MySQL学习总结:SQL语句
SQL(结构化查询语言):
通过DBMS用来管理DB的标准查询语言,可以对数据库进行创建,删除,操纵等操作。
SQL语言分为五种语句:
DDL(Data Definition Language) 数据定义语言
DML(Data Manipulation Language) 数据操纵语言
DCL(Data Control Language) 数据操纵语言
TCL(Transation Control Language) 事物控制语言
DQL(Data Query Language) 数据查询语言
目录
1、DDL
1.1、create:建表
1.2、alter:修改表结构(字段)
1.3、drop:删除表结构
1.4、truncate:清空表结构
2、DML
2.1、insert into 插入数据
2.2、delete 删除表数据
2.3、update 修改表数据
3、DQL
3.1、where子句
3.2、order by子句
3.3、分组查询和分组函数(聚合函数)
3.4、having子句
3.5、去重查询:distinct
3.6、别名的用法
4、DCL
4.1 、创建用户
4.2 、授予权限
4.3 、撤销权限
4.4、删除用户
5、TCL
1、DDL
用来创建,删除,修改清空"数据表结构"的。
包含关键字:create、alter、drop、truncate
1.1、create:建表
语法: create table tname(
fName1 Type,
fName2 Type,
....
fNameN Type
);
案例:
CREATE TABLE student (
sid INT,
sname VARCHAR ( 20 ),
sgender CHAR ( 1 ),
birth date,
score FLOAT ( 5, 2 )
);1.2、alter:修改表结构(字段)
1.2.1、添加表字段
语法:alter table tname add fname type;
案例:向student中追加school字段:
ALTER TABLE student ADD school VARCHAR ( 20 );1.2.2、删除多余的表字段
语法:alter table tname drop fname;
案例:删除school字段:
ALTER TABLE student DROP school;1.2.3、修改字段名,可以同时修改类型
语法:alter table tname change oldName newName type;
案例:将birth字段修改为sbirth:
ALTER TABLE student CHANGE birth birth date;1.2.4、修改表名
语法:alter table oldName rename newName;
案例:将student修改为student_01:
ALTER TABLE student RENAME student_01;
1.2.5、复制表(包括表内数据)
语法:create table tname2 as select * from tname1;
案例:将student_01复制一份为student:
CREATE TABLE student AS SELECT * FROM student_01;仅复制表结构:
语法::create table newName like oldName;
CREATE TABLE student_02 LIKE student;1.3、drop:删除表结构
语法:drop table tname
案例:删除student_01:
DROP TABLE student_01;1.4、truncate:清空表结构
即清空表中的所有记录,无法回收
语法:truncate table tname;
案例:清空student表:
TRUNCATE TABLE student;2、DML
对表中的数据进行增加,删除,修改操作。
包含关键字:insert into、delete、update
2.1、insert into 插入数据
语法1:所有字段都赋值
insert into tname values (val1,val2,...valN);
案例1:插入学生的信息
INSERT INTO student VALUES( 20150123, '张三', 'm', '2008-8-8', 99.5 );语法2:部分字段赋值,其他字段值默认是null
insert into tname (fname1,fname2) values (v1,v2);案例2:插入学生的信息
INSERT INTO student ( sname, sgender ) VALUES ( '李四', 'm' );
INSERT INTO student VALUES ( NULL, '王五', 'm', NULL, NULL );2.2、delete 删除表数据
语法1:删除所有记录
delete from tname;
案例1:删除student表内的记录
DROP TABLE student_02;语法2:删除指定记录
delete from tname where 条件
案例2:删除student_02表中的姓名为'李四'的记录
DELETE FROM student_02 WHERE sname = '李四';2.3、update 修改表数据
2.3.1、语法1:修改某一列上的所有数据
update tname set fname1=v1,fname2=v2;
案例1:修改student中score字段的值为100
UPDATE student SET score = 100;语法2:按照条件修改数据。
update tname set fname1=v1,fname2=v2 where 条件
UPDATE student SET birth = '2000-10-9' WHERE sname = '李四';2.3.2、当null作为条件,或者修改数据为null时的操作
案例1:将生日为null的记录的分数改为80分
UPDATE student SET score = 80 WHERE birth IS NULL;案例2:将张三的性别修改为null
UPDATE student SET sgender = NULL WHERE sname = '张三';3、DQL
用来查询表中的数据
关键字:select
语法:select fname1,fname2,....fnameN from tname;
select * from tname; *:通配符,表示所有字段。
案例1:查询student表中姓名,性别,分数
SELECT sname, sgender, score FROM student;基本查询语句基本格式:select.. from...[where..][group by...][having...][order by...]
子句执行顺序 (1)from (2)where (3)group by (4)having (5)select (6)order by
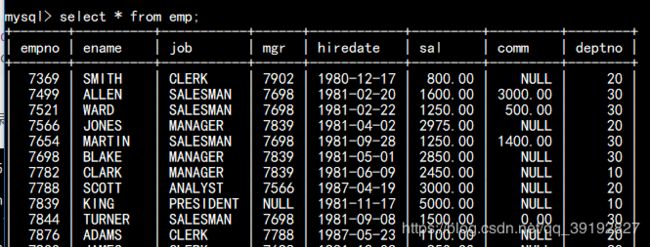
现有部门表与职工表
3.1、where子句
3.1.1、关系运算符:>,>=,<,<=,=,!=,<>
案例1:查询工资大于2000的所有员工的编号,姓名,职位
select empno,ename,job from emp where sal >2000;案例2:查询姓名不是JONES的所有员工信息
select * from emp where ename!='jones';3.1.2、多条件连接符:and、or
案例1:查询20号部门工资大于1500的员工编号、姓名,工资,部门号
select empno,ename,sal,deptno from emp where deptno=20 and sal>1500;案例2:查询20号部门姓名是smith和scott员工的所有信息
select * from emp where deptno=20 and (ename='smith' or ename='scott');案例3:查询20部门所有员工的信息或者是工资大于1500的所有员工信息
select * from emp where deptno=20 or sal>1500;3.1.3、范围查询: [not] between .. and..
案例1:查询工资大于等于1500并且小于等于2500的所有员工信息
select * from emp where sal between 1500 and 2500;
select * from emp where sal >= 1500 and sal <= 2500;案例2:查询工资小于1500或者是大于2500的员工信息
select * from emp where sal not between 1500 and 2500;
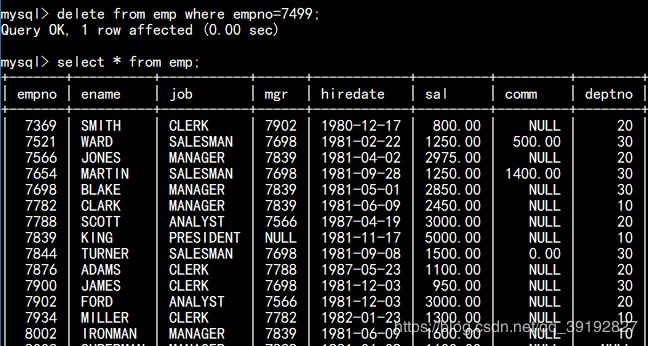
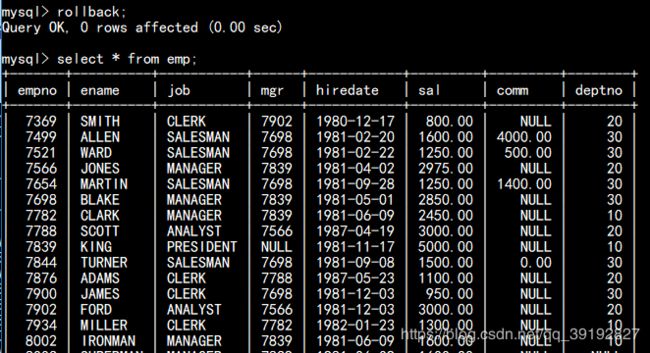
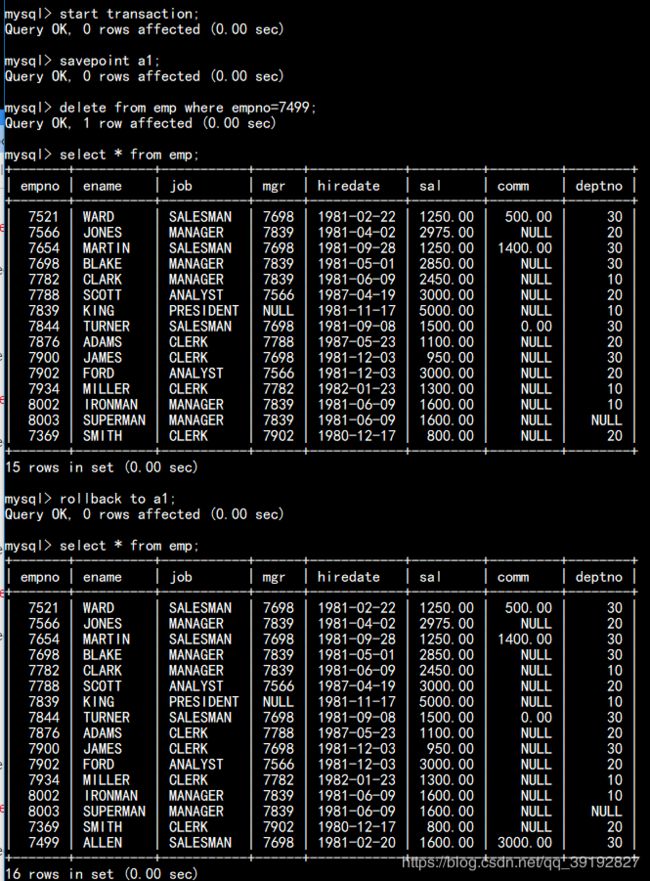
select * from emp where sal < 1500 or sal > 2500;3.1.4、集合操作:in (集合数据)、not in(集合数据) 案例1:查询20和30部门的所有员工 案例2:查询除了20号和30号部门其他部门的员工姓名,职位,领导编号 案例3:查询工资大于james,martin,turner这三个员工的姓名和工资(all中不能放数值,如sal>all(1500,3000)是错误的) 案例4:查询工资大于james,martin,turner这三个员工中的任意一个的员工的姓名和工资 3.1.5、模糊查询 like 通配符:% :匹配0个或0个以上的任意字符 案例1:查询姓名首字母为j的员工的编号,姓名,职位,部门号 案例2:查询职位名称中有a的,并且工资大于2500的员工姓名,职位,工资,部门号。 对需要所显示出来的字段数据进行排序; 排序规则有升序/降序;关键字:ASC表示升序,DESC表示降序;默认不写时为升序。 语法:order by field1 asc|desc[,field2 asc|desc][...] 案例1:查看有奖金的员工的姓名,职位,奖金,按照奖金升序排序 案例2:查看所有员工信息,按照部门升序,工资降序排序 3.3.1、分组查询 语法:group by field1[,field2][...] 3.3.2、分组函数 sum(field):统计此字段的和。 max(field):统计此字段的最大值 min(field):统计此字段的最小值 avg(field):统计此字段的平均值 count(field):统计此字段的记录数.因为会忽略空值,因此在决定字段时,我们使用通配符*来代替 1)分组函数忽略空值(字段值为空值的记录不统计在内) 因此需要视情况而定是否需要使用空值处理函数:ifnull(field,val)如果field的值是null,我们就使用val否则使用本身。 2)在做分组查询时,select子句中,除了分组函数不能写其他字段。 3)使用分组函数,一定是分组查询。当不使用group by子句,而使用分组函数,则视整张表为一组。 案例1:统计员工表中的所有员工的工资之和 案例2:统计20号部门的工资之和,最高工资,最低工资,总人数 案例3:查询每个部门的平均工资,平均奖金,奖金之和,工资之和,总人数 案例4:按照部门和职位分组查看每组中的人数和平均工资 对分组查询再一次过滤,having子句一定要跟在group by子句后面。 案例1:查询平均工资大于1700的部门号与平均工资 案例2:查询职位的平均工资,最高工资,分别大于1500和2500的职位、平均工资,最高工资,工资之和,总人数。 distinct关键字必须放到select关键字之后 案例:查询员工表中有那些职位 列别名:select子句中的字段可以使用别名 select avg(ifnull(sal,0)) [as] nickName,....... 表别名:from子句中的表也可以使用别名 from tableName nickName 案例1:查询所有的员工的姓名,职位,工资 案例2:查询部门工资之和大于1750的部门号,与工资之和,按照工资之和降序排序 关键字:create user、grant、revoke、drop user 语法: create user username@ip identified by newPwd; 语法:grant 权限1,权限2... on 数据库名.* to username@ip; 案例:授予创建表,修改表,插入数据三个权限给scott,针对于bd1705数据库 语法:revoke 权限1,权限2..on 数据库名.* from username@ip; 案例1:撤销scott用户的修改表结构的权限 案例2:修改密码 使权限立即生效 有时可能需要使用DML进行批量数据的增删改。比如,在一个员工系统中,我们想删除一个人的信息。除了删除这个人的基 本信息外,还应该删除与此人有关的其他信息,如邮箱,地址等等。那么从开始执行到结束就会构成一个事务。 事务遵循符合四个条件(ACID): 原子性(Atomicity):事务要么成功,要么撤回。不可切割性。 一致性(Consistency):事务开始前和结束后,要保证数据的一致性。转账前账号A和账号B的钱的总数为10000;转账后账号A和账号B的前的总数应该还是10000。 隔离性(Isolation):当涉及到多用户操作同一张表时,数据库为会每一个用户开启一个事务。那么当其中一个事务正在进行时,其他事务应该处于等待状态。保证事务之间不会受影响。 持久性(Durability):当一个事务被提交后,我们要保证数据库里的数据是永久改变的。即使数据库崩溃了,我们也要保证事务的完整性。 存储引擎:就是表的类型。innoDB:mysql主流的存储引擎,支持事务;Myisam: 不支持事务。 关键字:commit:提交、rollback:撤回,回滚、savepoint:保存点 mysql数据库每次执行完DML操作时,会默认commit 事务的验证:取消默认提交。 在workbench中开启事务,更新7499号员工奖金为4000 此时在控制台中登录root用户开启事务,再次更改7499号员工奖金为2000 出现更新错误 在workbench中commit一下 此时控制台中查看emp表 7499号员工的comm没有更改,因为此时select的是在控制台开启事务时的表数据 提交后重开一个事物,数据更新了 删除7499号员工的信息 回滚之后数据恢复: 使用savepoint可以回滚到指定位置
>all(集合数据)、select * from emp where deptno in (20,30);
select * from emp where deptno = 20 or deptno = 30;select ename,job,mgr,deptno from emp where deptno not in (20,30) or deptno is null;
select ename,job,mgr,deptno from emp where deptno<>20 and deptno<>30 or deptno is null;
select ename,sal from emp where sal>all(
select sal from emp where ename in('james','martin','turner'));select ename,sal from emp where sal>any(
select sal from emp where ename in('james','martin','turner'));
_ :匹配1个任意字符select empno,ename,job,deptno from emp where ename like 'j%';select ename,job,sal,deptno from emp where job like '%a%' and sal>2500;3.2、order by子句
select ename,job,comm from emp where comm >0 order by comm;select * from emp order by deptno asc,sal desc;3.3、分组查询和分组函数(聚合函数)
select sum(sal) from emp;select deptno,sum(sal),max(sal),min(sal),count(*) from emp where deptno=20;select deptno,avg(ifnull(sal,0)),avg(ifnull(comm,0)),
sum(comm),sum(sal),count(*) from emp group by deptno;
select deptno,job,count(*),avg(ifnull(sal,0)) from emp group by deptno,job;3.4、having子句
select deptno,avg(ifnull(sal,0)) from emp group by deptno
having avg(ifnull(sal,0))>1700;
select job,avg(ifnull(sal,0)),max(sal),sum(sal),count(*) from
emp group by job having avg(ifnull(sal,0))>1500 and max(sal)>2500;3.5、去重查询:distinct
select distinct job from emp;3.6、别名的用法
select e.ename '姓名', e.job '职位', e.sal '薪水' from emp e;select deptno,sum(sal) s from emp group by deptno having s>1750 order by s desc;
4、DCL
4.1 、创建用户
create user 'scott'@localhost IDENTIFIED by '123456';4.2 、授予权限
grant create,alter,insert on bd1705.* to 'scott'@localhost;
show grants for 'scott'@localhost;4.3 、撤销权限
revoke alter on bd1705.* from scott@localhost;alter user scott@localhost identified by '111111';4.4、删除用户
drop user scott;flush privileges;
5、TCL
第一步:start transaction
第二步:savepoint 保存点名称。
第三步:DML
第四步:commit/rollback;start transaction;
update emp set comm=4000 where empno=7499;
commit;