Linux下MapReduce编程WordCount练习——使用命令行编译打包运行MapReduce程序(里面有对应安装包下载)
MapReduce编程目录
- 一、WordCount练习
- 二、编译、打包 Hadoop MapReduce 程序
- 三、遇见的问题及解决办法
一、WordCount练习
要在 Eclipse 上编译和运行 MapReduce 程序,需要安装 hadoop-eclipse-plugin,参见厦大网址。
hadoop2x-eclipse-plugin-master的安装包
提取码:6l8p
(我把这次实验需要用到的hadoop2x-eclipse-plugin-master的安装包放在了我的百度网盘,需要的可以点击上面链接直接下载,下载完成后放进ubuntu相应目录里面压缩即可使用)
1、查看 HDFS 中的文件列表

2、在 Eclipse 中创建 MapReduce 项目WordCount

3、新建类 Class,在 Package 处填写 org.apache.hadoop.examples;在 Name 处填写 WordCount,如图

4、 WordCount.java 这个文件的代码如下
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public WordCount() {
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
if(otherArgs.length < 2) {
System.err.println("Usage: wordcount [...] ");
System.exit(2);
}
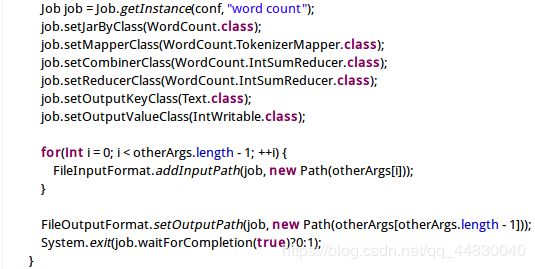
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCount.TokenizerMapper.class);
job.setCombinerClass(WordCount.IntSumReducer.class);
job.setReducerClass(WordCount.IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for(int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true)?0:1);
}
public static class IntSumReducer extends Reducer {
private IntWritable result = new IntWritable();
public IntSumReducer() {
}
public void reduce(Text key, Iterable values, Reducer.Context context) throws IOException, InterruptedException {
int sum = 0;
IntWritable val;
for(Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get()) {
val = (IntWritable)i$.next();
}
this.result.set(sum);
context.write(key, this.result);
}
}
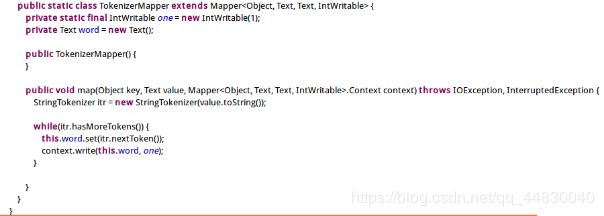
public static class TokenizerMapper extends Mapper {
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public TokenizerMapper() {
}
public void map(Object key, Text value, Mapper.Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()) {
this.word.set(itr.nextToken());
context.write(this.word, one);
}
}
}
}


5、复制配置文件解决参数设置问题
cp /usr/local/hadoop/etc/hadoop/core-site.xml ~/workspace/WordCount/src
cp /usr/local/hadoop/etc/hadoop/hdfs-site.xml ~/workspace/WordCount/src
cp /usr/local/hadoop/etc/hadoop/log4j.properties ~/workspace/WordCount/src

6、复制完成后,右键点击 WordCount 选择 refresh 进行刷新,可以看到文件结构如下所示

7、设置运行时的相关参数,如图所示

也可以直接在代码中设置好输入参数,如图所示
![]()
8、设定参数后,再次运行程序,可以看到运行成功的提示如下所示
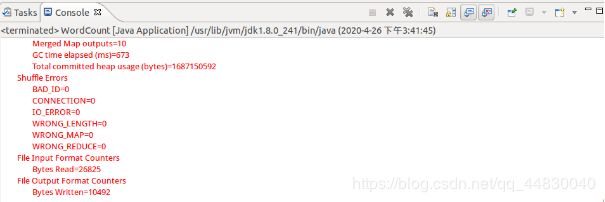
9、做到这里,就可以使用 Eclipse 方便的进行 MapReduce程序的开发了
二、编译、打包 Hadoop MapReduce 程序
10、将 Hadoop 的 classhpath 信息添加到 CLASSPATH 变量,执行 source ~/.bashrc 使变量生效
vim ~/.bashrc
source ~/.bashrc
![]()
11、通过 javac 命令编译 WordCount.java
(这里要到你的WordCount.java目录下运行!)
javac WordCount.java
![]()
12、把 .class 文件打包成 jar
(这里也在相关目录下运行)
jar -cvf WordCount.jar ./WordCount*.class

如图(生成的jar包)

(我把它拷贝到了workspace/WordCount目录下,方便!)

13、打包完成后,运行,创建几个输入文件
mkdir input
echo "echo of the rainbow" > ./input/file0
echo "the waiting game" > ./input/file1
![]()
14、查看input下的文件
ls ./input
![]()
15、把本地文件上传到伪分布式HDFS上
/usr/local/hadoop/bin/hadoop fs -put ./input input
![]()
16、开始运行(代码中设置了package包名,这里要写全!)
/usr/local/hadoop/bin/hadoop jar WordCount.jar org/apache/hadoop/examples/WordCount input output
![]()
终端运行结果

17、Localhost:50070端口查看/user/hadoop/output/结果

终端查看伪分布式下/user/hadoop/output/结果
cd /usr/local/hadoop
./bin/hdfs dfs -ls /user/hadoop/output

18、查看伪分布式下/user/hadoop/output/part-r-00000结果
./bin/hdfs dfs -cat /user/hadoop/output/part-r-00000

三、遇见的问题及解决办法
问题一:出现找不到类的错误

解决办法:这是因为在代码中设置了package包名,这里也要写全(正确的命令:/usr/local/hadoop/bin/hadoop jar WordCount.jar org/apache/hadoop/examples/WordCount input output)
问题二:Exception in thread “main” org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://localhost:9000/user/hadoop/output already exists

解决办法:伪分布式下删除运行时自动创建的output
./bin/hdfs dfs -rm -r /user/hadoop/output

加油!
