mysql优化-explain和索引有效性分析
定位有效率问题的sql
1.通过开启慢查询日志来定位有效率问题的sql
log_output=file
slow_query_log=on
slow_query_log_file = /tmp/mysql-slow.log
log_queries_not_using_indexes=on
long_query_time = 1
2.如果你是使用阿里巴巴的Druid数据源的话,可以接入阿里巴巴的数据源监控
定位到慢查询sql后,使用explain来进行分析
1.例如我们分析如下的sql
explain select * from index_test where id=100;
他的输出结果如下:

explain他可以分析:
(1)表的读取顺序-id(2)读取操作的操作类型-type(3)可能用了哪些索引-possible_keys(4)哪些索引被实际使用了-key(5)表之间的引用等等
2.id分析:
(1)id他可以知道表的加载顺序和sql的执行的优先级问题
例如:
explain select ui.* from user_info ui , class_info ci
where ui.id=ci.user_id
and ui.id=1;
结果为

id相同可以理解为具有相同的优先级,按照顺序,他是先加载了user_info表,再加载了class_info表。
接着分析优先级,子查询的优先级一般有比较高:
explain select ui.* from user_info ui , class_info ci
where ui.id=ci.user_id
and ui.id=(SELECT ci.user_id from class_info ci where ci.user_id=1);
结果:

可以看到,id的数值越大,他执行的优先级就会越大。
3.分析select_type:
(1)select_type他主要是用来区分普通查询,联合查询,子查询等等复杂查询的。

SIMPLE:表示他只是一个普通的查询
PRIMARY:表示里面包含了子查询
SUBQUERY:表示子查询
UNION:表示联合查询
4.分析type:
(1)查询具体使用了哪一种类型的查询,例如是索引还是全表扫
system:系统表,只有一条记录
const:只经过一次索引就找到了数据.
eq_ref:唯一索引,主键
ref:非唯一的索引,返回某一个值匹配的所有的行
range:把一个索引作为一个范围检索的条件
index:全扫索引文件
ALL:全表扫,效率低下
5.possible_key:
可能用到的索引
6.key:
实际使用到的索引
7.rows:
可能返回的行数
8.extra:
其他列显示不了的重要信息,using filesort:无法利用索引完成排序,需要利用外部索引文件来进行排序。
单列索引有效性分析
1.精确查询key=?
单列索引是会走索引的。一般type是const
2.范围查询
(1)一是范围查询覆盖索引:返回的字段都是索引字段,他是会走索引的
(2)二是范围查询非覆盖索引:第一种情况是,辅助树索引查询得到的数据是少量的数据的时候,他是走索引的,第二种是,当辅助树得到的数据是大量的数据的时候,他会大量的再从主键树里面再次查询,这是mysql查询优化器会自动把他优化为all全表扫。
explain select * from index_test where biz_no>"bizno2";
结果:

辅助树查询的时候,数据量很大,所以全表扫会效率更高一点
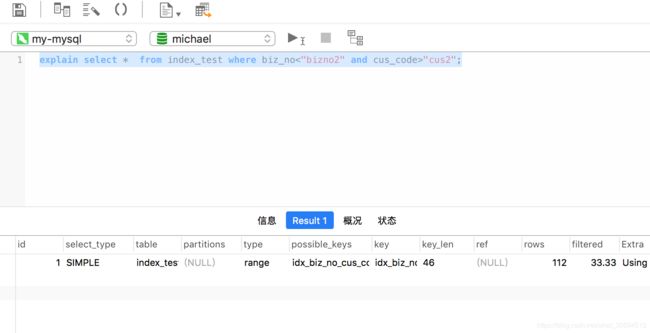
explain select * from index_test where biz_no<"bizno2";
辅助树查询结果数据量很少,走索引,范围。
3.order by,group by:
(1)order by的一列,或者多列,都需要建立索引,否则他会filesort
(2)where 条件与order by 索引一致
(3)如果依然存在filesort,请考虑是否辅助树检索到大量的数据,导致的,这时可以从业务上优化
4.<>和!=
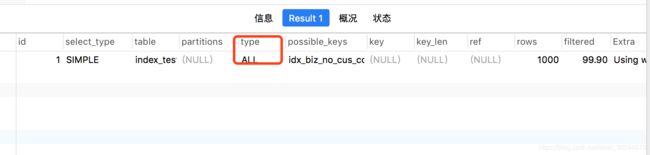
这两个是一定不会走索引的。
explain select * from index_test where biz_no<>"bizno2";
联合索引有效性分析
联合索引是最左匹配原则的,最左决定,例如有联合索引(A,B)
1.索引A,B都是精确查询,A=? AND B=?
这时他的索引是有效的
2. 一个精确,一个范围:A=? AND B>?
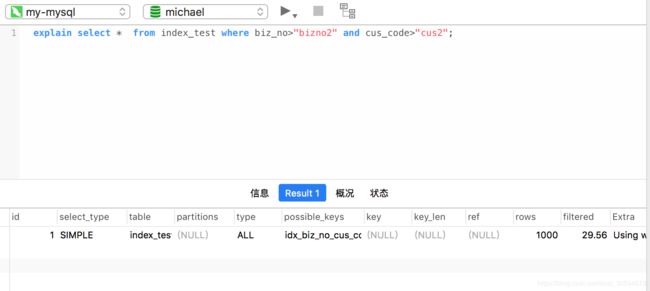
explain select * from index_test where biz_no="bizno2" and cus_code>"cus2";

是走索引的。
3.联合索引范围查询:关键是最左索引,最左匹配原则,最左的索引的情况才是决定走不走索引的:
1)一是范围查询覆盖索引:返回的字段都是索引字段,他是会走索引的
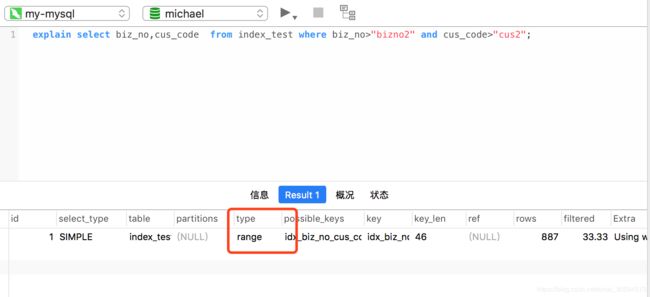
(2)二是范围查询非覆盖索引:第一种情况是,辅助树索引查询得到的数据是少量的数据的时候,他是走索引的,第二种是,当辅助树得到的数据是大量的数据的时候,他会大量的再从主键树里面再次查询,这是mysql查询优化器会自动把他优化为all全表扫。