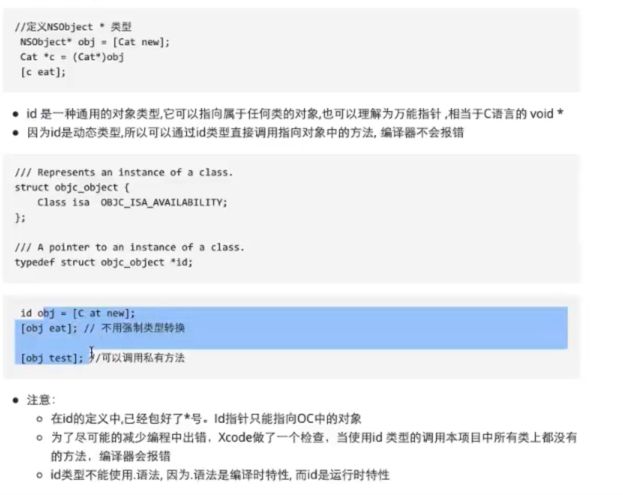
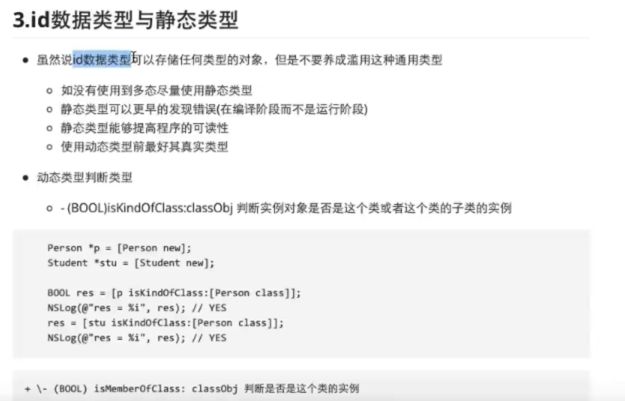
- 一些unity知识点
乌趣
unityc#游戏引擎
变量类型Animatora:定义animator组件类型变量LayerMaska:定义存储图层的变量Texta:定义文本变量,如UI的TextLineRenderer:定义保存LineRenderer组件的变量(画线用的)Material:定义保存材质的变量使用UI和场景管理的方法时记得usingUnityEngine.UI;usingUnityEngine.SceneManagement;pub
- 游戏研发高效利器:SVN资源动态项目管理解决方案
还债大湿兄
游戏项目管理
一、问题背景与解决方案传统资源分发痛点:人工打包耗时:平均每次版本发布需2小时版本隔离:不同团队无法同时使用多个版本资源冲突:美术/QA/策划资源版本不一致动态管理方案优势:二、系统核心流程//完整工作流控制器voidGameResourceManager::executeFullWorkflow(){//1.凭证验证if(!validateCredentials()){showError("认证
- FB-OCC: 3D Occupancy Prediction based on Forward-BackwardView Transformation
justtoomuchforyou
智驾
NVidia,CVPR20233DOccupancyPredictionChallengeworkshoppaper:https://arxiv.org/pdf/2307.1492code:https://github.com/NVlabs/FB-BEV大参数量imagebackboneInternImage-H,1B外部数据集预训练:object365nuscenes:有点云label,强化网络
- 树莓派中 Python+opencv打开摄像头
68lizi
光电设计python
树莓派中Python+opencv打开摄像头注意不要使用cap=cv2.VideoCapture(0,cv2.CAP_DSHOW),我在树莓派使用这个的时候会报错,在windows不会报错,具体原因不清楚cap=cv2.VideoCapture(0)#使用cap=cv2.VideoCapture(0,cv2.CAP_DSHOW)会报错whileTrue:status,img=cap.read()i
- [学习] PID算法原理与实践(代码示例)
极客不孤独
学习算法c语言
PID算法原理与实践文章目录PID算法原理与实践一、PID算法原理1.1PID算法概述1.定义2.应用领域3.核心目标1.2基本原理1.3数学表达离散化实现(适用于数字控制)二、实践案例(C语言)1.电机转速控制2.温度控制系统3.时钟驯服系统三、常见问题与优化1.积分饱和(Windup)问题2.噪声干扰问题3.非线性系统适配问题四、扩展方向1.数字PID与模拟PID的差异2.变参数PID(如增益
- ✨【Blender/Houdini 渲染必看】CPUⓥⓢGPU?3 分钟选对算力不踩坑!
渲染101专业云渲染
blenderhoudini分布式服务器maya
核心问题速答Q:渲染该选CPU还是GPU?✅CPU:复杂场景/批量渲染/预算可控首选✅GPU:单帧速度/实时预览/急单交付必选维度1:硬件硬刚——CPU凭啥赢麻了?▫️多线程王者:16核/32核服务器矩阵,支持50-300台并行渲染▫️场景兼容性:粒子特效/全局光照/超复杂模型稳定输出秘密武器:CPU批量渲染100帧耗时=GPU单帧耗时,整体效率持平!⚙️维度2:动态计费逻辑——成本由什么决定?计
- 代码随想录算法训练营第52天 | 101.孤岛的总面积 、102.沉没孤岛、103.水流问题、104.建造最大岛屿
Amor_Fati_Yu
算法java数据结构
101.孤岛的总面积importjava.util.*;publicclassMain{privatestaticintcount=0;privatestaticfinalint[][]dir={{0,1},{1,0},{-1,0},{0,-1}};//四个方向privatestaticvoidbfs(int[][]grid,intx,inty){Queueque=newLinkedList=gr
- Go插件性能优化:如何减少内存占用和提升加载速度
Golang编程笔记
golang性能优化网络ai
Go插件性能优化:如何减少内存占用和提升加载速度关键词:Go插件、性能优化、内存占用、加载速度、编译优化、动态链接、插件架构摘要:本文将深入探讨Go语言插件的性能优化策略,从内存管理和加载速度两个核心维度出发,详细分析插件系统的运行机制,并提供一系列实用的优化技巧和最佳实践。通过本文,您将学会如何诊断插件性能瓶颈,应用有效的优化手段,并构建高效可靠的Go插件系统。背景介绍目的和范围本文旨在为Go开
- 【鸿蒙游戏技术分享 第40期】1001860003 无效的商品信息
关键词1001860003商品管理应用内支付问题描述在游戏测试过程中,遇到商品购买报错问题"code":1001860003,"message":"BusinessError1001860003:Invalidproductinformation."问题分析1.传入的商品ID或者商品类型有误2.在AppGalleryConnect上创建的商品未提交审核或未审核通过问题处理登录AppGalleryC
- 代码随想录算法训练营第52天| 101. 孤岛的总面积、102. 沉没孤岛、103. 水流问题、104.建造最大岛屿
扛过今天777
算法深度优先
101.孤岛的总面积卡码题目链接:101.孤岛的总面积学习链接:代码随想录题解:法一:count=0defdfs(grid,x,y):globalcountgrid[x][y]=0count+=1directions=[[1,0],[0,1],[-1,0],[0,-1]]fori,jindirections:next_x=x+inext_y=y+jifnext_x=len(grid)ornext_
- 右移的错误使用 造成 超出时间限制 解决方案
aPurpleBerry
LeetCode做题总结算法力扣二分查找
题目链接:https://leetcode.cn/problems/guess-number-higher-or-lower/?envType=study-plan-v2&envId=leetcode-75最开始的代码varguessNumber=function(n){letl=1,r=n;while(l>1;if(guess(m)===-1){r=m-1;}elseif(guess(m)===
- [Python] 使用 dataclass 简化数据结构:定义、功能与实战
踏雪无痕老爷子
Pythonpython开发语言
在经典面向对象编程中,为了保存和操作数据往往需要定义多个类,手写__init__()、__repr__()、__eq__()等方法。Python3.7引入了@dataclass装饰器,它能自动生成这些常见方法,大幅减少样板代码。本文将介绍dataclass的定义与参数、比较与普通类的差别、实战示例,以及常见注意事项。一、什么是dataclass@dataclass是一种类装饰器,它通过类成员的类型
- Go语言--包(Package)
yunfan188
#Go语言学习笔记gogo语言golangpackage
1命名空间和作用域1.1命名空间命名空间(Namespace)在编程语言中常用来表示标识符(identifier)的可见范围。编程语言借助命名空间来解决标识符不能同名的问题,命名空间实际上相当于给标识符添加了标识前缀,使标识符变得全局唯一。另外,命名空间是程序组织更加模块化,降低了程序内部的耦合性。一个标识符可以在多个命名空间中定义,它在不同命名空间中的含义是不互相干的。新的命名空间中可定义任意的
- HarmonyOS从入门到精通:WebView开发
逻极
harmonyos华为鸿蒙webviewUI前端实战
引言WebView是现代移动应用中不可或缺的组件,它使应用能够显示Web内容,实现混合开发。本文将详细介绍鸿蒙系统中WebView的开发技术,包括基本使用、性能优化和最佳实践。WebView基础知识1.WebView类型鸿蒙系统支持多种WebView实现:系统WebView自定义WebViewWeb组件2.WebView权限配置在开发WebView应用前,需要在配置文件中添加相关权限:{"modu
- Java Fork/Join 框架详解
empti_
数据结构与算法java
JavaFork/Join框架详解Fork/Join框架是Java7引入的一个并行编程框架,专门设计用来高效地实现分治算法(Divide-and-Conquer)。它通过工作窃取(Work-Stealing)算法来最大化多核处理器的利用率。一、核心概念1.基本组成ForkJoinPool:特殊的线程池,管理工作线程ForkJoinTask:表示任务的抽象类,有两个重要子类:RecursiveAct
- Java注解的实现原理
empti_
Java基础java
Java注解的实现原理Java注解的实现涉及Java语言规范、编译器处理和JVM支持等多个层面。下面我将详细解释注解在Java中的实现机制。一、注解的本质注解本质上是一种特殊的接口,所有注解类型都隐式继承自java.lang.annotation.Annotation接口。当你定义一个注解时:public@interfaceMyAnnotation{Stringvalue();}编译器实际上会生成
- 微信小程序跳转其他小程序以及跳转网站
一、跳转其他小程序1.1知道appid和页面路径wx.navigateToMiniProgram({appId:appid,//替换为目标小程序AppIDpath:pathWithParams,//小程序路径envVersion:'release',//开发版、体验版或正式版success(res){console.log("跳转到其他小程序成功!",res);},fail(err){consol
- Python爬虫实战:全方位爬取知乎学习板块问答数据
Python爬虫项目
2025年爬虫实战项目python爬虫学习开发语言scrapy游戏
1.项目背景与爬取目标知乎是中国最大的知识问答社区,聚集了大量高质量的学习资源和经验分享。爬取知乎“学习”板块的问答数据,可以为学习资料整理、舆情分析、推荐系统开发等提供数据支持。本项目目标:爬取“学习”话题下的热门问答列表抓取每个问答的标题、作者、回答内容、点赞数、评论数等详细信息实现动态加载内容的抓取,包含图片和富文本避免被反爬机制限制,保证数据采集稳定结合数据分析,为后续应用打基础2.知乎“
- 并行归并排序的 Java 实现
empti_
数据结构与算法java算法排序算法
并行归并排序Java实现importjava.util.concurrent.RecursiveAction;importjava.util.concurrent.ForkJoinPool;publicclassParallelMergeSort{//主方法,供外部调用publicstaticvoidparallelMergeSort(int[]array){ForkJoinPoolpool=ne
- 【网络】Linux 内核优化实战 - net.ipv4.tcp_rmem 和 net.core.rmem_default 关系
锅锅来了
Linux性能优化原理和实战网络linuxtcp/ip
net.ipv4.tcp_rmem和net.core.rmem_default都是Linux内核中控制网络接收缓冲区的参数,但它们的作用范围、优先级和使用场景存在明显区别。以下是详细对比:核心区别参数net.ipv4.tcp_rmemnet.core.rmem_default作用协议仅针对TCP协议针对所有网络协议(TCP、UDP等)参数类型三元组:mindefaultmax单个值:默认缓冲区大小
- MySQL表达式之公用表表达式(CTE)的使用示例
@Corgi
后端开发mysql数据库CTE
示例一数据表中有每个企业每年每月并且每月的产值是累加的数据的数据记录需求:统计企业产值能力,找出所有家企业中产值最高的企业,其产值记为P。对于第i家企业,其产值为Pi则该企业的产值能力评分=Pi/P×100。SQL:--使用ROW_NUMBER()为每个企业每年每个月的产值排名,筛选出每个企业每年最大月份的产值。WITHMaxMonthlyOutputAS(SELECTcompany_id,dec
- Memfault 简介及在Nordic nRF91 系列 DK的应用
1:Memfault是一个云平台,它允许您和您的团队持续监控设备、调试固件问题,并将OTA更新部署到您的设备群,从而以软件的速度交付硬件产品。Memfault以嵌入式优先:支持运行在任何实时操作系统(RTOS)或Android、Linux等操作系统上的嵌入式系统和设备它适用于任何设备:从功能强大的SoC一直到功能受限的MCU,Memfault都能适配您设备的可用闪存、RAM和带宽我们的SDK是专为
- 安卓开发 手动构建 .so
XCZHONGS
android
手动构建.so(兼容废弃ABI)下载旧版NDK(推荐r16b)地址:https://developer.android.com/ndk/downloads/older_releases下载NDKr16b(最后支持armeabi、mips、mips64的版本)使用ndk-build手动构建(不使用Gradle)在源文件目录下执行D:\ideal\androidstudio\sdk\ndk\16.1.
- GitHub Actions与AWS OIDC实现安全的ECR/ECS自动化部署
ivwdcwso
运维与云原生githubaws安全ecrecsoldcCI/CD
引言在现代云原生应用开发中,实现安全、高效的CI/CD流程至关重要。本文将详细介绍如何利用GitHubActions和AWSOIDC(OpenIDConnect)构建一个无需长期凭证的安全部署管道,将容器化应用自动部署到AmazonECR和ECS服务。架构概述整个解决方案的架构包含三个主要部分:GitHub端:代码仓库和GitHubActions工作流AWS端:OIDC身份验证、ECR容器仓库和E
- 26、A* Algorithm: An In-depth Guide to Optimal Pathfinding
tree
C#搜索设计模式精解A*AlgorithmPathfindingHeuristicFunction
A*Algorithm:AnIn-depthGuidetoOptimalPathfinding1.IntroductiontoA*AlgorithmA(pronounced“Astar”)isapowerfulalgorithmwidelyusedforpathfindingandgraphtraversal.Itcombinestheadvantagesofbothuniform-costsea
- Linux ps 指令
halugin
Linux指令linux运维
Linuxps指令ps(ProcessStatus)是Linux系统中用于查看进程状态的核心命令行工具。它提供系统当前运行进程的快照,显示进程ID、CPU和内存使用情况、运行状态等信息。作为系统管理员或开发人员,ps是监控系统资源、排查性能问题和管理系统进程的必备工具。其灵活的选项和输出格式使其适用于从简单查询到复杂分析的各种场景。什么是ps指令?概述ps是一个经典的Linux/Unix命令,用于
- Nginx 核心功能
?ccc?
nginx服务器网络
目录一:正向代理1:编译安装Nginx(1)安装支持软件(2)创建运行用户、组和日志目录(3)编译安装Nginx(4)添加Nginx系统服务2:配置正向代理二:反向代理1:配置nginx七层代理2:配置nginx四层代理三:Nginx缓存1:缓存功能的核心原理和缓存类型2:代理缓存功能设置四:Nginxrewrite和正则一:正向代理正向代理(ForwardProxy)是一种位于客户端和原始服务器
- Spring Boot项目初始化加载自定义配置文件内容到静态属性字段
@Corgi
Java面试题springboot后端java
文章目录创建配置文件cXXX.properties配置类XXXConfig.java添加第三方JAR包创建配置文件cXXX.properties在resource目录下新建配置文件cXXX.properties,内容如下:#商户号mch_id=xxxxx#商户密码pwd=xxxx#接口请求地址req_url=https://xxx#异步回调通知地址(请替换为实际地址)notify_url=htt
- 鸿蒙 ArkTS 开发知识点全体系(HarmonyOS NEXT 架构)
码农乐园
harmonyos架构华为
一、基础知识:ArkTS语言与项目结构1.ArkTS基础语法(华为增强TypeScript)类型声明与推导函数与箭头函数类、接口、枚举、泛型模块导入与导出装饰器语法(@Entry、@Component等)异步编程(async/await)2.DevEcoStudio开发环境项目创建与构建模拟器配置与真机调试工程结构(entry、pages、resources、common、config.json)
- 【开源项目】「安卓原生3D开源渲染引擎」:Sceneform‑EQR
「安卓原生3D开源渲染引擎」:Sceneform‑EQR渲染引擎“那一夜凌晨3点,第一次提交PR的手在抖……”——我深刻体会这种忐忑与激动。仓库地址:(github.com)。一、前言:开源对我意味着什么DIY的自由Vs.工业化的束缚刚入Android原生开发时,我习惯自己在项目里嵌入各种3D渲染/AR/XR模块,结构臃肿、流程混乱。当我知道GoogleSceneformSDK被弃用,起初只是出于
- ztree异步加载
3213213333332132
JavaScriptAjaxjsonWebztree
相信新手用ztree的时候,对异步加载会有些困惑,我开始的时候也是看了API花了些时间才搞定了异步加载,在这里分享给大家。
我后台代码生成的是json格式的数据,数据大家按各自的需求生成,这里只给出前端的代码。
设置setting,这里只关注async属性的配置
var setting = {
//异步加载配置
- thirft rpc 具体调用流程
BlueSkator
中间件rpcthrift
Thrift调用过程中,Thrift客户端和服务器之间主要用到传输层类、协议层类和处理类三个主要的核心类,这三个类的相互协作共同完成rpc的整个调用过程。在调用过程中将按照以下顺序进行协同工作:
(1) 将客户端程序调用的函数名和参数传递给协议层(TProtocol),协议
- 异或运算推导, 交换数据
dcj3sjt126com
PHP异或^
/*
* 5 0101
* 9 1010
*
* 5 ^ 5
* 0101
* 0101
* -----
* 0000
* 得出第一个规律: 相同的数进行异或, 结果是0
*
* 9 ^ 5 ^ 6
* 1010
* 0101
* ----
* 1111
*
* 1111
* 0110
* ----
* 1001
- 事件源对象
周华华
JavaScript
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml&q
- MySql配置及相关命令
g21121
mysql
MySQL安装完毕后我们需要对它进行一些设置及性能优化,主要包括字符集设置,启动设置,连接优化,表优化,分区优化等等。
一 修改MySQL密码及用户
- [简单]poi删除excel 2007超链接
53873039oycg
Excel
采用解析sheet.xml方式删除超链接,缺点是要打开文件2次,代码如下:
public void removeExcel2007AllHyperLink(String filePath) throws Exception {
OPCPackage ocPkg = OPCPac
- Struts2添加 open flash chart
云端月影
准备以下开源项目:
1. Struts 2.1.6
2. Open Flash Chart 2 Version 2 Lug Wyrm Charmer (28th, July 2009)
3. jofc2,这东西不知道是没做好还是什么意思,好像和ofc2不怎么匹配,最好下源码,有什么问题直接改。
4. log4j
用eclipse新建动态网站,取名OFC2Demo,将Struts2 l
- spring包详解
aijuans
spring
下载的spring包中文件及各种包众多,在项目中往往只有部分是我们必须的,如果不清楚什么时候需要什么包的话,看看下面就知道了。 aspectj目录下是在Spring框架下使用aspectj的源代码和测试程序文件。Aspectj是java最早的提供AOP的应用框架。 dist 目录下是Spring 的发布包,关于发布包下面会详细进行说明。 docs&nb
- 网站推广之seo概念
antonyup_2006
算法Web应用服务器搜索引擎Google
持续开发一年多的b2c网站终于在08年10月23日上线了。作为开发人员的我在修改bug的同时,准备了解下网站的推广分析策略。
所谓网站推广,目的在于让尽可能多的潜在用户了解并访问网站,通过网站获得有关产品和服务等信息,为最终形成购买决策提供支持。
网站推广策略有很多,seo,email,adv
- 单例模式,sql注入,序列
百合不是茶
单例模式序列sql注入预编译
序列在前面写过有关的博客,也有过总结,但是今天在做一个JDBC操作数据库的相关内容时 需要使用序列创建一个自增长的字段 居然不会了,所以将序列写在本篇的前面
1,序列是一个保存数据连续的增长的一种方式;
序列的创建;
CREATE SEQUENCE seq_pro
2 INCREMENT BY 1 -- 每次加几个
3
- Mockito单元测试实例
bijian1013
单元测试mockito
Mockito单元测试实例:
public class SettingServiceTest {
private List<PersonDTO> personList = new ArrayList<PersonDTO>();
@InjectMocks
private SettingPojoService settin
- 精通Oracle10编程SQL(9)使用游标
bijian1013
oracle数据库plsql
/*
*使用游标
*/
--显示游标
--在显式游标中使用FETCH...INTO语句
DECLARE
CURSOR emp_cursor is
select ename,sal from emp where deptno=1;
v_ename emp.ename%TYPE;
v_sal emp.sal%TYPE;
begin
ope
- 【Java语言】动态代理
bit1129
java语言
JDK接口动态代理
JDK自带的动态代理通过动态的根据接口生成字节码(实现接口的一个具体类)的方式,为接口的实现类提供代理。被代理的对象和代理对象通过InvocationHandler建立关联
package com.tom;
import com.tom.model.User;
import com.tom.service.IUserService;
- Java通信之URL通信基础
白糖_
javajdkwebservice网络协议ITeye
java对网络通信以及提供了比较全面的jdk支持,java.net包能让程序员直接在程序中实现网络通信。
在技术日新月异的现在,我们能通过很多方式实现数据通信,比如webservice、url通信、socket通信等等,今天简单介绍下URL通信。
学习准备:建议首先学习java的IO基础知识
URL是统一资源定位器的简写,URL可以访问Internet和www,可以通过url
- 博弈Java讲义 - Java线程同步 (1)
boyitech
java多线程同步锁
在并发编程中经常会碰到多个执行线程共享资源的问题。例如多个线程同时读写文件,共用数据库连接,全局的计数器等。如果不处理好多线程之间的同步问题很容易引起状态不一致或者其他的错误。
同步不仅可以阻止一个线程看到对象处于不一致的状态,它还可以保证进入同步方法或者块的每个线程,都看到由同一锁保护的之前所有的修改结果。处理同步的关键就是要正确的识别临界条件(cri
- java-给定字符串,删除开始和结尾处的空格,并将中间的多个连续的空格合并成一个。
bylijinnan
java
public class DeleteExtraSpace {
/**
* 题目:给定字符串,删除开始和结尾处的空格,并将中间的多个连续的空格合并成一个。
* 方法1.用已有的String类的trim和replaceAll方法
* 方法2.全部用正则表达式,这个我不熟
* 方法3.“重新发明轮子”,从头遍历一次
*/
public static v
- An error has occurred.See the log file错误解决!
Kai_Ge
MyEclipse
今天早上打开MyEclipse时,自动关闭!弹出An error has occurred.See the log file错误提示!
很郁闷昨天启动和关闭还好着!!!打开几次依然报此错误,确定不是眼花了!
打开日志文件!找到当日错误文件内容:
--------------------------------------------------------------------------
- [矿业与工业]修建一个空间矿床开采站要多少钱?
comsci
地球上的钛金属矿藏已经接近枯竭...........
我们在冥王星的一颗卫星上面发现一些具有开采价值的矿床.....
那么,现在要编制一个预算,提交给财政部门..
- 解析Google Map Routes
dai_lm
google api
为了获得从A点到B点的路劲,经常会使用Google提供的API,例如
[url]
http://maps.googleapis.com/maps/api/directions/json?origin=40.7144,-74.0060&destination=47.6063,-122.3204&sensor=false
[/url]
从返回的结果上,大致可以了解应该怎么走,但
- SQL还有多少“理所应当”?
datamachine
sql
转贴存档,原帖地址:http://blog.chinaunix.net/uid-29242841-id-3968998.html、http://blog.chinaunix.net/uid-29242841-id-3971046.html!
------------------------------------华丽的分割线--------------------------------
- Yii使用Ajax验证时,如何设置某些字段不需要验证
dcj3sjt126com
Ajaxyii
经常像你注册页面,你可能非常希望只需要Ajax去验证用户名和Email,而不需要使用Ajax再去验证密码,默认如果你使用Yii 内置的ajax验证Form,例如:
$form=$this->beginWidget('CActiveForm', array( 'id'=>'usuario-form',&
- 使用git同步网站代码
dcj3sjt126com
crontabgit
转自:http://ued.ctrip.com/blog/?p=3646?tn=gongxinjun.com
管理一网站,最开始使用的虚拟空间,采用提供商支持的ftp上传网站文件,后换用vps,vps可以自己搭建ftp的,但是懒得搞,直接使用scp传输文件到服务器,现在需要更新文件到服务器,使用scp真的很烦。发现本人就职的公司,采用的git+rsync的方式来管理、同步代码,遂
- sql基本操作
蕃薯耀
sqlsql基本操作sql常用操作
sql基本操作
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
蕃薯耀 2015年6月1日 17:30:33 星期一
&
- Spring4+Hibernate4+Atomikos3.3多数据源事务管理
hanqunfeng
Hibernate4
Spring3+后不再对JTOM提供支持,所以可以改用Atomikos管理多数据源事务。Spring2.5+Hibernate3+JTOM参考:http://hanqunfeng.iteye.com/blog/1554251Atomikos官网网站:http://www.atomikos.com/ 一.pom.xml
<dependency>
<
- jquery中两个值得注意的方法one()和trigger()方法
jackyrong
trigger
在jquery中,有两个值得注意但容易忽视的方法,分别是one()方法和trigger()方法,这是从国内作者<<jquery权威指南》一书中看到不错的介绍
1) one方法
one方法的功能是让所选定的元素绑定一个仅触发一次的处理函数,格式为
one(type,${data},fn)
&nb
- 拿工资不仅仅是让你写代码的
lampcy
工作面试咨询
这是我对团队每个新进员工说的第一件事情。这句话的意思是,我并不关心你是如何快速完成任务的,哪怕代码很差,只要它像救生艇通气门一样管用就行。这句话也是我最喜欢的座右铭之一。
这个说法其实很合理:我们的工作是思考客户提出的问题,然后制定解决方案。思考第一,代码第二,公司请我们的最终目的不是写代码,而是想出解决方案。
话粗理不粗。
付你薪水不是让你来思考的,也不是让你来写代码的,你的目的是交付产品
- 架构师之对象操作----------对象的效率复制和判断是否全为空
nannan408
架构师
1.前言。
如题。
2.代码。
(1)对象的复制,比spring的beanCopier在大并发下效率要高,利用net.sf.cglib.beans.BeanCopier
Src src=new Src();
BeanCopier beanCopier = BeanCopier.create(Src.class, Des.class, false);
- ajax 被缓存的解决方案
Rainbow702
JavaScriptjqueryAjaxcache缓存
使用jquery的ajax来发送请求进行局部刷新画面,各位可能都做过。
今天碰到一个奇怪的现象,就是,同一个ajax请求,在chrome中,不论发送多少次,都可以发送至服务器端,而不会被缓存。但是,换成在IE下的时候,发现,同一个ajax请求,会发生被缓存的情况,只有第一次才会被发送至服务器端,之后的不会再被发送。郁闷。
解决方法如下:
① 直接使用 JQuery提供的 “cache”参数,
- 修改date.toLocaleString()的警告
tntxia
String
我们在写程序的时候,经常要查看时间,所以我们经常会用到date.toLocaleString(),但是date.toLocaleString()是一个过时 的API,代替的方法如下:
package com.tntxia.htmlmaker.util;
import java.text.SimpleDateFormat;
import java.util.
- 项目完成后的小总结
xiaomiya
js总结项目
项目完成了,突然想做个总结但是有点无从下手了。
做之前对于客户端给的接口很模式。然而定义好了格式要求就如此的愉快了。
先说说项目主要实现的功能吧
1,按键精灵
2,获取行情数据
3,各种input输入条件判断
4,发送数据(有json格式和string格式)
5,获取预警条件列表和预警结果列表,
6,排序,
7,预警结果分页获取
8,导出文件(excel,text等)
9,修