二、商品微服务数据库设计
一、商品相关表概念简介
1.什么是SKU
SKU是库存进出计量的单位, 可以是以件、盒、托盘等为单位。在服装、鞋类商品中使用最多最普遍。 例如纺织品中一个SKU通常表示:规格、颜色、款式。也就是说SKU通过规格、颜色、款式来将一种产品拆分成多个“品种”,而库存量是通过一种SKU品种来进行计算的。
2.什么是SPU
SPU指的是一种商品,用于区分不同品种商品的一种计量单位。
3.案例区分SPU和SKU
Oppo R17是商品的SPU,这里的SPU是一组商品的属性组合,如【硬件参数】、【尺寸】、【摄像头】、【显示屏】、【操作系统】等等这些属性构成了一个SPU、这个SPU属性组合的名称叫做Oppo R17。
spu : 包含在每一部 oppo r17 的属性集合, 与商品是一对一的关系
sku : 影响价格和库存的 属性集合, 与商品是多对一的关系,即一个商品有多个SKU。
如流光蓝(三种颜色:流光蓝、霓光紫、霓光渐变色)+8G+128G(两种配置:8G+128G、6G+128G)。
即Oppo R17有一个SPU、6种SKU。
二、表的设计
1.表设计的字段选择
(1)主键是int还是char(假设该项目达到分库分表级别)
主键选择递增的int类型是一个最好的选择,但是对于分库分表的场景下会产生主键的冲突。使用uuid等方式可以解决主键冲突的问题,但是使用char类型的uuid来解决冲突问题会使得主键的索引效率降低,所以本项目选择使用分布式雪花算法生成id,数据库中使用bigint类型存储id。
(2)时间类型选择datetime还是timestamp
datetime类型
- 占用8个字节
- 允许为空值,可以自定义值,系统不会自动修改其值,不可设置默认值,非空时必须手动使用now()变量插入值
- 实际格式储存,与时区无关
结论:datetime类型适合用来记录数据的原始的创建时间,因为无论你怎么更改记录中其他字段的值,datetime字段的值都不会改变,除非你手动更改它。
timestamp类型
- 占用4个字节
- 允许为空值,但是不可以自定义值,所以为空值时没有任何意义。默认值为CURRENT_TIMESTAMP(),其实也就是当前的系统时间。
- TIMESTAMP值不能早于1970或晚于2037。这说明一个日期,例如'1968-01-01',虽然对于DATETIME或DATE值是有效的,但对于TIMESTAMP值却无效,如果分配给这样一个对象将被转换为0。
- 值以UTC格式保存( it stores the number of milliseconds),时区转化 ,存储时对当前的时区进行转换,检索时再转换回当前的时区。
- 数据库会自动修改其值,所以在插入记录时不需要指定timestamp字段的名称和timestamp字段的值,你只需要在设计表的时候添加一个timestamp字段即可,插入后该字段的值会自动变为当前系统时间。
结论:timestamp类型适合用来记录数据的最后修改时间,因为只要你更改了记录中其他字段的值,timestamp字段的值都会被自动更新。由于timestamp在查询的过程中存在时间的转换等一些其它自动的操作,会降低查询速度,所以如果不考虑时区的话推荐使用datetime。
2.商品详情页系统存储设计
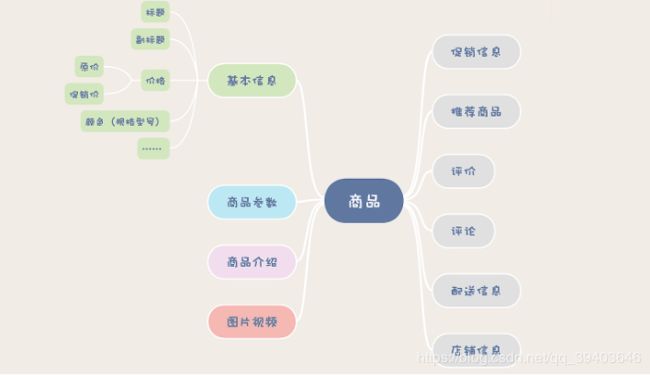
(1)产生的问题
商品详情页具有高并发、数量多,重量大的特点,小型电商可以存储到一个表(左边是商品服务提供的信息)
(2)商品基本信息存储方式
它包括商品的主副标题、价格、颜色等一些商品最基本、主要的属性。这些属性都是固定的,不太可能会因为需求或者不同的商品而变化,而且,这部分数据也不会太大。所以,还是建议你在数据库中建一张表来保存商品的基本信息。还需要在数据库前面,加一个缓存,帮助数据抵挡绝大部分的读请求。这个缓存,你可以使用 Redis,也可以用 Memcached,这两种存储系统都是基于内存的 KV 存储,都能解决问题。
(3)使用 MongoDB 保存商品参数(也可用json方式)
参数就是商品的特征。比如说,电脑的内存大小、手机的屏幕尺寸、酒的度数、口红的色号等等。和商品的基本属性一样,都是结构化的数据。但麻烦的是,不同类型的商品,它的参数是完全不一样的。
大多数数据库,都要求数据表要有一个固定的结构。但有一种数据库,没有这个要求。特别适合保存像“商品参数”这种,属性不固定的数据,这个数据库就是 MongoDB。
(4)使用对象存储保存图片和视频
图片和视频由于占用存储空间比较大,一般的存储方式都是,在数据库中只保存图片视频的ID 或者 URL,实际的图片视频以文件的方式单独存储。现在图片和视频存储技术已经非常成熟了,首选的方式就是保存在对象存储(Object
Storage)中。各大云厂商都提供对象存储服务,比如国内的七牛云、AWS 的 S3 等等,也有开源的对象存储产品,比如 MinIO,可以私有化部署。虽然每个产品的 API 都不一样,但功能大同小异
对象存储可以简单理解为一个无限容量的大文件 KV 存储,它的存储单位是对象,其实就是文件,可以是一张图片,一个视频,也可以是其他任何文件。每个对象都有一个唯一的key,利用这个 key 就可以随时访问对应的对象。基本的功能就是写入、访问和删除对象。
云服务厂商的对象存储大多都提供了客户端 API,可以在 Web 页面或者 App 中直接访问而不用通过后端服务来中转。这样,App 和页面在上传图片视频的时候,直接保存到对象存储中,然后把对应 key 保存在商品系统中就可以了。
访问图片视频的时候,真正的图片和视频文件也不需要经过商品系统的后端服务,页面直接通过对象存储提供的 URL 来访问,又省事儿又节约带宽。而且,几乎所有的对象存储云服务都自带 CDN(Content Delivery Network)加速服务,响应时间比直接请求业务的服务器更短。
(5)将商品介绍静态化
大部分用户在抢购开始之前,会一直疯狂刷新抢购商品页面,尤其是倒计时一分钟内,查看商品详情页面的请求量会猛增。此时如果商品详情页面没有做好,就很容易成为整个抢购系统中的第一个性能瓶颈。
类似这种问题,我们通常的做法是提前将整个抢购商品页面生成为一个静态页面,并 push 到 CDN 节点,并且在浏览器端缓存该页面的静态资源文件,通过 CDN 和浏览器本地缓存这两种缓存静态页面的方式来实现商品详情页面的优化。
至于商品价格、促销信息等这些需要频繁变动的信息,不能静态化到页面中,可以在前端页面使用 AJAX 请求商品系统动态获取。这样就兼顾了静态化带来的优势,也能解决商品价格等信息需要实时更新的问题。
3.主要表的详细设计
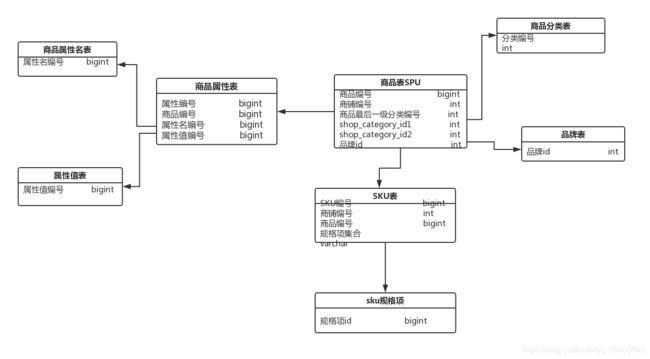
(1)商品基本设定表
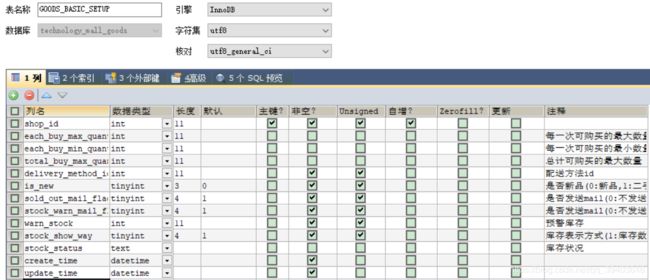
(2)商品SPU表
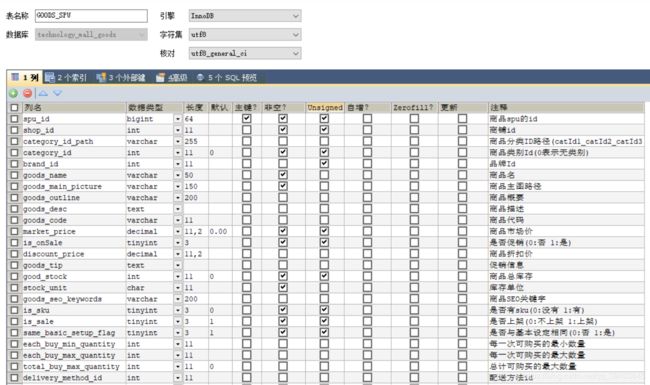
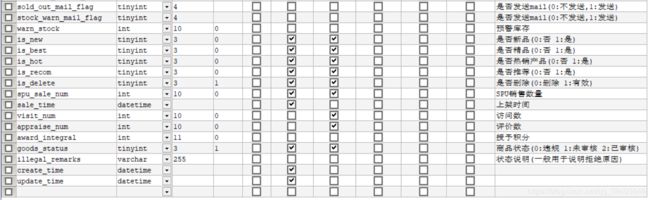
①category_id,直接对应的类别表主键ID,可以通过对分类表的递归,查询出全部路径。当商品不具有类别的时候其值为0并且goodsCatIdPath为空。
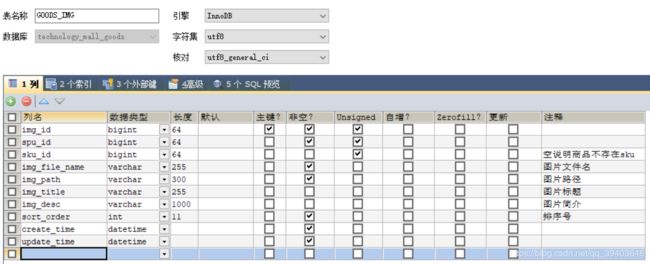
②商品主图非空,数据类型为varchar对应图片表的商品的第一张图的地址信息,是商品地址的uri
如果使用了绝对地址,例如:http://192.168.1.23/ftp/images/aaa.png,如果图片服务器的地址发生了变化,则数据库中的所有地址均需要修改,代价过高,常用方式,将“http://192.168.1.23/ftp”放在属性文件中,将“/images/aaa.png“相对路径存入数据库,解耦合。
属于反范式设计,增加了数据冗余性,却大大提高了业务查询的效率,因为商品查询时会大量用到主图,每一次都与图片表进行关联,效率会被降低。并发时,我们也可以通过缓存来提高效率。
③商品原价和商品促销价,代表11位有效数字,包含2位小数,9位整数,适用于财务级别的高精度计算。对应java类型是BigDecimal。当is_onSale为1是才具有取消价和取消信息。
④商品总库存,指的是该种商品如果没有sku时的库存。
⑤is_sku表示该商品是否具有sku属性,如果有的话需要查询sku表获取sku的详细信息。
⑥goodsSeoKeywords商品SEO关键字 ,商品查询字段
⑦same_basic_setup_flag表示是否与基本设定信息相同,当不同时读取商品表each_buy_min_quantity、each_buy_max_quantity、total_buy_max_quantity、delivery_method_id、sold_out_mail_flag、stock_warn_mail_flag、warn_stock,否则读取基本设定表的上述字段
⑧访问数和评价数同样适用了反范式设计,提高了查询的效率,并且对于数据一致性要求不高。
⑨商品状态,当店铺添加商铺后,需要进行审核,只有审核通过的商品才可以完成上架,审核失败的商品将向商品的状态说明中插入失败原因。
(3)商品分类表
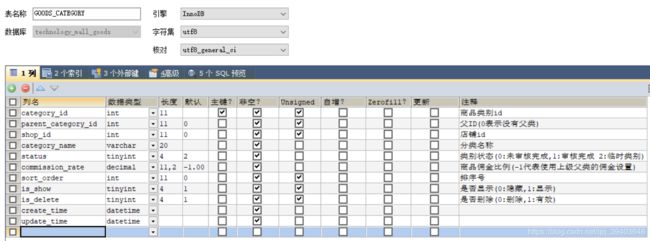
分类由超级管理员进行添加,普通管理员只可以选择,如果想要添加的话需要进行审核 。 是否审核:0 未审核完成 1审核完成 2 临时类别(管理员可以使用,但是前台用户无法看到该类别))
①采用category_id和shop_id作为复合主键,店铺新建文件夹两种方式一种完全新建(生成新的category_id),一种是选择类别文件夹(此时不新建category_id)
②设计parent_category_id字段非空,当parent_id=0时,说明是根节点,一级目录级别,并且可以实现递归查询。
③设计sort_order字段,排序编号(非空,默认为0),用于在同级别的分类显示时,规定显示顺序,如果数值相等,则自然排序。
例如根目录(parent_id=0)中有“食品“,“图书“,“家用电器”,通过sort_order的值来规定显示排序“家用电器,食品,图书”,也可以自然排序。
④commission_rate表示该类商品销售平台所获取的佣金比例,-1表示与其父类相同。
(4)商品品牌表
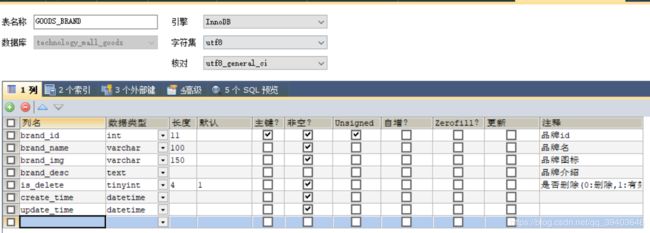
(5)SKU表
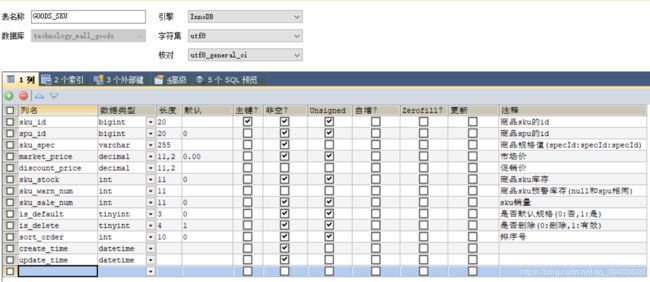
(6)sku规格项表
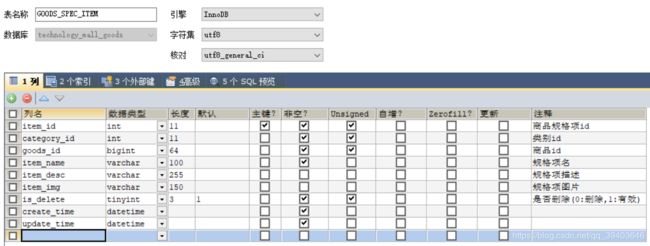
注:规格值表指的是单个sku的属性值,而属性表指的是spu的属性值
(7)商品属性名表
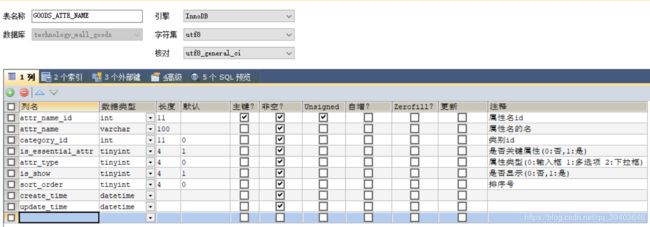
(8)属性值表
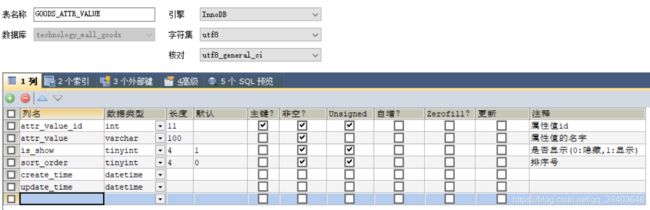
产品通过关键字搜索和属性搜索是分开的,两种搜索并不是一种解决方式,比如淘宝,在首页的搜索框是通过分词匹配宝贝标题的关键字,通过关键字的匹配程度,店铺的dsr评分权重来决定搜索结果,而属性搜索的时候则是匹配满足属性条件的宝贝。
(9)商品属性关联表
(10)图片表
图片实际访问路径 = 图片路径+图片名