2019独角兽企业重金招聘Python工程师标准>>> 
前言
在分布式(数据库)系统中,我们经常会听到一些“高大上”却又比较“迷惑”的词汇,比如,ACID和CAP中的"C"是否是同一含义、Snapshot Isolation(SI)和Serializable Snapshot Isolation(SSI)区别是什么、Serializable和Linearizable是一个意思吗、Consistency和Consensus呢?如果你无法清晰的回答这些问题,那么希望本文会对你有所帮助。
ACID与CAP的Consistency
ACID和CAP中的C是都是Consistency的缩写,但是他们的含义却是截然不同的。ACID包含Atomicity(原子性)、Consistency(一致性)、Durability(持久性)、Isolation(隔离性)四个方面,其中Atomicity(原子性)、Durability(持久性)和 Isolation(隔离性)都是存储引擎提供的能力保障,但是Consistency(一致性)却不是存储引擎提供的,相反,它是业务层面的一种逻辑约束,以转账这个最为经典的例子而言,A有100元RMB,B有0元RMB,现在A要转给B 50元RMB,那么转账前后,A和B的总钱数必须还是100元RMB,显然,这只是业务层规定的逻辑约束而已。在《DDIA》一书中,对ACID也有着如下的描述:

CAP是Consistency(一致性)、Availability(可用性)和Partition tolerance(分区容错性)的简称,这里的Consistency(一致性)其实更符合我们对一致性更直观的理解,它表示一种对“数据新鲜度”的保证,即对“何时”能读到“正确”的数据的保证。这里的Consistency就代表Linearizability Consistency(线性一致性),另外,我们常见一致性模型还有Sequential Consistency(顺序一致性)和Casual Consistency(因果一致性)等,这些在后文中会着重介绍。《DDIA》一书对CAP也有一些介绍,在此贴一下作为辅助说明:

Consistency和Consensus
Consistency和Consensus比较迷惑的不是它们的含义,更多的是他们看上去很“相似”,其实,只要把它们翻译成中文,也就好理解了。Consistency就是“一致性”的意思了(前文已经多次提到),而Consensus是“共识”的意思。工程中,Consistency表示你“何时”能读到“正确”的数据,常见的有Linearizability Consistency(线性一致性)、Sequential Consistency(顺序一致性)和Casual Consistency(因果一致性)等。而Consensus多指一种“共识”算法,即多方参与共同决定一件事情,比如Basic Paxos算法就可以用来在一群分布式节点中决定一个值(诸如选主操作)。当然Consistency和Consensus也不是完全没有关系的,很多Consistency模型中也会用到Consensus算法来完成。
Serializable和Linearizable
Serializable和Linearizable可以说是最容易混淆的两个概念,Serializable字面翻译为“序列化”,Linearizable字面翻译为“线性化”,乍一看差不多,但事实上它们是完全不同的两个方面。为了直观的看出它们的关系,引用一张出自jepsen官网的图:

从上图可以看到,Serializable是一种事务隔离级别(并发的事务之间),让所有的事务从自身角度看上去,好像所有的事务都以某种次序顺序执行一样(不一定满足全局时间顺序)。而Linearizable,前文已经多次提到,它是一种一致性模型(线性一致性),表示对某个对象执行写之后可以立刻读到这个最新值(读写顺序与全局时间一致)。因此可以看到,Serializable和Linearizable是完全不相关的概念。《DDIA》一书中对这两个概念也有较为直白的对比。

因此,所谓的Strict Serializable(强一致)模型,就是同时满足Serializable和Linearizable,即所有事务按串行化隔离级别执行(注:不一定是真的串行化执行,而是最终效果和某种串行执行效果相同)、并能立刻读出“正确”(注:正确表示能立刻读到一个对象最近写入的数据)数据的一致性模型,而Serializable Snapshot Isolation(SSI)只满足了Serializable却不具备Linearizable的语义,即它只满足了事务按某种顺序串行执行,却无法满足能立刻读到“正确”的数据。既然Linearizable表示一种Consistency模型,Serializable表示事务的一种Isolation级别,那么下文就分别从“一致性”和“隔离性”两个方面分别进行阐述。
一致性
Consistency并不是分布式数据库中新增的概念,相反,Consistency存在于计算机中的各个角落。比如,多核CPU的Cache之间存在Consistency问题,并发编程中多线程之间也存在内存Consistency问题。本文就将以常见的多线程编程为例,着重介绍Linearizability Consistency(线性一致性)、Sequential Consistency(顺序一致性)和Casual Consistency(因果一致性)之间的概念和区别,不用担心,这些概念和分布式中的Consistency模型是完全一致的。
Linearizability Consistency(线性一致性)
Linearizability Consistency(线性一致性)的要求两个:
-
任何一次读都能读到某个数据的最近一次写的数据。
-
系统中的所有进程,看到的操作顺序,都和全局时钟下的顺序一致。
显然这两个条件都对全局时钟有非常高的要求。比它要求更弱一些的,就是Sequential Consistency(顺序一致性)。
Sequential Consistency(顺序一致性)
Sequential Consistency(顺序一致性),也同样有两个条件,其一与前面Linearizability Consistency(线性一致性)的要求一样,也是可以马上读到最近写入的数据,然而它的第二个条件就弱化了很多,它允许系统中的所有进程形成自己合理的统一的一致性,不需要与全局时钟下的顺序都一致。
这里的第二个条件的要点在于:
-
系统的所有进程的顺序一致,而且是合理的,就是说任何一个进程中,这个进程对同一个变量的读写顺序要保持,然后大家形成一致。
-
不需要与全局时钟下的顺序一致。
可见, Sequential Consistency(顺序一致性)在顺序要求上并没有那么严格,它只要求系统中的所有进程达成自己认为的一致就可以了,即错的话一起错,对的话一起对,同时不违反程序的顺序即可,并不需要个全局顺序保持一致。
引用《分布式计算-原理、算法与系统》一张图进一步说明Linearizability Consistency(线性一致性)和Sequential Consistency(顺序一致性)之间的区别:

-
图a是满足Sequential Consistency(顺序一致性),但是不满足Linearizability Consistency(线性一致性)。原因在于,从全局时钟的观点来看,P2进程对变量X的读操作在P1进程对变量X的写操作之后,然而读出来的却是旧的数据。但是这个图却是满足Sequential Consistency(顺序一致性)的,因为两个进程P1,P2的一致性并没有冲突。从这两个进程的角度来看,顺序应该是这样的:Write(y,2) , Read(x,0) , Write(x,4), Read(y,2),每个进程内部的读写顺序都是合理的,但是显然这个顺序与全局时钟下看到的顺序并不一样。
-
图b满足Linearizability Consistency(线性一致性),因为每个读操作都读到了该变量的最新写的结果,同时两个进程看到的操作顺序与全局时钟的顺序一样,都是Write(y,2) , Read(x,4) , Write(x,4), Read(y,2)。
-
图c不满足Sequential Consistency(顺序一致性),当然也就不满足Linearizability Consistency(线性一致性)。因为从进程P1的角度看,它对变量Y的读操作返回了结果0。那么就是说,P1进程的对变量Y的读操作在P2进程对变量Y的写操作之前,这意味着它认为的顺序是这样的:write(x,4) , Read(y,0) , Write(y,2), Read(x,0),显然这个顺序又是不能被满足的,因为最后一个对变量x的读操作读出来也是旧的数据。因此这个顺序是有冲突的,不满足顺序一致性。
Casual Consistency(因果一致性)
Casual Consistency(因果一致性)在一致性的要求上,又比Sequential Consistency(顺序一致性)降低了:它仅要求有因果关系的操作顺序得到保证,非因果关系的操作顺序则无所谓。
因果相关的要求是这样的:
-
本地顺序:本进程中,事件执行的顺序即为本地因果顺序。
-
异地顺序:如果读操作返回的是写操作的值,那么该写操作在顺序上一定在读操作之前。
-
闭包传递:和时钟向量里面定义的一样,如果a->b,b->c,那么肯定也有a->c。
引用《分布式计算-原理、算法与系统》一书中的图来进一步说明 Casual Consistency(因果一致性)和 Sequential Consistency(顺序一致性)之间的区别:

-
图a满足 Sequential Consistency(顺序一致性),因此也满足Casual Consistency(因果一致性),因为从这个系统中的四个进程的角度看,它们都有相同的顺序也有相同的因果关系。
-
图b满足Casual Consistency(因果一致性)但是不满足 Sequential Consistency(顺序一致性)。首先P1和P2的写是没有因果关系的,从P3看来,Read(x,7) 表示P2的 Write(x,7)一定在P3的Read(x,7)之前, P3的Read(x,2)表示P1的Write(x,2)一定在P3的Read(x,2)之前,又因为P3中Read(x,7) 在Read(x,2)之前(本地因果顺序),因此,从P3角度看P1和P2的执行顺序应该是:Write(x,7)、Write(x,2)、Write(x,4)。同样的分析方法,可以得出从P4角度看P1和P2的执行顺序应该是:Write(x,2)、Write(x,4)、Write(x,7)。由于P3和P4看到的执行顺序不一致,因此这不满足Sequential Consistency(顺序一致性)要求。
-
图c展示了比Casual Consistency(因果一致性)更弱的一种一致性模型: PRAM(Pipelined Random Access Memory)管道式存储器,是Lipton和Sandberg于1988年在学术报告”PRAM: A scalable shared memory”中提出。如前所述, Sequential Consistency(顺序一致性)要求所有进程看到的程序执行顺序必须一致,而Casual Consistency(因果一致性)降低了一致性要求,它要求有因果关系的操作在所有进程上看到必须一致,而PRAM Consistency进一步降低一致性要求。先看PRAM定义:“…Writesdone by a single process are received by all other processes in the order inwhich they were issued, but writes from different processes may be seen in adifferent order by different processes.” 意即在PRAM中,不同进程可以看到不同的执行顺序,但在某一进程上的多个写操作,在所有进程上看到的顺序必须一致,而不同进程上的写操作在不同进程上看起来其执行顺序则可以不一致。图c展示的例子而言,从P3角度看到的P1和P2操作顺序为:Write(x,2)、Write(x,4)、Read(x,4)、Write(x,7),这是满足Casual Consistency(因果一致性)的。从P4角度看为:Write(x,2)、Read(x,4)、Write(x,7)、Write(x,4),这显然不满足Casual Consistency(因果一致性)的要求。
从jepsen官网的那张图可以看到,Casual Consistency(因果一致性)和PRAM下面还包含了Writes Follow Reads、Monotonic Reads、Monotonic Writes、Read Your Writes等一致性模型,这些都比较简单,鉴于篇幅原因本文不再赘述。
隔离性
前文提到了,Serializable是一种事务隔离级别(并发的事务之间),是ACID中的Isoloation的意思。但是最开始ACID的Isolation只有4中隔离级别,随着技术的演进,出现了很多当初的标准没有定义的新的隔离级别,诸如snapshot Isoloation等。下表详细概括了6种隔离级别,每种隔离级别强度层层递进,但也存在或引入某些新的问题,以snapshot Isoloation为例,它能解决repeatable read存在的幻读问题,但是却存在write skew的问题。
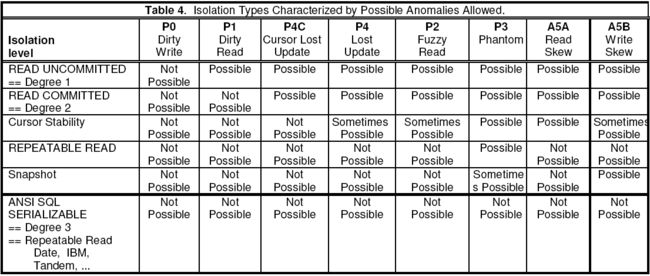
下面这张图更明显的体现了各隔离级别的强度关系。
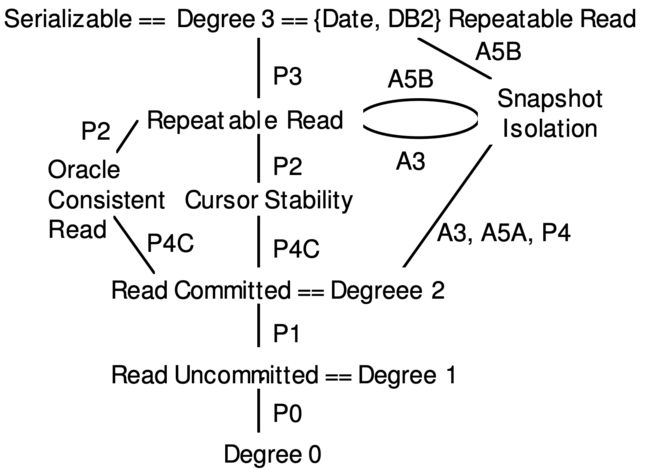
下面就不同隔离异常分别说明。
在这之前先定义几个概念:
长期锁:到事务结束就释放的锁
短期锁:对相关数据操作完成就释放的锁
这里提到的写锁和排他锁可以互换,读锁和共享锁可以互换,长期锁也被称为二阶段锁,就是事务某个时候锁上了算一个阶段,最后一起释放算一个阶段。
P0 dirty write (脏写)
现象:最开始的阶段是一切皆有可能发生,没有任何锁,所以碰到的第一个问题是脏写。当一个事务覆盖写了另一个正在运行的事务写入的值时就会发生脏写。比如下面的例子,事务一致性的约束性条件是x必须等于y, 一开始x和y初始值都为0,之后事务T1 准备写入 x=y=1 并且事务 T2 准备写入 x=y=2,但是由于T1和T2都没有对数据加锁,因此导致互相发生覆盖写(脏写),导致最终都成功commit之后,x==2,y==1,违反了约束性条件。
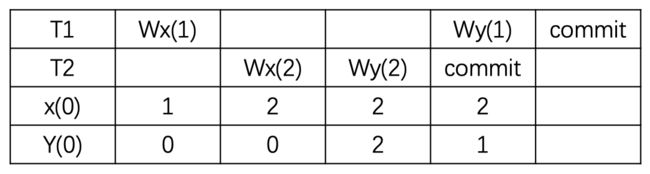
解决:对 x 和 y 持有长期写锁(直到commit之后才释放锁),这样后续的T2就无法覆盖写x,T1无法覆盖写y了。防止脏写以后会出现新的现象,脏读。
P1 dirty read (脏读 read uncommited)
现象: 当一个事务读取另一个仍处于运行中的事务写入的值时(未提交),就会发生脏读。比如下面的例子,事务一致性的约束性条件是x+y=100, 一开始x和y初始值都为50,事务T1准备将x改写为10(加长期写锁),此时事务T2读x为10(没有加任何锁),读y为50,对事务T2而言,x+y=60不满足约束性条件。

解决: 在基于锁的实现中,使用短期读锁和长期写锁,长期写锁可以防止事务 T2 读到x读数据,短期读锁可以让后续的T1 可以继续写y。解决脏读问题,又面临的问题是不可重复读。
P2 non-repeatable read (不可重复读)
现象:在使用短期读锁和长期写锁实现read commited之后就可能存在这种异常。比如下面的例子,事务一致性的约束性条件是x+y=100, 一开始x和y初始值都为50,T1读x为50(对x加短期读锁),之后事务T2对x和y都做了修改(对x和y加长期写锁),然后成功提交。 之后T1读y为90,此时对T1而言,x+y=140不满足约束条件,因此出现不可重复读。(注:因为此时T2已经commit,因此这不属于脏读read uncommited,注意和上面的例子做区分。同时还要注意,很多人认为只有对同一个对象读多次出现值不一样才算不可重复读,其实这是狭隘的理解,其实可以多次读不同对象,只要多次读会改变一致性约束就算不可重复读)
解决:在基于锁的实现中,使用长期读锁和长期写锁,也就是事务 T2 的 x 要等事务 T1 提交之后才能写入。解决了不可重复读以后,还会碰到幻读的情况。
P3 phantom (幻读)
现象:幻读发生在正在执行的事务 T1 有断言读 (如select where) 时,另外一个事务 T2 执行了和断言集合有交集的插入操作。比如 T1 在 T2 插入d之前读到了员工总数是 3,但是 T2 执行的时候有交集,插入了新的数据d,这个时候员工总数是 4,但是 T1 如果再读取的话,就会发现员工总数变成了 4,而不是最初的 3,这就是幻读。

解决:解决幻读的方式是使用长期(断言型)读锁和写锁。也就是不允许在这个范围内进行插入操作。解决了幻读以后的事务就完全可串行化了(不一定是真正的串行,而是等同于某种串行执行效果),这样的事务并发度是最弱的。
P4 update lost (更新丢失)
更新丢失这个现象不是比幻读更约束的现象,这个是在防止脏读(实现read commited)以后可能会出现的现象。
现象:事务 T2 提交的写被其他事务覆盖,首先,这不是脏写,因为 T2 已经提交,其次没有脏读,因为在写之后没有读操作,这样的现象称为更新丢失。
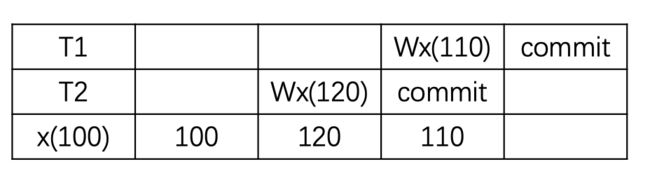
解决:升级到可重复读就可以了。
P4C cursor update lost (游标更新丢失)
现象:Cursor Lost Update 是上面 Lost Update 的一个变种,跟 SQL 的 cursor 相关。在下面的例子中,RC(x) 表明在 cursor 下面 read x,而 WC(x) 则表明在 cursor 下面写入 x。如果允许 T2 在 T1 RC 和 WC 之间写入数据,那么 T2 的更新也会丢失。
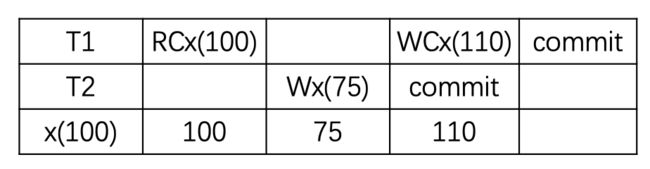
解决:在游标移动或者释放之前,都不释放锁,这个是到达可重复读之前的一个插曲。这个也是在实现read commited后会发生的事情。
A5A read skew (读偏)
偏可以理解为不一致,这个是发生在多个数据之间有一个总的约束的时候(逻辑上业务层面的约束)。
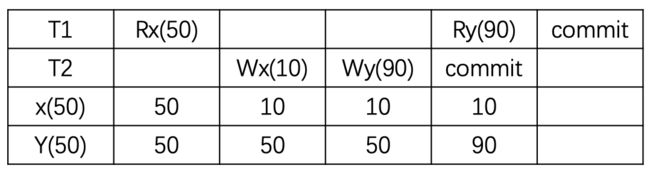
现象:读偏也是在实现read commited后可能出现的现象。 假设现在的约束是x+y=100,事务T1先读x为50(T1对x加短期读锁),然后事务T2将x改写为25(T2对x加长期写锁),将y改写为75(T2对x加长期写锁),对事务T2而言,x+y=100是满足约束的,所以它可以成功提交。T2提交成功之后(所有的锁也都释放了),此时T1还在运行,T1读y为75,x+y>100,不满足约束。
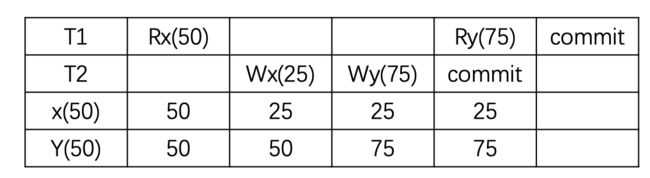
解决:使用快照隔离 (Snapshot Isolation),快照隔离是基于 MVCC 的。当一个 T 事务开始的时候,T 会获得一个抽象的时间戳(版本),当对数据 x 进行读取的时候,并不是直接看到最新写入的数据,而是在 T 开始前的所有执行事务中最后一个对 X 标记的版本(如果 T 修改过 x,那么看到的是自己的版本)。也就是说 T 是基于当前的数据库最近一个镜像进行操作的,而 T 开始执行时获得的版本就是这个快照的凭证。这样能保证所有的读都是基于一个一致的状态获取的。
SI 解决冲突的方法一般是 “First-Commiter-Wins”, 也就是说,如果两个并发的事务修改了同一个数据,先写的事务会成功,而后写的事务会发现版本和原本的不一致而退出事务(abort)。
以这里的例子来说,T1 的 y 只会读到自己开始时候的版本,也就是 50,而不是 75,这样读偏就解决了。但是快照隔离还是不能解决另一个问题,就是写偏。这是我们要面临的新问题。
A5B write skew (写偏)
现象:这个和读偏类似,只不过,它是一种业务逻辑层面上的不一致。事务T1和T2一开始都有自己的版本,T1读x为30,并将y从10改为60,从T1自身角度看并没有违反约束(x+y<=100)。同样,T2中先读y为10,并将x从30改为50,从T2角度看也并没有违反约束(x+y<=100)。最后,在T1和T2提交时都是可以提交成功的(任意顺序),因为它们没有修改相同的数据,在数据层面不存在冲突。但是此时x+y已经大于100了,违反了业务逻辑层面的约束。
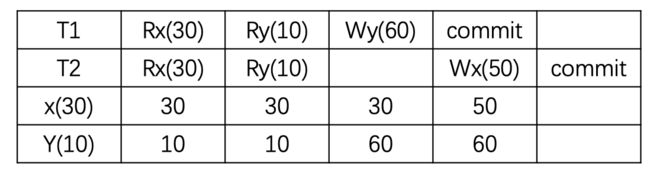
解决:目前Snapshot Isolation(SI)的算法有很多,参考 cockroachDB 使用的论文的话,可以说,通过对版本依赖构成有向图,解决成环问题,以此达到Serializable Snapshot Isolation(SSI)的级别。
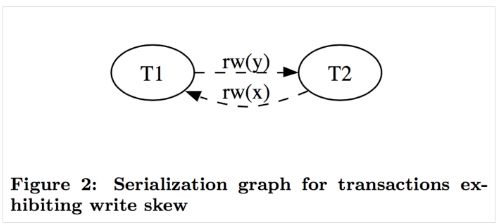
比如上面的例子,如果 T1 在 y 读了之后写了一个版本的 y 就构成一个先读后写的 rw(y) 依赖,类似的 T2 对 T1 构成了一个先读后写的 rw(x) 依赖。还有两种无害的依赖是先写后读 (wr) 和先写后写 (ww)。论文中阐述了,造成写偏的条件是成环,并且环中有两个连续的 rw 依赖。也就是下面这种形式。
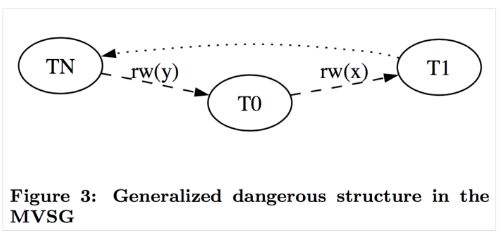
这个问题的关键是,检查成环这件事情,就跟操作系统检查死锁一样,消耗太大了,性能上不能接受。所以这个实现的妥协是,把检查放宽,让一些无害的条件也被认定为有害,通过重试来恢复执行,宁可错是一百,也绝不放过一个。
这个条件是只要有两个连续的 rw 依赖就会放弃提交,即使没有成环。这个检查发生在读的时候如果发现读的版本和自己开始之前的版本不一致就会找到依赖的事务,构建一条入边,另一个事务构建一条出边,如果某个事务入边出边都有 rw 边,这个节点就会被作为嫌疑人。当然还有其他关于Serializable Snapshot Isolation(SSI)隔离的论文可以参考。
总结
至此,本文对开始提出的几个概念和疑惑都做了介绍和解答,其实,分布式(数据库)系统中还有很多类似的概念,比如计算层常用的逻辑执行计划与物理执行计划、2PC与2PL、MVCC与Snapshot Isolation是什么关系等,其中,有很多并不是概念上的迷惑,而是由于这些技术和词汇大多由国外发明,在向国内渗透过程中,一般人很难在一开始就能完全东西背后的含义。