Java篇 - 并发容器之ConcurrentHashMap为何如此优秀? (基于JDK1.8)
Java并发容器类之ConcurrentHashMap为什么如此优秀?
- HashMap是非线程同步的散列表,实现原理和HashTable类似,具体可以看我的这篇文章:《Java篇 - 并发容器类之Hashtable源码分析》https://blog.csdn.net/u014294681/article/details/85298342
- HashTable不允许空key和空value,但是HashMap可以,HashMap允许存储一个空key和多个空value,空key是采用覆盖上个空key的方式。其实这样设计是合理的,因为项目中有时需要用的空key或者空value。
- 实现散列表同步的方式还有:Collections.synchronizedMap(Map
list),Collections.synchronizedCollection(Collection c)也是同样的道理,看实现就知道了:
private final Map m; // Backing Map
final Object mutex; // Object on which to synchronize
SynchronizedMap(Map m) {
this.m = Objects.requireNonNull(m);
mutex = this;
}
SynchronizedMap(Map m, Object mutex) {
this.m = m;
this.mutex = mutex;
}
public int size() {
synchronized (mutex) {return m.size();}
}
public boolean isEmpty() {
synchronized (mutex) {return m.isEmpty();}
}
public boolean containsKey(Object key) {
synchronized (mutex) {return m.containsKey(key);}
}
public boolean containsValue(Object value) {
synchronized (mutex) {return m.containsValue(value);}
}
public V get(Object key) {
synchronized (mutex) {return m.get(key);}
}
public V put(K key, V value) {
synchronized (mutex) {return m.put(key, value);}
}
public V remove(Object key) {
synchronized (mutex) {return m.remove(key);}
}
public void putAll(Map map) {
synchronized (mutex) {m.putAll(map);}
}
public void clear() {
synchronized (mutex) {m.clear();}
}
而ConcurrentHashMap属于开创性的锁概念,分段锁,这和读写锁的意义是一样的。
1. 分段锁技术
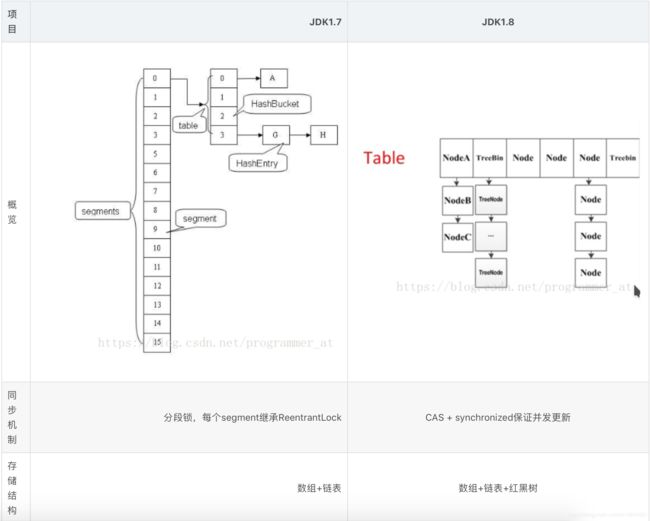
HashTable容器在竞争激烈的并发环境下表现出效率低下的原因,是因为所有访问HashTable的线程都必须竞争同一把锁,那假如容器里有多把锁,每一把锁用于锁容器其中一部分数据,那么当多线程访问容器里不同数据段的数据时,线程间就不会存在锁竞争,从而可以有效地提高并发访问效率,这就是ConcurrentHashMap所使用的锁分段技术,首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。有些方法需要跨段,比如size()和containsValue(),它们可能需要锁定整个表而而不仅仅是某个段,这需要按顺序锁定所有段,操作完毕后,又按顺序释放所有段的锁。这里"按顺序"是很重要的,否则极有可能出现死锁,在ConcurrentHashMap内部,段数组是final的,并且其成员变量实际上也是final的,但是,仅仅是将数组声明为final的并不保证数组成员也是final的,这需要实现上的保证。这可以确保不会出现死锁,因为获得锁的顺序是固定的。
2. 应用场景
当有一个大数组时需要在多个线程共享时就可以考虑是否把它给分层多个节点了,避免大锁。并可以考虑通过hash算法进行一些模块定位。
其实不止用于线程,当设计数据表的事务时(事务某种意义上也是同步机制的体现),可以把一个表看成一个需要同步的数组,如果操作的表数据太多时就可以考虑事务分离了(这也是为什么要避免大表的出现),比如把数据进行字段拆分,水平分表等。
3. 源码分析(by JDK1.8)
- 3.1 数据结构
JDK1.7及之前中主要实体类就是两个:Segment(桶),HashEntry(节点)。而JDK1.8主要是Node(结点),当然Segment还存在,但是已然不是主角。
先来看下Node类的定义:
static class Node implements Map.Entry {
final int hash;
final K key;
volatile V val;
volatile Node next;
Node(int hash, K key, V val, Node next) {
this.hash = hash;
this.key = key;
this.val = val;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return val; }
public final int hashCode() { return key.hashCode() ^ val.hashCode(); }
public final String toString(){ return key + "=" + val; }
public final V setValue(V value) {
throw new UnsupportedOperationException();
}
public final boolean equals(Object o) {
Object k, v, u; Map.Entry e;
return ((o instanceof Map.Entry) &&
(k = (e = (Map.Entry)o).getKey()) != null &&
(v = e.getValue()) != null &&
(k == key || k.equals(key)) &&
(v == (u = val) || v.equals(u)));
}
/**
* Virtualized support for map.get(); overridden in subclasses.
*/
Node find(int h, Object k) {
Node e = this;
if (k != null) {
do {
K ek;
if (e.hash == h &&
((ek = e.key) == k || (ek != null && k.equals(ek))))
return e;
} while ((e = e.next) != null);
}
return null;
}
}
仍然是继承于Map.Entry
而Segment则沦为序列化的工具:
/**
* 继承重入锁实现序列化接口
*/
static class Segment extends ReentrantLock implements Serializable {
private static final long serialVersionUID = 2249069246763182397L;
// 加载因子,HashTable那章有介绍
final float loadFactor;
Segment(float lf) { this.loadFactor = lf; }
}
/**
* 通过对象流写入对象
*/
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
// For serialization compatibility
// Emulate segment calculation from previous version of this class
int sshift = 0;
int ssize = 1;
while (ssize < DEFAULT_CONCURRENCY_LEVEL) {
++sshift;
ssize <<= 1;
}
int segmentShift = 32 - sshift;
int segmentMask = ssize - 1;
@SuppressWarnings("unchecked")
Segment[] segments = (Segment[])
new Segment[DEFAULT_CONCURRENCY_LEVEL];
for (int i = 0; i < segments.length; ++i)
segments[i] = new Segment(LOAD_FACTOR);
s.putFields().put("segments", segments);
s.putFields().put("segmentShift", segmentShift);
s.putFields().put("segmentMask", segmentMask);
s.writeFields();
Node[] t;
if ((t = table) != null) {
Traverser it = new Traverser(t, t.length, 0, t.length);
for (Node p; (p = it.advance()) != null; ) {
s.writeObject(p.key);
s.writeObject(p.val);
}
}
s.writeObject(null);
s.writeObject(null);
segments = null; // throw away
}
- 3.2 构造器
/**
* 最大容量,2的30次方
*/
private static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* 默认容量,必须是2的幂
*/
private static final int DEFAULT_CAPACITY = 16;
/**
* 最大数组容量
*/
static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
/**
* 默认并发级别,JDK1.7就存在
*/
private static final int DEFAULT_CONCURRENCY_LEVEL = 16;
/**
* 加载因子
*/
private static final float LOAD_FACTOR = 0.75f;
/**
* 数组的大小和扩容控制变量
*/
private transient volatile int sizeCtl;
/**
* 创建一个新的空的ConcurrentHashMap,默认容量为16
*/
public ConcurrentHashMap() {
}
/**
* 创建一个新的空的ConcurrentHashMap,传入初始容量
*/
public ConcurrentHashMap(int initialCapacity) {
if (initialCapacity < 0)
throw new IllegalArgumentException();
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
MAXIMUM_CAPACITY :
tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
this.sizeCtl = cap;
}
/**
* 通过map创建ConcurrentHashMap
*/
public ConcurrentHashMap(Map m) {
this.sizeCtl = DEFAULT_CAPACITY;
putAll(m);
}
/**
* 通过初始容量和加载因子创建一个新的空的ConcurrentHashMap
*/
public ConcurrentHashMap(int initialCapacity, float loadFactor) {
this(initialCapacity, loadFactor, 1);
}
/**
* 通过初始容量,加载因子和并发级别创建一个新的空的ConcurrentHashMap
*/
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (initialCapacity < concurrencyLevel) // Use at least as many bins
initialCapacity = concurrencyLevel; // as estimated threads
long size = (long)(1.0 + (long)initialCapacity / loadFactor);
int cap = (size >= (long)MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY : tableSizeFor((int)size);
this.sizeCtl = cap;
}- 3.3 全局变量
ConcurrentHashMap中有两个变量:
transient volatile Node[] table;
private transient volatile Node[] nextTable; table变量是存储
nextTable:默认为null,扩容时新生成的数组,其大小为原数组的两倍。
- 3.4 存放元素
public V put(K key, V value) {
return putVal(key, value, false);
}
final V putVal(K key, V value, boolean onlyIfAbsent) {
// 不允许空key和空value
if (key == null || value == null) throw new NullPointerException();
// 通过key计算哈希值
int hash = spread(key.hashCode());
int binCount = 0;
for (Node[] tab = table;;) {
Node f; int n, i, fh;
// 懒加载table,第一插入元素时初始化
if (tab == null || (n = tab.length) == 0)
tab = initTable();
// 当前bucket为空时,使用CAS操作,将Node放入对应的bucket中
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node(hash, key, value, null)))
break; // no lock when adding to empty bin
}
// 当前Map在扩容,先协助扩容,在更新值
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
// hash冲突
else {
V oldVal = null;
// 采用synchronized
synchronized (f) {
// 链表头节点
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node e = f;; ++binCount) {
K ek;
// 节点已经存在,修改链表节点的值
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
// 节点不存在,添加到链表末尾
Node pred = e;
if ((e = e.next) == null) {
pred.next = new Node(hash, key,
value, null);
break;
}
}
}
// 红黑树根节点
else if (f instanceof TreeBin) {
Node p;
binCount = 2;
if ((p = ((TreeBin)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
// 链表节点超过了8,链表转为红黑树
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
// 统计节点个数,检查是否需要resize
addCount(1L, binCount);
return null;
} 假设table已经初始化完成,put操作采用CAS+synchronized实现并发插入或更新操作:
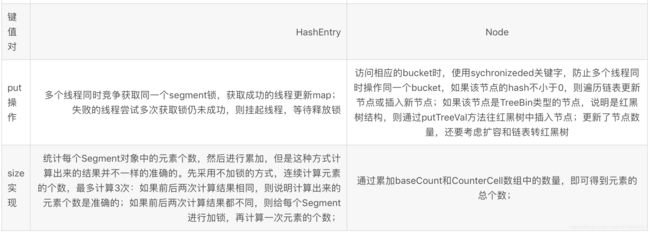
- 当前bucket为空时,使用CAS操作,将Node放入对应的bucket中。
- 出现hash冲突,则采用synchronized关键字。倘若当前hash对应的节点是链表的头节点,遍历链表,若找到对应的node节点,则修改node节点的val,否则在链表末尾添加node节点;倘若当前节点是红黑树的根节点,在树结构上遍历元素,更新或增加节点。
- 倘若当前map正在扩容f.hash == MOVED, 则跟其他线程一起进行扩容。
- 3.5 初始化表
上面代码可以看到,存放数据的table(Entry[])是懒加载的,第一次插入数据时调用initTable()进行初始化:
private final Node[] initTable() {
Node[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
// 如果一个线程发现sizeCtl<0,意味着另外的线程执行CAS操作成功,当前线程只需要让出cpu时间片
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
// 使用CAS无锁编程(UnSafe类,内部直接调用一条cpu指令),compare and swap
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node[] nt = (Node[])new Node[n];
table = tab = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}
- 3.6 hash算法
static final int HASH_BITS = 0x7fffffff; // usable bits of normal node hash
static final int spread(int h) {
return (h ^ (h >>> 16)) & HASH_BITS;
}先int h = key.hashCode,然后传入spread(h)获hash值。
hash值无符号右移16位原因:因为table使用的是2的整数次幂的掩码,仅在当前掩码之上的位上变化的散列集将会总是碰撞。(比如,Float键的集合在小table中保持连续的整数)所以我们应用一个转换,将高位的影响向下扩展。这是在速度,性能,分布上做的一个平衡。 因为许多常见的哈希集合已经合理分布(它们就不会在spread机制中受益)因为我们已经使用了红黑树对bin中的大量碰撞做了处理,因此我们只是以最简单的方式做一些移位,然后进行异或运算,以减少系统损失,并合并由于表边界而不会用于索引计算的最高位的影响(也就是&运算)。
- 3.7 获取table对应的索引元素f
static final Node tabAt(Node[] tab, int i) {
// U为Unsafe对象
return (Node)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
} 采用Unsafe.getObjectVolatie()来获取,而不是直接用table[index]的原因跟ConcurrentHashMap的弱一致性有关。在java内存模型中,我们已经知道每个线程都有一个工作内存,里面存储着table的副本,虽然table是volatile修饰的,但不能保证线程每次都拿到table中的最新元素,Unsafe.getObjectVolatile可以直接获取指定内存的数据,保证了每次拿到数据都是最新的。
- 3.8 table扩容
什么时候会触发扩容?
- 如果新增节点之后,所在的链表的元素个数大于等于8,则会调用treeifyBin把链表转换为红黑树。在转换结构时,若tab的长度小于MIN_TREEIFY_CAPACITY,默认值为64,则会将数组长度扩大到原来的两倍,并触发transfer,重新调整节点位置。(只有当tab.length >= 64, ConcurrentHashMap才会使用红黑树。)
- 新增节点后,addCount统计tab中的节点个数大于阈值(sizeCtl),会触发transfer,重新调整节点位置。
4. ConcurrentHashMap 在1.7与1.8中的不同