设计模式GOF23之-----------行为型模式(责任链模式、迭代器模式、中介者模式、命令模式、解释器模式、访问者模式、模版方法模式、状态模式、观察者模式、备忘录模式)
一 责任链模式
任链模式是一种对象的行为模式。在责任链模式里,很多对象由每一个对象对其下家的引用而连接起来形成一条链。请求在这个链上传递,直到链上的某一个对象决定处理此请求。发出这个请求的客户端并不知道链上的哪一个对象最终处理这个请求,这使得系统可以在不影响客户端的情况下动态地重新组织和分配责任。
责任链模式的结构
下面使用了一个责任链模式的最简单的实现。
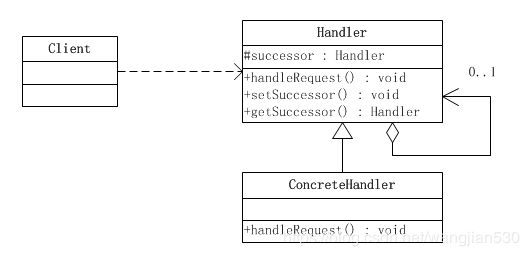
责任链模式涉及到的角色如下所示:
● 抽象处理者(Handler)角色:定义出一个处理请求的接口。如果需要,接口可以定义 出一个方法以设定和返回对下家的引用。这个角色通常由一个Java抽象类或者Java接口实现。上图中Handler类的聚合关系给出了具体子类对下家的引用,抽象方法handleRequest()规范了子类处理请求的操作。
● 具体处理者(ConcreteHandler)角色:具体处理者接到请求后,可以选择将请求处理掉,或者将请求传给下家。由于具体处理者持有对下家的引用,因此,如果需要,具体处理者可以访问下家。
下面我们来看一个员工请假的例子:

首先我们封装请假的基本信息 :
package GOF23;
/**
* 封装请假的基本信息
*
* @author lenovo
*
*/
public class Chain_LeaveRequest {
private String empName;
private int leaveDays;
private String reason;
public Chain_LeaveRequest(String empName, int leaveDays, String reason) {
super();
this.empName = empName;
this.leaveDays = leaveDays;
this.reason = reason;
}
public String getEmpName() {
return empName;
}
public void setEmpName(String empName) {
this.empName = empName;
}
public int getLeaveDays() {
return leaveDays;
}
public void setLeaveDays(int leaveDays) {
this.leaveDays = leaveDays;
}
public String getReason() {
return reason;
}
public void setReason(String reason) {
this.reason = reason;
}
}
构建领导的抽象类:
package GOF23;
/**
* 抽象类
*
* @author lenovo
*
*/
public abstract class Chain_Leader {
protected String name;
protected Chain_Leader nextLeader; // 责任链的后继对象
public Chain_Leader(String name) {
super();
this.name = name;
}
public Chain_Leader getNextLeader() {
return nextLeader;
}
// 设定责任链上的后继对象(即设置他们的上司)
public void setNextLeader(Chain_Leader nextLeader) {
this.nextLeader = nextLeader;
}
/**
* 处理请求的核心业务方法
* @param request
*/
public abstract void handleRequest(Chain_LeaveRequest request);
}
下面将实现三个领导,对上面的抽象类实例化:
package GOF23;
/**
*主任
* @author lenovo
*
*/
public class Chain_Director extends Chain_Leader {
public Chain_Director(String name) {
super(name);
}
@Override
public void handleRequest(Chain_LeaveRequest request) {
if(request.getLeaveDays() < 3) {
System.out.println("员工:" + request.getEmpName() + " 请假天数:" + request.getLeaveDays() + " 理由: " + request.getReason());
System.out.println("主任:" + this.name + "审批通过!");
} else {
if(this.nextLeader != null) {
this.nextLeader.handleRequest(request);
}
}
}
}
package GOF23;
/**
* 经理
* @author lenovo
*
*/
public class Chain_Manager extends Chain_Leader {
public Chain_Manager(String name) {
super(name);
}
@Override
public void handleRequest(Chain_LeaveRequest request) {
if(request.getLeaveDays() < 10) {
System.out.println("员工:" + request.getEmpName() + " 请假天数:" + request.getLeaveDays() + " 理由: " + request.getReason());
System.out.println("经理:" + this.name + "审批通过!");
} else {
if(this.nextLeader != null) {
this.nextLeader.handleRequest(request);
}
}
}
}
package GOF23;
/**
* 总经理
* @author lenovo
*
*/
public class Chain_GeneralManager extends Chain_Leader {
public Chain_GeneralManager(String name) {
super(name);
}
@Override
public void handleRequest(Chain_LeaveRequest request) {
if(request.getLeaveDays() < 30) {
System.out.println("员工:" + request.getEmpName() + " 请假天数:" + request.getLeaveDays() + " 理由: " + request.getReason());
System.out.println("总经理:" + this.name + "审批通过!");
} else {
System.out.println("莫非" + request.getEmpName() + "想辞职, 居然请假" + request.getLeaveDays() + "天!");
}
}
}
客户端:
package GOF23;
public class Chain_Client {
public static void main(String[] args) {
Chain_Leader a = new Chain_Director("张三");
Chain_Leader b = new Chain_Manager("李四");
Chain_Leader c = new Chain_GeneralManager("王五");
// 组织责任链对象的关系
a.setNextLeader(b); // a的领导是b;
b.setNextLeader(c); // b的领导是c
// 开始请假操作
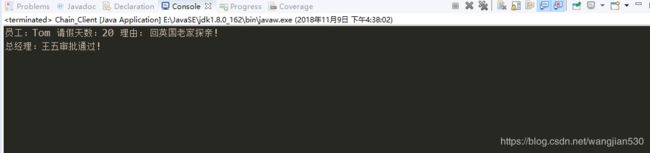
Chain_LeaveRequest req1 = new Chain_LeaveRequest("Tom", 200, "回英国老家探亲!");
a.handleRequest(req1);
}
}
结果:
核心代码:
public void handleRequest(Chain_LeaveRequest request) {
if(request.getLeaveDays() < 3) {
System.out.println("员工:" + request.getEmpName() + " 请假天数:" + request.getLeaveDays() + " 理由: " + request.getReason());
System.out.println("主任:" + this.name + "审批通过!");
} else {
if(this.nextLeader != null) {
this.nextLeader.handleRequest(request);
}
}
}
责任链从主任--经理--总经理一步一步移交,由于天数大于了10,最后交给总经理处理。
责任链的作用
-
弱化了发出请求的人和处理请求的人之间的关系
发出请求的人只需要向第一个具体的处理者发送请求,然后就可以不用管了,处理者会在责任链上自己寻找处理的方法。
这样就解耦了处理者和请求者之间的关系。
如果我们不采取责任链模式,那么请求者就必须要很清楚哪个处理者能处理它的请求,就必须对所有的处理者都有所了解,类似于上帝视角,然而在实际中,要求请求这了解这么多是不实际的 -
可以动态的改变责任链
责任链还有的好处就是可以动态的改变责任,删除或者添加或者改变顺序。 -
让各个处理者专注于实现自己的职责
责任链模式同时还做到了处理者之间的解耦,处理者自己专注于自己的处理逻辑就好,不管其他处理者干什么。 -
推卸责任也可能导致处理延迟
我们可以责任链模式需要在责任链上传播责任,直至找到合适的处理对象。这样提高了程序的灵活性,但同时也出现了处理的延迟,因为有一个寻找的过程。所以需要低延迟的情况下,就不应该使用责任链模式
责任链模式的应用
在视窗系统中,经常会使用到责任链模式,尤其是事件的处理,熟悉javascript开发的朋友,可能会知道,浏览器中的事件有冒泡机制,,就是事件的是向父控件传播的,如果自己处理不了,就会传播给父控件去处理。
二 迭代器模式
代器模式定义
迭代器模式(Iterator),提供一种方法顺序访问一个聚合对象中的各种元素,而又不暴露该对象的内部表示。
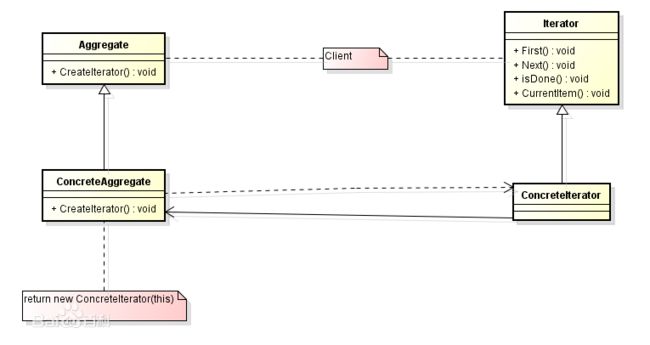
迭代器模式的角色构成
(1)迭代器角色(Iterator):定义遍历元素所需要的方法,一般来说会有这么三个方法:取得下一个元素的方法next(),判断是否遍历结束的方法hasNext()),移出当前对象的方法remove(),
(2)具体迭代器角色(Concrete Iterator):实现迭代器接口中定义的方法,完成集合的迭代。
(3)容器角色(Aggregate): 一般是一个接口,提供一个iterator()方法,例如java中的Collection接口,List接口,Set接口等
(4)具体容器角色(ConcreteAggregate):就是抽象容器的具体实现类,比如List接口的有序列表实现ArrayList,List接口的链表实现LinkList,Set接口的哈希列表的实现HashSet等。
迭代器模式应用的场景及意义
(1)访问一个聚合对象的内容而无需暴露它的内部表示
(2)支持对聚合对象的多种遍历
(3)为遍历不同的聚合结构提供一个统一的接口
迭代器模式四个角色之间的关系可以用类图表示
下面我们来看一个自定迭代器的例子:
(1)迭代器角色(Iterator)
package GOF23;
/**
* 自定义迭代器接口
* @author lenovo
*
*/
public interface MyIterator {
void first(); //将游标指向第一个元素
void next(); //将游标指向下一个元素
boolean hasNext(); //判断是否存在下一个元素
boolean isFirst();
boolean isLast();
Object getCurrentobj(); //获取当前游标指向的对象
}
(2)具体容器角色(ConcreteAggregate)+具体迭代器角色(Concrete Iterator作为ConcreteAggregate的内部类)
package GOF23;
import java.util.ArrayList;
import java.util.List;
/**
* 自定义聚合类
*
* @author lenovo
*
*/
public class ConcreteMyAggreate {
// 定义容器
private List客户端我们逐个遍历容器里的元素:
package GOF23;
public class Iterator_Client {
public static void main(String[] args) {
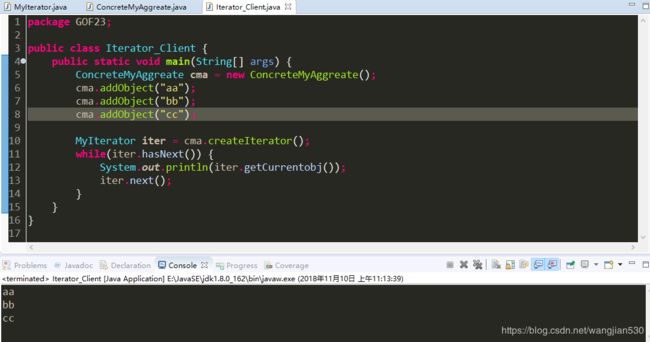
ConcreteMyAggreate cma = new ConcreteMyAggreate();
cma.addObject("aa");
cma.addObject("bb");
cma.addObject("cc");
MyIterator iter = cma.createIterator();
while(iter.hasNext()) {
System.out.println(iter.getCurrentobj());
iter.next();
}
}
}
我们来看结果:
迭代器模式的优缺点:
迭代器模式的优点有:
- 简化了遍历方式,对于对象集合的遍历,还是比较麻烦的,对于数组或者有序列表,我们尚可以通过游标来取得,但用户需要在对集合了解很清楚的前提下,自行遍历对象,但是对于hash表来说,用户遍历起来就比较麻烦了。而引入了迭代器方法后,用户用起来就简单的多了。
- 可以提供多种遍历方式,比如说对有序列表,我们可以根据需要提供正序遍历,倒序遍历两种迭代器,用户用起来只需要得到我们实现好的迭代器,就可以方便的对集合进行遍历了。
- 封装性良好,用户只需要得到迭代器就可以遍历,而对于遍历算法则不用去关心。
迭代器模式的缺点:
- 对于比较简单的遍历(像数组或者有序列表),使用迭代器方式遍历较为繁琐,大家可能都有感觉,像ArrayList,我们宁可愿意使用for循环和get方法来遍历集合。
总的来说: 迭代器模式是与集合共生共死的,一般来说,我们只要实现一个集合,就需要同时提供这个集合的迭代器,就像java中的Collection,List、Set、Map等,这些集合都有自己的迭代器。假如我们要实现一个这样的新的容器,当然也需要引入迭代器模式,给我们的容器实现一个迭代器。
三 中介者模式
定义及使用场景
定义:中介者模式包装了一系列对象相互作用的方式,使得这些对象不必相互明显作用。从而使它们可以松散耦合。当某些对象之间的作用发生改变时,不会立即影响其他的一些对象之间的作用。保证这些作用可以彼此独立的变化。
使用场景:
当对象之间的交互操作很多且每个对象的行为操作都依赖彼此时,为防止在修改一个对象的行为时,同时涉及很多其他对象的行为,可使用中介者模式。
UML图:
(1)Mediator:抽象中介者角色,定义了同事对象到中介者对象的接口,一般以抽象类的方式实现。
(2)ConcreteMediator:具体中介者角色,继承于抽象中介者,实现了父类定义的方法,它从具体的同事对象接受消息,向具体同事对象发出命令。
(3)Colleague:抽象同事类角色,定义了中介者对象的接口,它只知道中介者而不知道其他的同事对象。
(4)ConcreteColleague1、ConcreteColleague2:具体同事类角色,继承于抽象同事类,每个具体同事类都知道本身在小范围的行为,而不知道在大范围内的目的。
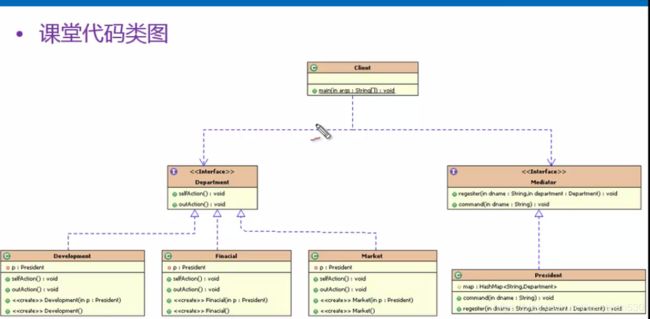
下面我们来通过代码实现上述UML图:
(1)Mediator:
package GOF23;
/**
* 总经理(中介者)
* @author lenovo
*
*/
public interface Mediator {
void register(String dname, Department d);
void command(String dname);
}
(2)ConcreteMediator:
package GOF23;
import java.util.HashMap;
import java.util.Map;
public class Mediator_President implements Mediator {
private Map map = new HashMap();
@Override
public void register(String dname, Department d) {
map.put(dname, d); //同事(department)注册时,放入map里
}
@Override
public void command(String dname) {
map.get(dname).selfAction();
}
}
(3)Colleague:
package GOF23;
/**
* 同事类
* @author lenovo
*
*/
public interface Department {
void selfAction(); //做本部门的事
void outAction(); //向总经理发出申请
}
(4)ConcreteColleague1、ConcreteColleague2 ConcreteColleague3(每一个都持有一个Mediator对象的引用):
package GOF23;
/**
*研发部
* @author lenovo
*
*/
public class Department_Development implements Department {
private Mediator m; // 持有中介者(总经理)的引用
public Department_Development(Mediator m) {
super();
this.m = m;
m.register("development", this);
}
@Override
public void selfAction() {
System.out.println("专心科研,开发项目!");
}
@Override
public void outAction() {
System.out.println("汇报工作,需要资金支持!");
}
}
package GOF23;
/**
*财务部
* @author lenovo
*
*/
public class Department_Finacial implements Department {
private Mediator m; // 持有中介者(总经理)的引用
public Department_Finacial(Mediator m) {
super();
this.m = m;
m.register("finacial", this);
}
@Override
public void selfAction() {
System.out.println("数钱!");
}
@Override
public void outAction() {
System.out.println("汇报工作!钱太多!");
}
}
package GOF23;
/**
* 市场部
*
* @author lenovo
*
*/
public class Department_Market implements Department {
private Mediator m; // 持有中介者(总经理)的引用
public Department_Market(Mediator m) {
super();
this.m = m;
m.register("market", this);
}
@Override
public void selfAction() { //自己的本职
System.out.println("跑接项目!");
}
@Override
public void outAction() { //与本部门外的交互
System.out.println("汇报工作,项目承接的进度,需要资金支持!");
m.command("finacial");
}
}
客户端:我们调用market对外的方法outAction(),然后里面又执行 m.command("finacial");通过终结者,实现和财务部finacial的交互,即market通过mediator.commaned()实现和finacial的交互
package GOF23;
public class Mediator_Client {
public static void main(String[] args) {
Mediator m = new Mediator_President();
Department_Market market = new Department_Market(m);
Department_Development development = new Department_Development(m);
Department_Finacial finacial = new Department_Finacial(m);
market.selfAction();
market.outAction();
}
}
结果: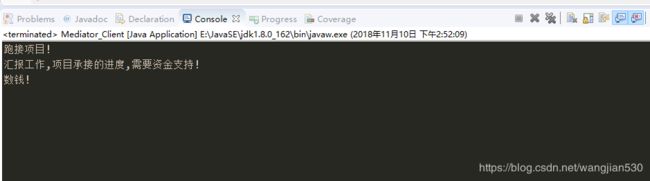

中介者模式的优缺点
优点:
- 简化了对象之间的关系,将系统的各个对象之间的相互关系进行封装,将各个同事类解耦,使得系统变为松耦合。
- 提供系统的灵活性,使得各个同事对象独立而易于复用。
缺点:
- 中介者模式中,中介者角色承担了较多的责任,所以一旦这个中介者对象出现了问题,整个系统将会受到重大的影响。
- 新增加一个同事类时,不得不去修改抽象中介者类和具体中介者类,此时可以使用观察者模式和状态模式来解决这个问题。
中介者模式的适用场景
以下情况下可以考虑使用中介者模式:
- 一组定义良好的对象,现在要进行复杂的相互通信。
- 想通过一个中间类来封装多个类中的行为,而又不想生成太多的子类。
四 命令模式
命令模式属于对象的行为模式。命令模式又称为行动(Action)模式或交易(Transaction)模式。
命令模式把一个请求或者操作封装到一个对象中。命令模式允许系统使用不同的请求把客户端参数化,对请求排队或者记录请求日志,可以提供命令的撤销和恢复功能。
命令模式的结构
命令模式是对命令的封装。命令模式把发出命令的责任和执行命令的责任分割开,委派给不同的对象。
每一个命令都是一个操作:请求的一方发出请求要求执行一个操作;接收的一方收到请求,并执行操作。命令模式允许请求的一方和接收的一方独立开来,使得请求的一方不必知道接收请求的一方的接口,更不必知道请求是怎么被接收,以及操作是否被执行、何时被执行,以及是怎么被执行的。
命令允许请求的一方和接收请求的一方能够独立演化,从而具有以下的优点:
(1)命令模式使新的命令很容易地被加入到系统里。
(2)允许接收请求的一方决定是否要否决请求。
(3)能较容易地设计一个命令队列。
(4)可以容易地实现对请求的撤销和恢复。
(5)在需要的情况下,可以较容易地将命令记入日志。
下面以一个示意性的系统,说明命令模式的结构。
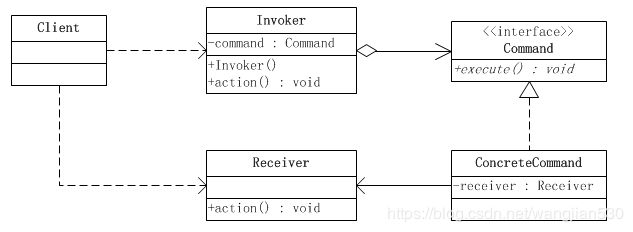
命令模式涉及到五个角色,它们分别是:
● 客户端(Client)角色:创建一个具体命令(ConcreteCommand)对象并确定其接收者。
● 命令(Command)角色:声明了一个给所有具体命令类的抽象接口。
● 具体命令(ConcreteCommand)角色:定义一个接收者和行为之间的弱耦合;实现execute()方法,负责调用接收者的相应操作。execute()方法通常叫做执行方法。
● 请求者(Invoker)角色:负责调用命令对象执行请求,相关的方法叫做行动方法。
● 接收者(Receiver)角色:负责具体实施和执行一个请求。任何一个类都可以成为接收者,实施和执行请求的方法叫做行动方法。
源代码
接收者角色类
public class Receiver {
/**
* 真正执行命令相应的操作
*/
public void action(){
System.out.println("执行操作");
}
}抽象命令角色类
public interface Command {
/**
* 执行方法
*/
void execute();
}具体命令角色类
public class ConcreteCommand implements Command {
//持有相应的接收者对象
private Receiver receiver = null;
/**
* 构造方法
*/
public ConcreteCommand(Receiver receiver){
this.receiver = receiver;
}
@Override
public void execute() {
//通常会转调接收者对象的相应方法,让接收者来真正执行功能
receiver.action();
}
}请求者角色类
public class Invoker {
/**
* 持有命令对象
*/
private Command command = null;
/**
* 构造方法
*/
public Invoker(Command command){
this.command = command;
}
/**
* 行动方法
*/
public void action(){
command.execute();
}
}客户端角色类
public class Client {
public static void main(String[] args) {
//创建接收者
Receiver receiver = new Receiver();
//创建命令对象,设定它的接收者
Command command = new ConcreteCommand(receiver);
//创建请求者,把命令对象设置进去
Invoker invoker = new Invoker(command);
//执行方法
invoker.action();
}
}命令模式的优点
● 更松散的耦合
命令模式使得发起命令的对象——客户端,和具体实现命令的对象——接收者对象完全解耦,也就是说发起命令的对象完全不知道具体实现对象是谁,也不知道如何实现。
● 更动态的控制
命令模式把请求封装起来,可以动态地对它进行参数化、队列化和日志化等操作,从而使得系统更灵活。
● 很自然的复合命令
命令模式中的命令对象能够很容易地组合成复合命令,也就是宏命令,从而使系统操作更简单,功能更强大。
● 更好的扩展性
由于发起命令的对象和具体的实现完全解耦,因此扩展新的命令就很容易,只需要实现新的命令对象,然后在装配的时候,把具体的实现对象设置到命令对象中,然后就可以使用这个命令对象,已有的实现完全不用变化。
五 解释器模式
(1)模式定义
所谓解释器模式就是定义语言的文法,并且建立一个解释器来解释该语言中的句子。
在这里我们将语言理解成使用规定格式和语法的代码。
在前面我们知道可以构建解释器来解决那些频繁发生的某一特定类型的问题,在这我们将这些问题的实例表述为一个语言中句子。例如我经常利用正则表达式来检测某些字符串是否符合我们规定的格式。这里正则表达式就是解释器模式的应用,解释器为正则表达式定义了一个文法,如何表示一个特定的正则表达式,以及如何解释这个正则表达式。
解释器模式描述了如何构成一个简单的语言解释器,主要应用在使用面向对象语言开发的编译器中。它描述了如何为简单的语言定义一个文法,如何在该语言中表示一个句子,以及如何解释这些句子。
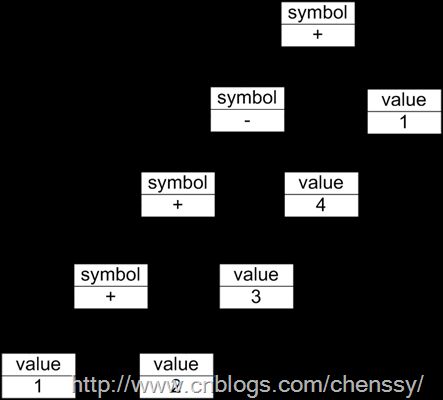
在解释器模式中除了能够使用文法规则来定义一个语言,还有通过一个更加直观的方法来表示——使用抽象语法树。抽象语法树能够更好地,更直观地表示一个语言的构成,每一颗抽象语法树对应一个语言实例。
(2)模式结构
下图是解释器模式的UML结构图。
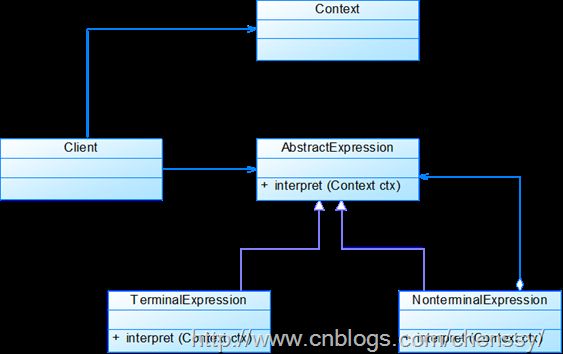
解释器模式主要包含如下几个角色:
AbstractExpression: 抽象表达式。声明一个抽象的解释操作,该接口为抽象语法树中所有的节点共享。
TerminalExpression: 终结符表达式。实现与文法中的终结符相关的解释操作。实现抽象表达式中所要求的方法。文法中每一个终结符都有一个具体的终结表达式与之相对应。
NonterminalExpression: 非终结符表达式。为文法中的非终结符相关的解释操作。
Context: 环境类。包含解释器之外的一些全局信息。
Client: 客户类。
抽象语法树描述了如何构成一个复杂的句子,通过对抽象语法树的分析,可以识别出语言中的终结符和非终结符类。 在解释器模式中由于每一种终结符表达式、非终结符表达式都会有一个具体的实例与之相对应,所以系统的扩展性比较好。
(3)模式实现
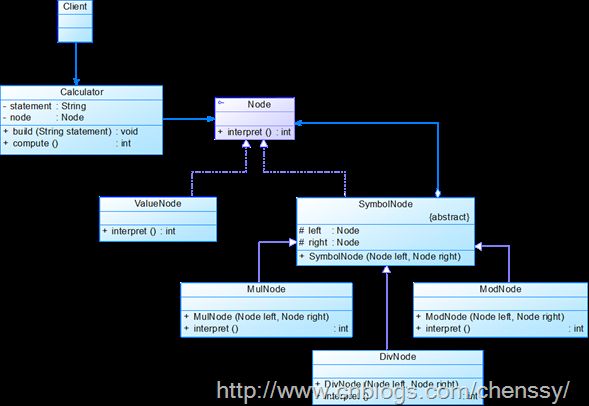
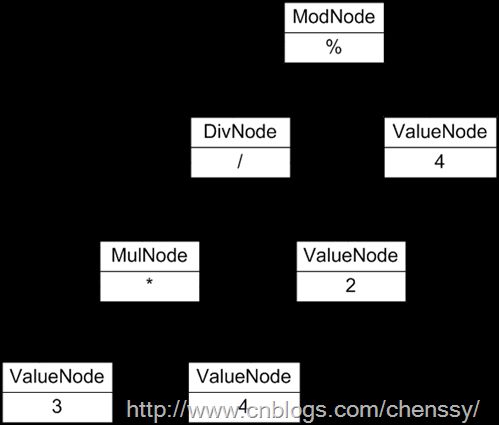
现在我们用解释器模式来实现一个基本的加、减、乘、除和求模运算。例如用户输入表达式“3 * 4 / 2 % 4”,输出结果为2。下图为该实例的UML结构图:
抽象语法树
实现过程:
抽象表达式:Node.java。
public interface Node
{
public int interpret();
}非终结表达式:ValueNode.java。主要用解释该表达式的值。
public class ValueNode implements Node
{
private int value;
public ValueNode(int value)
{
this.value=value;
}
public int interpret()
{
return this.value;
}
}终结表达式抽象类,由于该终结表达式需要解释多个运算符号,同时用来构建抽象语法树:
public abstract class SymbolNode implements Node
{
protected Node left;
protected Node right;
public SymbolNode(Node left,Node right)
{
this.left=left;
this.right=right;
}
}MulNode.java
public class MulNode extends SymbolNode
{
public MulNode(Node left,Node right)
{
super(left,right);
}
public int interpret()
{
return left.interpret() * right.interpret();
}
}ModNode.java
public class ModNode extends SymbolNode{
public ModNode(Node left,Node right){
super(left,right);
}
public int interpret(){
return super.left.interpret() % super.right.interpret();
}
}DivNode.java
public class DivNode extends SymbolNode{
public DivNode(Node left,Node right){
super(left,right);
}
public int interpret(){
return super.left.interpret() / super.right.interpret();
}
}Calculator.java
public class Calculator{
private String statement;
private Node node;
public void build(String statement){
Node left=null,right=null;
Stack stack=new Stack();
String[] statementArr=statement.split(" ");
for(int i=0;i客户端:Client.java
public class Client{
public static void main(String args[]){
String statement = "3 * 2 * 4 / 6 % 5";
Calculator calculator = new Calculator();
calculator.build(statement);
int result = calculator.compute();
System.out.println(statement + " = " + result);
}
}运行结果:3 * 2 * 4 / 6 % 5 = 4
(4)模式优缺点
优点:
1、 可扩展性比较好,灵活。
2、 增加了新的解释表达式的方式。
3、 易于实现文法。
缺点 :
1、 执行效率比较低,可利用场景比较少。
2、 对于复杂的文法比较难维护。
(5)模式使用场景:
1、可以将一个需要解释执行的语言中的句子表示为一个抽象语法树。
2、一些重复出现的问题可以用一种简单的语言来进行表达。
3、文法较为简单。
(6)模式总结:
1、在解释器模式中由于语法是由很多类表示的,所以可扩展性强。
2、虽然解释器的可扩展性强,但是如果语法规则的数目太大的时候,该模式可能就会变得异常复杂。所以解释器模式适用于文法较为简单的。
3、解释器模式可以处理脚本语言和编程语言。常用于解决某一特定类型的问题频繁发生情况。
六 访问者模式
访问者模式是对象的行为模式。访问者模式的目的是封装一些施加于某种数据结构元素之上的操作。一旦这些操作需要修改的话,接受这个操作的数据结构则可以保持不变。
分派的概念:
变量被声明时的类型叫做变量的静态类型(Static Type),有些人又把静态类型叫做明显类型(Apparent Type);而变量所引用的对象的真实类型又叫做变量的实际类型(Actual Type)。比如:
List list = null;
list = new ArrayList();声明了一个变量list,它的静态类型(也叫明显类型)是List,而它的实际类型是ArrayList。
根据对象的类型而对方法进行的选择,就是分派(Dispatch),分派(Dispatch)又分为两种,即静态分派和动态分派。
静态分派(Static Dispatch)发生在编译时期,分派根据静态类型信息发生。静态分派对于我们来说并不陌生,方法重载就是静态分派。
动态分派(Dynamic Dispatch)发生在运行时期,动态分派动态地置换掉某个方法。
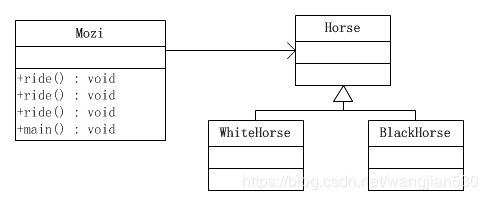
静态分派
Java通过方法重载支持静态分派。用墨子骑马的故事作为例子,墨子可以骑白马或者黑马。墨子与白马、黑马和马的类图如下所示:
在这个系统中,墨子由Mozi类代表
public class Mozi {
public void ride(Horse h){
System.out.println("骑马");
}
public void ride(WhiteHorse wh){
System.out.println("骑白马");
}
public void ride(BlackHorse bh){
System.out.println("骑黑马");
}
public static void main(String[] args) {
Horse wh = new WhiteHorse();
Horse bh = new BlackHorse();
Mozi mozi = new Mozi();
mozi.ride(wh);
mozi.ride(bh);
}
}显然,Mozi类的ride()方法是由三个方法重载而成的。这三个方法分别接受马(Horse)、白马(WhiteHorse)、黑马(BlackHorse)等类型的参数。
那么在运行时,程序会打印出什么结果呢?结果是程序会打印出相同的两行“骑马”。换言之,墨子发现他所骑的都是马。
为什么呢?两次对ride()方法的调用传入的是不同的参数,也就是wh和bh。它们虽然具有不同的真实类型,但是它们的静态类型都是一样的,均是Horse类型。
重载方法的分派是根据静态类型进行的,这个分派过程在编译时期就完成了。
动态分派
Java通过方法的重写支持动态分派。用马吃草的故事作为例子,代码如下所示:
public class Horse {
public void eat(){
System.out.println("马吃草");
}
}public class BlackHorse extends Horse {
@Override
public void eat() {
System.out.println("黑马吃草");
}
}public class Client {
public static void main(String[] args) {
Horse h = new BlackHorse();
h.eat();
}
}变量h的静态类型是Horse,而真实类型是BlackHorse。如果上面最后一行的eat()方法调用的是BlackHorse类的eat()方法,那么上面打印的就是“黑马吃草”;相反,如果上面的eat()方法调用的是Horse类的eat()方法,那么打印的就是“马吃草”。
所以,问题的核心就是Java编译器在编译时期并不总是知道哪些代码会被执行,因为编译器仅仅知道对象的静态类型,而不知道对象的真实类型;而方法的调用则是根据对象的真实类型,而不是静态类型。这样一来,上面最后一行的eat()方法调用的是BlackHorse类的eat()方法,打印的是“黑马吃草”。
分派的类型
一个方法所属的对象叫做方法的接收者,方法的接收者与方法的参数统称做方法的宗量。比如下面例子中的Test类
public class Test {
public void print(String str){
System.out.println(str);
}
}在上面的类中,print()方法属于Test对象,所以它的接收者也就是Test对象了。print()方法有一个参数是str,它的类型是String。
根据分派可以基于多少种宗量,可以将面向对象的语言划分为单分派语言(Uni-Dispatch)和多分派语言(Multi-Dispatch)。单分派语言根据一个宗量的类型进行对方法的选择,多分派语言根据多于一个的宗量的类型对方法进行选择。
C++和Java均是单分派语言,多分派语言的例子包括CLOS和Cecil。按照这样的区分,Java就是动态的单分派语言,因为这种语言的动态分派仅仅会考虑到方法的接收者的类型,同时又是静态的多分派语言,因为这种语言对重载方法的分派会考虑到方法的接收者的类型以及方法的所有参数的类型。
在一个支持动态单分派的语言里面,有两个条件决定了一个请求会调用哪一个操作:一是请求的名字,而是接收者的真实类型。单分派限制了方法的选择过程,使得只有一个宗量可以被考虑到,这个宗量通常就是方法的接收者。在Java语言里面,如果一个操作是作用于某个类型不明的对象上面,那么对这个对象的真实类型测试仅会发生一次,这就是动态的单分派的特征。
双重分派
一个方法根据两个宗量的类型来决定执行不同的代码,这就是“双重分派”。Java语言不支持动态的多分派,也就意味着Java不支持动态的双分派。但是通过使用设计模式,也可以在Java语言里实现动态的双重分派。
在Java中可以通过两次方法调用来达到两次分派的目的。类图如下所示:
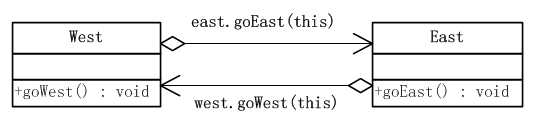
在图中有两个对象,左边的叫做West,右边的叫做East。现在West对象首先调用East对象的goEast()方法,并将它自己传入。在East对象被调用时,立即根据传入的参数知道了调用者是谁,于是反过来调用“调用者”对象的goWest()方法。通过两次调用将程序控制权轮番交给两个对象,其时序图如下所示:
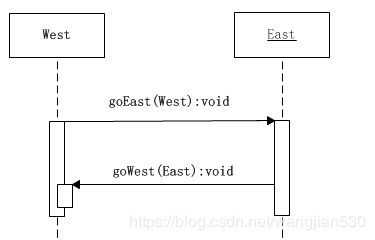
这样就出现了两次方法调用,程序控制权被两个对象像传球一样,首先由West对象传给了East对象,然后又被返传给了West对象。
但是仅仅返传了一下球,并不能解决双重分派的问题。关键是怎样利用这两次调用,以及Java语言的动态单分派功能,使得在这种传球的过程中,能够触发两次单分派。
动态单分派在Java语言中是在子类重写父类的方法时发生的。换言之,West和East都必须分别置身于自己的类型等级结构中,如下图所示:
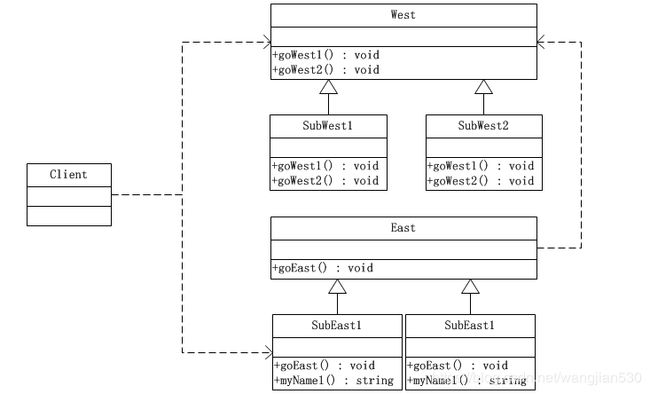
源代码
West类
public abstract class West {
public abstract void goWest1(SubEast1 east);
public abstract void goWest2(SubEast2 east);
}SubWest1类
public class SubWest1 extends West{
@Override
public void goWest1(SubEast1 east) {
System.out.println("SubWest1 + " + east.myName1());
}
@Override
public void goWest2(SubEast2 east) {
System.out.println("SubWest1 + " + east.myName2());
}
}SubWest2类
public class SubWest2 extends West{
@Override
public void goWest1(SubEast1 east) {
System.out.println("SubWest2 + " + east.myName1());
}
@Override
public void goWest2(SubEast2 east) {
System.out.println("SubWest2 + " + east.myName2());
}
}East类
public abstract class East {
public abstract void goEast(West west);
}SubEast1类
public class SubEast1 extends East{
@Override
public void goEast(West west) {
west.goWest1(this);
}
public String myName1(){
return "SubEast1";
}
}SubEast2类
public class SubEast2 extends East{
@Override
public void goEast(West west) {
west.goWest2(this);
}
public String myName2(){
return "SubEast2";
}
}客户端类
public class Client {
public static void main(String[] args) {
//组合1
East east = new SubEast1();
West west = new SubWest1();
east.goEast(west);
//组合2
east = new SubEast1();
west = new SubWest2();
east.goEast(west);
}
}运行结果如下
SubWest1 + SubEast1
SubWest2 + SubEast1
系统运行时,会首先创建SubWest1和SubEast1对象,然后客户端调用SubEast1的goEast()方法,并将SubWest1对象传入。由于SubEast1对象重写了其超类East的goEast()方法,因此,这个时候就发生了一次动态的单分派。当SubEast1对象接到调用时,会从参数中得到SubWest1对象,所以它就立即调用这个对象的goWest1()方法,并将自己传入。由于SubEast1对象有权选择调用哪一个对象,因此,在此时又进行一次动态的方法分派。
这个时候SubWest1对象就得到了SubEast1对象。通过调用这个对象myName1()方法,就可以打印出自己的名字和SubEast对象的名字,其时序图如下所示:
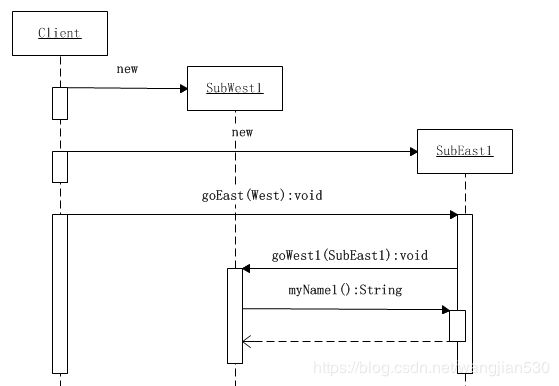
由于这两个名字一个来自East等级结构,另一个来自West等级结构中,因此,它们的组合式是动态决定的。这就是动态双重分派的实现机制。
访问者模式的结构
访问者模式适用于数据结构相对未定的系统,它把数据结构和作用于结构上的操作之间的耦合解脱开,使得操作集合可以相对自由地演化。访问者模式的简略图如下所示:
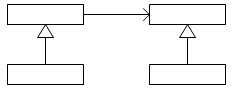
数据结构的每一个节点都可以接受一个访问者的调用,此节点向访问者对象传入节点对象,而访问者对象则反过来执行节点对象的操作。这样的过程叫做“双重分派”。节点调用访问者,将它自己传入,访问者则将某算法针对此节点执行。访问者模式的示意性类图如下所示:
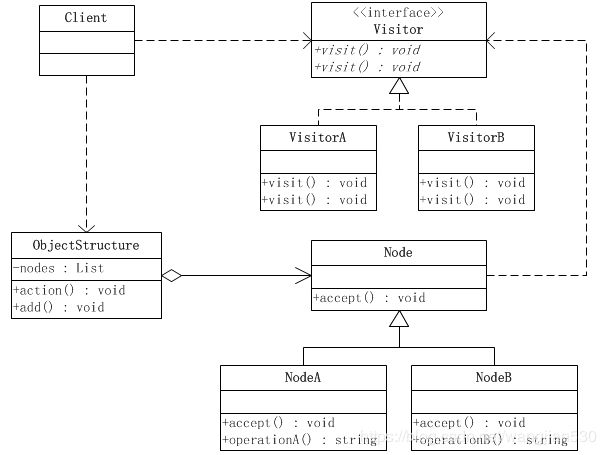
访问者模式涉及到的角色如下:
● 抽象访问者(Visitor)角色:声明了一个或者多个方法操作,形成所有的具体访问者角色必须实现的接口。
● 具体访问者(ConcreteVisitor)角色:实现抽象访问者所声明的接口,也就是抽象访问者所声明的各个访问操作。
● 抽象节点(Node)角色:声明一个接受操作,接受一个访问者对象作为一个参数。
● 具体节点(ConcreteNode)角色:实现了抽象节点所规定的接受操作。
● 结构对象(ObjectStructure)角色:有如下的责任,可以遍历结构中的所有元素;如果需要,提供一个高层次的接口让访问者对象可以访问每一个元素;如果需要,可以设计成一个复合对象或者一个聚集,如List或Set。
源代码
可以看到,抽象访问者角色为每一个具体节点都准备了一个访问操作。由于有两个节点,因此,对应就有两个访问操作。
public interface Visitor {
/**
* 对应于NodeA的访问操作
*/
public void visit(NodeA node);
/**
* 对应于NodeB的访问操作
*/
public void visit(NodeB node);
}具体访问者VisitorA类:
public class VisitorA implements Visitor {
/**
* 对应于NodeA的访问操作
*/
@Override
public void visit(NodeA node) {
System.out.println(node.operationA());
}
/**
* 对应于NodeB的访问操作
*/
@Override
public void visit(NodeB node) {
System.out.println(node.operationB());
}
}具体访问者VisitorB类:
public class VisitorB implements Visitor {
/**
* 对应于NodeA的访问操作
*/
@Override
public void visit(NodeA node) {
System.out.println(node.operationA());
}
/**
* 对应于NodeB的访问操作
*/
@Override
public void visit(NodeB node) {
System.out.println(node.operationB());
}
}抽象节点类
public abstract class Node {
/**
* 接受操作
*/
public abstract void accept(Visitor visitor);
}具体节点类NodeA
public class NodeA extends Node{
/**
* 接受操作
*/
@Override
public void accept(Visitor visitor) {
visitor.visit(this);
}
/**
* NodeA特有的方法
*/
public String operationA(){
return "NodeA";
}
}具体节点类NodeB:
public class NodeB extends Node{
/**
* 接受方法
*/
@Override
public void accept(Visitor visitor) {
visitor.visit(this);
}
/**
* NodeB特有的方法
*/
public String operationB(){
return "NodeB";
}
}结构对象角色类,这个结构对象角色持有一个聚集,并向外界提供add()方法作为对聚集的管理操作。通过调用这个方法,可以动态地增加一个新的节点。
public class ObjectStructure {
private List nodes = new ArrayList();
/**
* 执行方法操作
*/
public void action(Visitor visitor){
for(Node node : nodes)
{
node.accept(visitor);
}
}
/**
* 添加一个新元素
*/
public void add(Node node){
nodes.add(node);
}
} 客户端类
public class Client {
public static void main(String[] args) {
//创建一个结构对象
ObjectStructure os = new ObjectStructure();
//给结构增加一个节点
os.add(new NodeA());
//给结构增加一个节点
os.add(new NodeB());
//创建一个访问者
Visitor visitor = new VisitorA();
os.action(visitor);
}
}虽然在这个示意性的实现里并没有出现一个复杂的具有多个树枝节点的对象树结构,但是,在实际系统中访问者模式通常是用来处理复杂的对象树结构的,而且访问者模式可以用来处理跨越多个等级结构的树结构问题。这正是访问者模式的功能强大之处。
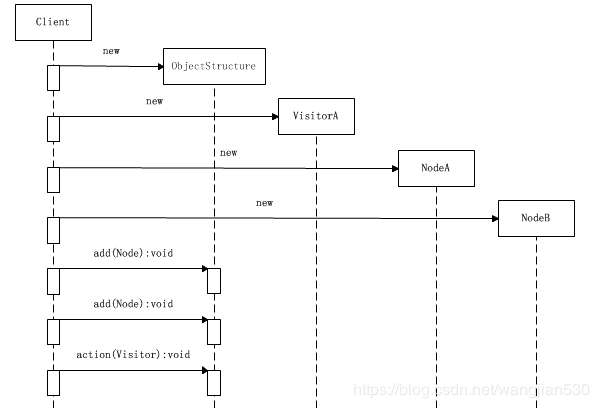
准备过程时序图
首先,这个示意性的客户端创建了一个结构对象,然后将一个新的NodeA对象和一个新的NodeB对象传入。
其次,客户端创建了一个VisitorA对象,并将此对象传给结构对象。
然后,客户端调用结构对象聚集管理方法,将NodeA和NodeB节点加入到结构对象中去。
最后,客户端调用结构对象的行动方法action(),启动访问过程。
访问过程时序图
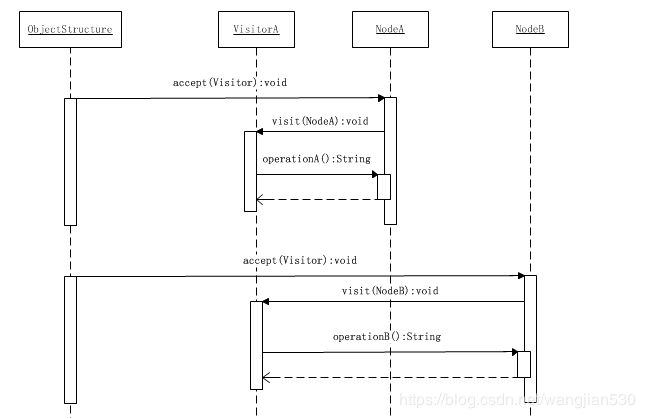
结构对象会遍历它自己所保存的聚集中的所有节点,在本系统中就是节点NodeA和NodeB。首先NodeA会被访问到,这个访问是由以下的操作组成的:
(1)NodeA对象的接受方法accept()被调用,并将VisitorA对象本身传入;
(2)NodeA对象反过来调用VisitorA对象的访问方法,并将NodeA对象本身传入;
(3)VisitorA对象调用NodeA对象的特有方法operationA()。
从而就完成了双重分派过程,接着,NodeB会被访问,这个访问的过程和NodeA被访问的过程是一样的,这里不再叙述。
访问者模式的优点
● 好的扩展性
能够在不修改对象结构中的元素的情况下,为对象结构中的元素添加新的功能。
● 好的复用性
可以通过访问者来定义整个对象结构通用的功能,从而提高复用程度。
● 分离无关行为
可以通过访问者来分离无关的行为,把相关的行为封装在一起,构成一个访问者,这样每一个访问者的功能都比较单一。
访问者模式的缺点
● 对象结构变化很困难
不适用于对象结构中的类经常变化的情况,因为对象结构发生了改变,访问者的接口和访问者的实现都要发生相应的改变,代价太高。
● 破坏封装
访问者模式通常需要对象结构开放内部数据给访问者和ObjectStructrue,这破坏了对象的封装性。
七 策略模式
策略模式属于对象的行为模式。其用意是针对一组算法,将每一个算法封装到具有共同接口的独立的类中,从而使得它们可以相互替换。策略模式使得算法可以在不影响到客户端的情况下发生变化。
策略模式的结构
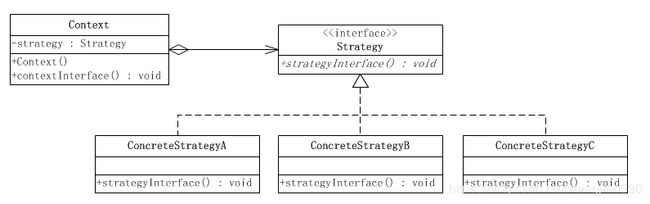
策略模式是对算法的包装,是把使用算法的责任和算法本身分割开来,委派给不同的对象管理。策略模式通常把一个系列的算法包装到一系列的策略类里面,作为一个抽象策略类的子类。用一句话来说,就是:“准备一组算法,并将每一个算法封装起来,使得它们可以互换”。下面就以一个示意性的实现讲解策略模式实例的结构。
这个模式涉及到三个角色:
● 环境(Context)角色:持有一个Strategy的引用。
● 抽象策略(Strategy)角色:这是一个抽象角色,通常由一个接口或抽象类实现。此角色给出所有的具体策略类所需的接口。
● 具体策略(ConcreteStrategy)角色:包装了相关的算法或行为。
源代码
环境角色类
public class Context {
//持有一个具体策略的对象
private Strategy strategy;
/**
* 构造函数,传入一个具体策略对象
* @param strategy 具体策略对象
*/
public Context(Strategy strategy){
this.strategy = strategy;
}
/**
* 策略方法
*/
public void contextInterface(){
strategy.strategyInterface();
}
}
抽象策略类
public interface Strategy {
/**
* 策略方法
*/
public void strategyInterface();
}
具体策略类
public class ConcreteStrategyA implements Strategy {
@Override
public void strategyInterface() {
//相关的业务
}
}
public class ConcreteStrategyB implements Strategy {
@Override
public void strategyInterface() {
//相关的业务
}
}
public class ConcreteStrategyC implements Strategy {
@Override
public void strategyInterface() {
//相关的业务
}
}
使用场景
假设现在要设计一个贩卖各类书籍的电子商务网站的购物车系统。一个最简单的情况就是把所有货品的单价乘上数量,但是实际情况肯定比这要复杂。比如,本网站可能对所有的高级会员提供每本20%的促销折扣;对中级会员提供每本10%的促销折扣;对初级会员没有折扣。
根据描述,折扣是根据以下的几个算法中的一个进行的:
算法一:对初级会员没有折扣。
算法二:对中级会员提供10%的促销折扣。
算法三:对高级会员提供20%的促销折扣。
使用策略模式来实现的结构图如下:

源代码
抽象折扣类
public interface MemberStrategy {
/**
* 计算图书的价格
* @param booksPrice 图书的原价
* @return 计算出打折后的价格
*/
public double calcPrice(double booksPrice);
}
初级会员折扣类
public class PrimaryMemberStrategy implements MemberStrategy {
@Override
public double calcPrice(double booksPrice) {
System.out.println("对于初级会员的没有折扣");
return booksPrice;
}
}
中级会员折扣类
public class IntermediateMemberStrategy implements MemberStrategy {
@Override
public double calcPrice(double booksPrice) {
System.out.println("对于中级会员的折扣为10%");
return booksPrice * 0.9;
}
}
高级会员折扣类
public class AdvancedMemberStrategy implements MemberStrategy {
@Override
public double calcPrice(double booksPrice) {
System.out.println("对于高级会员的折扣为20%");
return booksPrice * 0.8;
}
}
价格类
public class Price {
//持有一个具体的策略对象
private MemberStrategy strategy;
/**
* 构造函数,传入一个具体的策略对象
* @param strategy 具体的策略对象
*/
public Price(MemberStrategy strategy){
this.strategy = strategy;
}
/**
* 计算图书的价格
* @param booksPrice 图书的原价
* @return 计算出打折后的价格
*/
public double quote(double booksPrice){
return this.strategy.calcPrice(booksPrice);
}
}
客户端
public class Client {
public static void main(String[] args) {
//选择并创建需要使用的策略对象
MemberStrategy strategy = new AdvancedMemberStrategy();
//创建环境
Price price = new Price(strategy);
//计算价格
double quote = price.quote(300);
System.out.println("图书的最终价格为:" + quote);
}
}
从上面的示例可以看出,策略模式仅仅封装算法,提供新的算法插入到已有系统中,以及老算法从系统中“退休”的方法,策略模式并不决定在何时使用何种算法。在什么情况下使用什么算法是由客户端决定的。
认识策略模式
策略模式的重心
策略模式的重心不是如何实现算法,而是如何组织、调用这些算法,从而让程序结构更灵活,具有更好的维护性和扩展性。
算法的平等性
策略模式一个很大的特点就是各个策略算法的平等性。对于一系列具体的策略算法,大家的地位是完全一样的,正因为这个平等性,才能实现算法之间可以相互替换。所有的策略算法在实现上也是相互独立的,相互之间是没有依赖的。
所以可以这样描述这一系列策略算法:策略算法是相同行为的不同实现。
运行时策略的唯一性
运行期间,策略模式在每一个时刻只能使用一个具体的策略实现对象,虽然可以动态地在不同的策略实现中切换,但是同时只能使用一个。
公有的行为
经常见到的是,所有的具体策略类都有一些公有的行为。这时候,就应当把这些公有的行为放到共同的抽象策略角色Strategy类里面。当然这时候抽象策略角色必须要用Java抽象类实现,而不能使用接口。
这其实也是典型的将代码向继承等级结构的上方集中的标准做法。
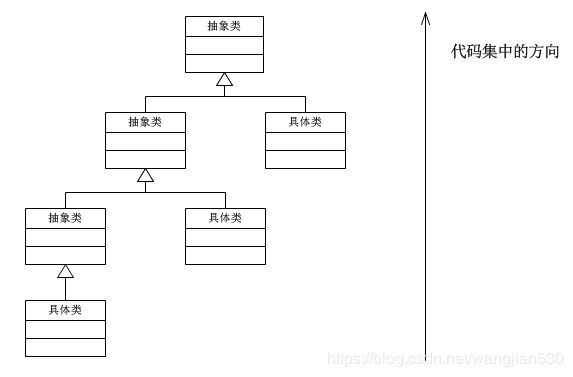
策略模式的优点
(1)策略模式提供了管理相关的算法族的办法。策略类的等级结构定义了一个算法或行为族。恰当使用继承可以把公共的代码移到父类里面,从而避免代码重复。
(2)使用策略模式可以避免使用多重条件(if-else)语句。多重条件语句不易维护,它把采取哪一种算法或采取哪一种行为的逻辑与算法或行为的逻辑混合在一起,统统列在一个多重条件语句里面,比使用继承的办法还要原始和落后。
策略模式的缺点
(1)客户端必须知道所有的策略类,并自行决定使用哪一个策略类。这就意味着客户端必须理解这些算法的区别,以便适时选择恰当的算法类。换言之,策略模式只适用于客户端知道算法或行为的情况。
(2)由于策略模式把每个具体的策略实现都单独封装成为类,如果备选的策略很多的话,那么对象的数目就会很可观。
八 模版方法模式
模板方法模式是类的行为模式。准备一个抽象类,将部分逻辑以具体方法以及具体构造函数的形式实现,然后声明一些抽象方法来迫使子类实现剩余的逻辑。不同的子类可以以不同的方式实现这些抽象方法,从而对剩余的逻辑有不同的实现。这就是模板方法模式的用意。
模板方法模式的结构
模板方法模式是所有模式中最为常见的几个模式之一,是基于继承的代码复用的基本技术。
模板方法模式需要开发抽象类和具体子类的设计师之间的协作。一个设计师负责给出一个算法的轮廓和骨架,另一些设计师则负责给出这个算法的各个逻辑步骤。代表这些具体逻辑步骤的方法称做基本方法(primitive method);而将这些基本方法汇总起来的方法叫做模板方法(template method),这个设计模式的名字就是从此而来。
模板方法所代表的行为称为顶级行为,其逻辑称为顶级逻辑。模板方法模式的静态结构图如下所示:
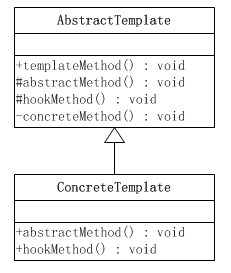
这里涉及到两个角色:
抽象模板(Abstract Template)角色有如下责任:
■ 定义了一个或多个抽象操作,以便让子类实现。这些抽象操作叫做基本操作,它们是一个顶级逻辑的组成步骤。
■ 定义并实现了一个模板方法。这个模板方法一般是一个具体方法,它给出了一个顶级逻辑的骨架,而逻辑的组成步骤在相应的抽象操作中,推迟到子类实现。顶级逻辑也有可能调用一些具体方法。
具体模板(Concrete Template)角色又如下责任:
■ 实现父类所定义的一个或多个抽象方法,它们是一个顶级逻辑的组成步骤。
■ 每一个抽象模板角色都可以有任意多个具体模板角色与之对应,而每一个具体模板角色都可以给出这些抽象方法(也就是顶级逻辑的组成步骤)的不同实现,从而使得顶级逻辑的实现各不相同。
下面我们来看一个银行办理业务得例子:

源代码:
package GOF23;
public abstract class BankTemplateMethod {
// 具体方法
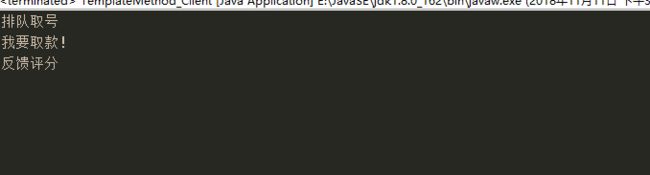
public void takeNumber() {
System.out.println("排队取号");
}
public abstract void transact(); // 办理具体业务----钩子方法
public void evaluate() {
System.out.println("反馈评分");
}
// 模版方法,把基本的操作组合到一起,子类一般能重写
public final void process() {
this.takeNumber();
this.transact(); // 像钩子一样,执行时,挂哪个子类的方法,就调用哪个。
this.evaluate();
}
}
客户端:
package GOF23;
public class TemplateMethod_Client {
public static void main(String[] args) {
BankTemplateMethod btm = new DrawMoney();
btm.process();
}
}
class DrawMoney extends BankTemplateMethod {
@Override
public void transact() {
System.out.println("我要取款!");
}
}结果:
也可以使用内部类来实现调用:
package GOF23;
public class TemplateMethod_Client {
public static void main(String[] args) {
// 也可以采用匿名内部类实现调用
BankTemplateMethod btm2 = new BankTemplateMethod() {
@Override
public void transact() {
System.out.println("我要存钱!");
}
};
btm2.process();
}
}
结果:

模板模式的关键是:子类可以置换掉父类的可变部分,但是子类却不可以改变模板方法所代表的顶级逻辑。
每当定义一个新的子类时,不要按照控制流程的思路去想,而应当按照“责任”的思路去想。换言之,应当考虑哪些操作是必须置换掉的,哪些操作是可以置换掉的,以及哪些操作是不可以置换掉的。使用模板模式可以使这些责任变得清晰。
模板方法模式中的方法
模板方法中的方法可以分为两大类:模板方法和基本方法。
模板方法
一个模板方法是定义在抽象类中的,把基本操作方法组合在一起形成一个总算法或一个总行为的方法。
一个抽象类可以有任意多个模板方法,而不限于一个。每一个模板方法都可以调用任意多个具体方法。
基本方法
基本方法又可以分为三种:抽象方法(Abstract Method)、具体方法(Concrete Method)和钩子方法(Hook Method)。
● 抽象方法:一个抽象方法由抽象类声明,由具体子类实现。在Java语言里抽象方法以abstract关键字标示。
● 具体方法:一个具体方法由抽象类声明并实现,而子类并不实现或置换。
● 钩子方法:一个钩子方法由抽象类声明并实现,而子类会加以扩展。通常抽象类给出的实现是一个空实现,作为方法的默认实现。
在上面的例子中,AbstractTemplate是一个抽象类,它带有三个方法。其中abstractMethod()是一个抽象方法,它由抽象类声明为抽象方法,并由子类实现;hookMethod()是一个钩子方法,它由抽象类声明并提供默认实现,并且由子类置换掉。concreteMethod()是一个具体方法,它由抽象类声明并实现。
默认钩子方法
一个钩子方法常常由抽象类给出一个空实现作为此方法的默认实现。这种空的钩子方法叫做“Do Nothing Hook”。显然,这种默认钩子方法在缺省适配模式里面已经见过了,一个缺省适配模式讲的是一个类为一个接口提供一个默认的空实现,从而使得缺省适配类的子类不必像实现接口那样必须给出所有方法的实现,因为通常一个具体类并不需要所有的方法。
命名规则
命名规则是设计师之间赖以沟通的管道之一,使用恰当的命名规则可以帮助不同设计师之间的沟通。
钩子方法的名字应当以do开始,这是熟悉设计模式的Java开发人员的标准做法。在上面的例子中,钩子方法hookMethod()应当以do开头;在HttpServlet类中,也遵从这一命名规则,如doGet()、doPost()等方法。
九 状态模式
1.概述
在软件开发过程中,应用程序可能会根据不同的情况作出不同的处理。最直接的解决方案是将这些所有可能发生的情况全都考虑到。然后使用if... ellse语句来做状态判断来进行不同情况的处理。但是对复杂状态的判断就显得“力不从心了”。随着增加新的状态或者修改一个状体(if else(或switch case)语句的增多或者修改)可能会引起很大的修改,而程序的可读性,扩展性也会变得很弱。维护也会很麻烦。那么我就考虑只修改自身状态的模式。
例子1:按钮来控制一个电梯的状态,一个电梯开们,关门,停,运行。每一种状态改变,都有可能要根据其他状态来更新处理。例如,开门状体,你不能在运行的时候开门,而是在电梯定下后才能开门。
例子2:我们给一部手机打电话,就可能出现这几种情况:用户开机,用户关机,用户欠费停机,用户消户等。 所以当我们拨打这个号码的时候:系统就要判断,该用户是否在开机且不忙状态,又或者是关机,欠费等状态。但不管是那种状态我们都应给出对应的处理操作。
2.问题
对象如何在每一种状态下表现出不同的行为?
3.解决方案
状态模式:允许一个对象在其内部状态改变时改变它的行为。对象看起来似乎修改了它的类。
在很多情况下,一个对象的行为取决于一个或多个动态变化的属性,这样的属性叫做状态,这样的对象叫做有状态的(stateful)对象,这样的对象状态是从事先定义好的一系列值中取出的。当一个这样的对象与外部事件产生互动时,其内部状态就会改变,从而使得系统的行为也随之发生变化。
4.适用性
在下面的两种情况下均可使用State模式:
if else(或switch case)语句,且这些分支依赖于该对象的状态。这个状态通常用一个或多个枚举常量表示。通常 , 有多个操作包含这一相同的条件结构。 State模式将每一个条件分支放入一个独立的类中。这使得你可以根据对象自身的情况将对象的状态作为一个对象,这一对象可以不依赖于其他对象而独立变化。
5.结构
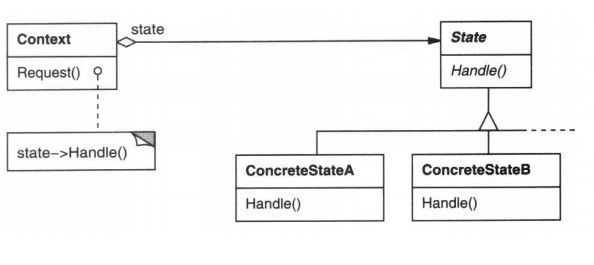
6.模式的组成
环境类(Context): 定义客户感兴趣的接口。维护一个ConcreteState子类的实例,这个实例定义当前状态。
抽象状态类(State): 定义一个接口以封装与Context的一个特定状态相关的行为。
具体状态类(ConcreteState): 每一子类实现一个与Context的一个状态相关的行为。
7.效果
State模式有下面一些效果:
状态模式的优点:
1 ) 它将与特定状态相关的行为局部化,并且将不同状态的行为分割开来: State模式将所有与一个特定的状态相关的行为都放入一个对象中。因为所有与状态相关的代码都存在于某一个State子类中, 所以通过定义新的子类可以很容易的增加新的状态和转换。另一个方法是使用数据值定义内部状态并且让 Context操作来显式地检查这些数据。但这样将会使整个Context的实现中遍布看起来很相似的条件if else语句或switch case语句。增加一个新的状态可能需要改变若干个操作, 这就使得维护变得复杂了。State模式避免了这个问题, 但可能会引入另一个问题, 因为该模式将不同状态的行为分布在多个State子类中。这就增加了子类的数目,相对于单个类的实现来说不够紧凑。但是如果有许多状态时这样的分布实际上更好一些, 否则需要使用巨大的条件语句。正如很长的过程一样,巨大的条件语句是不受欢迎的。它们形成一大整块并且使得代码不够清晰,这又使得它们难以修改和扩展。 State模式提供了一个更好的方法来组织与特定状态相关的代码。决定状态转移的逻辑不在单块的 i f或s w i t c h语句中, 而是分布在State子类之间。将每一个状态转换和动作封装到一个类中,就把着眼点从执行状态提高到整个对象的状态。这将使代码结构化并使其意图更加清晰。2) 它使得状态转换显式化: 当一个对象仅以内部数据值来定义当前状态时 , 其状态仅表现为对一些变量的赋值,这不够明确。为不同的状态引入独立的对象使得转换变得更加明确。而且, State对象可保证Context不会发生内部状态不一致的情况,因为从 Context的角度看,状态转换是原子的—只需重新绑定一个变量(即Context的State对象变量),而无需为多个变量赋值
3) State对象可被共享 如果State对象没有实例变量—即它们表示的状态完全以它们的类型来编码—那么各Context对象可以共享一个State对象。当状态以这种方式被共享时, 它们必然是没有内部状态, 只有行为的轻量级对象。
状态模式的缺点:
1) 状态模式的使用必然会增加系统类和对象的个数。
2) 状态模式的结构与实现都较为复杂,如果使用不当将导致程序结构和代码的混乱。
8.实现
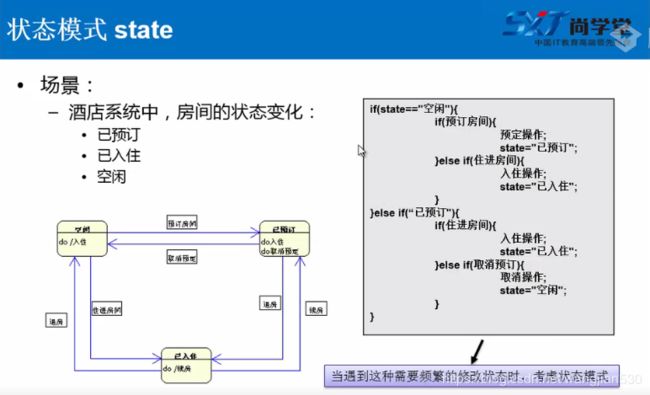
下面我将举一个酒店订房间的例子:
State接口:
package GOF23;
/**
* 状态模式
* @author lenovo
*
*/
public interface State {
void handle();
}
酒店房间分为空间、已预定、入住状态:
空闲:
package GOF23;
/**
* 空闲状态
* @author lenovo
*
*/
public class FreeState implements State{
@Override
public void handle() {
System.out.println("房间空闲状态!");
}
}
已预定:
package GOF23;
/**
* 预定状态
* @author lenovo
*
*/
public class BookedState implements State{
@Override
public void handle() {
System.out.println("房间以已经预定!");
}
}
入住:
package GOF23;
/**
* 入住状态
* @author lenovo
*
*/
public class CheckedState implements State{
@Override
public void handle() {
System.out.println("房间已经入住!");
}
}
Context
package GOF23;
/**
* 维持不同状态的切换
* @author lenovo
*
*/
public class State_Context {
private State state;
public void setState(State s) {
System.out.println("修改状态!");
state = s;
state.handle();
}
}
客户端:
package GOF23;
public class State_Client {
public static void main(String[] args) {
State_Context ctx = new State_Context();
ctx.setState(new FreeState()); // 房间设为空闲状态
ctx.setState(new BookedState());
}
}
结果:
9.与其他相关模式
1)职责链模式,
职责链模式和状态模式都可以解决If分支语句过多,
从定义来看,状态模式是一个对象的内在状态发生改变(一个对象,相对比较稳定,处理完一个对象下一个对象的处理一般都已确定),
而职责链模式是多个对象之间的改变(多个对象之间的话,就会出现某个对象不存在的现在,就像我们举例的公司请假流程,经理可能不在公司情况),这也说明他们两个模式处理的情况不同。
这两个设计模式最大的区别就是状态模式是让各个状态对象自己知道其下一个处理的对象是谁。
而职责链模式中的各个对象并不指定其下一个处理的对象到底是谁,只有在客户端才设定。
用我们通俗的编程语言来说,就是
状态模式:
相当于If else if else;
设计路线:各个State类的内部实现(相当于If,else If内的条件)
执行时通过State调用Context方法来执行。
职责链模式:
相当于Swich case
设计路线:客户设定,每个子类(case)的参数是下一个子类(case)。
使用时,向链的第一个子类的执行方法传递参数就可以。
就像对设计模式的总结,有的人采用的是状态模式,从头到尾,提前一定定义好下一个处理的对象是谁,而我采用的是职责链模式,随时都有可能调整链的顺序。2) 策略模式:(http://www.cnblogs.com/Mainz/archive/2007/12/15/996081.html)(状态模式是策略模式的孪生兄弟)
状态模式和策略模式的实现方法非常类似,都是利用多态把一些操作分配到一组相关的简单的类中,因此很多人认为这两种模式实际上是相同的。
然而在现实世界中,策略(如促销一种商品的策略)和状态(如同一个按钮来控制一个电梯的状态,又如手机界面中一个按钮来控制手机)是两种完全不同的思想。当我们对状态和策略进行建模时,这种差异会导致完全不同的问题。例如,对状态进行建模时,状态迁移是一个核心内容;然而,在选择策略时,迁移与此毫无关系。另外,策略模式允许一个客户选择或提供一种策略,而这种思想在状态模式中完全没有。
一个策略是一个计划或方案,通过执行这个计划或方案,我们可以在给定的输入条件下达到一个特定的目标。策略是一组方案,他们可以相互替换;选择一个策略,获得策略的输出。策略模式用于随不同外部环境采取不同行为的场合。我们可以参考微软企业库底层Object Builder的创建对象的strategy实现方式。而状态模式不同,对一个状态特别重要的对象,通过状态机来建模一个对象的状态;状态模式处理的核心问题是状态的迁移,因为在对象存在很多状态情况下,对各个business flow,各个状态之间跳转和迁移过程都是及其复杂的。
例如一个工作流,审批一个文件,存在新建、提交、已修改、HR部门审批中、老板审批中、HR审批失败、老板审批失败等状态,涉及多个角色交互,涉及很多事件,这种情况下用状态模式(状态机)来建模更加合适;把各个状态和相应的实现步骤封装成一组简单的继承自一个接口或抽象类的类,通过另外的一个Context来操作他们之间的自动状态变换,通过event来自动实现各个状态之间的跳转。在整个生命周期中存在一个状态的迁移曲线,这个迁移曲线对客户是透明的。我们可以参考微软最新的WWF 状态机工作流实现思想。
在状态模式中,状态的变迁是由对象的内部条件决定,外界只需关心其接口,不必关心其状态对象的创建和转化;
而策略模式里,采取何种策略由外部条件(C)决定。
他们应用场景(目的)却不一样,State模式重在强调对象内部状态的变化改变对象的行为,Strategy模式重在外部对策略的选择,策略的选择由外部条件决定,
也就是说算法的动态的切换。但由于它们的结构是如此的相似,我们可以认为“状态模式是完全封装且自修改的策略模式”。即状态模式是封装对象内部的状态的,而策略模式是封装算法族的
10.总结与分析
状态模式的主要优点在于封装了转换规则,并枚举可能的状态,它将所有与某个状态有关的行为放到一个类中,并且可以方便地增加新的状态,只需要改变对象状态即可改变对象的行为,还可以让多个环境对象共享一个状态对象,从而减少系统中对象的个数;其缺点在于使用状态模式会增加系统类和对象的个数,且状态模式的结构与实现都较为复杂,如果使用不当将导致程序结构和代码的混乱,对于可以切换状态的状态模式不满足“开闭原则”的要求。
十 观察者模式
1、初步认识
观察者模式的定义:
在对象之间定义了一对多的依赖,这样一来,当一个对象改变状态,依赖它的对象会收到通知并自动更新。
大白话:
其实就是发布订阅模式,发布者发布信息,订阅者获取信息,订阅了就能收到信息,没订阅就收不到信息。
2、这个模式的结构图
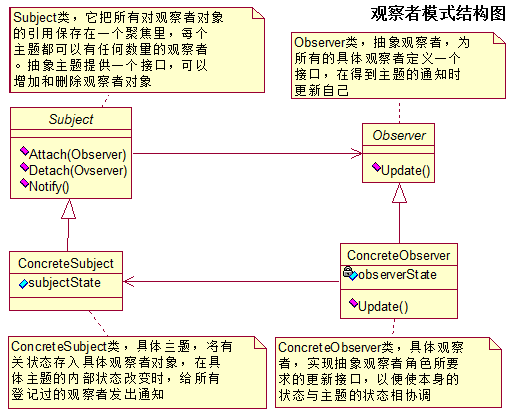
3、可以看到,该模式包含四个角色
- 抽象被观察者角色:也就是一个抽象主题,它把所有对观察者对象的引用保存在一个集合中,每个主题都可以有任意数量的观察者。抽象主题提供一个接口,可以增加和删除观察者角色。一般用一个抽象类和接口来实现。
- 抽象观察者角色:为所有的具体观察者定义一个接口,在得到主题通知时更新自己。
- 具体被观察者角色:也就是一个具体的主题,在集体主题的内部状态改变时,所有登记过的观察者发出通知。
- 具体观察者角色:实现抽象观察者角色所需要的更新接口,一边使本身的状态与制图的状态相协调。
4、使用场景例子
有一个微信公众号服务,不定时发布一些消息,关注公众号就可以收到推送消息,取消关注就收不到推送消息。
5、观察者模式具体实现
1、定义一个抽象被观察者接口
package com.jstao.observer;
/***
* 抽象被观察者接口
* 声明了添加、删除、通知观察者方法
* @author jstao
*
*/
public interface Observerable {
public void registerObserver(Observer o);
public void removeObserver(Observer o);
public void notifyObserver();
}2、定义一个抽象观察者接口
package com.jstao.observer;
/***
* 抽象观察者
* 定义了一个update()方法,当被观察者调用notifyObservers()方法时,观察者的update()方法会被回调。
* @author jstao
*
*/
public interface Observer {
public void update(String message);
}3、定义被观察者,实现了Observerable接口,对Observerable接口的三个方法进行了具体实现,同时有一个List集合,用以保存注册的观察者,等需要通知观察者时,遍历该集合即可
package com.jstao.observer;
import java.util.ArrayList;
import java.util.List;
/**
* 被观察者,也就是微信公众号服务
* 实现了Observerable接口,对Observerable接口的三个方法进行了具体实现
* @author jstao
*
*/
public class WechatServer implements Observerable {
//注意到这个List集合的泛型参数为Observer接口,设计原则:面向接口编程而不是面向实现编程
private List list;
private String message;
public WechatServer() {
list = new ArrayList();
}
@Override
public void registerObserver(Observer o) {
list.add(o);
}
@Override
public void removeObserver(Observer o) {
if(!list.isEmpty())
list.remove(o);
}
//遍历
@Override
public void notifyObserver() {
for(int i = 0; i < list.size(); i++) {
Observer oserver = list.get(i);
oserver.update(message);
}
}
public void setInfomation(String s) {
this.message = s;
System.out.println("微信服务更新消息: " + s);
//消息更新,通知所有观察者
notifyObserver();
}
} 4、定义具体观察者,微信公众号的具体观察者为用户User
package com.jstao.observer;
/**
* 观察者
* 实现了update方法
* @author jstao
*
*/
public class User implements Observer {
private String name;
private String message;
public User(String name) {
this.name = name;
}
@Override
public void update(String message) {
this.message = message;
read();
}
public void read() {
System.out.println(name + " 收到推送消息: " + message);
}
}5、编写一个测试类
首先注册了三个用户,ZhangSan、LiSi、WangWu。公众号发布了一条消息"PHP是世界上最好用的语言!",三个用户都收到了消息。
用户ZhangSan看到消息后颇为震惊,果断取消订阅,这时公众号又推送了一条消息,此时用户ZhangSan已经收不到消息,其他用户
还是正常能收到推送消息。
package com.jstao.observer;
public class Test {
public static void main(String[] args) {
WechatServer server = new WechatServer();
Observer userZhang = new User("ZhangSan");
Observer userLi = new User("LiSi");
Observer userWang = new User("WangWu");
server.registerObserver(userZhang);
server.registerObserver(userLi);
server.registerObserver(userWang);
server.setInfomation("PHP是世界上最好用的语言!");
System.out.println("----------------------------------------------");
server.removeObserver(userZhang);
server.setInfomation("JAVA是世界上最好用的语言!");
}
}测试结果:

其实我们还可以用Java自带的观察者类Observerable类:
具体的目标对象ConcreteSubject:
package GOF23;
import java.util.Observable;
/**
* 使用java自带的观察者类
*
* @author lenovo
*
*/
public class ConcreteSubject1 extends Observable {
private int state;
public void set(int s) {
state = s; // 目标对象的状态发生了改变
setChanged(); // 表示目标对象已经做了改变
notifyObservers(state); // 通知所有观察者模式
}
public int getState() {
return state;
}
public void setState(int state) {
this.state = state;
}
}
观察者Observer:
package GOF23;
import java.util.Observable;
import java.util.Observer;
public class ObserverA1 implements Observer {
private int myState;
@Override
public void update(Observable o, Object arg) {
myState = ((ConcreteSubject1) o).getState();
}
public int getMyState() {
return myState;
}
public void setMyState(int myState) {
this.myState = myState;
}
}
客户端我们改变目标对象的state的值,我们发现观察者们的myState的值也跟着改变了:
package GOF23;
public class Observer_Client1 {
public static void main(String[] args) {
ConcreteSubject1 subject = new ConcreteSubject1(); // 创建一个具体的目标对象
//创建多个观察者
ObserverA1 obs1 = new ObserverA1();
ObserverA1 obs2 = new ObserverA1();
ObserverA1 obs3 = new ObserverA1();
//将这三个观察者添加到subject对象的观察者容器中
subject.addObserver(obs1);
subject.addObserver(obs2);
subject.addObserver(obs3);
System.out.println("MyState原来的值:");
System.out.println(obs1.getMyState());
System.out.println(obs2.getMyState());
System.out.println(obs3.getMyState());
//改变subject的状态
subject.set(2000); //state默认值是0;
//我们看看观察者的状态有没有变化
System.out.println("MyState改变后的值:");
System.out.println(obs1.getMyState());
System.out.println(obs2.getMyState());
System.out.println(obs3.getMyState());
}
}
结果:

6、小结
- 这个模式是松偶合的。改变主题或观察者中的一方,另一方不会受到影像。
- JDK中也有自带的观察者模式。但是被观察者是一个类而不是接口,限制了它的复用能力。
- 在JavaBean和Swing中也可以看到观察者模式的影子。
十一 备忘录模式

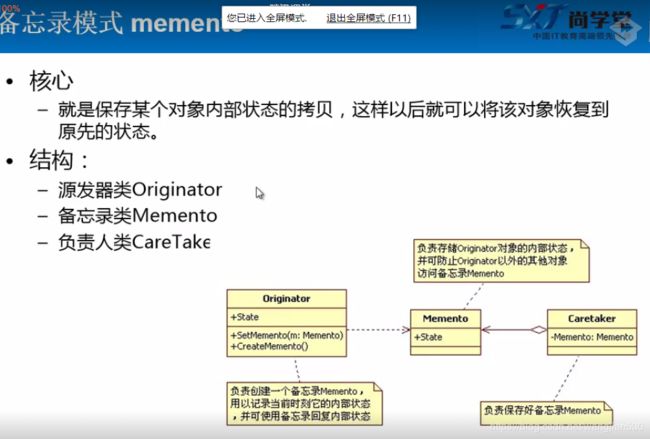



举个例子 :
源发器类:
package GOF23;
/**
* 备忘录模式 源发器类
*
* @author lenovo
*
*/
public class Memento_Emp {
private String ename;
private int age;
private double salary;
//进行备忘操作, 并返回备忘录对象
public Memento memento() {
return new Memento(this);
}
//进行数据恢复,恢复成指定备忘录对象的值
public void recovery(Memento mmt) {
this.ename = mmt.getEname();
this.age = mmt.getAge();
this.salary = mmt.getSalary();
}
public String getEname() {
return ename;
}
public void setEname(String ename) {
this.ename = ename;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public double getSalary() {
return salary;
}
public void setSalary(double salary) {
this.salary = salary;
}
public Memento_Emp(String ename, int age, double salary) {
super();
this.ename = ename;
this.age = age;
this.salary = salary;
}
}
备忘录类:
package GOF23;
/**
* 备忘录类
*
* @author lenovo
*
*/
public class Memento {
private String ename;
private int age;
private double salary;
public Memento(Memento_Emp e) {
this.ename = e.getEname();
this.age = e.getAge();
this.salary = e.getSalary();
}
public String getEname() {
return ename;
}
public void setEname(String ename) {
this.ename = ename;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public double getSalary() {
return salary;
}
public void setSalary(double salary) {
this.salary = salary;
}
}
负责人类 管理我们备忘录对象:
package GOF23;
import java.util.ArrayList;
import java.util.List;
/**
* 负责人类 管理我们备忘录对象
*
* @author lenovo
*
*/
public class CareTaker {
private Memento memento;
// private List list = new ArrayList(); //可以存多个备忘点
public Memento getMemento() {
return memento;
}
public void setMemento(Memento memento) {
this.memento = memento;
}
}
客户端:
package GOF23;
public class Memento_Client {
public static void main(String[] args) {
CareTaker careTaker = new CareTaker();
Memento_Emp emp = new Memento_Emp("aa", 19, 2000);
System.out.println("第一次打印对象:" + emp.getEname() + "---" + emp.getAge() + "---" + emp.getSalary());
careTaker.setMemento(emp.memento()); //备忘一次
emp.setEname("bb");
emp.setAge(38);
emp.setSalary(1000);
System.out.println("第二次打印对象:" + emp.getEname() + "---" + emp.getAge() + "---" + emp.getSalary());
emp.recovery(careTaker.getMemento()); //恢复到备忘录对象保存的状态
System.out.println("第三次打印对象:" + emp.getEname() + "---" + emp.getAge() + "---" + emp.getSalary());
}
}
结果:我们发现调用recovery函数我们可以回退到原来的样子
