视频编解码基础
1.编码的必要性
目前的视频捕获设备应用时,获得的数据量非常大。因此,为了节约存储空间,降低传输宽带占用,一般都要做编码处理。在不影响图像的客观信息表达的前提下,一般采用有损编码。图像的局部空间在一定意义上是光滑连续的,同时,图像帧间除了目标运动或者少许的光照变化之外,帧间的大部分残差很小,而且人眼对亮度比色度更敏感。上述的因素促使了视频编码的成功。
视频图像是立体场景的二维空间数据记录,在空间上是局部连续的、光滑的,而在时间上是运动持续的,连贯的。空间中的区域一致性或局部连续性允许采用少量的主信息来表达其他信息,即预测编码;时间上的运动渐变性允许帧间残差表示目标位移。因此说视频图像在空间和时间上是相关的、冗余的,编码压缩就是利用相关性去除冗余,保留图像的主要信息。
2.编码压缩原理
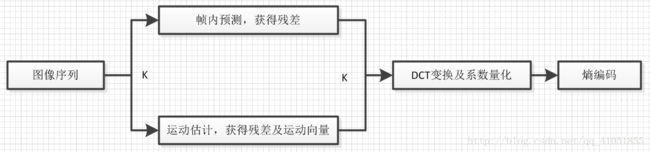
当前大部分编码算法,工作机制均是混合编码,处理模块包含预测、运动估计、变换、量化和熵编码等。不同的视频算法是各模块的不同实现方法,工作原理大同小异。总体来看,图像帧的编码模式主要有帧内和帧间两种方式。帧内编码包括预测、变换、量化和熵编码等,帧间编码包括运动估计、运动补偿、变换、量化和熵编码等。帧内预测和帧间运动估计统称预测编码。
预测编码是视频编码中最主要的方法。图像的当前像素点与帧内相邻的上、下、左、右等位置的像素点相比,灰度变化很小,相关性极强,图像存在空间冗余。视频帧是活动的图像序列,每秒含有多帧图像,当前图像点与前后帧的对应位置或者附近的像素点非常相似,相关性很强,存在时间冗余。预测编码就是减少上述的空间冗余和时间冗余,分别对应帧内编码和帧间编码。
压缩的原理图:
帧内预测编码:
帧内预测编码是对图像数据本身做编码,由于空间像素值不会突变,则我们在处理当前图像块时,可以以先前已编解码的图像作为参考,则参考的零值或较小的值会很多,起到了压缩编码的目的。帧内编码的优点是错误累积少,图像清晰,缺点是压缩倍率小。我们具体举个例子,存储一个像素的亮度值可能需要8bit,但是如果两个像素变化不大,我们可以保存第一个像素和第二个像素相对于第一个像素的变化值,这样只需要2bit,节约了码率。
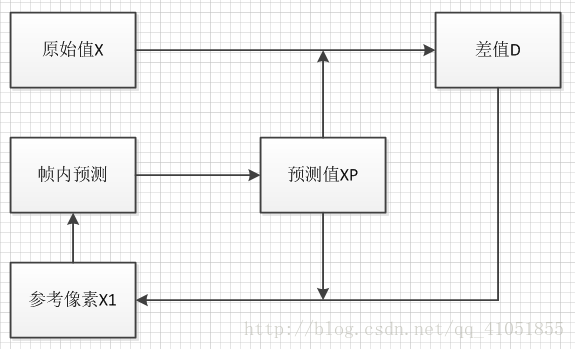
假设我们对一个像素X进行编码,此时已经有一个参考像素X1,根据X1的值,我们得到预测值XP。
用编码的像素X减去预测值XP,得到差值D,差值经过量化、编码形成最后的码流,不进行编码的话,应该是X被保存形成码流。最后,差值D和预测值XP相加,得到X1,用于下一个像素的预测。
上面介绍的就是帧内预测编码的原理了,但是根据不同的视频压缩算法标准,预测的方式也有多种。比如说MPEG-1/2/4标准的帧内预测是利用当前块的上方、左方、斜上方等已编码块的第一行或者第一列,来预测当前块的第一行或者第一列,同时除去第一个直流分量;H264标准的帧内预测则根据块的大小,16x16亮度块有四种预测模式,4x4亮度块有9种预测模式。预测值和当前值相减,得到预测残差,然后代替当前系数值,达到压缩效果。但是,如果图像细节丰富,帧内预测编码的效果不是太好。
帧间预测编码:
帧间预测编码是视频编码的主要方法,帧间编码即P帧(前向预测)编码、B帧(双向预测)编码。帧间的预测不是在当前图像帧内,而是在已编码重建帧的对应位置,或者周围作预测、搜索。帧间预测是图像在时间先后上的视频帧处理,所以非常像一个物体在运动,体现在各个视频帧中。帧间预测就是在一定窗口内搜索到最佳匹配宏块,然后这两个宏块相减得到预测残差。由于物体的实际运动轨迹并不是整数像素大小,为了更精确描述物体的运动轨迹,视频算法提出了1/2像素、1/4像素、1/8像素的运动估计,则此时得到的匹配块和运动矢量就更加精确。
(1)帧间预测基本原理
基本原理如图所示。当前帧图像f(x,y)与预测图像ft(x,y)相减后的帧误差e(x,y),经过量化器输出后输出et(x,y),进行熵编码。预测图像ft(x,y)与et(x,y)相加,得到ft1(x,y),当不计量化失真时,ft1(x,y)就是当前帧f(x,y)。把当前帧ft1(x,y)与帧存储器输出的前一帧(即参考重建帧)同时输入运动参数估值器,经搜索、比较得到运动矢量MV。MV输入运动补偿预测器,得到预测图像。
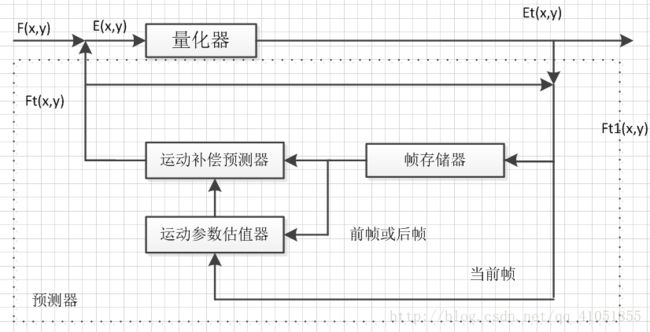
预测图像ft(x,y)不可能完全等同于当前图像f(x,y),无论预测的多么准确,总存在帧误差e(x,y)。
(2)重建图像的插值
连续运动的物体,轨迹是连续的,但像素是离散的。所以只用整数像素来表示运动物体显然是不准确的,因此有非整数像素运动轨迹之称。对于前向预测编码的参考帧来说,只要重建参考帧,就需要在此参考帧的基础上插值出多帧非整数像素运动轨迹的参考帧。例如,1/2像素运动轨迹则有四个参考帧:重建参考帧、重建参考帧的水平插值参考帧、重建参考帧的垂直参考帧、重建参考帧的斜角参考帧。
(3)运动估计算法
在以上参考帧中对当前宏块搜索最佳匹配宏块,估计出最佳运动矢量大小。运动估计算法是基于块匹配的运动估值算法,对当前编码宏块寻找最佳匹配图像宏块,同时就找到了最佳运动矢量。运动估计要解决两个问题:匹配准则和搜索算法。
常见的块匹配判断准则有平均绝对差(MAD)、差的绝对值的和(SAD)。SAD准则更为常用,值越小,表明两个块越相似。
最简单的运动估计算法有三步搜索法、对数搜索法、四步搜索法、菱形搜索法、大/小钻石搜索法、六角形搜索法等等。
由于实际物体的运动变化万千,很难用一种简单的模型去描述,也很难用一种单一的算法来搜索最佳运动矢量,因此实际上大多采用多种搜索算法相结合的办法,可以在很大程度上提高预测的有效性和鲁棒性。
H264视频标准推荐的运动估计算法,全称是非对称十字型多层次六边形格点运动搜索算法。利用了以下的多种搜索方式:第一步:非对称十字型搜索,水平搜索多于垂直方向;第二步:正方形区域搜索;第三步:中六边形模板、十字模板。
(4)运动补偿插值
根据匹配准则得到最佳匹配宏块及其运动矢量,作差运算得到残差,在计算残差时,需要根据运动矢量和参考帧类型做差值补偿。在参考帧中,对应宏块位置偏移运动矢量大小得到匹配宏块,然后根据运动矢量选择插值帧:水平插值、垂直插值、斜角插值,最后做减法运算,完成运动补偿。
变换编码:
变换编码是把时域的信号通过数学工具转换到另外一个域内,在这个新域中,信号的能量重新分布,而且能量更集中,从而便于编码压缩。平坦区域或者内容缓慢变化区域占据一幅图像的绝大部分,而细节区域或内容突变区域则占小部分。也可以说,图像中直流和低频分量占大部分,高频分量占小部分。这样,空间域的图像变换到频域,即变换域,会产生一些相关性很小的变换系数,并可以对其进行压缩编码。视频编码中变换编码的数据源有两种:图像数据本身和图像残差。
对图像做变换编码,最理想的变换运算应对整个图像进行,以便去除所有像素间的相关性。但是这样操作计算量太大,需要的临时存储区太大。实际上,往往把图像分为一定大小的块,然后以宏块为单位进行DCT变换。也正是因为以宏块为处理单位,编码后的图像有块效应,这就需要在解码视频时增加后处理以提高图像质量。H264视频编码算法在编码内部及解码端开启了环路滤波功能,提高参考帧或者解码帧的图像质量。
量化编码:
量化编码是把DCT系数除以一个常量,经过量化后的结果是量化步长的整数倍或为更多的零值,从而达到压缩的目的。H263编码方式是16x16宏块的DCT系数除以同一个量化步长,即均匀量化。在反量化时,由于量化过程取整或者四舍五入,无法还原DCT系数,从而产生失真。量化是视频编码失真的根本原因。
熵编码:
经过变换、量化之后,图像数据已经有一定程度的压缩。由于图像的DCT量化系数的相关性较小,所有系数均重要,但数据的概率分布有一定规律。熵编码就是利用概率分布规律实现无损的统计编码。基本原理:符号出现概率大的用短码字来表示,符号出现概率小的用长码字来表示,从而起到数据压缩的目的,所以熵编码又称为可变长编码VLC。
3.主流视频编码算法
目前主流的视频编码标准是MPEG-4和H264。
MPEG-4是ISO组织制定的音频编码编解码算法,主要针对网络、视频会议和可视电话等;
H264是ITU-T和ISO联合组织JVT制定的视频编解码标准,在MPEG-4中是part-10,称为AVC,在ITU中称为H264。
4.视频解码原理及
视频解码流程是编码流程的逆过程。实际上,任何一个编码器都隐含着解码器的大部分操作。
视频解码原理图:
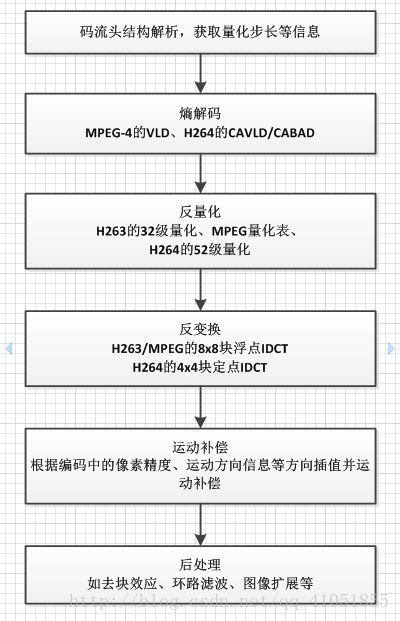
首先解析码流的头数据,获取编码图像的有关参数,包括帧编码类型(I/P)、图像宽度或高度等,后续就是以宏块为单位循环解码。熵解码是可变长编码VLC的逆操作,即VLD。H263/MPEG-1/2/4是Huffman熵编码,即通常意义上的VLD,而H264则是采用算数解码,又包括CAVLD、CABAD。另外,对于帧间编码的宏块,解码器还要解析出当前宏块的运动向量。熵编码后是反量化操作,对于不同的解码算法有着不同的反量化处理,H263采用了32级的均匀量化,即宏块数据采取一个量化步长;MPEG-4除了支持H263的均匀量化外,还增加了量化表的处理方式;H264采用了52级的均匀量化方式。反量化处理后,进行反变换IDCT,H264采取4x4的整数ICT。运动补偿是解码中的重点,因为码流统计中帧间编码为主要的编码类型,与之对应的处理就是插值运动补偿,根据从码流中解析的运动向量信息,定位参考帧的确切位置,然后计算1/2、1/4像素精度的插值,最后把结果补偿到重建帧中。最后处理是可选的去除块效应、环路滤波、图像扩展等。