_SIZE ((1*1024*1024) - (4096 *2))
由此可知,任何进程想成为Binder进程只需调用ProcessState单例即可。
管理BpBinder
除上述为进程进行Binder相关的初始化之外,ProcessState还有两个重要的功能:1. 管理各个Binder Server在此进程中的代理BpBinder;2. 可为进程开启一个默认的主Binder线程PoolThread。
先来说第一条,管理BpBinder。
在ProcessState中有个成员变量mHandleToObject,各个Binder Server在当前进程的代理BpBinder(handle)都会以handle_entry的形式被添加进这个向量表中。
// frameworks/native/include/binder/ProcessState.h
class ProcessState : public virtual RefBase{
//...
struct handle_entry {
IBinder* binder;//实质上是BpBinder(handle)。
RefBase::weakref_type* refs;
};
Vector<handle_entry>mHandleToObject;//向量表,负责保存各个代理实体
//...
}
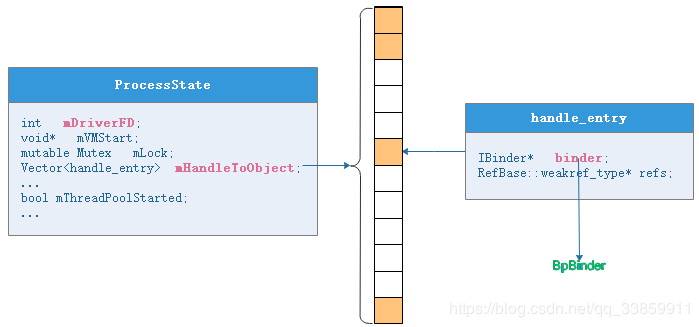
之前我们在讲述ServiceManagerProxy时说到其mRemote变量是由BinderInternal.getContextObject()通过jni的方式最终调用到ProcessState::self()->getContextObject(NULL)获取,这个 mRemote其实质上就是BpBinder(0)。
// frameworks/native/libs/binder/ProcessState.cpp
sp<IBinder> ProcessState::getContextObject(const sp<IBinder>& /*caller*/)
{
//获取svm,其handle=0
return getStrongProxyForHandle(0);
}
sp<IBinder> ProcessState::getStrongProxyForHandle(int32_t handle)
{
sp<IBinder> result;
AutoMutex _l(mLock);
//本地向量表中查询对应handle值的binder server,根据方法内部来看,其未找到则自动添加entry占位
//所以此处必有返回值!=null
handle_entry* e = lookupHandleLocked(handle);
if (e != NULL) {
IBinder* b = e->binder;
if (b == NULL || !e->refs->attemptIncWeak(this)) {
//handle=0应该是ServiceManager
//...
//每个代理都理解为一个BpBinder
b = new BpBinder(handle);
e->binder = b;//同时把代理存放在进程向量表中
if (b) e->refs = b->getWeakRefs();
result = b;
} else {
result.force_set(b);
e->refs->decWeak(this);
}
}
return result;
}
ProcessState::handle_entry* ProcessState::lookupHandleLocked(int32_t handle)
{
//从此处可见,handle,如果在mHandleToObject中没找到,则insert进去(包括之前没有的index)
//并且handle与向量表中的下角标呈对应关系
const size_t N=mHandleToObject.size();
if (N <= (size_t)handle) {
handle_entry e;
e.binder = NULL;
e.refs = NULL;
//insertAt(const TYPE& item, size_t index, size_t numItems)
status_t err = mHandleToObject.insertAt(e, N, handle+1-N);
if (err < NO_ERROR) return NULL;
}
return &mHandleToObject.editItemAt(handle);
}
在getStrongProxyForHandle()会首先调用lookupHandleLocked()方法根据handle值从上述的BpBinder管理者即向量表mHandleToObject中寻找是否已存在对应的handle_entry(此结构体中保存有对应handle的BpBinder),如果不存在则直接创建一个新的handle_entry插入到向量表对应角标(handle)位置(这种找不到就创建的思想我们会在Binder驱动中多次见到),其插入是通过向量表的insertAt()方法完成的,这种插入方式有个特点,如其插入的角标位置大于当前向量的size,则会在size至插入角标中间插入若干占位元素,以保证handle值就对应向量表的index角标。
那么除了ServiceManagerProxy我们可以清晰见到其通过getStrongProxyForHandle()获取BpBinder之外,ProcessState又如何管理其他Binder Server代理对应的BpBinder的呢?答案就在Parcel类中的readStrongBinder()/readWeakBinder()中。
我们知道,无论是java层的ServiceManagerProxy或native层的BpServiceManager,通过getService()获取在servicemanager进程管理的Binder Server引用时,都需要通过Parcel的readStrongBinder()/readWeakBinder()把这个Binder Server(实质上只是其代理)读取出来才能使用,而且不光是实名Binder Server获取是这样,我们通常通过AIDL方式构建的那种匿名Binder Server同样如此,也需要通过read方式读出Binder引用才能使用。而这里所说的readStrongBinder/readWeakBinder中除了取出Binder服务代理之外还别有乾坤。
// frameworks/native/libs/binder/Parcel.cpp
sp<IBinder> Parcel::readStrongBinder() const
{
sp<IBinder> val;
unflatten_binder(ProcessState::self(), *this, &val);
return val;
}
wp<IBinder> Parcel::readWeakBinder() const
{
wp<IBinder> val;
unflatten_binder(ProcessState::self(), *this, &val);
return val;
}
在readStrongBinder()/readWeakBinder()中,因传输需要被flat的Binder实体/Binder引用(两者形式都为即flat_binder_object)在这两方法中被重新unflat。
通过上边的代码中可见Binder Client对Binder的读取具体是通过unflatten_binder()方法完成的,那么我们有必要进去一探究竟。
// frameworks/native/libs/binder/Parcel.cpp
status_t unflatten_binder(const sp<ProcessState>& proc,
const Parcel& in, sp<IBinder>* out)
{
const flat_binder_object* flat = in.readObject(false);//从Parcel读取数据
if (flat) {
switch (flat->type) {
case BINDER_TYPE_BINDER://本进程内
*out = reinterpret_cast<IBinder*>(flat->cookie);
return finish_unflatten_binder(NULL, *flat, in);
case BINDER_TYPE_HANDLE://跨进程
//重点
*out = proc->getStrongProxyForHandle(flat->handle);
return finish_unflatten_binder(
static_cast<BpBinder*>(out->get()), *flat, in);
}
}
return BAD_TYPE;
}
在unflatten_binder()方法中出现的flat_binder_object中type值的含义如下:
| BINDER_TYPE_BINDER BINDER_TYPE_WEAK_BINDER |
表示传输的是binder实体,区分为强类型与弱类型 |
| BINDER_TYPE_HANDLE BINDER_TYPE_WEAK_HANDLE |
表示传输的是binder引用,区分为强类型与弱类型 |
| BINDER_TYPE_FD | 表示传输的是文件描述符 |
在上边flat_binder_object的type含义中,标识binder实体的只在Binder Server进程内传输,标识binder引用的部分则是跨进程传输。对于我们的flat_binder_object来说,如果是进程内使用则其在cookie域存放了BBinder,而对于跨进程传输来说则在其handle域存放用于跨进程的handle值(ip地址)。在上边unflatten_binder()方法中不难发现,如果是跨进程的形式,则会通过ProcessState的getStrongProxyForHandle()方法创建一个BpBinder(handle)。这个创建的BpBinder就被自然而然的保存在了ProcessState中的mHandleToObject向量表中了,进而来说ProcessState就通过此向量表就完成了对BpBinder的管理。
开启binder主线程
再说第二条,ProcessState可为进程开启一个默认的主Binder线程PoolThread。
java进程是通过Zygote进程fork出来的,这个新fork出来的进程会调用到app_main.cpp中的onZygoteInit()方法,而其中就通过ProcessState启动了一个binder线程专门为IPC服务。这也就是说,java进程天生就可以使用Binder机制。
// frameworks/base/cmds/app_process/app_main.cpp
virtual void onZygoteInit()
{
// Re-enable tracing now that we're no longer in Zygote.
atrace_set_tracing_enabled(true);
sp<ProcessState> proc = ProcessState::self();
ALOGV("App process: starting thread pool.\n");
proc->startThreadPool();
}
同样的,如以下代码中Android音频系统启动时,同样启动至少一个binder线程。
// frameworks/av/media/mediaserver/main_mediaserver.cpp
int main(int argc __unused, char** argv)
{
signal(SIGPIPE, SIG_IGN);
char value[PROPERTY_VALUE_MAX];
bool doLog = (property_get("ro.test_harness", value, "0") > 0) && (atoi(value) == 1);
pid_t childPid;
if (doLog && (childPid = fork()) != 0) {
strcpy(argv[0], "media.log");
sp<ProcessState> proc(ProcessState::self());
MediaLogService::instantiate();
ProcessState::self()->startThreadPool();
for (;;) {
siginfo_t info;
int ret = waitid(P_PID, childPid, &info, WEXITED | WSTOPPED | WCONTINUED);
//...
}
} else {
//...
sp<ProcessState> proc(ProcessState::self());
sp<IServiceManager> sm = defaultServiceManager();
ALOGI("ServiceManager: %p", sm.get());
AudioFlinger::instantiate();
MediaPlayerService::instantiate();
CameraService::instantiate();
AudioPolicyService::instantiate();
SoundTriggerHwService::instantiate();
registerExtensions();
ProcessState::self()->startThreadPool();
IPCThreadState::self()->joinThreadPool();
}
}
上述代码中为线程默认启动一个binder线程是通过ProcessState的startThreadPool()方法完成的。我们可以进入此方法看看:
void ProcessState::startThreadPool()
{
AutoMutex _l(mLock);
if (!mThreadPoolStarted) {
mThreadPoolStarted = true;
spawnPooledThread(true);
}
}
void ProcessState::spawnPooledThread(bool isMain)
{
if (mThreadPoolStarted) {
String8 name = makeBinderThreadName();
ALOGV("Spawning new pooled thread, name=%s\n", name.string());
sp<Thread> t = new PoolThread(isMain);
t->run(name.string());
}
}
可以看出,多次调用ProcessState的startThreadPool()并非每次都会开启一个binder线程,方法内部使用mThreadPoolStarted变量记录binder线程是否开启,只有mThreadPoolStarted为false时才会进入if语句中调用spawnPooledThread(true)为当前进程创建一个main Binder线程,被创建的这个主binder线程就是PoolThread。
// frameworks/native/libs/binder/ProcessState.cpp
class PoolThread : public Thread
{
//PoolThread父类的定义位于 system/core/libutils/Threads.cpp中
//Threads同java线程一样,其run方法标识线程开始运转,在run中会调用_threadLoop()进入循环,直到threadLoop返回值为false时退出循环。
public:
PoolThread(bool isMain)
: mIsMain(isMain)
{
}
//注:_threadLoop()与threadLoop()方法在Threads.cpp中并非同一方法。前者内部调用后者。
protected:
virtual bool threadLoop()
{
//IPCThreadState代表当前线程,joinThreadPool()则表示当前所在线程进入循环读取中。
IPCThreadState::self()->joinThreadPool(mIsMain);
return false;
}
const bool mIsMain;
};
在PoolThread中,threadLoop()方法返回false表示此方法只执行一次,那么这个binder线程又是如何进入循环的呢?答案就在IPCThreadState的joinThreadPool()方法中,joinThreadPool()方法内部是循环操作的,这里暂且不展开表述。同时从mIsMain=true来看当前通过startThreadPool()启动的binder线程是binder主线程。
transact到onTransact
在java层,当我们从servicemanager进程获取Binder Server服务时最终需要调用ServiceManagerProxy的getService()方法。
// frameworks/base/core/java/android/os/ServiceManagerNative.java
public IBinder getService(String name) throws RemoteException {
Parcel data = Parcel.obtain();
Parcel reply = Parcel.obtain();
data.writeInterfaceToken(IServiceManager.descriptor);
data.writeString(name);
mRemote.transact(GET_SERVICE_TRANSACTION, data, reply, 0);
IBinder binder = reply.readStrongBinder();
reply.recycle();
data.recycle();
return binder;
}
在getService()方法中通过mRemote的transact()方法进行真正的进程间通信,transact()方法拥有四个参数:
- 第一个参数code,int类型,用于标识当次操作的业务码。
- 第二个参数data,Parcel类型,其内部保存当次操作的数据内容。
- 第三个参数reply,Parcel类型,用于保存当次操作的返回结果,可在transact之后对此进行解析。
- 第四个参数flags,int类型,用于标识当次操作的类型。可填入的flags值及含义如以下:
| transaction操作类型 | 值 | 含义 |
|---|---|---|
| TF_ONE_WAY | 0x01 | 标识当前操作一去不复返,不用等待返回结果,属于非阻塞式调用 |
| TF_ROOT_OBJECT | 0x04 | 未知 |
| TF_STATUS_CODE | 0x08 | 表明当次操作返回的是无效数据 |
| TF_ACCEPT_FDS | 0x10 | 表示当次操作可以接受返回结果包含文件描述符 |
| 未定义 | 0x00 | 表示当次操作是阻塞式调用,需等待返回结果,与TF_ONE_WAY相反 |
之前我们有提过这个真正进行进程间通信的mRemote实质上是BpBinder,但是BpBinder终究是个C++类,我们只有先弄清楚mRemote在java层是什么才能明白其调用流程。我们知道java层的ServiceManagerProxy中的mRemote是通过BinderInternal.getContextObject()获取到的,前面亦有分析,我们这里只贴下其通过jni调用到native层的方法。
// frameworks/base/core/jni/android_util_Binder.cpp
static jobject android_os_BinderInternal_getContextObject(JNIEnv* env, jobject clazz)
{ //返回new BpBinder(0)。
sp<IBinder> b = ProcessState::self()->getContextObject(NULL);
return javaObjectForIBinder(env, b);
}
从这个jni方法可以看到,在通过getContextObject()获取到BpBinder后,BpBinder转换为java层对象是由javaObjectForIBinder()方法完成的。
在介绍javaObjectForIBinder方法之前,需要先说明下android_util_Binder.cpp中的gBinderProxyOffsets全局变量与java类BinderProxy的神秘联系。
gBinderProxyOffsets是native层用于标识java层代理的结构体,根据此结构体可轻易的构建于对应于native层BpBinder的java层代理对象。
// frameworks/base/core/jni/android_util_Binder.cpp
static struct binderproxy_offsets_t
{
jclass mClass;//对应java类,此处为BinderProxy
jmethodID mConstructor;//对应构造方法
jmethodID mSendDeathNotice;//标识java层方法,据此往java层传递讣告消息
jfieldID mObject;//对应java层BinderProxy成员变量,用于存放BinderProxy对应的native层BpBinder
jfieldID mSelf;//对应java层BinderProxy的成员变量mSelf,主要为BpBinder获取BinderProxy提供依据
jfieldID mOrgue;//对应java层BinderProxy成员变量,用于保存讣告列表
} gBinderProxyOffsets;
gBinderProxyOffsets在jni注册方法int_register_android_os_BinderProxy()中被赋值。在下边代码中,kBinderProxyPathName正是java类BinderProxy。
// frameworks/base/core/jni/android_util_Binder.cpp
const char* const kBinderProxyPathName = "android/os/BinderProxy";
static int int_register_android_os_BinderProxy(JNIEnv* env)
{
jclass clazz;
//...
clazz = env->FindClass(kBinderProxyPathName);//BinderProxy
gBinderProxyOffsets.mClass = (jclass) env->NewGlobalRef(clazz);
//使用 作为方法名,同时将 void (V) 作为返回类型,如果找不到指定的ID将返回NULL
gBinderProxyOffsets.mConstructor
= env->GetMethodID(clazz, "" , "()V");
gBinderProxyOffsets.mSendDeathNotice
= env->GetStaticMethodID(clazz, "sendDeathNotice", "(Landroid/os/IBinder$DeathRecipient;)V");
gBinderProxyOffsets.mObject
= env->GetFieldID(clazz, "mObject", "J");
gBinderProxyOffsets.mSelf
= env->GetFieldID(clazz, "mSelf", "Ljava/lang/ref/WeakReference;");
gBinderProxyOffsets.mOrgue
= env->GetFieldID(clazz, "mOrgue", "J");
//...
}
BinderProxy与BpBinder内部都有对方指针,两者为一对一关系。
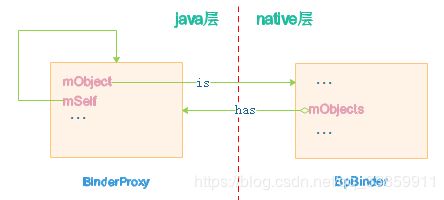
在了解了gBinderProxyOffsets结构体对应变量的含义之后,接下来就回到我们的native层BpBinder转java层BinderProxy的关键方法javaObjectForIBinder()中,方法代码如下:
// frameworks/base/core/jni/android_util_Binder.cpp
jobject javaObjectForIBinder(JNIEnv* env, const sp<IBinder>& val)
{
if (val == NULL) return NULL;
//说明是JavaBBinder,Binder Server进程内
if (val->checkSubclass(&gBinderOffsets)) {
jobject object = static_cast<JavaBBinder*>(val.get())->object();
return object;
}
//...
jobject object = (jobject)val->findObject(&gBinderProxyOffsets);
if (object != NULL) {
jobject res = jniGetReferent(env, object);
if (res != NULL) {
return res;
}
android_atomic_dec(&gNumProxyRefs);
val->detachObject(&gBinderProxyOffsets);//BpBinder取消与BinderProxy关联
env->DeleteGlobalRef(object);
}
//创建一个java层的BinderProxy对象
object = env->NewObject(gBinderProxyOffsets.mClass, gBinderProxyOffsets.mConstructor);
if (object != NULL) {
//为java层BinderProxy的mObject赋值
env->SetLongField(object, gBinderProxyOffsets.mObject, (jlong)val.get());
val->incStrong((void*)javaObjectForIBinder);//引用计数加一
//在Java层BinderProxy创建时其mSelf变量就被赋值为自身的弱引用。
jobject refObject = env->NewGlobalRef(
env->GetObjectField(object, gBinderProxyOffsets.mSelf));
//此处取出java层mSelf将其赋值给BpBinder内部的ObjectManager中。
val->attachObject(&gBinderProxyOffsets, refObject,
jnienv_to_javavm(env), proxy_cleanup);
//将native层的讣告列表地址赋值给BinderProxy
sp<DeathRecipientList> drl = new DeathRecipientList;
drl->incStrong((void*)javaObjectForIBinder);
env->SetLongField(object, gBinderProxyOffsets.mOrgue, reinterpret_cast<jlong>(drl.get()));
android_atomic_inc(&gNumProxyRefs);//进程BinderProxy对象计数增加
incRefsCreated(env);
}
return object;
}
javaObjectForIBinder()内部先通过checkSubclass()方法判断当前要转换成java对象的IBinder是JavaBBinder(Binder Server进程)还是BpBinder(Binder Client进程),因为checkSubclass()方法默认返回false,且只有JavaBBinder有重写checkSubclass()。因此如果当前实在Binder Server自身进程内获取自身IBinder,那么得到的就是java层Binder Server对应于native层的JavaBBinder,反之,如大多数情况那样当前是Binder Client进程的话则继续沿着javaObjectForIBinder()内部往下走。接下来则试图调用BpBinder的findObject()从BpBinder内部的对象管理者(ObjectManager)中找出对应java层BinderProxy对象的引用,如未找到则主动创建java对象BinderProxy并通过attachObject()将这个对象地址添加到BpBinder内部的mObjects(即对象管理者)中。当然,在这个过程中也完成了上图所示的BpBinder与BinderProxy的绑定关系。
不光BinderInternal.getContextObject()得到的是BinderProxy,Parcel的readStrongBinder()同样如此。
// frameworks/base/core/jni/android_os_Parcel.cpp
static jobject android_os_Parcel_readStrongBinder(JNIEnv* env, jclass clazz, jlong nativePtr)
{
Parcel* parcel = reinterpret_cast<Parcel*>(nativePtr);
if (parcel != NULL) {
//前边已经解释过,native的parcel的readXXXBinder得到的是BpBinder
return javaObjectForIBinder(env, parcel->readStrongBinder());
}
return NULL;
}
显而易见,最后返回到java层的并非直接是BpBinder,而是BinderProxy,也就是说java层的binder服务Proxy中的mRemote成员对应为BinderProxy对象。当然,如果在深入研究下的话你会发现BinderProxy的所有native方法最终都会调用到BpBinder中,这也正是上述我们展示两者的关系决定的。这里就不细看BinderProxy的native方法了。
回到本小节最开始的时候getService()方法内部的mRemote在此处我们应已有答案,其正是通过javaObjectForIBinder()方法把native层的BpBinder“转换”成的java层的BinderProxy,mRemote.transact()实质上就是调用BinderProxy对象的transact()方法。接下来我们就可以据此从进一步查看getService()方法的方法链。
// frameworks/base/core/java/android/os/Binder#BinderProxy.java
public boolean transact(int code, Parcel data, Parcel reply, int flags) throws RemoteException {
Binder.checkParcel(this, code, data, "Unreasonably large binder buffer");
return transactNative(code, data, reply, flags);
}
public native boolean transactNative(int code, Parcel data, Parcel reply,
int flags) throws RemoteException
可以看到transact内部调用了transactNative()方法。java类BinderProxy的jni方法注册之前已有提到,是在register_android_os_Binder()中完成的,自然transactNative()也是如此。
static const JNINativeMethod gBinderProxyMethods[] = {
//...
{"transactNative", "(ILandroid/os/Parcel;Landroid/os/Parcel;I)Z", (void*)android_os_BinderProxy_transact},
//...
};
const char* const kBinderProxyPathName = "android/os/BinderProxy";
static jboolean android_os_BinderProxy_transact(JNIEnv* env, jobject obj,
jint code, jobject dataObj, jobject replyObj, jint flags) // throws RemoteException
{
//...
//把相应的java层Parcel对象转成native层的Parcel对象
Parcel* data = parcelForJavaObject(env, dataObj);
if (data == NULL) {
return JNI_FALSE;
}
//把相应的java层Parcel对象转成native层的Parcel对象
Parcel* reply = parcelForJavaObject(env, replyObj);
if (reply == NULL && replyObj != NULL) {
return JNI_FALSE;
}
//取出BinderProxy中的mObject,mObject是native指针,指向的是BinderProxy对应的native层BpBinder
IBinder* target = (IBinder*)
env->GetLongField(obj, gBinderProxyOffsets.mObject);
//...
status_t err = target->transact(code, *data, reply, flags);
//...
}
根据javaObjectForIBinder()方法中对BinderProxy的mObject赋值来看,mObject指向的是native层的BpBinder。所以在上边代码中通过getLongField()取出的target即对应的BpBinder,同时我们注意到java层的BinderProxy的transact()方法层层调用最终调用了BpBinder的transact()方法。
// frameworks/native/libs/binder/BpBinder.cpp
//java层调用的mRemote.transact会进入此处
status_t BpBinder::transact(
uint32_t code, const Parcel& data, Parcel* reply, uint32_t flags)
{
if (mAlive) {
//可见最终都进入到各自线程的transact中
status_t status = IPCThreadState::self()->transact(
mHandle, code, data, reply, flags);
//如果BpBinder标识的server没有回复,则说明server已经dead,此刻需把BpBinder标识为不可用即mAlive=0
if (status == DEAD_OBJECT) mAlive = 0;
return status;
}
return DEAD_OBJECT;
}
IPCThreadState属线程单例,其负责与Binder驱动进行具体的命令交互,此处我们需要注意,在从BpBinder的transact()方法内调用IPCThreadState的transact()时把BpBinder所代表Binder Server的mHandle值(ip地址)也作为传输过去了。
IPCThreadState负责与Binder驱动进行实质上的交互,其依存于Thread线程并保存了当前线程的IPC通信状态及IPC通信数据。与ProcessState为进程单例对应的是IPCThreadState属于线程单例,其单例实现是通过linux线程局部存储即TLS完成。这种TLS技术依赖于以下三个方法调用实现。
- int pthread_key_create (pthread_key_t *key, void (*destructor)(void *));第一个参数是为线程局部数据而创建的键,之后可通过此键存放这些线程局部数据,第二个参数是清理函数,用于当前线程释放对应键时进行的清理操作。
- int pthread_setspecific (pthread_key_t key, const void *value);用于存放对应键的局部数据。
- void *pthread_getspecific (pthread_key_t key);根据键取出对应的线程局部变量。
IPCThreadState一般通过self()获取,而self内部正是单例的实现过程,具体如下:
// frameworks/native/libs/binder/IPCThreadState.cpp
IPCThreadState* IPCThreadState::self()
{
//使用关键字gTLS查询TLS中有无IPCThreadState,如无,则创建
if (gHaveTLS) {
restart:
const pthread_key_t k = gTLS;
IPCThreadState* st = (IPCThreadState*)pthread_getspecific(k);
if (st) return st;
return new IPCThreadState;
}
if (gShutdown) return NULL;
pthread_mutex_lock(&gTLSMutex);
if (!gHaveTLS) {
if (pthread_key_create(&gTLS, threadDestructor) != 0) {
pthread_mutex_unlock(&gTLSMutex);
return NULL;
}
gHaveTLS = true;
}
pthread_mutex_unlock(&gTLSMutex);
goto restart;
}
IPCThreadState::IPCThreadState()
: mProcess(ProcessState::self()),//主要为了获取ProcessState中的mDriverFD
mMyThreadId(androidGetTid()),//线程号
mStrictModePolicy(0),
mLastTransactionBinderFlags(0)
{
pthread_setspecific(gTLS, this);//把当前实例设置给TLS
clearCaller();//记录当前pid及uid
mIn.setDataCapacity(256);//设置当前线程IPC读区域容量
mOut.setDataCapacity(256);//设置当前线程IPC写区域容量
}
在上述代码中,如果是首次调用self(),则gHaveTLS变量为false,所以先走的self()内部代码后半段以创建键gTLS并指明清理函数为threadDestructor(),随后通过goto跳转至self()前半段代码中尝试获取键gTLS对应的线程局部数据即IPCThreadState本身,若获取失败则调用其构造函数并在其构造函数中通过pthread_setspecific()把自身保存到键gTLS对应的共享区域中。
IPCThreadState构造方法中mIn和mOut是当前线程进行IPC通信时的数据读写区域。具体而言,mIn用于接收IPC数据即ioctl中的binder_write_read结构体中read部分,而mOut则用于存放当前线程需要传输给其他进程的数据,以便在与Binder驱动交互时存放到ioctl()中的binder_write_read的write部分中去。
在了解了IPCThreadState的单例实现之后,我们接着来看上边BpBinder的transact()调用到的IPCThreadState的transact()的过程。

// frameworks/native/libs/binder/IPCThreadState.cpp
status_t IPCThreadState::transact(int32_t handle,
uint32_t code, const Parcel& data,
Parcel* reply, uint32_t flags)
{
status_t err = data.errorCheck();
//通知Binder Server当前进程可接收文件描述符
flags |= TF_ACCEPT_FDS;
if (err == NO_ERROR) {
//把binder数据data和cmd写入到mOut中
err = writeTransactionData(BC_TRANSACTION, flags, handle, code, data, NULL);
}
//...
//if 当前非ONE_WAY
if ((flags & TF_ONE_WAY) == 0) {
if (reply) {
err = waitForResponse(reply);
} else {
Parcel fakeReply;
err = waitForResponse(&fakeReply);
}
//...
} else {
err = waitForResponse(NULL, NULL);
}
return err;
}
在IPCThreadState的transact()方法中,我们可以看到其首先修改flags以通知通信的target进程此次通信可接收文件描述符FileDescriptor,此后通过writeTransactionData()把我们需要传输的Parcel数据填充到binder_transact_data中,此处需要注意此方法填入的BINDER_WRITE_READ子命令是BC_TRANSACTION(之前已言明BCTRANSACTION是通信发起端字段,在binder驱动层会转换为BR_TRANSACTION),然后通过判断此次通信的类型是否为TF_ONE_WAY(是否阻塞式调用,one way表示非阻塞式),如果是阻塞式调用,则此次通信返回结果会在reply中体现,当然我们应该也已注意到如果阻塞式调用情况下transact()调用者并没有填入reply时,transact()内部为保证通信完整性构建了fakeReply即假的reply以供填入通信结果。不管是否是阻塞式调用,transact()最终都调用了waitForResponse()来进行此次通信。
// frameworks/native/libs/binder/IPCThreadState.cpp
status_t IPCThreadState::waitForResponse(Parcel *reply, status_t *acquireResult)
{
int32_t cmd;
int32_t err;
while (1) {
//在与binder驱动通信的过程中不仅有写入操作,而且会读取数据
if ((err=talkWithDriver()) < NO_ERROR) break;
err = mIn.errorCheck();
if (err < NO_ERROR) break;
if (mIn.dataAvail() == 0) continue;
//读取指令
cmd = mIn.readInt32();
switch (cmd) {
case BR_TRANSACTION_COMPLETE:
if (!reply && !acquireResult) goto finish;
break;
case BR_DEAD_REPLY:
err = DEAD_OBJECT;
goto finish;
case BR_FAILED_REPLY:
err = FAILED_TRANSACTION;
goto finish;
case BR_ACQUIRE_RESULT:
{
ALOG_ASSERT(acquireResult != NULL, "Unexpected brACQUIRE_RESULT");
const int32_t result = mIn.readInt32();
if (!acquireResult) continue;
*acquireResult = result ? NO_ERROR : INVALID_OPERATION;
}
goto finish;
case BR_REPLY:{//解析返回结果
binder_transaction_data tr;
err = mIn.read(&tr, sizeof(tr));
ALOG_ASSERT(err == NO_ERROR, "Not enough command data for brREPLY");
if (err != NO_ERROR) goto finish;
//如果需要获取reply
if (reply) {
//如果flags包含TF_STATUS_CODE则表明tr是无效的返回数据,server端执行失败
if ((tr.flags & TF_STATUS_CODE) == 0) {
//设置返回数据到reply中
reply->ipcSetDataReference(
reinterpret_cast<const uint8_t*>(tr.data.ptr.buffer),
tr.data_size,
reinterpret_cast<const binder_size_t*>(tr.data.ptr.offsets),
tr.offsets_size/sizeof(binder_size_t),
freeBuffer, this);
} else {
err = *reinterpret_cast<const status_t*>(tr.data.ptr.buffer);
freeBuffer(NULL,
reinterpret_cast<const uint8_t*>(tr.data.ptr.buffer),
tr.data_size,
reinterpret_cast<const binder_size_t*>(tr.data.ptr.offsets),
tr.offsets_size/sizeof(binder_size_t), this);
}
} else {//不需要获取reply,则释放相应内存
freeBuffer(NULL,
reinterpret_cast<const uint8_t*>(tr.data.ptr.buffer),
tr.data_size,
reinterpret_cast<const binder_size_t*>(tr.data.ptr.offsets),
tr.offsets_size/sizeof(binder_size_t), this);
continue;
}
}
goto finish;
default:
err = executeCommand(cmd);
if (err != NO_ERROR) goto finish;
break;
}
}
finish:
//...
return err;
}
talkWithDriver()真正与Binder驱动进行通信,其把我们想要传输的数据mOut/mIn包装到binder_write_read的buffer中通过系统调用ioctl()传给Binder驱动,因代码比较简单,这就不贴了。
在waitForResponse()中我们可以看见其是循环调用,那么站在Binder Client的角度(BpBinder)来看,其又是如何退出循环以结束此次IPCThreadState的transact()调用呢?如果是one way式通信则binder驱动层会返回BR_TRANSACTION_COMPLETE告知此次通信结束,而非one way式的通信则挂起当前线程等待目标进程处理结果,返回结果可以是处理失败BR_FAILED_REPLY,也可以是目标进程已退出BR_DEAD_REPLY,也可以是正常返回BR_REPLY,这些情况都会通过goto语句跳出此次循环。当情况为正常返回时,也可区分为返回无效结果和有效结果,如是有效结果则通过ipcSetDataReference()方法填充结果到reply中以返给调用者。
以上就是Binder Client调用transact()向Binder Server传输数据的过程。但万里长征只走完了开始部分,下边我们暂且略过繁杂的Binder驱动部分先跳到Binder Server来解答服务端是如何接收传过来的通信数据及如何返回结果的。
Binder Server作为服务端,须有专有的binder线程来处理进程间的binder通信。就实现上来看,可以通过ProcessState的startThreadPool()方法启动一个binder主线程,也可以通过IPCThreadState的joinThreadPool()来启动一个binder线程来专门处理通信。从根本上而言startThreadPool()最终也是调用到IPCThreadState的joinThreadPool()来完成binder线程的启动。
// frameworks/native/libs/binder/IPCThreadState.cpp
//参数标识是否binder主线程,如果通过startThreadPool则参数是true
void IPCThreadState::joinThreadPool(bool isMain)
{
//是否主线程,注册的LOOPER状态不一致,在首次talkWithDriver时传输
mOut.writeInt32(isMain ? BC_ENTER_LOOPER : BC_REGISTER_LOOPER);
//让线程成为前台线程
set_sched_policy(mMyThreadId, SP_FOREGROUND);
status_t result;
//循环执行
do {
processPendingDerefs();
// now get the next command to be processed, waiting if necessary
result = getAndExecuteCommand();
if (result < NO_ERROR && result != TIMED_OUT && result != -ECONNREFUSED && result != -EBADF) {
//abort()函数首先解除进程对SIGABRT信号的阻止,然后向调用进程发送该信号
abort();
}
if(result == TIMED_OUT && !isMain) {//非主线程或超时会退出
break;
}
} while (result != -ECONNREFUSED && result != -EBADF);
//更改LOOPER状态为退出
mOut.writeInt32(BC_EXIT_LOOPER);
talkWithDriver(false);
}
进入joinThreadPool()首先往mOut中填入BC_ENTER_LOOPER/BC_REGISTER_LOOPER以告诉binder驱动当前binder线程即将进入循环,相对应的当线程退出循环时则发送BC_EXIT_LOOPER告知binder驱动当前线程退出了循环。在joinThreadPool()中通信的主体部分是do-whlie循环中的getAndExecuteCommand()方法,上边我们Binder Client调用BpBinder的transact()最终通过binder驱动到达getAndExecuteCommand()。
// frameworks/native/libs/binder/IPCThreadState.cpp
status_t IPCThreadState::getAndExecuteCommand()
{
status_t result;
int32_t cmd;
//内部包含系统调用方法ioctl(),其属于阻塞式
result = talkWithDriver();
if (result >= NO_ERROR) {
size_t IN = mIn.dataAvail();
if (IN < sizeof(int32_t)) return result;
cmd = mIn.readInt32();
result = executeCommand(cmd);
set_sched_policy(mMyThreadId, SP_FOREGROUND);
}
return result;
}
getAndExecuteCommand()是Binder Server真正与驱动通信的部分,其talkWithDriver()内部通过阻塞式的ioctl()来接收其他进程传递过来的binder消息,当binder消息到来时ioctl()解除阻塞,继续往下通过executeCommand()处理传递过来的binder消息。
// frameworks/native/libs/binder/IPCThreadState.cpp
status_t IPCThreadState::executeCommand(int32_t cmd)
{
BBinder* obj;
RefBase::weakref_type* refs;
status_t result = NO_ERROR;
switch (cmd) {
//...
case BR_TRANSACTION://标识接收别处的BC_TRANSATION(BC_TRANSACTION经过binder驱动会被驱动改为BR_TRANSACTION)
{
binder_transaction_data tr;
result = mIn.read(&tr, sizeof(tr));
if (result != NO_ERROR) break;
Parcel buffer;
//把传过来的数据binder_transaction_data,整理到Parcel中去
buffer.ipcSetDataReference(
reinterpret_cast<const uint8_t*>(tr.data.ptr.buffer),
tr.data_size,
reinterpret_cast<const binder_size_t*>(tr.data.ptr.offsets),
tr.offsets_size/sizeof(binder_size_t), freeBuffer, this);
//...
if (tr.target.ptr) {
sp<BBinder> b((BBinder*)tr.cookie);
error = b->transact(tr.code, buffer, &reply, tr.flags);
} else {
error = the_context_object->transact(tr.code, buffer, &reply, tr.flags);
}
//非ONE_WAY,需要返回reply
if ((tr.flags & TF_ONE_WAY) == 0) {
LOG_ONEWAY("Sending reply to %d!", mCallingPid);
if (error < NO_ERROR) reply.setError(error);
sendReply(reply, 0);
} else {
LOG_ONEWAY("NOT sending reply to %d!", mCallingPid);
}
//...
}
break;
//...
case BR_SPAWN_LOOPER://binder驱动通知binder server新建一个binder线程处理消息
mProcess->spawnPooledThread(false);
break;
default:
result = UNKNOWN_ERROR;
break;
}
if (result != NO_ERROR) {
mLastError = result;
}
return result;
}
在executeCommand()中则对具体接收的cmd进行处理,抛开一些引用计数方面的cmd命令之外,最值得注意的就是BR_TRANSACTION命令了。BR_TRANSACTION命令是经过binder驱动转换后的命令,它一般由Binder Client发起(BC_TRANSACTION),经过binder驱动时被修改为BR_TRANSACTION传输给Binder Server的binder线程处理,而在上述代码的BR_TRANSACTION这个case中正是这个处理过程。可以看到其在通过ipcSetDataReference()整理出传输过来的数据后,一般情况下调用了BBinder的transact()对这些数据进行处理,处理完成后如有必要(非one way)则通过sendReply()方法把处理结果包装好后以BC_REPLY命令形式返回给Binder Client端(BC_REPLY命令经过binder驱动后会修改为BR_REPLY,这也是我们waitForResponse()中为什么非one way时可以通过BR_REPLY跳出循环的原因)。
既然binder线程处理BR_TRANSACTION最后调用到BBinder中,那么我们有必要进去一探究竟。
// frameworks/native/libs/binder/Binder.cpp
status_t BBinder::transact(
uint32_t code, const Parcel& data, Parcel* reply, uint32_t flags)
{
data.setDataPosition(0);
status_t err = NO_ERROR;
switch (code) {
case PING_TRANSACTION:
reply->writeInt32(pingBinder());
break;
default:
//onTransact方法一般会被BBinder子类复写
err = onTransact(code, data, reply, flags);
break;
}
if (reply != NULL) {
reply->setDataPosition(0);
}
return err;
}
很明显除去PING_TRANSACTION外,BBinder对应具体业务的处理都交由onTransact()来处理了,这也是为什么我们Binder Server业务类一般都要重写onTransact()方法的原因。当然如果Binder Server是java层的Binder,那么可能还要经过JavaBBinder转换到java层的onTransact()来处理。在JavaBBinder中其onTransact()方法通过jni方式调用到对应java层Binder的execTransact()方法。
// frameworks/base/core/java/android/os/Binder.java
private boolean execTransact(int code, long dataObj, long replyObj,
int flags) {
Parcel data = Parcel.obtain(dataObj);
Parcel reply = Parcel.obtain(replyObj);
//...
res = onTransact(code, data, reply, flags);
//...
return res;
}
}
至此我们应以对Binder Client到Binder Server的上层通信过程有了整体的了解。
Binder驱动
驱动加载
Binder驱动运行于内核空间,其作为设备驱动的入口函数是device_initcall(),这个函数会在linux进行子系统初始化时经由内核init进程的do_initcalls()加载。
// drivers/staging/android\binder.c
device_initcall(binder_init);
可以看到device_install()调用的初始化func为binder_init()。
// drivers/staging/android\binder.c
static struct miscdevice binder_miscdev = {
.minor = MISC_DYNAMIC_MINOR,//动态分配设备号
.name = "binder",//misc驱动文件名
.fops = &binder_fops//驱动支持的操作
};
static int __init binder_init(void)
{
int ret;
//...
ret = misc_register(&binder_miscdev);
//...
return ret;
}
因misc类型的驱动仅通过misc_register()就可实现注册,Binder内核模块通过这种注册方式为上层提供了/dev/binder的设备节点(通过misc_register()注册的驱动节点都位于dev目录下)。而binder_init()中除了把自身注册为misc杂项驱动外,也创建了一些用于binder内核调试的debug文件系统(由于篇幅关系,此处没有贴出来),这些文件位于/sys/kernel/debug/binder目录下,用以记录一些方便调试的binder运行状态信息。
misc_register在注册成为驱动时,往往需要向上层应用提供一些驱动支持的操作接口,这就是file_operations结构体。我们binder驱动支持的操作接口如下:
// drivers/staging/android\binder.c
static const struct file_operations binder_fops = {
.owner = THIS_MODULE,
.poll = binder_poll,
.unlocked_ioctl = binder_ioctl,
.compat_ioctl = binder_ioctl,
.mmap = binder_mmap,
.open = binder_open,
.flush = binder_flush,
.release = binder_release,
};
除了owner以外其余函数都对应了binder驱动支持的操作,在binder_fops中如用户空间的open方法对应到此处就是binder_open,同样的如ioctl(unlocked_ioctl/compat_ioctl与ioctl属兼容性调用方式,他两自kernel 2.6.36后被用以替换原来的ioctl)则对应到此处则是binder_ioctl,依此等等。在以上操作接口中,使用最频繁的就是binder_open、binder_mmap、binder_ioctl,上边小节中ProcessState单例创建时就通过open()和mmap()方法让自身成为binder进程,进而后续可以通过ioctl()与binder驱动进行通信。
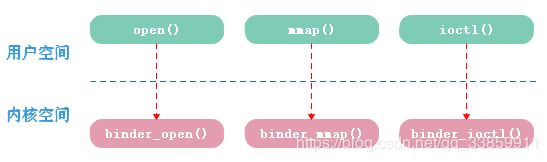
进程初始化过程
binder_open
在使用binder机制时,上层应用首先需要打开/dev/binder驱动节点进而成为binder进程后续才能发起进程间通信,对应到驱动层面来看其实就是调用binder_open()的过程。在binder_open()中我们可以看见名为binder_proc的结构体,其主要用于管理调用进程的各种IPC相关信息。以下就是binder_proc的个字段含义:
// drivers/staging/android\binder.c
struct binder_proc {
struct hlist_node proc_node;//用于标识双向链表中结点的前驱结点和后继结点
struct rb_root threads;//binder线程红黑树 节点类型---binder_thread
struct rb_root nodes;//标识当前进程中的binder server,每个binder server都与一个节点对应。类型binder_node
struct rb_root refs_by_desc;//此红黑树(以handle排序)标识当前进程中的binder引用(代理)。节点类型binder_ref
struct rb_root refs_by_node;//同上,仅排序方式不同(以节点地址排序)
int pid;//进程号
struct vm_area_struct *vma;//记载了用户空间的mmap地址区域信息
struct mm_struct *vma_vm_mm;//用户空间的mmap所指向的所属内存描述符
struct task_struct *tsk;//进程信息结构体
struct files_struct *files;//标识当前进程的文件结构体
struct hlist_node deferred_work_node;
int deferred_work;
void *buffer;//内核空间地址--起始值
ptrdiff_t user_buffer_offset;//用户空间地址与内核空间地址偏移量
struct list_head buffers;//内核空间地址链表
struct rb_root free_buffers;//记录内核中处于可用状态的buffer
struct rb_root allocated_buffers;//记录内核中已分配buffer
size_t free_async_space;//异步可以buffer大小,占总buffer大小一半
struct page **pages;/*存放物理页地址的数组*/
size_t buffer_size;//buffer虚拟地址空间大小
uint32_t buffer_free;//可用buffer区域大小
struct list_head todo;//todo链表,在binder_proc中未用到,但对于binder_thread却很重要
wait_queue_head_t wait;//wait队列,在binder_proc中未用到,但对于binder_thread却很重要
struct binder_stats stats;//cmd指令统计
struct list_head delivered_death;//proc所代表的进程dead时的通知列表
int max_threads;//当前进程所允许的最大binder线程数量
int requested_threads;//当前正在启动的binder线程数量
int requested_threads_started;//当前进程中已经成为binder线程的数量
int ready_threads;//当前处于准备状态的binder线程数量,处于此状态的线程可被唤醒处理binder任务
long default_priority;//进程调用使用,标识当前默认进程的nice值,范围[-20,19]
struct dentry *debugfs_entry;//debug文件系统信息实体,位于sys/kernel/debug/binder/proc/进程号,用于调试
};
binder_open()方法原则上进程应只调用一次,其主要是对上边binder_proc结构体进行初始化。其代码如下:
// drivers/staging/android\binder.c
//一般在ProcessState.cpp中会打开binder驱动,即调用此方法
static int binder_open(struct inode *nodp, struct file *filp)
{
struct binder_proc *proc;
//...
proc = kzalloc(sizeof(*proc), GFP_KERNEL);//分配proc空间
if (proc == NULL)//内存不足
return -ENOMEM;
get_task_struct(current);
proc->tsk = current;
INIT_LIST_HEAD(&proc->todo);//初始化todo列表
init_waitqueue_head(&proc->wait);//初始化等待队列
proc->default_priority = task_nice(current);
binder_lock(__func__);
binder_stats_created(BINDER_STAT_PROC);//proc数量++
hlist_add_head(&proc->proc_node, &binder_procs);//加到binder_procs的表头,hlist---哈希双向链表
proc->pid = current->group_leader->pid;//进程id
INIT_LIST_HEAD(&proc->delivered_death);//初始化proc所代表的进程dead时的通知列表
filp->private_data = proc;//文件指针存放proc信息
binder_unlock(__func__);
//...
return 0;
}
在binder驱动进程中我们有一个全局存在的HLIST_HEAD(binder_procs) ,它本质上是一个双向链表,用来保存各个进程打开驱动节点即binder_open()时生成的binder_proc。我们可以注意到binder_proc结构体中第一个字段proc_node,它是hlist_node类型,作用就是用来描述自身在这个全局双向链表binder_procs中的位置关系。在上边代码中我们亦可看见被创建的binder_proc通过hlist_add_head()被添加到了双向链表的头部。

同时我们注意到在binder_open()方法的最后,创建的binder_proc被保存到了filp的private_data域中。这样每次上层应用通过系统调用调到的binder驱动方法都可以从这个域中获取binder_proc,从而可以获取调用进程的IPC消息。
binder_proc除了proc_node这个域外还有四个非常重要的域。
threads域用于管理binder线程,这个域中每个节点binder_thread都对应上层应用一个binder线程。
nodes域则则管理进程中各个提供不同服务的Binder Server,每个nodes节点binder_node都对应上层应用的一个BBinder。
refs_by_desc和refs_by_node两个域节点类型、数量一致,每个节点binder_ref都对应上层应用中的一个BpBinder,只不过排序方式不同,前者以handle值排序,多用于当需要新增binder引用时从binder驱动内部来寻找当前refs_by_desc中最大handle以便给这个新增的binder引用分配handle值;而后者则以ptr地址排序,多用于binder驱动中常规寻找binder_ref。
binder_mmap
上层应用的mmap()操作对应到Binder驱动中就是binder_mmap()方法,它是进程初始化的一部分,主要通过虚拟内存映射以完成进程用户空间部分区域地址与内核空间区域地址的关联。
// drivers/staging/android\binder.c#binder_mmap
static int binder_mmap(struct file *filp, struct vm_area_struct *vma)
{
int ret;
struct vm_struct *area;
//取出binder_open存放的proc
struct binder_proc *proc = filp->private_data;
const char *failure_string;
struct binder_buffer *buffer;
在binder_mmap()中我们可以从filp中取出在binder_open()时存放到private_data域中的binder_proc。而参数vma则描述了供上层应用使用的一块虚拟内存,在这个结构体中vma->vm_start表示了这块虚拟内存的起始地址,相应的vma->vm_end描述了这块内存的结束地址。
// drivers/staging/android\binder.c#binder_mmap
//current标识当前进程,且在binder_open中已经往proc的tsk中存放了current信息,所以在此处鉴权
if (proc->tsk != current)
return -EINVAL;
//最多允许的映射内存大小不能大于4M
if ((vma->vm_end - vma->vm_start) > SZ_4M)
vma->vm_end = vma->vm_start + SZ_4M;
同时在binder驱动中,通过mmap()发起的地址映射大小不应该超过4M大小,因此如果vma中起始地址与结束地址之差不应大于这个值。当然,在上层应用中已经在mmap时定义好了这个范围为1M-8K大小。
// frameworks/native/libs/binder/ProcessState.cpp
#define BINDER_VM_SIZE ((1*1024*1024) - (4096 *2))
我们使用binder机制时传输的数据量从Binder驱动来看是不能大于4M的,甚至都不能大于上层应用定义好的1M-8K大小。正因此,凡是涉及到Binder的地方像Bitmap等是不适合用来传输的。
// drivers/staging/android\binder.c#binder_mmap
//检查vma是否禁止mmap
if (vma->vm_flags & FORBIDDEN_MMAP_FLAGS) {
ret = -EPERM;
failure_string = "bad vm_flags";
goto err_bad_arg;
}
//声明vma不能复制,不能写入
vma->vm_flags = (vma->vm_flags | VM_DONTCOPY) & ~VM_MAYWRITE;
mutex_lock(&binder_mmap_lock);
//当前进程已经mmap过,此次mmap失败
if (proc->buffer) {
ret = -EBUSY;
failure_string = "already mapped";
goto err_already_mapped;
}
接着判断当前是否已经禁用mmp,或者进程此前已经mmap过。如果已经mmap()则会在当前进程的binder_proc的buffer域保存有相对于内核空间的映射起始地址。
// drivers/staging/android\binder.c#binder_mmap
//在内核虚拟映射区域保留vm_end - vm_start大小的区域作为之后使用
area = get_vm_area(vma->vm_end - vma->vm_start, VM_IOREMAP);
if (area == NULL) {
ret = -ENOMEM;
failure_string = "get_vm_area";
goto err_get_vm_area_failed;
}
//将内核虚拟地址记录在proc的buffer中
proc->buffer = area->addr;
/* 记录用户态虚拟地址空间与内核态虚拟地址空间的偏移量。,
* 这样通过buffer和user_buffer_offset就可以计算出用户态的虚拟地址。
*/
proc->user_buffer_offset = vma->vm_start - (uintptr_t)proc->buffer;
get_vm_area()方法已在告知Binder驱动保留出相应大小的虚拟地址空间以对应上当前应用上层的虚拟地址空间区域,这两者最终都会指向同一块物理地址。此处我们可以看到,binder_proc的buffer字段保存了binder内核中被映射的起始地址,而user_buffer_offset字段则说明用户态虚拟地址空间与内核态虚拟地址空间的偏移量,而之后的buffer_size字段则存放了mmap映射的地址空间大小。
// drivers/staging/android\binder.c#binder_mmap
/*pages是分配存放物理页地址的数组,此处则是申请pages的内存*/
proc->pages = kzalloc(sizeof(proc->pages[0]) * ((vma->vm_end - vma->vm_start) / PAGE_SIZE), GFP_KERNEL);//PAGE_SIZE=4M
if (proc->pages == NULL) {
ret = -ENOMEM;
failure_string = "alloc page array";
goto err_alloc_pages_failed;
}
//记录虚拟地址空间大小
proc->buffer_size = vma->vm_end - vma->vm_start;
vma->vm_ops = &binder_vm_ops;
//vma vm_private_data的保存proc信息
vma->vm_private_data = proc;
pages是一个二维指针,是用来管理物理页的。上边的kzalloc中的PAGE_SIZE大小为4K,其代表了一页物理内存的大小,而从整个kzalloc方法上来看就是根据vma中虚拟地址空间大小换算成对应的页数后申请了这个页数大小的pages[0]内存空间,这样pages数组中每一个page都代表了一个物理页。
至此所有的mmap准备工作都已做好,下边就该进行实际对应大小的物理页面的申请了。
// drivers/staging/android\binder.c#binder_mmap
//只分配了1页物理地址
if (binder_update_page_range(proc, 1, proc->buffer, proc->buffer + PAGE_SIZE, vma)) {
ret = -ENOMEM;
failure_string = "alloc small buf";
goto err_alloc_small_buf_failed;
}
binder_update_page_range()就是具体申请物理页面及完成虚拟内核空间与虚拟用户空间关联的过程,我们先说明下这个方法各参数的含义:
static int binder_update_page_range(struct binder_proc *proc, int allocate,
void *start, void *end,
struct vm_area_struct *vma)
- proc:代表申请内存进程的binder_proc
- allocate:当前是申请过程还是释放内存的过程,1表示申请,而0表示释放。
- start:Binder驱动中虚拟地址空间的起始地址,对应到get_vm_area()中。
- end:Binder驱动中虚拟地址空间的结束地址,对应到get_vm_area()中。
- vma:上层应用中关于虚拟内存空间的描述。

在上边申请物理页面时我们应该注意到,此次申请的物理页面大小只有一个PAGE_SIZE即4K大小(一页物理内存),这是基于内存消耗上的考虑。
// drivers/staging/android\binder.c#binder_mmap
buffer = proc->buffer;
//初始化buffers序列
INIT_LIST_HEAD(&proc->buffers);
list_add(&buffer->entry, &proc->buffers);
buffer->free = 1;//1标识buffer可用,0标识buffer已用
binder_insert_free_buffer(proc, buffer);//当前buffer可用,插入到可用buffer链表中
//异步可用地址空间大小为总地址空间大小的一半。
proc->free_async_space = proc->buffer_size / 2;
barrier();
proc->files = get_files_struct(current);
proc->vma = vma;
proc->vma_vm_mm = vma->vm_mm;
/*pr_info("binder_mmap: %d %lx-%lx maps %p\n",
proc->pid, vma->vm_start, vma->vm_end, proc->buffer);*/
return 0;//binder_mmap()结束
在阅读了binder_mmap()之后,我们知道其仅仅只申请了一页物理内存及4K大小,那么后续我们进行进程间通信时传输的数据量很可能远不止此。那么显然,Binder驱动必须可以动态申请物理内存以避免不够用的情况,这个过程在binder_alloc_buf()方法中有体现,这里我们代码就不贴了,只对buffers相关的做下解释。
在Binder驱动中buffers是一个内存块链表,其结点为binder_buffer。这些bidner_buffer内存块共同组成了mmap()的物理内存区域。

当发生进程间通信时,如果需要使用到mmap对应的物理内存区域存放跨进程数据,则可以使用方法binder_alloc_buf()尝试获取指定大小的内存块,这个内存块由结构体binder_buffer描述,而我们处于用户空间的数据就可以通过copy_from_user()方法把数据存放到这个binder_buffer中去。
上图中实质上就是为什么Binder机制一次拷贝就可完成数据的跨进程传输的原因。仔细来说,当我们进程B想要传输数据给进程A时,必然经ioctl而陷入内核态调用,此时进程A需要先为这个数据准备相应大小的可用binder_buffer,然后我们再通过copy_from_user()就很容易的把进程A的数据拷贝到目标进程(进程A)mmap内存区域准备好的binder_buffer中,而又因为mmap内存区域对于目标进程(进程A)呈映射关系,所以上层就可以拿到这个传输过来的数据了。
数据的跨进程传输
杂项命令的处理
Binder机制进行数据传输的核心方法是ioctl(),对应到驱动层来说就是binder_ioctl()。binder_ioctl()是数据读和写的结合,其属于阻塞式调用,当应用上层调用此方法时首先会阻塞调用者线程直到目标线程返回由Binder驱动交给它的数据的处理结果后才会解除阻塞(非one way情形)。以下是binder_ioctl()的主体调用图:

每个应用上层的调用线程(IPCThreadState)通过binder_ioctol()调用到Binder驱动时,Binder驱动都有一个binder_thread与调用线程一一对应。面对binder_thread结构体,可能有读者会想到应用上层通过ProcessState的startThreadPool()或IPCThreadState的joinThreadPool()所启动的binder线程,这两者是否等价呢?答案是否定的,binder_thread所对应的当前调用线程,其可以是binder线程,也可以不是binder线程;而应用上层的binder线程在Binder驱动中是由binder_proc中的max_threads、requested_threads、ready_threads等字段加上binder_thread中的looper字段一起联合管理的。总而言之,应用上层的binder线程在binder驱动中有其对应的binder_thread,但驱动中的binder_thread反映到应用上层并非一定指代binder线程,其也可能是普通线程。
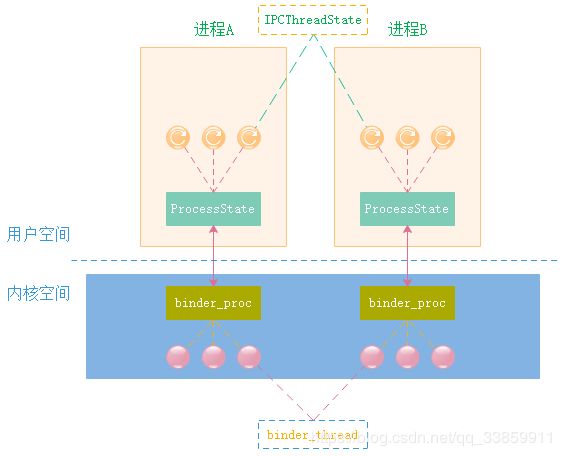
当调用binder_ioctl()时,首先需要确定当前的调用线程,只有确认了调用线程才可能在write/read时阻塞或唤醒线程。每个调用线程在Binder驱动中都由对应的binder_thread结构体标识,这些的binder_thread结构体被保存在binder_proc(代表进程)的红黑树threads中,当我们调用binder_ioctl()时其内部首先通过binder_get_thread()获取当前线程的binder_thread。
// drivers/staging/android\binder.c
static struct binder_thread *binder_get_thread(struct binder_proc *proc)
{
struct binder_thread *thread = NULL;
struct rb_node *parent = NULL;
//threads根据pid排序
struct rb_node **p = &proc->threads.rb_node;
//current->pid 拿到当前任务的pid,---线程id,如果想拿进程id,可通过current->group_leader->pid
//在红黑树中查找是否有当前线程
while (*p) {
parent = *p;
thread = rb_entry(parent, struct binder_thread, rb_node);
if (current->pid < thread->pid)
p = &(*p)->rb_left;
else if (current->pid > thread->pid)
p = &(*p)->rb_right;
else
break;
}
//没有找到则创建线程信息并将之存入红黑树&proc->threads
if (*p == NULL) {
thread = kzalloc(sizeof(*thread), GFP_KERNEL);
if (thread == NULL)
return NULL;
//引用计数增加
binder_stats_created(BINDER_STAT_THREAD);
//thread中比较重要的变量:proc ---标识进程信息,pid---标识线程id
thread->proc = proc;//内核中没有线程的概念,所以thread与proc之间需完成绑定
thread->pid = current->pid;
//初始化线程的wait队列与todo链表
init_waitqueue_head(&thread->wait);
INIT_LIST_HEAD(&thread->todo);
//插入到红黑树中
rb_link_node(&thread->rb_node, parent, p);
//调整颜色
rb_insert_color(&thread->rb_node, &proc->threads);
//thread状态
thread->looper |= BINDER_LOOPER_STATE_NEED_RETURN;
thread->return_error = BR_OK;
thread->return_error2 = BR_OK;
}
return thread;
}
在binder_get_thread()中我们可以清晰的看到其试图从红黑树proc->threads中获取对应线程号的binder_thread,如获取不到则主动创建并将其插入到这个红黑树中。
binder_thread结构体如下:
// drivers/staging/android\binder.c
struct binder_thread {
struct binder_proc *proc;//标识当前线程所属的进程
//当前binder_thread是binder_proc的threads域中的一个红黑树节点,此处则表示当前节点的在红黑树中的关系
struct rb_node rb_node;
int pid;//线程号
int looper//用于标识线程状态
struct binder_transaction *transaction_stack;//当前线程正在处理的事务
struct list_head todo;//双向链表,结点类型binder_work,当前正在处理事务的在本线程的存根
uint32_t return_error; /* Write failed, return error code in read buf */
uint32_t return_error2; /* Write failed, return error code in read */
/* buffer. Used when sending a reply to a dead process that */
/* we are also waiting on */
wait_queue_head_t wait;//用于控制线程中断、唤醒
struct binder_stats stats;//线程cmd统计
};
对binder_ioctl()的代码阅读过程先由比较简单的几个case说起,最后在了解BINDER_WRITE_READ这个使用最反复也最庞杂的case。
- BINDER_SET_MAX_THREADS:
一般在普通进程成为binder进程之后调用,用于告知binder驱动此binder进程可允许开启的最大binder线程数。当成为binder进程时,一般可通过ProcessState的startThreadPool()或IPCThreadState的joinThreadPool()先启动若干binder线程来接收跨进程信息,但当有新的跨进程信息到来而当前进程的这些binder线程都处于正在使用状态时,则binder驱动会告知我们的binder进程再启动一个binder线程直到达到最大binder线程数为止。
应用上层在成为binder进程时设置当前binder进程最大binder线程数,可以看到,默认为每个binder进程设置的最大binder线程数为15个。
// frameworks/native/libs/binder/ProcessState.cpp#open_driver
size_t maxThreads = 15;
result = ioctl(fd, BINDER_SET_MAX_THREADS, &maxThreads);
在binder驱动中把最大线程数记录到binder_proc的max_threads字段中。
// drivers/staging/android\binder.c#binder_ioctl
if (copy_from_user(&proc->max_threads, ubuf, sizeof(proc->max_threads))) {
ret = -EINVAL;
goto err;
}
以下对应binder_proc中对于binder线程管理的各个字段及其含义:
| 字段 | 含义 |
|---|---|
| requested_threads | 当前正在启动的binder线程数量 |
| ready_threads | 当前处于准备状态的binder线程数量,处于此状态的线程可被唤醒处理binder任务 |
| requested_threads_started | 当前进程中已经成为binder线程的数量 |
| max_threads | 当前进程所允许的最大binder线程数量 |
对应的binder线程还有诸多状态:
| 线程状态 | 含义 |
|---|---|
| BINDER_LOOPER_STATE_REGISTERED | 创建binder线程,通过BC_REGISTER_LOOPER协议通知Binder驱动(非binder主线程) |
| BINDER_LOOPER_STATE_ENTERED | 创建binder线程,通过BC_ENTER_LOOPER通知驱动(binder主线程) |
| BINDER_LOOPER_STATE_EXITED | Binder线程退出, 对应命令为BC_EXIT_LOOPER |
| BINDER_LOOPER_STATE_INVALID | 异常状态 |
| BINDER_LOOPER_STATE_WAITING | binder线程处于空闲状态 |
| BINDER_LOOPER_STATE_NEED_RETURN | 表示该线程需要马上返回结果到用户空间中 |
下边代码展示了binder驱动何时需要上层应用新建一个binder线程来处理跨进程任务。
// drivers/staging/android\binder.c#binder_thread_read
if (proc->requested_threads + proc->ready_threads == 0 &&
proc->requested_threads_started < proc->max_threads &&
(thread->looper & (BINDER_LOOPER_STATE_REGISTERED |
BINDER_LOOPER_STATE_ENTERED)) /* the user-space code fails to */
/*spawn a new thread if we leave this out */) {
proc->requested_threads++;
binder_debug(BINDER_DEBUG_THREADS,
"%d:%d BR_SPAWN_LOOPER\n",
proc->pid, thread->pid);
if (put_user(BR_SPAWN_LOOPER, (uint32_t __user *)buffer))//通知binder进程创建binder线程
return -EFAULT;
binder_stat_br(proc, thread, BR_SPAWN_LOOPER);
}
通过上边可知,想要新建一个binder线程来处理跨进程任务有三个条件:
1.当前正在启动的binder线程和处于准备状态的可用线程数为0。
2.当前已经成为binder线程的数量小于允许的最大binder线程数。
3.调用线程已经处于可用状态,即当前调用线程已有其它跨进程任务要处理。
如果这个三条件都满足则往应用上层中发送BR_SPAWN_LOOPER通知其需要新建一个binder线程,新建binder线程则通过ProcessState的spawnPooledThread()完成,此方法会创建一个PoolThread线程,而在这个线程中有进一步调用了IPCThreadState的joinThreadPool()让此线程成为了binder线程。
// frameworks/native/libs/binder/IPCThreadState.cpp#executeCommand
case BR_SPAWN_LOOPER://binder驱动通知binder server新建一个binder线程处理消息
mProcess->spawnPooledThread(false);//内部调用joinThreadPool()。
break;
在调用joinThreadPool()成为binder线程是会写入BC_REGISTER_LOOPER告知binder驱动当前进程已经准备OK。如果当前线程启动成功,则正在启动线程的记录字段(requested_threads)需自减,并且记录已成为binder线程数量的字段(requested_threads_started)需加一。
// drivers/staging/android\binder.c#binder_thread_write
case BC_REGISTER_LOOPER:
if (thread->looper & BINDER_LOOPER_STATE_ENTERED) {
thread->looper |= BINDER_LOOPER_STATE_INVALID;
binder_user_error("%d:%d ERROR: BC_REGISTER_LOOPER called after BC_ENTER_LOOPER\n",
proc->pid, thread->pid);
} else if (proc->requested_threads == 0) {
thread->looper |= BINDER_LOOPER_STATE_INVALID;
binder_user_error("%d:%d ERROR: BC_REGISTER_LOOPER called without request\n",
proc->pid, thread->pid);
} else {
proc->requested_threads--;
proc->requested_threads_started++;
}
thread->looper |= BINDER_LOOPER_STATE_REGISTERED;
break;
- BINDER_SET_CONTEXT_MGR:
Binder机制中binder驱动固然是各个binder进程之间的‘路由器’,但若无‘DNS’的来解析‘域名’则整个进程间的通信的关键一环—如何寻找目标进程就无法谈起。在之前我们说过‘DNS’这个角色是由servicemanager完成的,servicemanager本质上是由init.rc触发的第一个binder进程,其主要是负责存储其它的实名Binder Server。这就需要把servicemanager设置成为各个Binder Server的管理者,方式就是通过BINDER_SET_CONTEXT_MGR告知binder驱动。
// frameworks/native/cmds/servicemanager/binder.c
//注意,此binder.c非驱动层的binder.c
int binder_become_context_manager(struct binder_state *bs)
{
return ioctl(bs->fd, BINDER_SET_CONTEXT_MGR, 0);
}
在binder驱动中,拥有一个全局变量binder_context_mgr_node,这个变量就负责存储当前被设置成Binder Server大管家的进程节点。
// drivers/staging/android\binder.c
static struct binder_node *binder_context_mgr_node;
从理论上来说并非任意一个binder进程都可以成为Binder Server大管家的,这是有严格限制的,不然的话进程间的通信很容易就会受到恶意进程的串改和攻击。
// drivers/staging/android\binder.c#binder_ioctl
case BINDER_SET_CONTEXT_MGR://service_manager专用
if (binder_context_mgr_node != NULL) {
ret = -EBUSY;
goto err;
}
ret = security_binder_set_context_mgr(proc->tsk);//当前进程权限检查
//...
binder_context_mgr_node = binder_new_node(proc, 0, 0);//为servicemanager进程创建全局binder_node节点
if (binder_context_mgr_node == NULL) {
ret = -ENOMEM;
goto err;
}
/...
break;
从上边代码可知,注册成为Binder Server大管家的过程就是在binder驱动中通过binder_new_node()创建一个全局变量binder_context_mgr_node。在binder_new_node()调用时传入的第二、三个参数都是0,这是两者与servicemanager进程被分配的handle值为0有关,其它binder进程都显式的知道servicemanager的handle才能与之通信。
// drivers/staging/android\binder.c#binder_transaction
//根据handle值找到对应的binder_node
//handle是否为0,如果为0则说明是service_manager,此处进入条件为非0
if (tr->target.handle) {
//...
} else {
//handle==0时目标就是service_manager
target_node = binder_context_mgr_node;
//...
}
在我们往binder驱动中写入数据以进行跨进程通信时,我们可以根据其通信目标target的handle值寻找目标进程。正因此,在应用上层使用BpBinder(0)为什么能够确定是与servicemanager进行通信就得以确定。
- BINDER_THREAD_EXIT:
在讲解到IPCThreadState时我们有说过,当通过IPCThreadState创建的binder线程退出(包含主动或者异常退出)时会调用清理函数threadDestructor(),在这个清理函数中会清理掉所有的cmd命令(通过talkWithDriver把cmd发送给binder驱动),当清理完成时则调用cmd命令BINDER_THREAD_EXIT告知binder驱动当前binder线程已退出。
//// frameworks/native/libs/binder/IPCThreadState.cpp
void IPCThreadState::threadDestructor(void *st)
{
IPCThreadState* const self = static_cast<IPCThreadState*>(st);
if (self) {
self->flushCommands();
#if defined(HAVE_ANDROID_OS)
if (self->mProcess->mDriverFD > 0) {
ioctl(self->mProcess->mDriverFD, BINDER_THREAD_EXIT, 0);
}
#endif
delete self;
}
}
当binder驱动接收到BINDER_THREAD_EXIT时,代表当前的binder线程已经退出,作为驱动层面上来说,同样需要清理挂载在此线程上待处理的binder事务。这个具体工作就是由binder_free_thread()完成的。
在介绍binder_free_thread()方法前,我们有必要先了解一下什么是binder事务(binder_transaction)。
事务(transaction)指的是一组连续性操作的执行过程,一般而言其具有两个特性:
1.一致性,即在异常情况下如果这一组操作没有执行完毕,则这组连续性操作中已执行的操作都应该回滚到执行之前的样子,他们要么同时成功,要么同时失败。
2.隔离性,组成事务的这组连续性操作与其它的事务相互隔离,互不干扰。
对于binder机制来说,一组连续性操作的执行过程就被定义为binder事务,也称binder_transaction。binder_transaction本质上是结构体,它内部记录的当前这组binder操作的来源、去向、操作目的等。

对于完整的非one way通信过程来说,从Binder Client发送BC_TRANSATION到Binder Server收到BR_TRANSACTION这个过程就意味着一次事务,而Binder Server发送BC_REPLY到Binder Client收到BR_REPLY这个过程同样的也意味着一次事务;也就是说binder进程间的一次通信的过程就称为binder_transaction。
binder_transaction结构体字段及含义如下:
| binder_transaction | ||
| struct binder_work | work | 当前事务的存根,一般保存在当前事务目标端的todo队列中 |
| struct binder_thread * | from | 记录发送线程信息 |
| struct binder_transaction * | from_parent | 记录发送线程的传输栈的父栈 |
| struct binder_proc * | to_proc | 记录接收进程的进程信息 |
| struct binder_thread * | to_thread | 记录接收线程的信息 |
| struct binder_transaction * | to_parent | 记录接收进程的传输栈的父栈 |
| unsigned | need_reply | 当前事务是否需要返回结果,1标识是 |
| struct binder_buffer * | buffer | 当前事务对应的数据存储区域描述 |
| unsigned int | code | 当前事务的业务码 |
| unsigned int | flags | 当前事务的类型 |
为了让开发者能够理解Binder驱动,谷歌在起名方面可谓良苦用心,一次binder进程间的传输过程称为一次binder_transaction,这次binder事务所携带的数据就被称为binder_transaction_data(很熟悉不是吗)。
回到本小节binder线程退出时会发送BINDER_THREAD_EXIT告知Binder驱动,此时Binder驱动会调用下边binder_free_thread()方法清理当前线程。
// drivers/staging/android\binder.c
static int binder_free_thread(struct binder_proc *proc,
struct binder_thread *thread)
{
struct binder_transaction *t;//当亲被挂载的事务
struct binder_transaction *send_reply = NULL;
int active_transactions = 0;//用于记录被挂载的binder事务总数
rb_erase(&thread->rb_node, &proc->threads);
t = thread->transaction_stack;//挂载在当前线程上的事务栈
if (t && t->to_thread == thread)//事务栈顶部是否是当前线程需接收处理的事务
send_reply = t;
while (t) {
active_transactions++;
binder_debug(BINDER_DEBUG_DEAD_TRANSACTION,
"release %d:%d transaction %d %s, still active\n",
proc->pid, thread->pid,
t->debug_id,
(t->to_thread == thread) ? "in" : "out");
if (t->to_thread == thread) {//清理当前线程处理的消息
t->to_proc = NULL;
t->to_thread = NULL;
if (t->buffer) {//释放buffer空间
t->buffer->transaction = NULL;
t->buffer = NULL;
}
t = t->to_parent;
} else if (t->from == thread) {//清理来自当前线程的消息
t->from = NULL;//把from改为null,这样这个事务就会交由binder_proc处理
t = t->from_parent;
} else
BUG();
}
if (send_reply)
binder_send_failed_reply(send_reply, BR_DEAD_REPLY);//如果有当前线程正在处理的事务,则发送dead_reply告知目标
binder_release_work(&thread->todo);//清理todo链表
kfree(thread);//释放thread占用内存
binder_stats_deleted(BINDER_STAT_THREAD);//统计计数:线程数减一
return active_transactions;
}
在binder_free_thread()中,主要分为以下两种情况:
1.清理事务栈。binder_thread的transaction_stack字段代表了挂载在当前线程中正在处理的binder事务栈,线程释放时其检查这个栈顶部是否是其他线程发起而由当前线程处理的,若是则此线程被释放时需要给这个binder事务的发起线程返回一个reply结果(BR_DEAD_REPLY)。在while循环中,这个将要被释放的线程从binder事务栈栈顶往栈底一个一个排查栈中的binder事务,如果当前binder事务是接收的事务则把这个事务直接释放掉,如果是当前线程发起的binder事务,则把这个binder事务的from置为null,这样这个binder事务返回结果时由于丢失了源线程就会向下边代码那样,返回错误结果(BR_DEAD_REPLY)。
// drivers/staging/android\binder.c#binder_transaction
thread->transaction_stack = in_reply_to->to_parent;
//标识binder_transation的源线程,在对应reply时当然就是reply的目标线程
target_thread = in_reply_to->from;
//如果binder_transation源线程丢失,则属于dead reply
if (target_thread == NULL) {
return_error = BR_DEAD_REPLY;
goto err_dead_binder;
}
2.清理todo列表。binder_thread的todo字段代表了当前线程中等待处理的操作(虽然其结点是binder_work,但可据此binder_work找到对应的binder_transaction),这个todo列表中的binder事务在binder_release_work()方法中被遍历,如果当前binder事务是非one way类型(需返回结果),则给这个binder事务的源线程返回BR_DEAD_REPLY。
// drivers/staging/android\binder.c#binder_transaction
static void binder_release_work(struct list_head *list)
{
struct binder_work *w;
while (!list_empty(list)) {
w = list_first_entry(list, struct binder_work, entry);
list_del_init(&w->entry);//安全删除w
switch (w->type) {
case BINDER_WORK_TRANSACTION: {
struct binder_transaction *t;
t = container_of(w, struct binder_transaction, work);//todo列表可依据binder_work取出binder_transaction
if (t->buffer->target_node && !(t->flags & TF_ONE_WAY)) {//需要回复结果的
binder_send_failed_reply(t, BR_DEAD_REPLY);//给挂载在当前线程todo链表上的非one way消息发送dead reply
} else {
t->buffer->transaction = NULL;//不需要回复,所以直接清理buffer区域
//...
}
} break;
case BINDER_WORK_TRANSACTION_COMPLETE: {
//...
} break;
case BINDER_WORK_DEAD_BINDER_AND_CLEAR:
case BINDER_WORK_CLEAR_DEATH_NOTIFICATION: {
//...
} break;
default:
break;
}
}
}
关于binder_thread事务栈及todo列表还有很多细节,在下边还会详细介绍。
- BINDER_VERSION:
此cmd主要用于获取当前binder内核驱动的版本号。一般而言,binder驱动的代码位于linux kernel中,而其他binder机制的上层代码都位于android代码中。鉴于不同版本kernel与android代码对于binder机制的协议定义可能不一致,所以当android运行时需要判断两者版本号是否一致。
// frameworks/native/cmds/servicemanager/binder.c#binder_open
//获取binder内核驱动版本与binder native版本 比较是否一致
if ((ioctl(bs->fd, BINDER_VERSION, &vers) == -1) ||
(vers.protocol_version != BINDER_CURRENT_PROTOCOL_VERSION)) {
fprintf(stderr, "binder: driver version differs from user space\n");
goto fail_open;
}
在servicemanager启动时会去判断binder驱动的版本是否与当前android中binder机制的代码版本号匹配,如果不匹配的话整个系统是无法使用的。
BINDER_WRITE_READ
在整个Binder机制中使用最频繁的ioctl命令无疑就是BINDER_WRITE_READ了,此命令广泛使用于进程间的数据通信,其传输的数据结构分为write/read两个部分,在Binder驱动中则相应的对这两部分分别进行读写。
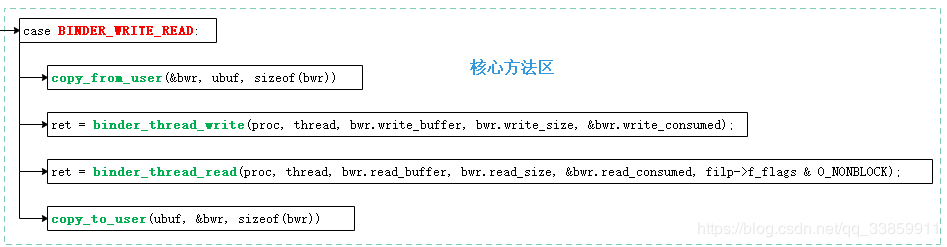
我们先来看write部分,传输数据结构中写入部分的数据一般是需要进行跨进程传输的数据,这部分由应用上层填充。
在传输结构体binder_write_read的写入部分中,包含以下几个字段:
- write_buffer,存储了形式如BC_XXXX的各式各样的写入指令及指令数据,例如BC_TRANSACTION指令随后跟随了binder_transaction_data数据,这些指令(指令长度固定为uint32_t大小)及随后对应的数据大小是固定的,当buffer区域传到Binder驱动之后Binder驱动负责根据cmd指令取出其后的数据进行解析。
- write_size,buffer区域大小。
- write_consumed,buffer区域已经读取的数据区域长度,未读取时为0。
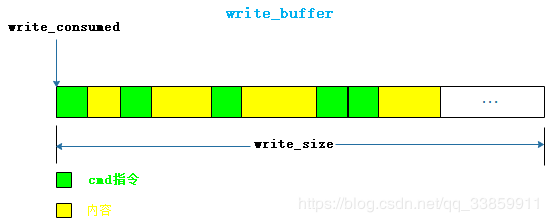
// frameworks/native/cmds/servicemanager/binder.c#binder_ioctl
//有数据写入,一般需要唤醒target
if (bwr.write_size > 0) {
ret = binder_thread_write(proc, thread, bwr.write_buffer, bwr.write_size, &bwr.write_consumed);
trace_binder_write_done(ret);
//target读取写入数据失败时ret<0
if (ret < 0) {
//因target处理写入失败,还原数据
bwr.read_consumed = 0;
if (copy_to_user(ubuf, &bwr, sizeof(bwr)))
ret = -EFAULT;
goto err;
}
在binder_thread_write()中负责解析当前线程中通过ioctl传输到驱动的write_buffer数据,这些write_buffer数据由数个BINDER_WRITE_READ的子命令及对应子命令可能包含的内容部分组成。这些子命令除了引用计数管理、线程状态管理、binder讣告管理等辅助部分外,最重要的就是进程间数据通信用的BC_TRANSACTION/BC_REPLY部分了。
// frameworks/native/cmds/servicemanager/binder.c
int binder_thread_write(struct binder_proc *proc, struct binder_thread *thread,
binder_uintptr_t binder_buffer, size_t size,
binder_size_t *consumed)
{
uint32_t cmd;
void __user *buffer = (void __user *)(uintptr_t)binder_buffer;
void __user *ptr = buffer + *consumed;
void __user *end = buffer + size;
//未处理完或者除非中途发生错误,否则一直循环处理
while (ptr < end && thread->return_error == BR_OK) {
//获取用户空间ptr的cmd命令
if (get_user(cmd, (uint32_t __user *)ptr))
return -EFAULT;
//顺延cmd指令大小
ptr += sizeof(uint32_t);
//根据cmd指令来处理ptr数据
switch (cmd) {
//...
case BC_TRANSACTION:
case BC_REPLY: {
struct binder_transaction_data tr;
//拷贝指针
if (copy_from_user(&tr, ptr, sizeof(tr)))
return -EFAULT;
ptr += sizeof(tr);//地址顺延
//真正处理任务的地方,第三个参数用以标明当前是否是REPLY
binder_transaction(proc, thread, &tr, cmd == BC_REPLY);
break;
}
//...
}
return 0;
}
可以看到对当前写入到驱动的数据解析的起始地址是需要减去已经消费(consumed)部分的,binder_thread_write()中通过循环方式解析存放在write buffer中未被consumed的cmd指令部分,这些cmd指令对应的内容部分(若有的话)则通过copy_from_user()从用户空间获取。
在相应BC_TRANSACTION/BC_REPLY的case中我们注意到这两种cmd指令的内容是binder_transaction_data结构体,需要注意的是这个结构体的重要字段buffer和offsets所存储的只是地址指针,此处通过copy_from_user()还并未将这两指针所指向的实际的传输数据拷贝到内核空间。无论是BC_TRANSACTION或BC_REPLY,因其传输内容相同且都属于进程间的数据通信(BC_TRANSACTION多表示client->server,BC_REPLY多表示server->client),所以两者都是用binder_transaction()方法进行跨进程传输。
binder_transaction()代码极其庞大,但此方法总纲是为了把当前线程的binder_transaction_data传输给目标进程的目标线程。下边我们分别对BC_TRANSACTION发起跨进程通信和BC_REPLY回复结果等进行解析,在解析过程中不可避免的会把binder_transaction()中的代码进行拆分阅读,所以binder_transaction()源码部分可能不会完整贴出来。
BC_TRANSACTION-发起跨进程通信
当一个进程发起通信时,起始端对应应用上层的代码来说就是mRemote.transact()的过程,这个调用最终会调用到IPCThreadState的transact()。在这个transact()中对我们的cmd命令BC_TRANSACTION进行了组装,并通过ioctl()与Binder驱动发生通信。
// frameworks/native/libs/binder/IPCThreadState.cpp
status_t IPCThreadState::transact(int32_t handle,
uint32_t code, const Parcel& data,
Parcel* reply, uint32_t flags)
{
//...
if (err == NO_ERROR) {
//把binder数据data和cmd写入到mOut中
err = writeTransactionData(BC_TRANSACTION, flags, handle, code, data, NULL);
}
//...后续会调用ioctl与Binder驱动通信。
return err;
}
上述的通信经由binder_ioctl()最后调用到binder_transaction()方法中,这个binder_transaction()包含了结果回复(BC_REPLY)部分内容,但此处我们暂不关心,优先看BC_TRANSACTION部分。
以下是binder_transaction()中使用到的各个字段定义。
// frameworks/native/cmds/servicemanager/binder.c#binder_transaction
static void binder_transaction(struct binder_proc *proc,
struct binder_thread *thread,
struct binder_transaction_data *tr, int reply)
{
struct binder_transaction *t;//依据当前的binder_transaction_dat组装成的binder事务
struct binder_work *tcomplete;//binder_work节点,传输时添加到源线程的todo链表中
binder_size_t *offp, *off_end;//offp标识flat_binder_object的起始地址,off_end则标识offsets域的终止地址,据此可解析flat_binder_object(binder实体)
binder_size_t off_min;//对offsets区域解析的偏移量
struct binder_proc *target_proc;//此次通信的目标进程
struct binder_thread *target_thread = NULL;//此次通信的目标线程
struct binder_node *target_node = NULL;//此次通信的目标binder
struct list_head *target_list;//此次通信目标线程的todo链表
wait_queue_head_t *target_wait;//此次通信目标线程的wait(用于线程中断与唤醒)
struct binder_transaction *in_reply_to = NULL;//reply时当前线程的传输栈栈顶元素
struct binder_transaction_log_entry *e;//辅助日志
uint32_t return_error;
在这些字段中除了in_reply_to在BC_TRANSACTION部分不会使用到之外,其他都各有其重要作用。
其中binder_thread的todo链表标识了当前线程待处理的任务,节点类型为binder_work,它以链表形式把这些待处理任务binder_work给串联起来,如果当前线程有任务处理时就会被唤醒。binder_work只不过是一个区分了类型type的list_head结构体,其标识的真正的任务是由type类型决定的,比方说当前的binder_work类型是BINDER_WORK_TRANSACTION,则意味着这个binder_work指向一个binder_transaction(binder事务)。上边代码中的target_list就是标识了目标线程的todo链表。

早在本章早些时候我们就说过,handle值标识了目标binder服务(BBinder),我们可以通过这个handle值确认我们是同谁在跨进程通信。这个一路从IPCThreadState的transact()中传递到Binder驱动的handle值显然有着举足轻重的作用。
有一点我们需要了解,应用上层的BpBinder(代理)在Binder驱动中都对应一个binder_ref,同样的每一个Binder服务(BBinder)在Binder驱动中也对应一个binder_node。BpBinder与binder_ref通过handle建立联系,而BBinder与binder_node则通过ptr+cookie建立联系,这些handle、ptr、cookie在binder_transaction_data中都有描述。
正因此,当BC_TRANSACTION传到binder_transaction()中进行处理时,可以根据handle值确定我们的目标进程。这部分代码如下:
// frameworks/native/cmds/servicemanager/binder.c#binder_transaction
//根据handle值找到对应的binder_node
//handle是否为0,如果为0则说明是service_manager,此处进入条件为非0
if (tr->target.handle) {
struct binder_ref *ref;
//从proc的红黑树refs_by_desc中获取binder引用
ref = binder_get_ref(proc, tr->target.handle);
if (ref == NULL) {
binder_user_error("%d:%d got transaction to invalid handle\n",
proc->pid, thread->pid);
return_error = BR_FAILED_REPLY;
goto err_invalid_target_handle;
}
//从引用中取出binder_node
target_node = ref->node;
} else {
//handle==0时目标就是service_manager
target_node = binder_context_mgr_node;
if (target_node == NULL) {
return_error = BR_DEAD_REPLY;
goto err_no_context_mgr_node;
}
}
在上边我们可以看见,如果传下来的handle值不为0则通过binder_get_ref()从当前进程(binder_proc)的refs_by_desc红黑树中根据handle找到对应的binder_ref,进而通过这个binder_ref找到了目标binder_node;如果传下来的handle值为0则说明当前进程是想跟servicemanager服务进行通信,这时我们servicemanager通过设置自身为大管家所生成的binder_context_mgr_node就是目标binder_node。
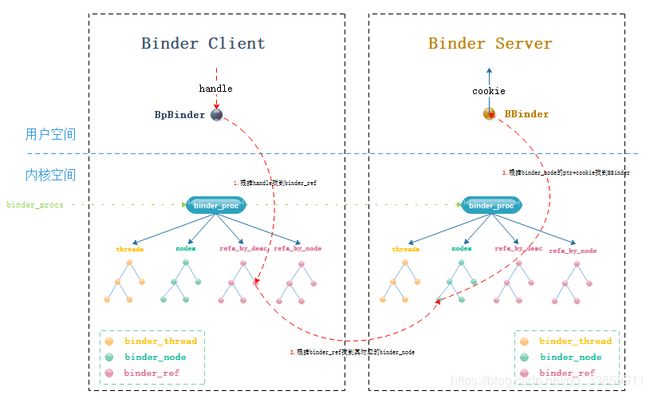
在找到了目标binder服务所对应的binder_node之后,我们进而可以据此找到其所在的进程。
// frameworks/native/cmds/servicemanager/binder.c#binder_transaction
e->to_node = target_node->debug_id;
//BC_TRANSATION对应传递的目标binder_proc
target_proc = target_node->proc;
if (target_proc == NULL) {
return_error = BR_DEAD_REPLY;
goto err_dead_binder;
}
//检查Client进程是否有权限向Server进程发送请求
if (security_binder_transaction(proc->tsk, target_proc->tsk) < 0) {
return_error = BR_FAILED_REPLY;
goto err_invalid_target_handle;
}
//当前binder_transation_data是非one_way(即需要reply),则寻找目标线程
//此处存疑,为什么要判断thread->transation_stack
if (!(tr->flags & TF_ONE_WAY) && thread->transaction_stack) {
struct binder_transaction *tmp;
tmp = thread->transaction_stack;
//当前线程的transation_stack的栈顶元素是否合法
if (tmp->to_thread != thread) {
return_error = BR_FAILED_REPLY;
goto err_bad_call_stack;
}
//试图寻找target_thread,寻找方案:在本线程的任务栈中寻找来自于BC_TRANSATION目标最早的任务的源线程
while (tmp) {
if (tmp->from && tmp->from->proc == target_proc)
target_thread = tmp->from;
tmp = tmp->from_parent;
}
}
在上边代码中我们不仅通过target_node找到了目标进程binder_proc,如果发现此次通信是非TF_ONE_WAY类型(需要目标进程回复结果)则还需要试图找到一个目标binder线程来执行这次跨进程通信。
在找到目标进程之后,接下来很明显要把此次跨进程的通信数据传送给目标进程中的某个binder线程来执行。那么我们是如何把这些通信数据传输给目标binder线程的呢?这就涉及到下边代码中的target_list和target_wait。
// frameworks/native/cmds/servicemanager/binder.c#binder_transaction
//寻找到target_thread之后就需要得到目标线程的双向链表todo及线程中断。唤醒用的wait
if (target_thread) {
e->to_thread = target_thread->pid;
target_list = &target_thread->todo;
target_wait = &target_thread->wait;
} else {//如只找到目标进程proc,则获取目标进程的双向链表todo及线程中断。唤醒用的wait
target_list = &target_proc->todo;
target_wait = &target_proc->wait;
}
target_list是目标线程(binder_thread)或目标进程(binder_proc)中的todo链表,todo名字取得恰到好处,其存放了所在binder线程(或进程)待处理的binder任务,这个target_list的节点类型正是binder_work(是不是似曾相识,上边我们有解说过)。
target_wait类型是wait_queue_head_t,它标识了当前的线程,在linux中被广泛应用于线程的阻塞与唤醒。
我们顺着BC_TRANSACTION的处理过程继续往下看。
正如之前我们所说的那样,对于BC_TRANSACTION的跨进程的过程都是一次binder事务(binder_transaction),所以此处我们的数据binder_transaction_data也需要存放在这个binder_transaction结构体中。此处我们申请了这个结构体的内存,同时也申请了tcomplete(binder_work)内存,这个tcomplete用于当此次传输完成时负责给当前线程返回传输完成指令。
// frameworks/native/cmds/servicemanager/binder.c#binder_transaction
//新增binder_transation,后续需要压栈
t = kzalloc(sizeof(*t), GFP_KERNEL);
if (t == NULL) {
return_error = BR_FAILED_REPLY;
goto err_alloc_t_failed;
}
//统计计数
binder_stats_created(BINDER_STAT_TRANSACTION);
//创建binder_work
tcomplete = kzalloc(sizeof(*tcomplete), GFP_KERNEL);
if (tcomplete == NULL) {
return_error = BR_FAILED_REPLY;
goto err_alloc_tcomplete_failed;
}
在申请完传输过程中需要的内存之后,接下来就是对这个binder_transaction事务内容进行填充了。
整个填充过程分为两个部分:
1.基础性填充。包括源线程、目标进程/线程、业务码、binder事务类型、用户uid、优先级等。
// frameworks/native/cmds/servicemanager/binder.c#binder_transaction
//填充binder_transation t
//当前是reply,且任务非one_way
if (!reply && !(tr->flags & TF_ONE_WAY))
t->from = thread;
else
t->from = NULL;
t->sender_euid = proc->tsk->cred->euid;
t->to_proc = target_proc;
t->to_thread = target_thread;
t->code = tr->code;
t->flags = tr->flags;
t->priority = task_nice(current);
2.buffer填充。从下边代码可以看到调用binder_alloc_buf()申请了一块大小为data_size+offsets_size的binder_buffer,这块binder_buffer内存是位于内核空间。注意!此刻我们实际的数据Parcel还是位于用户空间的,之前的种种copy_from_user()只是拷贝了cmd命令及地址指针,接下来这块binder_buffer才是真正的传输数据存放区域。
// frameworks/native/cmds/servicemanager/binder.c#binder_transaction
t->buffer = binder_alloc_buf(target_proc, tr->data_size,
tr->offsets_size, !reply && (t->flags & TF_ONE_WAY));
if (t->buffer == NULL) {
return_error = BR_FAILED_REPLY;
goto err_binder_alloc_buf_failed;
}
t->buffer->allow_user_free = 0;
t->buffer->debug_id = t->debug_id;
t->buffer->transaction = t;
t->buffer->target_node = target_node;
在进行buffer其他字段填充后,下边就是Binder机制一次拷贝就完成数据跨进程传输的关键所在,其把处于用户空间的data与offsets拷贝到了内核空间。
// frameworks/native/cmds/servicemanager/binder.c#binder_transaction
//把具体数据拷贝到内核区域
if (copy_from_user(t->buffer->data, (const void __user *)(uintptr_t)
tr->data.ptr.buffer, tr->data_size)) {
binder_user_error("%d:%d got transaction with invalid data ptr\n",
proc->pid, thread->pid);
return_error = BR_FAILED_REPLY;
goto err_copy_data_failed;
}
//给offp赋值,主要从用户区拷贝offsets过来
if (copy_from_user(offp, (const void __user *)(uintptr_t)
tr->data.ptr.offsets, tr->offsets_size)) {
binder_user_error("%d:%d got transaction with invalid offsets ptr\n",
proc->pid, thread->pid);
return_error = BR_FAILED_REPLY;
goto err_copy_data_failed;
}
在完成了数据从用户空间到内核空间的拷贝之后,接下来就是把数据传输到目标进程/线程。
// frameworks/native/cmds/servicemanager/binder.c#binder_transaction
if (reply) {
//...
} else if (!(t->flags & TF_ONE_WAY)) {
//如果是BC_TRANSATION,则源线程任务栈需进栈
BUG_ON(t->buffer->async_transaction != 0);
t->need_reply = 1;
//记录源线程传输栈
t->from_parent = thread->transaction_stack;
//当前传输任务进栈
thread->transaction_stack = t;
} else {
//对应BC_TRANSATION的TF_ONE_WAY
BUG_ON(target_node == NULL);
BUG_ON(t->buffer->async_transaction != 1);
if (target_node->has_async_transaction) {
target_list = &target_node->async_todo;
target_wait = NULL;
} else
target_node->has_async_transaction = 1;
}
对于非one way类型的BC_TRANSACTION跨进程来说因为其需要返回结果,所以这个过程是一个binder事务,因此这个构建的binder_transaction需要进源线程事务栈中等待返回reply。而对于one way类型的数据传输来说,其只管发送,并不关心此次传输是成功或者失败,所以不需要进入事务栈。
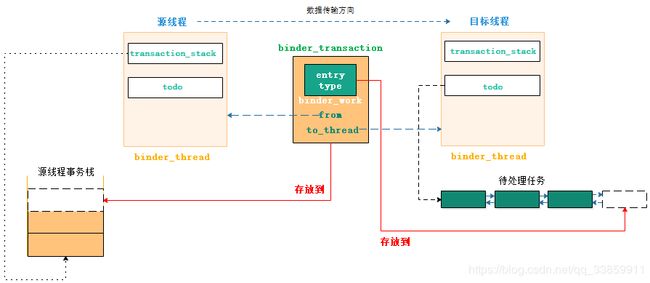
// frameworks/native/cmds/servicemanager/binder.c#binder_transaction
t->work.type = BINDER_WORK_TRANSACTION;
//target_list即目标线程/进程的todo链表,目标线程可根据binder_work找到binder_transation
list_add_tail(&t->work.entry, target_list);
//当前线程的todo链表,本地线程则在todo队列添加传输完成指令
tcomplete->type = BINDER_WORK_TRANSACTION_COMPLETE;
list_add_tail(&tcomplete->entry, &thread->todo);
接下来就是把当前binder事务以binder_work节点的形式添加到目标线程的todo链表等待目标线程执行。同时,给当前线程的todo链表返回一个传输完成的指令任务,这个返回的tcomplete的类型是BINDER_WORK_TRANSACTION_COMPLETE,这样本线程就会在binder_thread_read中读取此todo链表中的tcomplete进而给应用上层返回BR_TRANSACTION_COMPLETE(如下图)。

在完成把当前binder事务以binder_work形式添加到目标线程的todo链表后,接下来就可谓万事俱备只欠东风了。
// frameworks/native/cmds/servicemanager/binder.c#binder_transaction
//需要唤醒目标线程
if (target_wait)
wake_up_interruptible(target_wait);
如上,最后一步就是唤醒处于阻塞状态的目标线程。
目标线程唤醒后的处理
目标线程被唤醒在上边是通过wake_up_interruptible()完成的,这属于主动唤醒的方式。
而在被唤醒之前,我们需要了解目标线程是如何处于阻塞状态的。
当目标线程通过ioctl()调用到Binder驱动时,抛开正常的写入部分,当其调用到binder_thread_read()时会判断当前有无需要读取的跨进程数据,如果没有的话就会进入阻塞状态。
// frameworks/native/cmds/servicemanager/binder.c#binder_thread_read
wait_for_proc_work = thread->transaction_stack == NULL &&
list_empty(&thread->todo);
上边就是目标线程阻塞条件,主要是判断目标线程事务栈是否为空且没有待处理的todo任务。如果当前没有要处理的任务,则当前线程(目标线程)需要进入阻塞状态。
// frameworks/native/cmds/servicemanager/binder.c#binder_thread_read
thread->looper |= BINDER_LOOPER_STATE_WAITING;
//可用线程数+1
if (wait_for_proc_work)
proc->ready_threads++;
可见如果没有要处理的任务,则把当前线程标记为waiting状态,且记录当前进程处于准备状态的线程加一。
// frameworks/native/cmds/servicemanager/binder.c#binder_thread_read
if (wait_for_proc_work) {
binder_set_nice(proc->default_priority);
if (non_block) {
if (!binder_has_proc_work(proc, thread))
ret = -EAGAIN;
} else
ret = wait_event_freezable_exclusive(proc->wait, binder_has_proc_work(proc, thread));
} else {
if (non_block) {
if (!binder_has_thread_work(thread))
ret = -EAGAIN;
} else
ret = wait_event_freezable(thread->wait, binder_has_thread_work(thread));
}
//被动唤醒条件
static int binder_has_proc_work(struct binder_proc *proc,
struct binder_thread *thread)
{
return !list_empty(&proc->todo) ||
(thread->looper & BINDER_LOOPER_STATE_NEED_RETURN);
}
接着当前线程就调用wait_event_freezable_exclusive()或wait_event_freezable()进入阻塞状态,注意此处添加了一个被动唤醒的条件binder_has_thread_work(),这个条件包含进程todo链表不为空或者当前线程需要立即返回结果,至此线程就完成了阻塞等待条件满足或由其它线程主动唤醒。
在上边BC_TRANSACTION发起跨进程通信最后,通过wake_up_interruptible()这个等待线程就被唤醒了。
被唤醒后因线程管理需要,标识当前进程的已准备线程数ready_threads需要减一。
// frameworks/native/cmds/servicemanager/binder.c#binder_thread_read
//可用线程数-1,因为线程被唤醒才会走到此处
if (wait_for_proc_work)
proc->ready_threads--;
thread->looper &= ~BINDER_LOOPER_STATE_WAITING;
思考下这个目标线程为什么会被唤醒我们就不难知道,其todo上的binder任务将被取出来处理。
// frameworks/native/cmds/servicemanager/binder.c#binder_thread_read
//被唤醒之后尝试从thread/proc的todo链表中取出binder_work
if (!list_empty(&thread->todo))
w = list_first_entry(&thread->todo, struct binder_work, entry);
else if (!list_empty(&proc->todo) && wait_for_proc_work)
w = list_first_entry(&proc->todo, struct binder_work, entry);
else {
if (ptr - buffer == 4 && !(thread->looper & BINDER_LOOPER_STATE_NEED_RETURN)) /* no data added */
goto retry;
break;
}
从上边代码可知,这个目标线程被唤醒后不仅可以处理线程todo链表上待处理的任务,代表进程的proc的todo链表如果有任务待处理,在此也可以被取出来处理。这个todo链表上的待处理任务的节点类型是binder_work,我们可以根据binder_work的type字段确认当前节点的任务类型。
// frameworks/native/cmds/servicemanager/binder.c#binder_thread_read
switch (w->type) {
case BINDER_WORK_TRANSACTION: {
t = container_of(w, struct binder_transaction, work);//根据binder_work取出其依附于的binder_transation
} break;
case BINDER_WORK_TRANSACTION_COMPLETE: {
cmd = BR_TRANSACTION_COMPLETE;//由此可知,此命令是有binder驱动发出的,并且与BR_TRANSATION、BC_REPLY呈对应关系
//把cmd存入ptr指向的地址
if (put_user(cmd, (uint32_t __user *)ptr))
return -EFAULT;
ptr += sizeof(uint32_t);
//统计计数
binder_stat_br(proc, thread, cmd);
//log打印
binder_debug(BINDER_DEBUG_TRANSACTION_COMPLETE,
"%d:%d BR_TRANSACTION_COMPLETE\n",
proc->pid, thread->pid);
//删除传输栈中的binder_work(此处删除的不是当前线程的binder_work,而是源线程)
list_del(&w->entry);
//释放binder_work内存
kfree(w);
//统计计数
binder_stats_deleted(BINDER_STAT_TRANSACTION_COMPLETE);
} break;
上述代码中我们贴出了两种type类型的处理方式:
1.BINDER_WORK_TRANSACTION。此类型标识当前要处理的任务为收到的binder事务(binder_transaction)。这个binder事务很显然是在binder_transaction()方法中传过来的BC_TRANSACTION事务。
2.BINDER_WORK_TRANSACTION_COMPLETE。此类型是用于返回一个BR_TRANSACTION_COMPLETE指令给应用上层以告知此次传输完成。对应到前边也已出现过,在binder_transaction()方法最后tcomplete就被加入当源线程的todo链表中,当源线程处理到binder_thread_read()时就会进入到此处并返回BR_TRANSACTION_COMPLETE给应用上层。
此处对于目标线程来说,则是处理BINDER_WORK_TRANSACTION,这个case中通过container_of()方法取出了binder_work节点指向的内容即binder_transaction结构体。
// frameworks/native/cmds/servicemanager/binder.c#binder_thread_read
if (t->buffer->target_node) {
struct binder_node *target_node = t->buffer->target_node;
tr.target.ptr = target_node->ptr;
tr.cookie = target_node->cookie;
t->saved_priority = task_nice(current);
if (t->priority < target_node->min_priority &&
!(t->flags & TF_ONE_WAY))
binder_set_nice(t->priority);
else if (!(t->flags & TF_ONE_WAY) ||
t->saved_priority > target_node->min_priority)
binder_set_nice(target_node->min_priority);
cmd = BR_TRANSACTION;
} else {
tr.target.ptr = 0;
tr.cookie = 0;
cmd = BR_REPLY;
}
tr.code = t->code;
tr.flags = t->flags;
tr.sender_euid = from_kuid(current_user_ns(), t->sender_euid);
当取出这个binder_transaction之后,那么之前被填充进去的binder_transaction_data就在此处被重新取出来了。在上边我们可以看到,根据buffer中是否有target_node可以区分此次是BC_TRANSACTION还是BC_REPLY,当然了,不管是BC_TRANSACTION还是BC_REPLY在此处都被我们的Binder驱动转成了BR_TRANSACTION和BR_REPLY。当然,上边还有一个关键是填充了tr的ptr与cookie字段,这样如果这个binder_transaction_data传到应用上层,就可据此找到对应的BBinder执行此次传输。此处我们补充下应用上层的代码:
// frameworks/native/libs/binder/IPCThreadState.cpp#executeCommand
//应用上层代码
case:BR_TRANSACTION:
//...
if (tr.target.ptr) {
sp<BBinder> b((BBinder*)tr.cookie);
error = b->transact(tr.code, buffer, &reply, tr.flags);
} else {
error = the_context_object->transact(tr.code, buffer, &reply, tr.flags);
}
//...
在上边取出了诸如业务码、flags类型、cmd命令外,还差最为关键的一步,就是把存放在内核空间binder_buffer中的跨进程数据给取出来。
// frameworks/native/cmds/servicemanager/binder.c#binder_thread_read
//通信数据的重新填装
tr.data_size = t->buffer->data_size;
tr.offsets_size = t->buffer->offsets_size;
tr.data.ptr.buffer = (binder_uintptr_t)(
(uintptr_t)t->buffer->data +
proc->user_buffer_offset);
tr.data.ptr.offsets = tr.data.ptr.buffer +
ALIGN(t->buffer->data_size,
sizeof(void *));
因为此处还是在Binder驱动中,所有运行的代码都运行在内核空间,源线程在驱动中申请的binder_buffer内存在目标线程也是共享、有意义的地址。可以看见上述把buffer区域地址取出来之后加上了proc->user_buffer_offset这个值,前边binder_mmap()中说过这个user_buffer_offset是当前进程用户空间地址与内核空间内存地址的偏移量,所以此处加上这个值就意味着内核空间地址补上了mmap偏移量,这样处于用户空间的应用上层就可以获取到我们取出来的binder_transaction_data了。
// frameworks/native/cmds/servicemanager/binder.c#binder_thread_read
if (put_user(cmd, (uint32_t __user *)ptr))
return -EFAULT;
ptr += sizeof(uint32_t);
//data区域及offsets区域拷贝一次,此处只不过把tr数据结构从内核区拷贝到用户区
if (copy_to_user(ptr, &tr, sizeof(tr)))
return -EFAULT;
ptr += sizeof(tr);
//删除当前binder_work(此处删除的不是当前线程的binder_work,而是源线程)
list_del(&t->work.entry);
在把binder_transaction_data结构体(data域与offsets域仅仅地址指针)拷贝到用户空间后,删除掉todo链表上的此次任务。
// frameworks/native/cmds/servicemanager/binder.c#binder_thread_read
//如果当前是TRANSATION任务且需要返回reply,则添加当前binder_transation到传输栈中,以等待bc_reply时取出
if (cmd == BR_TRANSACTION && !(t->flags & TF_ONE_WAY)) {
t->to_parent = thread->transaction_stack;
t->to_thread = thread;
thread->transaction_stack = t;//此处与binder_transation方法中BC_REPLY时的弹栈呈对应关系
} else {
t->buffer->transaction = NULL;
kfree(t);
binder_stats_deleted(BINDER_STAT_TRANSACTION);
}
在删除todo链表的此次binder_work节点之后,还需要判断当前传输事务的类型是否是非one way类型(源线程要求返回结果),如果是则需要往目标线程的transaction_stack中挂载上这个正在处理的binder事务。
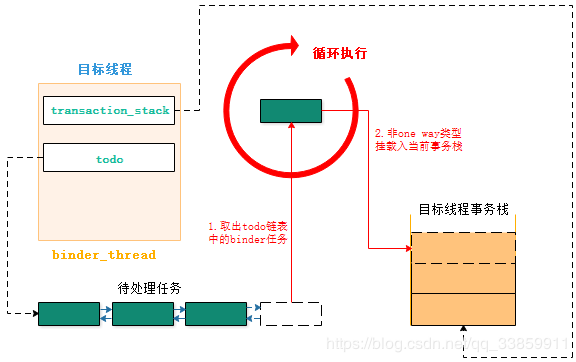
这样,整个binder_thread_read过程甚至binder_ioctl()就基本告一段落,接下来就是应用上层处理此次BR_TRANSACTION了。
以下就是应用上层处理BR_TRANSACTION的过程(已省略部分),可以看出来,应用上层把此次传输事务交给了BBinder的transact()处理,处理完成之后如果当前是非one way类型(需返回源线程处理结果),那么就调用sendReply()方法把处理结果以BC_REPLY命令形式返回给Binder驱动。
// frameworks/native/libs/binder/IPCThreadState.cpp#executeCommand
//应用上层代码
case BR_TRANSACTION://标识接收别处的BC_TRANSATION(BC_TRANSACTION经过binder驱动会被驱动改为BR_TRANSACTION)
//...
if (tr.target.ptr) {
sp<BBinder> b((BBinder*)tr.cookie);
error = b->transact(tr.code, buffer, &reply, tr.flags);
} else {
error = the_context_object->transact(tr.code, buffer, &reply, tr.flags);
}
//非ONE_WAY,需要返回reply
if ((tr.flags & TF_ONE_WAY) == 0) {
LOG_ONEWAY("Sending reply to %d!", mCallingPid);
if (error < NO_ERROR) reply.setError(error);
sendReply(reply, 0);
} else {
LOG_ONEWAY("NOT sending reply to %d!", mCallingPid);
}
sendReply()中也是以ioctl()的形式给Binder驱动写入一个BC_REPLY命令,这里我们就不贴代码了。
BC_REPLY-目标线程返回处理结果
在上边关于binder_thread_write()的解说中我们应该已经知道,目标线程返回处理结果也是在binder_transaction()方法中进行的。
// frameworks/native/cmds/servicemanager/binder.c#binder_thread_write
case BC_TRANSACTION:
case BC_REPLY: {
struct binder_transaction_data tr;
//拷贝指针
if (copy_from_user(&tr, ptr, sizeof(tr)))
return -EFAULT;
ptr += sizeof(tr);
//真正处理任务的地方,第三个参数用以标明当前是否是REPLY
binder_transaction(proc, thread, &tr, cmd == BC_REPLY);
break;
}
那么在binder_transaction()中又是如何对BC_REPLY进行处理的呢?
其实整体上来看BC_REPLY返回通信结果与BC_TRANSACTION发起跨进程通信在流程上必然有很大的相似性,只有这样我们的谷歌工程师才会将之放在同一方法中处理。可以想象BC_REPLY的处理过程大致如下:
1.找到此次BC_REPLY的目标进程/线程。
2.把传输数据binder_transaction_data填充成binder事务(binder_transaction结构体)。
3.进行必要的binder事务处理后将此binder事务以binder_work形式添加到目标线程todo链表中并唤醒线程。
接下来我们进入binder_transaction()对BC_REPLY的处理流程进行详细分析。
// frameworks/native/cmds/servicemanager/binder.c#binder_transaction
if (reply) {
//transaction_stack用于存放需要此线程正在处理的binder_transation信息(只有需要reply的才会放入此栈)
//所以reply必定对应transaction_stack的一个binder_transation任务,以下即取出栈顶任务进行比对
in_reply_to = thread->transaction_stack;
if (in_reply_to == NULL) {
return_error = BR_FAILED_REPLY;
goto err_empty_call_stack;
}
binder_set_nice(in_reply_to->saved_priority);
//栈顶任务与reply不属于同一线程时,说明reply出错
if (in_reply_to->to_thread != thread) {
return_error = BR_FAILED_REPLY;
in_reply_to = NULL;
goto err_bad_call_stack;
}
//当前线程的transaction_stack弹栈
thread->transaction_stack = in_reply_to->to_parent;
//标识binder_transation的源线程,在对应reply时当然就是reply的目标线程
target_thread = in_reply_to->from;
//如果binder_transation源线程丢失,则属于dead reply
if (target_thread == NULL) {
return_error = BR_DEAD_REPLY;
goto err_dead_binder;
}
//同样,如果源线程中存有非one_way任务binder_transation的传输栈的栈顶与当前reply的binder_transation不对应
//则说明此次reply失败
if (target_thread->transaction_stack != in_reply_to) {
return_error = BR_FAILED_REPLY;
in_reply_to = NULL;
target_thread = NULL;
goto err_dead_binder;
}
//通过以上有效性检查后,获取当前进程信息binder_proc
target_proc = target_thread->proc;
}
发送BC_REPLY的线程把transaction_stack事务栈栈顶元素in_reply_to进行弹栈,然后与源线程(即in_reply_to的from线程)的事务栈栈顶进行比较,两栈顶元素一致的话这说明此次事务传输没有出差错。
对于非one way类型的跨进程传输而言,其BC_REPLY的target_thread应当与其发起BC_TRANSACTION通信时的线程一致,这有这样阻塞式ioctl()才有意义。在上述代码中这个一致的线程就是target_thread,且进程为target_proc。
在确认了BC_REPLY的目标线程和目标进程之后,接下来的操作其实就与之前我们所介绍的BC_TRANSACTION没什么两样了。接下来就是找到目标线程的todo链表target_list及用于线程中断、唤醒之用的wait队列target_wait。
// frameworks/native/cmds/servicemanager/binder.c#binder_transaction
//寻找到target_thread之后就需要得到目标线程的双向链表todo及线程中断。唤醒用的wait
if (target_thread) {
e->to_thread = target_thread->pid;
target_list = &target_thread->todo;
target_wait = &target_thread->wait;
} else {//如只找到目标进程proc,则获取目标进程的双向链表todo及线程中断。唤醒用的wait
target_list = &target_proc->todo;
target_wait = &target_proc->wait;
}
找到了此次BC_REPLY的传输目标之后,接下来就是填充binder_transaction结构体,并把data区域和offsets区域的数据通过copy_from_user()拷贝到内核空间的binder_buffer中来。
// frameworks/native/cmds/servicemanager/binder.c#binder_transaction
//新增binder_transation,后续需要压栈
t = kzalloc(sizeof(*t), GFP_KERNEL);
if (t == NULL) {
return_error = BR_FAILED_REPLY;
goto err_alloc_t_failed;
}
//统计计数
binder_stats_created(BINDER_STAT_TRANSACTION);
//创建binder_work
tcomplete = kzalloc(sizeof(*tcomplete), GFP_KERNEL);
if (tcomplete == NULL) {
return_error = BR_FAILED_REPLY;
goto err_alloc_tcomplete_failed;
}
//统计计数
binder_stats_created(BINDER_STAT_TRANSACTION_COMPLETE);
t->debug_id = ++binder_last_id;
e->debug_id = t->debug_id;
//填充binder_transation t
//当前是reply,且任务非one_way
if (!reply && !(tr->flags & TF_ONE_WAY))
t->from = thread;
else
t->from = NULL;
t->sender_euid = proc->tsk->cred->euid;
t->to_proc = target_proc;
t->to_thread = target_thread;
t->code = tr->code;
t->flags = tr->flags;
t->priority = task_nice(current);
trace_binder_transaction(reply, t, target_node);
t->buffer = binder_alloc_buf(target_proc, tr->data_size,
tr->offsets_size, !reply && (t->flags & TF_ONE_WAY));
if (t->buffer == NULL) {
return_error = BR_FAILED_REPLY;
goto err_binder_alloc_buf_failed;
}
t->buffer->allow_user_free = 0;
t->buffer->debug_id = t->debug_id;
t->buffer->transaction = t;
t->buffer->target_node = target_node;
trace_binder_transaction_alloc_buf(t->buffer);
//target_node代表目标进程中的binder节点,此处增加引用计数
if (target_node)
binder_inc_node(target_node, 1, 0, NULL);
offp = (binder_size_t *)(t->buffer->data +
ALIGN(tr->data_size, sizeof(void *)));
//把具体数据拷贝到内核区域
if (copy_from_user(t->buffer->data, (const void __user *)(uintptr_t)
tr->data.ptr.buffer, tr->data_size)) {
return_error = BR_FAILED_REPLY;
goto err_copy_data_failed;
}
//给offp赋值,主要从用户区拷贝offsets过来
if (copy_from_user(offp, (const void __user *)(uintptr_t)
tr->data.ptr.offsets, tr->offsets_size)) {
return_error = BR_FAILED_REPLY;
goto err_copy_data_failed;
}
当我们这些填充工作都做好了之后,就把发起BC_TRANSACTION的线程的事务栈栈顶的binder_transaction给弹栈,这样整个传输过程(从发起BC_TRANSACTION到BC_REPLY返回)中涉及到的事务栈对应关系在此时就医告一段落了。
// frameworks/native/cmds/servicemanager/binder.c#binder_transaction
if (reply) {
BUG_ON(t->buffer->async_transaction != 0);
//如果是BC_REPLY,则把目标线程的传输栈中对应的binder_transation给弹栈
binder_pop_transaction(target_thread, in_reply_to);
BC_REPLY所构建的binder_transaction最终以binder_work的方式添加到发起BC_TRANSACTION的这个源线程的todo待做任务链表中去了,同时,给BC_REPLY这个线程添加一个tcomplete节点以便其给BC_REPLY的应用上层返回一个传输完成命令BR_TRANSACTION_COMPLETE。
// frameworks/native/cmds/servicemanager/binder.c#binder_transaction
t->work.type = BINDER_WORK_TRANSACTION;
//target_list即目标线程/进程的todo链表,目标线程可根据binder_work找到binder_transation
list_add_tail(&t->work.entry, target_list);
//当前线程的todo链表,本地线程则在todo队列保留待完成事务(类似存根)
tcomplete->type = BINDER_WORK_TRANSACTION_COMPLETE;
list_add_tail(&tcomplete->entry, &thread->todo);
//是否需要唤醒目标线程
if (target_wait)
wake_up_interruptible(target_wait);
接下来就是对这个最初发起BC_TRANSACTION的线程(即target_list)进行唤醒。在唤醒之后,binder_thread_read()中就开始对加到todo链表中的binder事务进行处理,这部分处理过程与之前我们说的大同小异,与之前BC_TRANSACTION修改为BR_TRANSACTION所不同的是此次是BC_REPLY被修改为BR_REPLY,并且不需要管transaction_stack这部分内容。
// frameworks/native/cmds/servicemanager/binder.c#binder_thread_read
//以下代码只处理binder_transation的情况,否则进入下次逻辑(检查是否需要睡眠)
if (!t)
continue;
BUG_ON(t->buffer == NULL);
//target_node在源线程write时填入,标识目标线程即当前读线程的binder_node
if (t->buffer->target_node) {
//...
} else {
tr.target.ptr = 0;
tr.cookie = 0;
cmd = BR_REPLY;
}
tr.code = t->code;
tr.flags = t->flags;
tr.sender_euid = from_kuid(current_user_ns(), t->sender_euid);
if (t->from) {//标识源线程
struct task_struct *sender = t->from->proc->tsk;//取出源线程tsk---tsk正是存放pid
tr.sender_pid = task_tgid_nr_ns(sender,
task_active_pid_ns(current));
} else {
tr.sender_pid = 0;//如果是one way类型的则未指定from
}
//通信数据的重新填装
tr.data_size = t->buffer->data_size;
tr.offsets_size = t->buffer->offsets_size;
tr.data.ptr.buffer = (binder_uintptr_t)(
(uintptr_t)t->buffer->data +
proc->user_buffer_offset);
tr.data.ptr.offsets = tr.data.ptr.buffer +
ALIGN(t->buffer->data_size,
sizeof(void *));
if (put_user(cmd, (uint32_t __user *)ptr))
return -EFAULT;
ptr += sizeof(uint32_t);
//data区域及offsets区域拷贝一次,此处只不过把tr数据结构从内核区拷贝到用户区
if (copy_to_user(ptr, &tr, sizeof(tr)))
return -EFAULT;
ptr += sizeof(tr);
trace_binder_transaction_received(t);
//cmd计数
binder_stat_br(proc, thread, cmd);
//删除当前binder_work(此处删除的不是当前线程的binder_work,而是源线程)
list_del(&t->work.entry);
t->buffer->allow_user_free = 1;
//如果当前是TRANSATION任务且需要返回reply,则添加当前binder_transation到传输栈中,以等待bc_reply时取出
if (cmd == BR_TRANSACTION && !(t->flags & TF_ONE_WAY)) {
//...
} else {
t->buffer->transaction = NULL;
kfree(t);
binder_stats_deleted(BINDER_STAT_TRANSACTION);
}
整个BC_TRANSACTION到BC_REPLY返回结果的完整走向图大致如下:
binder_ref与binder_node的因缘
我们知道,如果Binder Client想要与某个Binder Server通信,其必须先要获得这个Binder Server的binder实体(一般而言对于实名Binder都是从servicemanager中获得),才能与这个Binder Server进行通信。比方说我们要跟ActivityManagerService通信的话,需要先调用ServiceManager的getService()方法获取到ActivityManagerService的Binder实体,接下来才能调用ActivityManagerService的startActivity等方法。
Binder实体是不能直接跨进程传输的,它通常被Parcel打包成flag_binder_object结构体的方式,其结构体地址指针被存放到Parcel中的mObjects域中,数据被存放在这个地址指针指向的mData域,这两个域随着不断被打包最后对应到binder_transaction_data的offsets域与data域。
// frameworks/native/libs/binder/Parcel.cpp
status_t flatten_binder(const sp<ProcessState>& /*proc*/,
const sp<IBinder>& binder, Parcel* out)
{
flat_binder_object obj;
obj.flags = 0x7f | FLAT_BINDER_FLAG_ACCEPTS_FDS;
if (binder != NULL) {
IBinder *local = binder->localBinder();//localBinder方法一般本地BBinder要求重写
if (!local) {
BpBinder *proxy = binder->remoteBinder();
if (proxy == NULL) {
ALOGE("null proxy");
}
const int32_t handle = proxy ? proxy->handle() : 0;
obj.type = BINDER_TYPE_HANDLE;
obj.binder = 0; /* Don't pass uninitialized stack data to a remote process */
obj.handle = handle;
obj.cookie = 0;
} else {
obj.type = BINDER_TYPE_BINDER;
obj.binder = reinterpret_cast<uintptr_t>(local->getWeakRefs());
obj.cookie = reinterpret_cast<uintptr_t>(local);
}
} else {
obj.type = BINDER_TYPE_BINDER;
obj.binder = 0;
obj.cookie = 0;
}
return finish_flatten_binder(binder, obj, out);
}
在Parcel打包过程flatten_binder()方法中,可以看见其内部有一个Binder的关键方法localBinder(),这个方法一般要求Binder Server即BBinder对此进行重写(返回BBinder的this),如果localBinder()有值则说明是Binder服务,若为空则说明是Binder代理。在上述代码中我们可以根据type类型区分此次打包的是BBinder还是Binder代理,如果打包的是BBinder则flat_binder_object中需要关注binder及cookie字段,反之如果是Binder代理则需关注handle字段。
再回到本小节最开始的问题,我们为什么要在这里介绍binder_ref与binder_node的种种‘因缘’呢?
我们知道在binder_proc结构体中有两颗结点为binder_ref的红黑树refs_by_desc和refs_by_node,且在我们发起BC_TRANSACTION跨进程通信时会调用binder_get_ref()从refs_by_desc红黑树中去获取,那么这个binder_ref是什么时候存放进去的呢?这个问题在我们介绍BC_TRANSACTION发起跨进程通信时故意略过了,但仍有必要了解Binder是如何生成binder_ref乃至binder_node的。
事实上我们生成binder_ref与binder_node从时间上来说是比BC_TRANSACTION发起进程通信要早的。回想一下,我们想要与BBinder通信时首先需要Binder Server(BBinder)把自身以flat_binder_object的形式调用writeStrongBinder()方法写入到Parcel中,在经由Binder驱动传递给BC_TRANSACTION的发起进程(此进程以readStrongBinder()方式把Binder Server读取出来),在完成这一切之后这个BC_TRANSACTION发起进程才能与Binder Server(BBinder)进行通信。我们的binder_ref与binder_node也是在flat_binder_object首次经过驱动时就生成了。
在写入flat_binder_object后,通过ioctl()传输带有这些binder实体的数据时进入的还是binder_thread_write()的binder_transaction()方法中。binder_transaction()在把用户空间的传输数据拷贝到内核空间时同时会拷贝offsets区域的flat_binder_object(可能包含多个)地址指针。
// frameworks/native/cmds/servicemanager/binder.c#binder_transaction
binder_size_t *offp, *off_end;//标识offsets区域的起始、终止地址,据此可解析flat_binder_object(binder实体)
binder_size_t off_min;//对offsets区域解析的偏移量
//...
//给offp赋值,主要从用户区拷贝offsets过来
if (copy_from_user(offp, (const void __user *)(uintptr_t)
tr->data.ptr.offsets, tr->offsets_size)) {
binder_user_error("%d:%d got transaction with invalid offsets ptr\n",
proc->pid, thread->pid);
return_error = BR_FAILED_REPLY;
goto err_copy_data_failed;
}
在拷贝了offsets区域数据后,接下来就会对这个区域中包含的各个flat_binder_object进行解析。在解析过程中有几个变量需要关注:
offp:标识当前flat_binder_object在data区域的起始地址,这个offp是存放在offsets中的一个地址指针。
off_end:标识offsets区域的终止地址。在下边代码中“终止地址=起始地址+offsets域长度”。
// frameworks/native/cmds/servicemanager/binder.c#binder_transaction
binder_size_t *offp, *off_end;//offp标识flat_binder_object的起始地址,off_end则标识offsets域的终止地址,据此可解析flat_binder_object(binder实体)
//offs区域记录了flat_binder_object在数据区域的指针
off_end = (void *)offp + tr->offsets_size;
off_min = 0;
off_min:offsets是一大串地址指针,off_min标识当前遍历到的offsets区域的位置即对offsets区域解析的偏移量,最刚开始时此值为0。
在对offsets区域进行遍历过程中我们需要不停的对其范围进行判断。
// frameworks/native/cmds/servicemanager/binder.c#binder_transaction
//对offp指向的区域范围进行有效性判断
if (*offp > t->buffer->data_size - sizeof(*fp) ||
*offp < off_min ||
t->buffer->data_size < sizeof(*fp) ||
!IS_ALIGNED(*offp, sizeof(u32))) {
binder_user_error("%d:%d got transaction with invalid offset, %lld (min %lld, max %lld)\n",
proc->pid, thread->pid, (u64)*offp,
(u64)off_min,
(u64)(t->buffer->data_size -
sizeof(*fp)));
return_error = BR_FAILED_REPLY;
goto err_bad_offset;
}
这些范围判断主要分为:
1.*offp > t->buffer->data_size - sizeof(*fp)。offp是data域flat_binder_object的起始地址,所以offp后一定要足够一个flat_binder_object结构体的长度,此处就是判断是否足够。
2.*offp < off_min。offp在offsets域中是否小于已经遍历过的位置。
3.t->buffer->data_size < sizeof(*fp)。data区域长度是否小于一个flat_binder_object结构体的长度,如小于则根本存放不下一个flat_binder_object。
4.!IS_ALIGNED(*offp, sizeof(u32))。*offp是否是一个32位的地址指针。
如果以上条件都满足则说明此次遍历有效,接着就把flat_binder_object从data域取出,并对off_min进行偏移。
// frameworks/native/cmds/servicemanager/binder.c#binder_transaction
//取出offp指向的data区域的数据
fp = (struct flat_binder_object *)(t->buffer->data + *offp);
//off_min进行偏移
off_min = *offp + sizeof(struct flat_binder_object);
当flat_binder_object被取出来时候,需对其type类型进行判断,这个flat_binder_object是一个BBinder还是一个Binder代理。
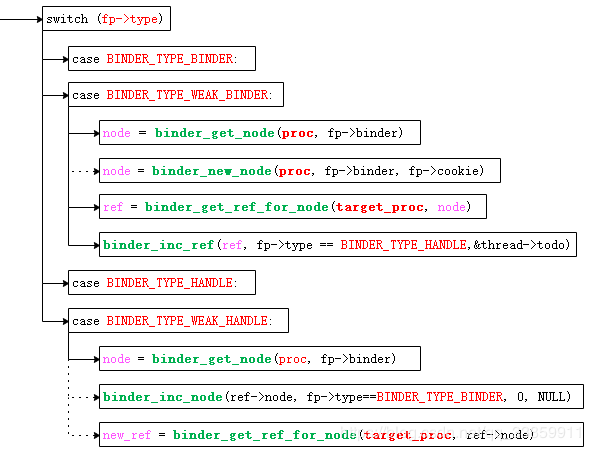
BINDER_TYPE_BINDER/BINDER_TYPE_WEAK_BINDER:
对于属于BBinder的情况,其具体代码如下:
// frameworks/native/cmds/servicemanager/binder.c#binder_transaction
case BINDER_TYPE_BINDER:
case BINDER_TYPE_WEAK_BINDER: {//在framework层标识binder_type为binder,即表示需在此创建binder_node
struct binder_ref *ref;
//查看binder驱动对于proc标识进程的本地binder_node记录,如果没有记录则新建一个
struct binder_node *node = binder_get_node(proc, fp->binder);
if (node == NULL) {
node = binder_new_node(proc, fp->binder, fp->cookie);
if (node == NULL) {
return_error = BR_FAILED_REPLY;
goto err_binder_new_node_failed;
}
node->min_priority = fp->flags & FLAT_BINDER_FLAG_PRIORITY_MASK;
node->accept_fds = !!(fp->flags & FLAT_BINDER_FLAG_ACCEPTS_FDS);
}
//地址判断
if (fp->cookie != node->cookie) {
binder_user_error("%d:%d sending u%016llx node %d, cookie mismatch %016llx != %016llx\n",
proc->pid, thread->pid,
(u64)fp->binder, node->debug_id,
(u64)fp->cookie, (u64)node->cookie);
goto err_binder_get_ref_for_node_failed;
}
//binder权限判断
if (security_binder_transfer_binder(proc->tsk, target_proc->tsk)) {
return_error = BR_FAILED_REPLY;
goto err_binder_get_ref_for_node_failed;
}
//在经过有效性判断之后,从目标进程取出对node的引用,没有即创建并返回ref,
//当然,此处返回的ref其实只判空确定是否成功,除此无其他作用
ref = binder_get_ref_for_node(target_proc, node);
if (ref == NULL) {
return_error = BR_FAILED_REPLY;
goto err_binder_get_ref_for_node_failed;
}
//因为跨进程,需改变BINDER_TYPE
if (fp->type == BINDER_TYPE_BINDER)
fp->type = BINDER_TYPE_HANDLE;
else
fp->type = BINDER_TYPE_WEAK_HANDLE;
fp->handle = ref->desc;
binder_inc_ref(ref, fp->type == BINDER_TYPE_HANDLE,
&thread->todo);
} break;
可以看见处于BBinder这种情况时其首先尝试使用binder_get_node()方法从当前进程proc红黑树nodes中获取binder_node,如果获取为空,则说明当前进程还没有BBinder所对应的binder_node,所以通过binder_new_node()为其新建一个。
target_proc标识了当前传输任务的目标进程,在完成binder_node的获取之后,接着尝试使用方法binder_get_ref_for_node()获取目标进程中的binder_ref。
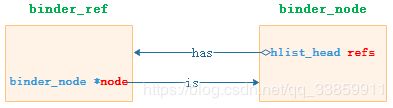
binder_ref内部包含一个node字段指向其对应的binder_node,而binder_node中则包含一个链表refs,刚才的binder_ref是refs中的一个结点。
binder_get_ref_for_node()内部其实很有意思,这个方法内部首先从目标进程proc中的红黑树refs_by_node中查询是否有无对应binder_node的binder_ref。若没有则创建一个binder_ref并根据这个binder_ref指向的node添加到refs_by_node红黑树,根据目标进程红黑树refs_by_desc中最大的handle值添加一个binder_ref到这个目标进程的refs_by_desc中。
// frameworks/native/cmds/servicemanager/binder.c#binder_get_ref_for_node
new_ref->desc = (node == binder_context_mgr_node) ? 0 : 1;
for (n = rb_first(&proc->refs_by_desc); n != NULL; n = rb_next(n)) {
ref = rb_entry(n, struct binder_ref, rb_node_desc);
if (ref->desc > new_ref->desc)
break;
new_ref->desc = ref->desc + 1;
}
从上边代码可知,这个新建的binder_ref的handle值是红黑树中最大的handle值加上一(排除servicemanager情况,如果是servicemanager,则handle值恒为0)。
至此这个binder_ref已经准备OK,在转换这个flat_binder_object的type之后,传递到应用上层,即可为接下来的BC_TRANSACTION发起通信建立基础。
BINDER_TYPE_HANDLE/BINDER_TYPE_WEAK_HANDLE:
对于Binder代理写入驱动的情形则简单的多。
// frameworks/native/cmds/servicemanager/binder.c#binder_transaction
case BINDER_TYPE_HANDLE:
case BINDER_TYPE_WEAK_HANDLE: {
struct binder_ref *ref = binder_get_ref(proc, fp->handle);
if (ref == NULL) {
return_error = BR_FAILED_REPLY;
goto err_binder_get_ref_failed;
}
//binder权限判断
if (security_binder_transfer_binder(proc->tsk, target_proc->tsk)) {
return_error = BR_FAILED_REPLY;
goto err_binder_get_ref_failed;
}
//是否属于同一进程
if (ref->node->proc == target_proc) {
if (fp->type == BINDER_TYPE_HANDLE)
fp->type = BINDER_TYPE_BINDER;
else
fp->type = BINDER_TYPE_WEAK_BINDER;
fp->binder = ref->node->ptr;
fp->cookie = ref->node->cookie;
binder_inc_node(ref->node, fp->type == BINDER_TYPE_BINDER, 0, NULL);
} else {
struct binder_ref *new_ref;
//寻找或添加ref到target_proc
new_ref = binder_get_ref_for_node(target_proc, ref->node);
if (new_ref == NULL) {
return_error = BR_FAILED_REPLY;
goto err_binder_get_ref_for_node_failed;
}
fp->handle = new_ref->desc;
binder_inc_ref(new_ref, fp->type == BINDER_TYPE_HANDLE, NULL);
}
} break;
这种情形直接从当前进程proc的红黑树refs_by_desc中尝试获取对应handle值的binder_ref。获取到之后分为两种情况:
1.当前通信的目标进程与binder_ref代理对应的binder_node进程(Binder Server)是同一进程,那么只需把binder_ref所对应的binder_node取出来,把其ptr与cookie赋值给flat_binder_object即可,这样就可直接与binder_node所对应的BBinder进行通信。
2.若当前通信的目标进程即非binder_ref代理对应的Binder Server进程,也不是当前进程,则需要为这个第三方进程创建一个新的binder_ref,然后才能与这个第三方进程进行通信。
至此,Binder驱动的主要流程已经介绍完毕。
后记
在经历数月闲余时间的源码阅读和间歇性写作之后,这篇文章才得已成形,这期间对源码的理解不断提升可能导致文章前边部分与后边有些脱节,请读者见谅!