数据结构-树(赫夫曼树(哈夫曼树)(最优二叉树))-C语言
哈夫曼树(Huffman Tree)是一种特殊的二叉树,这种树的所有叶子节点都带有权值,哈夫曼树的主要目的是产生叶子节点的哈夫曼编码。
哈夫曼树
- 哈夫曼树的定义
- 构造哈夫曼树
- 哈夫曼树编码
- 相关代码
- 结果图示
哈夫曼树的定义
赫夫曼大叔说,从树中一个结点到另一个结点之间的分支构成两个结点之间的路径,路径上的分支数目称做路径长度。从根结点到各个叶子结点的路径长度与相应结点的权值的乘积的和称为该二叉树的带权路径长度,记作:

如下图所示的带权二叉树:
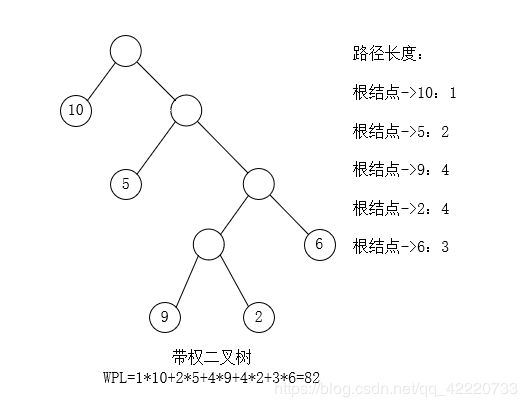
给定一组具有确定权值的叶子结点,可以构造出不同的二叉树,例如用4个整数2、3、5、8作为叶子结点的权值,共可以构造出120棵不同的二叉树,他们的带权路径长度可能不同。其中具有最小带权路径长度的二叉树称为哈夫曼树。
构造哈夫曼树
根据哈夫曼树的定义,一棵二叉树要使其WPL值最小,必须使权值大的叶子结点更靠近根结点,而权值小的叶子结点更远离根结点。
以下图都是以权值代替结点,构造大致步骤图示如下:
第一步:确定所有的叶子结点权值。
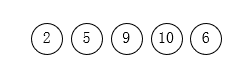
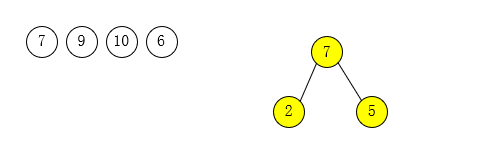
第二步:选择叶子结点权值最小的两个结点2和5作为一个新结点7的孩子结点。注意:权值相对较小的为新结点的左孩子,反之为右孩子,新节点权值=左右孩子权值之和。

第三步:将之前操作过的结点划去、新结点加入。
第四步:选择叶子结点权值最小的两个结点6和7作为一个新结点13的孩子结点。
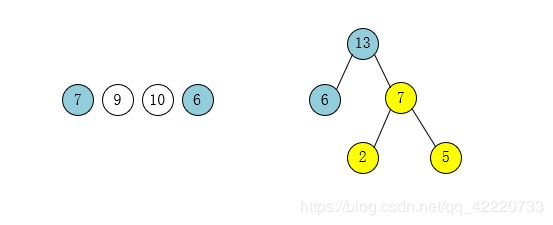
第五步:将之前操作过的结点划去、新结点加入。
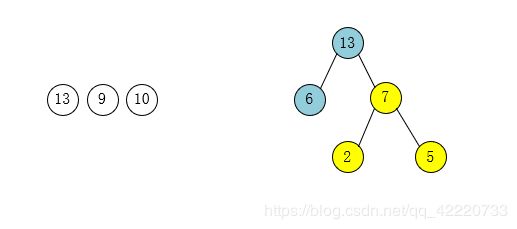
第六步:选择叶子结点权值最小的两个结点9和10作为一个新结点19的孩子结点。

第七步:将之前操作过的结点划去、新结点加入。
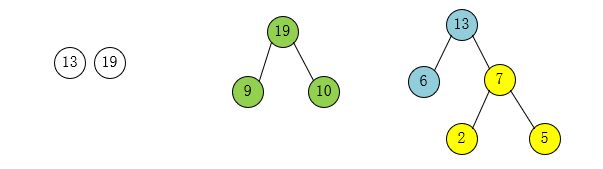
第八步:选择叶子结点权值最小的两个结点13和19作为一个新结点32的孩子结点。
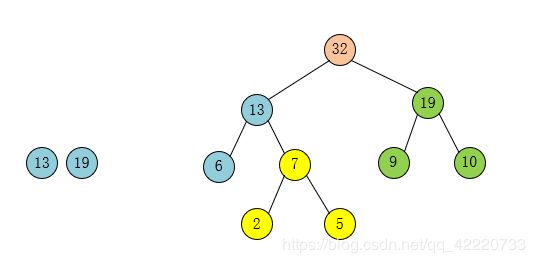
第九步:将之前操作过的结点划去、完成哈夫曼树的创建
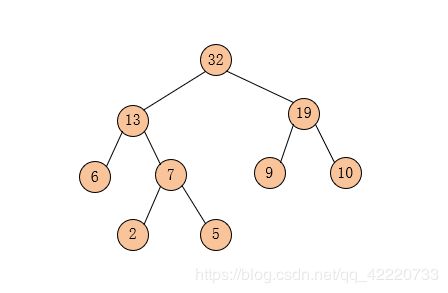
哈夫曼树编码
哈夫曼树编码具有广泛的应用,最开始它的目的是为了解决当年远距离通信(主要是电报)的数据传输的最优化问题,至于为什么可以做优化可以上百度或谷歌自行学习,我这里只是说说怎么用0和1做编码。
假设字母A,B,C,D,E这5个字符出现频率分别是0.1875,0.0625,0.15625,0.28125,0.3125。

我们将权值放大一些(这里是我偷懒没有修改数值,大家要注意的是这里的权值是各个字符出现的频率)并将权值的左分支规划为0,右分支规划为1,则出现下图所示内容。
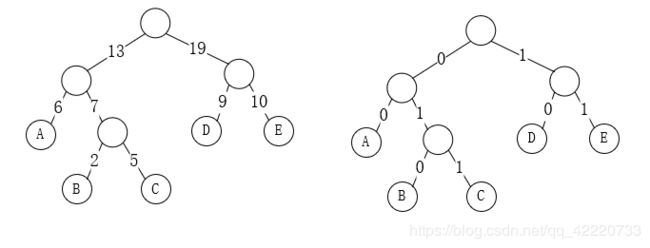
取每条路径上的0和1的序列作为各个叶子 结点对应的字符编码,这就是哈夫曼编码。

从哈夫曼编码可以看出,对于n个字符,构造他们的哈夫曼编码,没有一个字符的哈夫曼编码是另一个字符的哈弗曼编码的前缀,如某个字符的哈弗曼编码为11,则该字符组中不可能出现以11开头的哈弗曼编码了。而且对于每个字符对应的哈夫曼编码中0、1个数m是小于所有字符总数n的。
相关代码
//二叉树 - 哈夫曼树
#include 结果图示

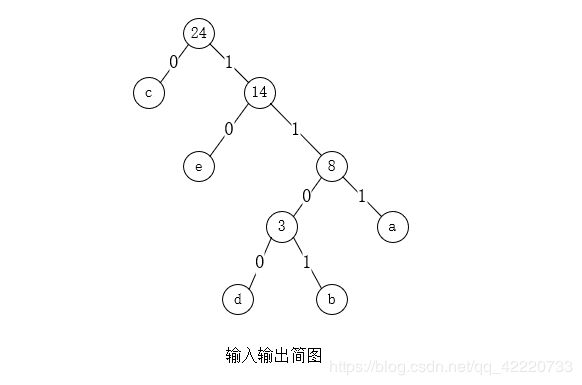

不足之处,还请批评指正。