在线教育音视频技术探索与应用

随着实时音视频通信技术的发展,1对1,1对多直播等在线教育形式不断的满足个人定制化的学习需求。掌门1对1音视频负责人 曾小伟在LiveVideoStack 线上交流分享中介绍了在线教育中音视频技术的应用现状、挑战以及未来的发展。本文由LiveVideoStack整理而成。
文 / 曾小伟
整理 / LiveVideoStack
直播回放
https://www.baijiayun.com/web/playback/index?classid=18120589731745&token=Y70ES34BeD3hKKZLIMQ5htJW7QTXpNFvF3HfaEnKnKsX8VWf2DfBnRl2q5tNi5GNCqdH1zJ1Si0
大家好,我是来自掌门1对1的曾小伟,本次跟大家分享一下在线教育领域音视频技术的探索与应用,分享内容主要分为以下四个部分:
1,在线教育场景剖析;
2,在线教育中音视频技术应用的现状及难点;
3,在线教育领域音视频技术的发展;
4,总结;
一,在线教育场景剖析
1. 1v1教学
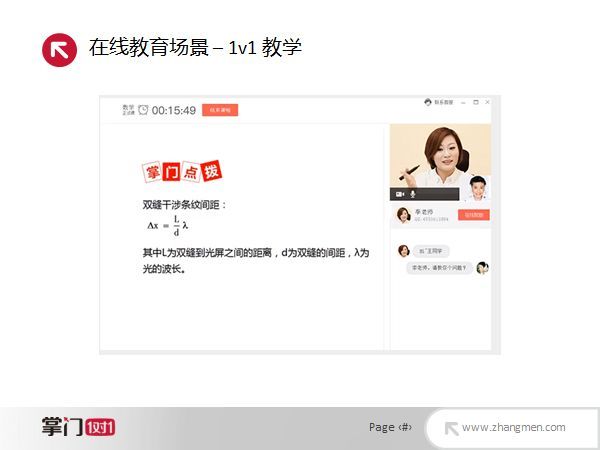
首先为大家介绍的在线教育场景是“1对1”教学,上图是掌门1对1官网的一幅宣传图,它讲的是一个1对1教学的场景,就是一个老师和一个学生在一起上课的情景。我们将图中的场景进行了分析简化。

从简化过的图中可以看出,1对1教学时,上课的主角就是学生和老师,在课件区域的右上方会显示自己的视频和对方的视频,而学生和老师关注的重点部分是课件区域。另外同样包包含一个聊天区域,方便大家进行一些文字的交流;课件区域一般会选择上传PPT或PDF格式的课件,但同样存在一些自定义格式的复杂课件。同样,在这个区域也能播放一些视频或者小游戏;视频区域,主要是为了使得学生和老师之间的互动与交流更好一些。而聊天区域,就是文字沟通的渠道,当声音断了或需要需要说一些比较长的字符时,用文字区域表达会更好一些。
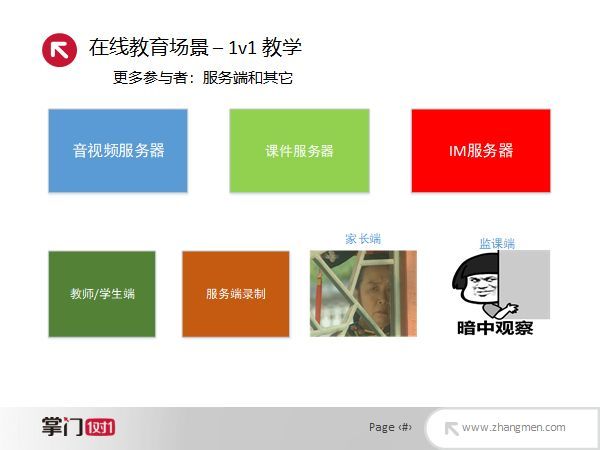
在1对1的教学场景中,除了学生和老师之外,还有一些隐藏的参与者。除了客户端,在这个场景中还需要有三个比较重要的服务端的参与,分别是音视频的服务器、课件服务器、IM服务器。音视频服务器就是我们这边的一个WebRTC的转化服务器;课件服务器就是向大家提供课件资源以供下载;IM服务器就是提供大家聊天的服务器,类似于腾讯QQ或微信的服务端;服务端录制会将课程内容进行录制;此外,还有家长端和监课端。家长端为只读的模式,它在远端进行拉流,可以观看上课内容但不能参与。监课端则是属于线教育公司的行为,它是在线教育公司的质检部门观察所聘请老师的教学质量的手段。基本上,我们可以这样认为,一个1对1的教学场景中,学生和老师一定会在,家长偶尔会在,监课在的几率会更少一些。接下来,简单介绍一下1对1教学的架构,如下图:
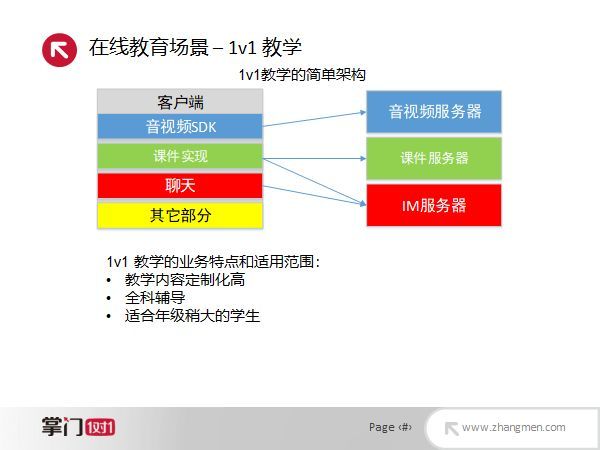
在1对1教学的架构中,客户端包含比较重要的几部分:一个是需要音视频的SDK;一个就是课件的实现,比如怎样展示一个PPT或PDF,在课件展示的上层还有白板,老师可以在课件上写字,推导公式或者划出一些重点,学生可以看见老师书写的内容;在这里还有一个聊天模块,是一个聊天的SDK,对接IM的服务端;最后,客户端还有一些其它部分,包括课堂服务等。在服务端主要是三个服务器:音视频服务器、课件服务器和IM服务器。当前的1对1教学比较适用于教学内容定制化高、需要全科辅导的年纪稍大的学生。
2. 1vN教学

在线教育中比较常见的另一种场景就是“1对N”教学,这里的N一般特指两到六个学生。当学生数量超过六个时,一个老师难以管理。那么,为什么低龄的学生不太适用于1对1的教学场景呢?通过一些教育心理学的实验可以发现,年纪比较小的小朋友更喜欢大家在一起学习,小朋友喜欢抢着举手回答问题,人多会提高他们的积极性;但是学生超过六个则会变得比较嘈杂,老师也难以管理。和1对1教学比起来,这种教学场景只是学生多一些,在服务端没有什么变化,但由于学生多一些,去监课的家长也会多一些,因此在同一个房间里面,要支持的视频的路数会更多一些。
3. 大班课场景

另外,第三个场景就是一个大班课的场景。大班课场景就是有点类似于我们在教室里面上课,是一个老师在讲台上讲,几十个或者更多学生在下面听课,这种场景类似于网红直播的方式。大班课场景的讲师会一直讲课,直到课程末尾的时候才会进行答疑环节,学生则通过连麦来提问。在服务端有一个音视频服务器,更加偏向于CDN广播,另外还有一个音视频连麦服务器,这个连麦服务器跟WebRTC的这套技术就比较类似了,同样它也有课件服务器和IM服务器。在客户端,与1对N的客户端架构类似,但因为不用考量学生跟老师之间的互动情况,因此监课的需求也就没那么高了。
4. 其它
最后,我们讲一下在线教育中的一些其他场景,刚才介绍的都是一些需要用到音视频技术或者是通过直播技术实现的在线教育的场景。除此之外,还有一些基于点播的教育场景,如MOOC、网易云课堂等;还有和音视频无关的,如在线搜题解题、阅读、背单词等。
二,在线教育中音视频技术应用的现状及难点
首先在1对1和1对N的场景中,老师和学生需要相互看到对方,因此音视频技术一般应用在头像区域的视频通信中。这里涉及到的音视频的特点,核心在于一个字就是“低”。第一,分辨率低。正如你们现在在直播间看我分享一样,我的头像分辨率就是非常低的,大家关注的重点在于PPT的内容而并非分享者本人。简单的说,在1对1教学的时候,只要能保证能看到老师和学生大概长什么样子就可以了,不要求高分辨率。第二,帧率低。帧率低与场景有关,因为老师在讲课时不会有那种剧烈的动作,所以帧率低一些也可以。另外,我们知道一个事实,当分辨率越高的时候,需要更高的帧率才能让视频没有卡顿感,而在线教育基本上是240P的分辨率,帧率为15帧每秒就足够了。第三,码率低,在分辨率和帧率都低的情况下,我们编码出来的视频码率就很低,加上场景中对视频质量的要求也并不是特别高,在编码时,通过设定一些质量参数,可以进一步地把码率压缩得更低。第四,延迟低,学生跟老师之间的沟通延迟最好在300毫秒以内,大家交流才比较好。当大家用微信语音或微信视频去跟朋友聊天时,如果说你们两个中有一个人的网不好,就会延时很高,变得卡顿起来,导致体验很糟糕,所以这里也是同样的,我们希望延迟能够尽量的低,老师说完一句话,学生马上就能够得到反馈。

除了刚才说的四个低之外,在1对1、1对N的场景中,还有如下特点:首先,音频传输优先,一般来说,在上课时,老师的画面卡几帧或者卡几秒都不是问题,但是声音不能断。其次,因为现在是移动互联网的时代,用作客户端的设备种类繁多,它们所带的摄像头、麦克风等硬件质量参差不齐,对这些设备进行媒体采集后,视频做起来就非常的麻烦。需要对音频进行回音消除及降噪处理。最后,我们常用的一些音视频编码格式在当前场景中不一定是适合的,比如说,现在WebRTC里面音频格式是Opus,视频格式是VP8,当然也支持H.264,但是最好是没有双向预测帧的,否则会导致延迟进一步增大。总结一下,以上这些就是在线教育中音视频的基本特点,而其中最重要的关键点就是低延时。
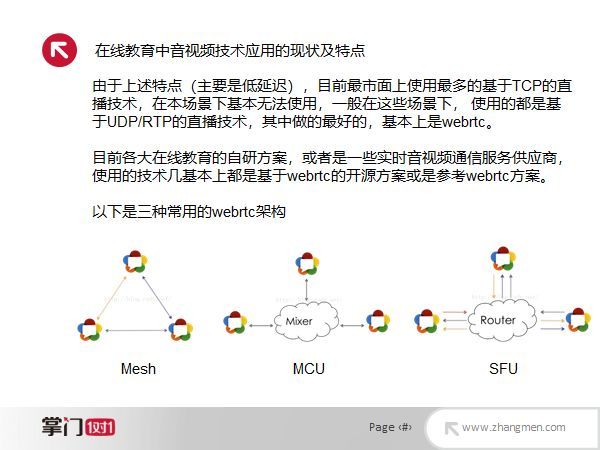
为了实现低延迟,目前市面上使用最多的直播技术有RMTP、HLS、Dash等,但在这种1对1、1对N的教学下,基本上是无法使用的,随随便便延迟就会达到3~5秒。目前基本上采用的都是基于UDP/RTP的直播技术,而做得相对比较成熟的就是WebRTC了。现在各大在线教育以及一些音视频通道服务供应商的自研方案,基本上都是基于WebRTC开源方案或者参考了WebRTC的方案提出来的。我们常见的WebRTC连接方案有三种,第一种是Mesh,就是所有的客户端都是P2P的;第二个种是MCU,大家都把流发到一个中间的MCU上,进行混流之后,分发到每个客户端。其好处就是每个人的带宽低,缺陷是延迟会稍高一些;第三种是SFU,也是最常用的,就是每个人都把自己的流都推上去,服务端只做转发,人越多的时候,流的数目就越多。

在线教育领域中,我们为什么选择SFU架构呢?原因有两点:第一,相对于Mesh结构来说,SFU提供的是一个优选过后的由供应商保障的转发线路,稳定性更高,延迟或者丢包率会更低。第二,如果选用MCU,服务端的转码会带来一定的延迟。在线教育场景中每一路视频的码率一般来说是200~300kbps,当同时存在2~3路,对于现在的宽带和4G来说,问题也不大,而且我们也会考虑编解码的消耗,当分辨率很低时,编解码的CPU内存消耗也是不大的。在这里我们还需要注意两点:第一,就是1对1和1对N的场景在SFU转发时的码率控制策略是不一样的。举例说明,当只有一个老师和一个学生的时候,SFU转发的时候,当学生发现老师出现卡顿情况之后会告知老师端发慢一点,老师就会把自己的码率降低一些。而当1对N的时候,可能众多学生中的一个告诉老师出现卡顿后,老师将自己的码率调低了,则有可能导致同一房间内剩余的学生看到质量比较差的码流。所以1对N的时候,SFU转发策略会进行不同的处理,如果只有一个学生卡顿,可能会忽略,或者码率降的程度会缩小一些;第二,在直播的时候,我们其实可以把课件通过直接抓屏或者抓取一个窗口得方式,通过音视频通道放出去。那么为什么我们一般不采用这种方式,而是直接选用课件服务和白板的信令同步策略呢?因为如果用音视频通道的话,可能需要与头像区域的音视频之间做一个同步,另外,白板的分辨率要达到720P,一般需要1Mbps左右的码率,当码率升高时,卡顿的风险以及编码和网络消耗都增加了。

接下来,介绍一下大班课场景下的特点,大班课非常类似于网红直播,技术架构也非常像,直接采用稳定的TCP模式做直播,然后就是用CDN,成本比用UDP传输的WebRTC自建要低很多。另外,也有一些企业采用的是SFU架构的WebRTC方案,其目的可能是出于资源的复用。除此之外,大班课的课件可以选择通过视频传输,这时候带宽消耗会大一些,但是它的客户端兼容性会好一些。
三,在线教育领域音视频技术的发展
目前音视频领域中,各种AI/AR技术也逐渐的在发展和落地,在有些方面已经成熟或有一定精湛,比如说现在比较常见的人脸检测、背景分割、手势识别、情绪识别、视线估计、美颜、动态贴纸、超分技术和语音检测等。

下面会大概介绍一下基于上述一些技术的应用场景:第一,登录检测,就是采用人脸识别检测技术。第二,课堂背景更换,就是基于背景分割,举例说明,因为在线教育的有些老师是在校大学生,上课的地方也许是在自己的宿舍里,环境复杂。如果说可以把背景分割出来,更换统一的幕布,可减少一些对学生的环境干扰。第三,教学质量检测,通过视频里面的学生的情绪检测、视线识别,语音检测,来评估课堂的教学质量。举例说明,老师和学生上课的时候,学生的视线长期盯着屏幕看,就证明他可能是发呆了;在上课过程中我们识别出学生的情绪是疑惑,那么有可能是老师讲的点他没有理解,如果我们把结果实时反馈给老师,老师就可以再把这个问题再讲一遍,进而提升课程质量;还有语音检测,即通过学生和老师的一些交流情况来判断课程的质量。第四,课堂趣味互动,基于手势检测和动态贴图以及人脸检测技术。举例说明,快到圣诞节了,对于一些年纪比较小的学生上课的时候,如果他的问题答的好,老师对他比一个大拇指,通过手势检测,在学生的客户端上显示一个贴图,提升学生的学习兴趣。第五,超分辨率重建,正如前面所讲,以200~300kbps的码率传输240P的视频给对方,但是有时候老师或者学生希望对方的视频能够看的更清楚一些,这时候我们可以重新发送请求,让对方重新连接一下,发送一个更清楚的视频。但如果说我们能够在本地,通过超分辨重建技术,将视频做的更清晰的话,就可以带来更好的体验,而且传输的带宽会比较低,不过会牺牲一些计算资源,通过计算资源换取带宽。
四,总结

总结一下,当前在线教育领域的音视频技术的应用和传统的点播、直播技术有共同点也有区别,主流的音视频领域都在追求超高分辨率和较高的帧率,但是在线教育行业只是在传输延迟方面的要求是最苛刻的。随着5G网络和一些高性能硬件的普及,在线教育领域音视频的分辨率、码率也会随之提升,延迟也会进一步降低,但上升的速度肯定是比不上传统音视频领域的。另外,低分辨率还会带来一些麻烦,举例说明,在视频AI技术里面一般都会用神经网络去训练一些模型。在训练模型时,大部分算法工程师的处理都是基于分辨率比较高的部分做的,这种比较低的分辨率在训练的时候会比较麻烦。而且除了在线教育之外,其它一些比较常见的场景,基本上分辨率会越来越高。因此,能够在在线教育的低分辨率上面应用视频AI技术也是一个挑战,但是在线教育依然是一个非常火爆的领域,并且是在不断向前发展的。
精品文章推荐
技术干货:
跨国实时网络调度系统设计
CEV模型与质量甜点算法设计
基于FFmpeg的运动视频分析
基于HLS格式的低延时互动直播技术
编码压缩新思路:面向QoE的感知视频编码
精致前处理,精准码控 — 极致视觉效果
利用JPEG制作更快,更准确的神经网络
基于QoE的实时视频编码优化:低功耗,低延时,高质量