Mycat数据库中间件(史上最详细)
单机数据库瓶颈:
1.磁盘空间上限
2.服务器性能上限
3.单点故障
数据库性能瓶颈 :
1.单表性能瓶颈
2.单库性能瓶颈
3.读写性能瓶颈
解决方案1:读写分离
1.MySQL读写分离能提高系统性能的原因在于:
2.物理服务器增加,机器处理能力提升。拿硬件换性能。
3.主从只负责各自的读和写,极大程度缓解X锁和S锁争用。
4.slave可以配置myisam引擎,提升查询性能以及节约系统开销。
5.master直接写是并发的,slave通过主库发送来的binlog恢复数据是异步。
6.slave可以单独设置一些参数来提升其读的性能。
7.增加冗余,提高可用性。
解决方案2:分库分表
在我们的业务(web应用)中,关系型数据库本身比较容易成为系统性能瓶颈,单机存储容量、连接数、处理能力等都很有限,数据库本身的“有状态性”导致了它并不像Web和应用服务器那么容易扩展。那么在我们的业务中,是否真的有必要进行分库分表,就可以从上面几个条件来考虑。
1.单机储存容量。您的数据量是否在单机储存中碰到瓶颈。
2.连接数、处理能力。在我们的用户量达到一定程度时,特定时间的并发量又成了一个大问题,在一个高并发的网站中秒级数十万的并发量都是很正常的。在普通的单机数据库中秒级千次的操作问题都很大。
3.所以在我们进行分库分表之前我们最好考虑一下,我们的数据量是不是够大,并发量是不是够大。
分库分表之垂直分表:
垂直分表在日常开发和设计中比较常见,通俗的说法叫做“大表拆小表”,拆分是基于关系型数据库中的“列”(字段)进行的。通常情况,某个表中的字段比较多,可以新建立一张“扩展表”,将不经常使用或者长度较大的字段拆分出去放到“扩展表”中,如下图所示:
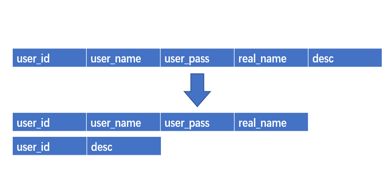
分库分表之垂直分库:
垂直分库在“微服务”盛行的今天已经非常普及了。基本的思路就是按照业务模块来划分出不同的数据库,而不是像早期一样将所有的数据表都放到同一个数据库中。如下图:
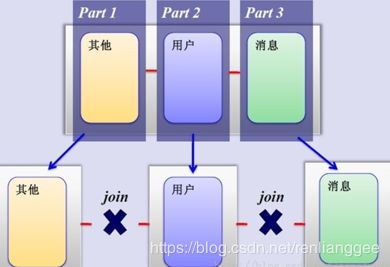
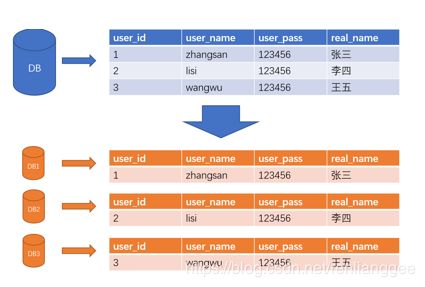
分库分表之水平切分:
水平切分是一个非常好的思路,将用户按一定规则(按id哈希)分组,并把该组用户的数据存储到一个数据库分片中,即一个sharding,这样随着用户数量的增加,只要简单地配置一台服务器即可,原理图如下:
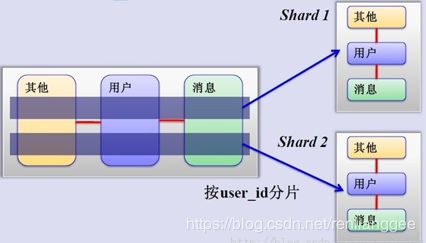
分库分表之水平分表
水平分表也称为横向分表,比较容易理解,就是将表中不同的数据行按照一定规律分布到不同的数据库表中(这些表保存在同一个数据库中),这样来降低单表数据量,优化查询性能。最常见的方式就是通过主键或者时间等字段进行Hash和取模后拆分。如下图所示:
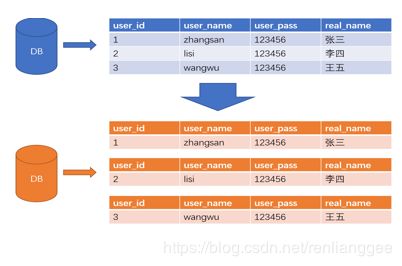
分库分表之水平分库分表
水平分库分表与上面讲到的水平分表的思想相同,唯一不同的就是将这些拆分出来的表保存在不同的数据库中。这也是很多大型互联网公司所选择的做法。如下图:
分库分表之数据库中间件:
2013年阿里的Cobar在社区使用过程中发现存在一些比较严重的问题,及其使用限制,经过Mycat发起人第一次改良,第一代改良版——Mycat诞生。 Mycat开源以后,一些Cobar的用户参与了Mycat的开发,最终Mycat发展成为一个由众多软件公司的实力派架构师和资深开发人员维护的社区型开源软件。
1.一个新颖的数据库中间件产品
2.一个彻底开源的,面向企业应用开发的大数据库集群
3.支持事务、ACID、可以替代MySQL的加强版数据库
4.一个可以视为MySQL集群的企业级数据库,用来替代昂贵的Oracle集群
5.一个融合内存缓存技术、NoSQL技术、HDFS大数据的新型SQL Server
6.结合传统数据库和新型分布式数据仓库的新一代企业级数据库产品
环境准备-mysql集群
通过docker准备mysql集群
拉取mysql镜像 docker pull mysql:5.7
启动多个mysql容器
docker run -itd -p 3301:3306 -e MYSQL_ROOT_PASSWORD=123456 docker.io/mysql:5.7
docker run -itd -p 3302:3306 -e MYSQL_ROOT_PASSWORD=123456 docker.io/mysql:5.7
docker run -itd -p 3303:3306 -e MYSQL_ROOT_PASSWORD=123456 docker.io/mysql:5.7
在多个mysql节点上创建多个database
mysql3301:CREATE DATABASE `db1` DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci
mysql3302:CREATE DATABASE `db2` DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci
mysql3303:CREATE DATABASE `db3` DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci
环境准备-mycat安装
官网 http://www.mycat.io/
下载链接 http://dl.mycat.io/1.6.6.1/
安装
环境准备-mycat系统设置
Server.xml
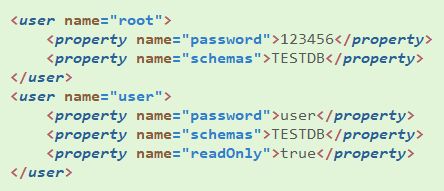
用户配置
端口配置
![]()
环境准备-mycat名词解释
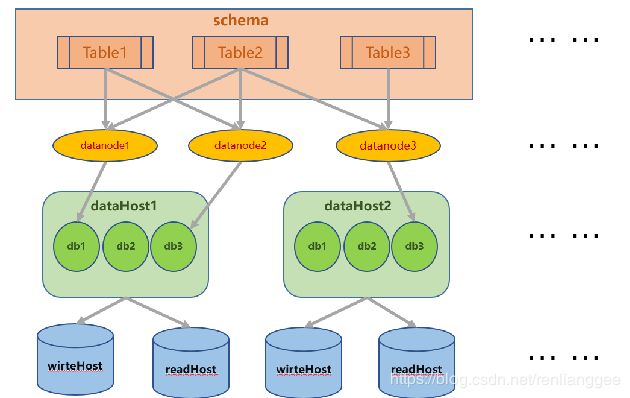
Schema标签
schema 标签用于定义 MyCat 实例中的逻辑库,MyCat 可以有多个逻辑库,每个逻辑库都有自己的相关配置。可以使用 schema 标签来划分这些不同的逻辑库。
dataNode标签
dataNode 标签定义了 MyCat 中的数据节点,也就是我们通常说所的数据分片。一个 dataNode 标签就是一个独立的数据分片。
dataHost标签
该标签定义了具体的数据库实例、读写分离配置和心跳语句。
环境准备-mycat数据库配置:
Datahost

DataNode

Schema
![]()
Mycat结构图
Mycat分库分表-全局表:
一个真实的业务系统中,往往存在大量的类似字典表的表格,它们与业务表之间可能有关系,这种关系,可 以理解为“标签”,而不应理解为通常的“主从关系”,这些表基本上很少变动,可以根据主键 ID 进行缓存; 在分片的情况下,当业务表因为规模而进行分片以后,业务表与这些附属的字典表之间的关联,就成了比较 棘手的问题,考虑到字典表具有以下几个特性:
1.变动不频繁
2.数据量总体变化不大
3.数据规模不大,很少有超过数十万条记录。
鉴于此,MyCAT 定义了一种特殊的表,称之为“全局表”,全局表具有以下特性:
全局表的插入、更新操作会实时在所有节点上执行,保持各个分片的数据一致性
全局表的查询操作,只从一个节点获取
全局表可以跟任何一个表进行 JOIN 操作 将字典表或者符合字典表特性的一些表定义为全局表,则从另外一个方面,很好的解决了数据 JOIN 的难题。
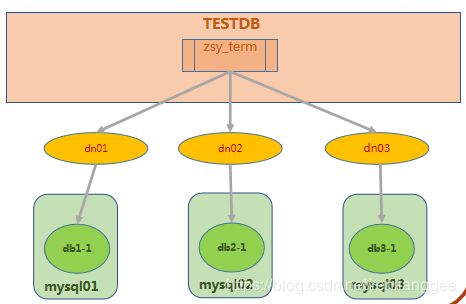
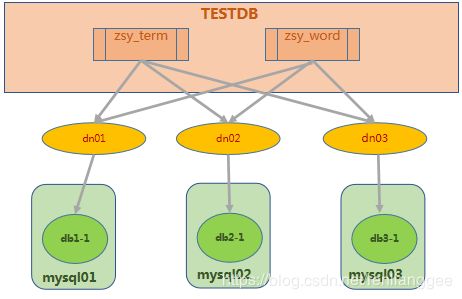
Mycat分库分表-取模分片
实现方式:切分规则根据配置中输入的数值n。此种分片规则将数据分成n份(通常dn节点也为n),从而将数据均匀的分布于各节点上。
优点:这种策略可以很好的分散数据库写的压力。比较适合于单点查询的情景
缺点:不方便扩展;出现了范围查询,就需要MyCAT去合并结果,当数据量偏高的时候,这种跨库查询+合并结果消耗的时间有可能会增加很多,尤其是还出现了order by的时候
根据本人多年从业以及学习经验,录制了一套最新的Java精讲视频教程,如果你现在也在学习Java,在入门学习Java的过程当中缺乏系统的学习教程,你可以加群654631948领取下学习资料,面试题,开发工具等,群里有资深java老师做答疑,每天也会有基础部分及架构的直播课,也可以加我的微信renlliang2013做深入沟通,只要是真心想学习Java的人都欢迎。
java基础教程:https://ke.qq.com/course/149432?tuin=57912c43
Java分布式互联网架构/微服务/高性能/springboot/springcloud:
https://ke.qq.com/course/179440?tuin=57912c43