mysql-北京林业大学
1.内连接

2.内连接和外连接的不同
外连接不符合条件的记录也会作为Null返回 内连接不符合条件的记录不显示
3.自连接
把一张表看成两张表,比如,把一张表的两个字段交换值,可以使用自连接
实际场景,之前的数据存储错了,把最大值最小值两个字段存反了,改完代码之后要对之前的数据进行处理
解决办法,使用自连接
UPDATE pf1001 a,
pf1001 b
SET a.MAXVALUE = b.minValue,
a.minValue = b.MAXVALUE
WHERE
a.id = b.id
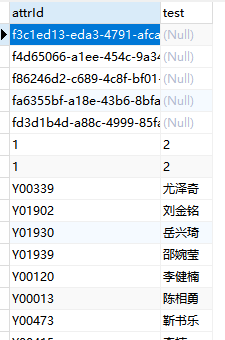
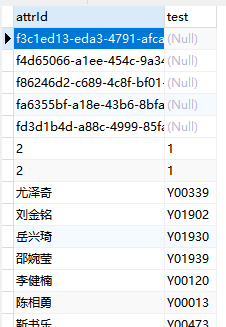
AND a.id >= 498下边是亲测有效的sql和对比图
sql
update pftest a,pftest b
set a.attrId = b.test,a.test = b.attrId
where a.attrId=b.attrId and b.test is not null
执行前 执行后
4.in和多表查询
可以转换
SELECT
*
FROM
T
WHERE
Tno IN ( SELECT Tno FROM TC WHERE TC.NO = 5 )
可以替换为
SELECT
*
FROM
T,
TC
WHERE
T.Tno = TC.NO
AND TC.NO =5
5.sql练习
需求1 找出一张表里,其他系任意大于计算机系某一教师的工资
SELECT
salary
FROM
pf1089
WHERE
salary > ( SELECT min( salary ) FROM pf1089 AND zhuanye = "计算机" )
AND zhuanye != "计算机"
注意需求 任意大于 就是大于最低的那个
其他系 就是不是计算机的那个系需求2 找出一张表里,其他系比计算机系所有教师都高的工资
SELECT
salary
FROM
pf1089
WHERE
salary > ( SELECT max( salary ) FROM pf1089 AND zhuanye = "计算机" )
AND zhuanye != "计算机"
注意需求 比所有都高 就是找出最高的那个
6.exists
exists返回的是 真 假 不是具体数据
所以
有case when exists then else end
也有case when not exists then else end当单独使用时,他的执行顺序是一个循环比对关系
相关子查询,查询多次,依赖外部查询:只要存在条件满足,就查询
他是循环从a001里边拿记录 对比这条记录 在子查询条件中成不成立 与普通的子查询不同,普通的子查询是先执行子查询再执行父查询,而且 普通子查询(非相关子查询)只执行一次
如果成立 exists返回true 这条记录会出现在结果集中
如果不成立 exists返回false 这条记录不会出现在结果集中
也就是说,在相关子查询中,子查询要执行若干次,这个次数,与父查询中表的行数相等
SELECT
*
FROM
a001
WHERE
EXISTS ( SELECT * FROM a002 WHERE a002.a001id = a001.a001id )
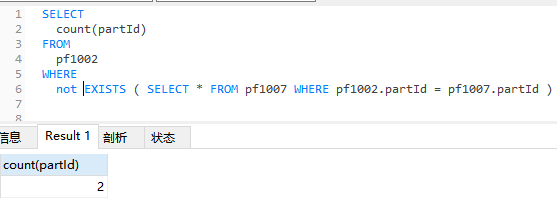
7.exists与not exists
执行逻辑相同 下边这张表一共37条数据 分别exists和not exists对比

8.select into from的坑
执行失败
select attrId into pftest from pf1001
网上搜索结果如下
然而今天在使用 SELECT INTO FROM 备份mysql数据表的时候,
运行相关 sql 语句的时候却一直返回 [Err] 1327 - Undeclared variable: ......
这种错误,实在不解,经过查询相关资料才知道,
原来 mysql 数据库是不支持 SELECT INTO FROM 这种语句的,
但是经过研究是可以通过另外一种变通的方法解决这个问题的,
下面就来说说解决这个错误的办法吧!
进过搜索相关资料以及实验结果证实,可以使用
Create table Table2 (Select * from Table1);
或者是insert into 接子查询确实ok
执行之后会创建一张表 表名为pftest 字段就是子查询查出来的字段


9.按顺序删除第几行到第几行的数据
DELETE
FROM
pftest
WHERE
attrId IN
( SELECT * FROM ( SELECT attrId FROM pftest ORDER BY attrId LIMIT 1, 100 ) a )
包了一层 select * from 是因为报子查询中不能有limit
后边起了一个 a 的别名是因为报 Every derived table must have its own alias10.复习一下insert into
insert into pftest (attrId,test) VALUES("1","2")或者 insert into 后边还可以跟子查询 把查询到的数据插入到表中
这个知识点可以跟create table tablename (子查询) 做对比
两者差别是create table会创建出一张表 但是insert into是已经存在表
两者共同点是都会把子查询结果插入到表
insert into pftest (select userId as attrId,userName as test from pf1011)11.给字符串字段拼接指定字符串
concat函数
update pftest set attrId=concat(attrId,'456')
拼接后

12.视图
视图概念 联想到内联视图 概念有点像 本质也差不多

13.索引

用过的索引 唯一索引 普通索引
主键不用建索引 默认就是唯一索引

下边是增删查索引操作sql
#给表pftest的test字段建立索引且索引名称是t
create index t on pftest(test)
#查询表pftest的所有索引
show index from pftest
#删除pftest的索引t
drop index t on pftest
#给pftest的attrId字段建立唯一索引,索引名称是t2
create UNIQUE INDEX t2 on pftest(attrid)
14.having
在group by之后做查询
例子 查询分类统计数量大于1的数据
select attrId from pftest GROUP BY attrId HAVING count(attrId)>1继续,删除
直接delete from 删除上边查询出来的数据报错
You can't specify target table 'pftest' for update in FROM clause解决办法 用中间表select一下
这个和第9个知识点删除从第几条到第几条的数据比较像
子查询都起了临时表名 都用select * 做了中间表
delete from pftest where attrid in(select * from (
select attrId from pftest GROUP BY attrId HAVING count(attrId)>1) a
)