Webbench实现与详解
本博客已弃用,当时存在一些小细节错误后期也不再修改了
欢迎来我的新博客
Webench是一款轻量级的网站测压工具,最多可以对网站模拟3w左右的并发请求,可以控制时间、是否使用缓存、是否等待服务器回复等等,且对中小型网站有明显的效果,基本上可以测出中小型网站的承受能力,对于大型的网站,如百度、淘宝这些巨型网站没有意义,因为其承受能力非常大。同时测试结果也受自身网速、以及自身主机的性能与内存的限制,性能好、内存大的主机可以模拟的并发就明显要多。
Webbench用C语言编写,运行于linux平台,下载源码后直接编译即可使用,非常迅速快捷,对于中小型网站的制作者,在上线前用webbench进行系列并发测试不失为一个好的测试方法。
使用方法也是非常的简单,例如对百度进行测试
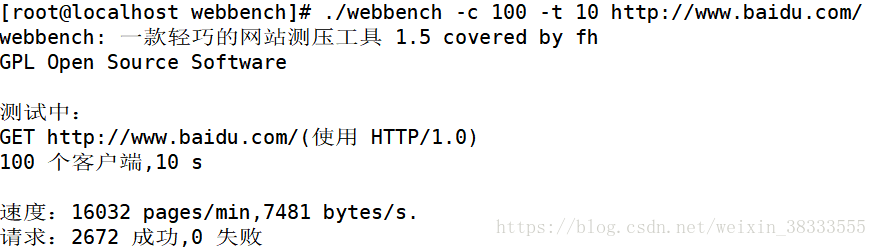
Webbench实现的核心原理是:父进程fork若干个子进程,每个子进程在用户要求时间或默认的时间内对目标web循环发出实际访问请求,父子进程通过管道进行通信,子进程通过管道写端向父进程传递在若干次请求访问完毕后记录到的总信息,父进程通过管道读端读取子进程发来的相关信息,子进程在时间到后结束,父进程在所有子进程退出后统计并给用户显示最后的测试结果,然后退出。
下面我从我实现的思路来详细说一下每个过程,非常显然的地方就略过了,有不明白的地方提问后会尽快回复。
源代码主要有三个源文件:Socket.c\Socket.h\webbench.c
其中Sokcet.c与Socket.h封装了对于目标网站的TCP套接字的构造,其中Socket函数用于获取连接目标网站TCP套接字,这一部分后面就不做说明了,重点讲解webbench.c,其中有些对于各种错误的处理就不在此加以说明了,详见末尾的源码。
详细实现过程
主函数的思路如下
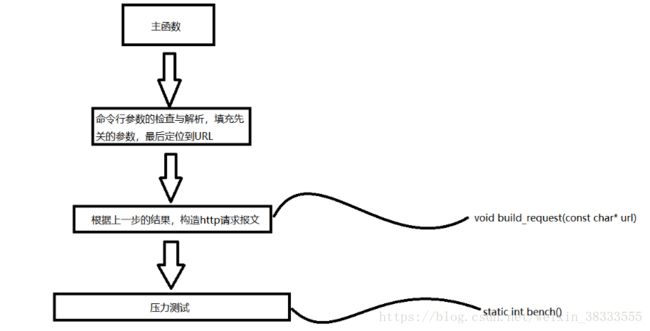
命令行参数解析
命令行参数解析当然是linux下的经典做法,通过getopt_long库函数,该函数非常强大,若是没有这个函数,多命令行参数解析会显得很麻烦,很复杂,但有了这个函数就非常简单了,若你不了解这个函数的使用方法,那么点击这篇博客或者自己查阅相关博客进行学习,不然你肯定是看不懂代码的,在此就不做多余的讲解了。在解析命令行参数的过程中,会对每个不同的参数做出一些相应的操作,若解析到有问题的参数会结束并打印帮助手册。命令行参数解析完毕后,就进入请求报文构造函数。
构造http请求报文
该模块由build_request函数实现,该函数流程如下
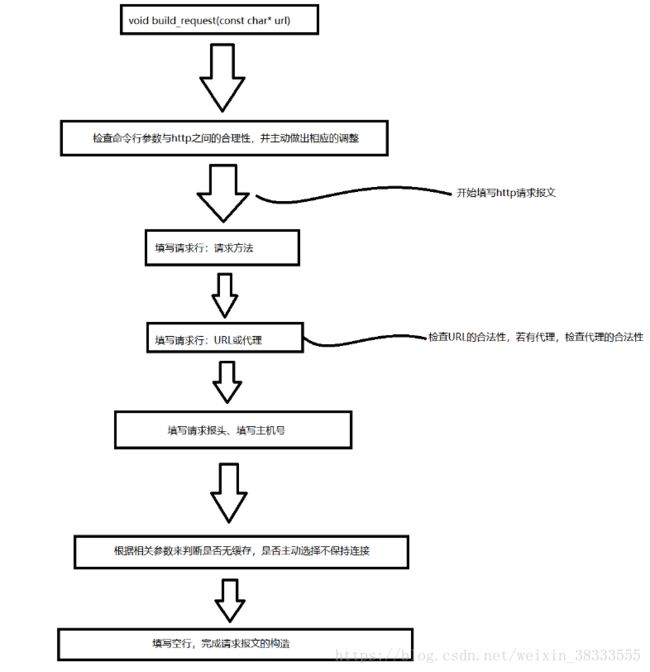
这个模块需要进行大量的错误分析,分析用户有可能出现的错误填写,并及时终止,如果在这一步不做好这件事,后面会出现几乎找不出的错误。然后就是在填写报文时,一定要严格的注意格式,不要随意少空格、回车换行,保证报文填写的正确。
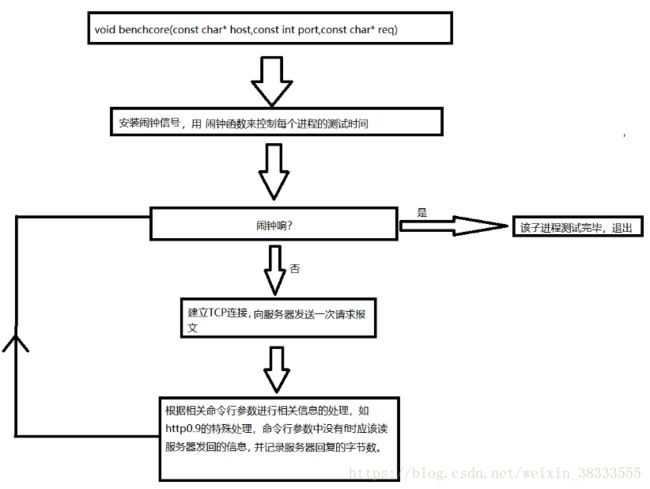
压力测试
这一模块由bench函数来完成

这一过程中关键是恰当的利用管道在父子进程间通信,其中函数benchcore函数时每个子进程在要求时间内发送请求报文的函数,该函数会记录请求的成功次数、失败次数、以及服务器回复的字节数。
过程分析得再清楚,不如代码清楚来得好(Socket.c与Socket.h不用做说明,就不放了,在末尾的github上)
#include"Socket.h"
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
static void usage(void)
{
fprintf(stderr,
"webbench [选项参数]... URL\n"
" -f|--force 不等待服务器响应\n"
" -r|--reload 重新请求加载(无缓存)\n"
" -t|--time 运行时间,单位:秒,默认为30秒\n"
" -p|--proxy 使用代理服务器发送请求\n"
" -c|--clients 创建多少个客户端,默认为1个\n"
" -9|--http09 使用http0.9协议来构造请求\n"
" -1|--http10 使用http1.0协议来构造请求\n"
" -2|--http11 使用http1.1协议来构造请求\n"
" --get 使用GET请求方法\n"
" --head 使用HEAD请求方法\n"
" --options 使用OPTIONS请求方法\n"
" --trace 使用TRACE请求方法\n"
" -?|-h|--help 显示帮助信息\n"
" -V|--version 显示版本信息\n" );
};
//http请求方法
#define METHOD_GET 0
#define METHOD_HEAD 1
#define METHOD_OPTIONS 2
#define METHOD_TRACE 3
//相关参数选项的默认值
int method = METHOD_GET;
int clients = 1;
int force = 0; //默认需要等待服务器相应
int force_reload = 0; //默认不重新发送请求
int proxyport = 80; //默认访问80端口,http国际惯例
char* proxyhost = NULL; //默认无代理服务器,因此初值为空
int benchtime = 30; //默认模拟请求时间
//所用协议版本
int http = 1; //0:http0.9 1:http1.0 2:http1.1
//用于父子进程通信的管道
int mypipe[2];
//存放目标服务器的网络地址
char host[MAXHOSTNAMELEN];
//存放请求报文的字节流
#define REQUEST_SIZE 2048
char request[REQUEST_SIZE];
//构造长选项与短选项的对应
static const struct option long_options[]=
{
{"force",no_argument,&force,1},
{"reload",no_argument,&force_reload,1},
{"time",required_argument,NULL,'t'},
{"help",no_argument,NULL,'?'},
{"http09",no_argument,NULL,9},
{"http10",no_argument,NULL,1},
{"http11",no_argument,NULL,2},
{"get",no_argument,&method,METHOD_GET},
{"head",no_argument,&method,METHOD_HEAD},
{"options",no_argument,&method,METHOD_OPTIONS},
{"trace",no_argument,&method,METHOD_TRACE},
{"version",no_argument,NULL,'V'},
{"proxy",required_argument,NULL,'p'},
{"clients",required_argument,NULL,'c'},
{NULL,0,NULL,0}
};
int speed = 0;
int failed = 0;
long long bytes = 0;
int timeout = 0;
void build_request(const char* url);
static int bench();
static void alarm_handler(int signal);
void benchcore(const char* host,const int port,const char* req);
int main(int argc,char* argv[])
{
int opt = 0;
int options_index = 0;
char* tmp = NULL;
//首先进行命令行参数的处理
//1.没有输入选项
if(argc == 1)
{
usage();
return 1;
}
//2.有输入选项则一个一个解析
while((opt = getopt_long(argc,argv,"frt:p:c:?V912",long_options,&options_index)) != EOF)
{
switch(opt)
{
case 'f':
force = 1;
break;
case 'r':
force_reload = 1;
break;
case '9':
http = 0;
break;
case '1':
http = 1;
break;
case '2':
http = 2;
break;
case 'V':
printf("WebBench 1.5 covered by fh\n");
exit(0);
case 't':
benchtime = atoi(optarg); //optarg指向选项后的参数
break;
case 'c':
clients = atoi(optarg); //与上同
break;
case 'p': //使用代理服务器,则设置其代理网络号和端口号,格式:-p server:port
tmp = strrchr(optarg,':'); //查找':'在optarg中最后出现的位置
proxyhost = optarg; //
if(tmp == NULL) //说明没有端口号
{
break;
}
if(tmp == optarg) //端口号在optarg最开头,说明缺失主机名
{
fprintf(stderr,"选项参数错误,代理服务器 %s:缺失主机名",optarg);
return 2;
}
if(tmp == optarg + strlen(optarg)-1) //':'在optarg末位,说明缺少端口号
{
fprintf(stderr,"选项参数错我,代理服务器 %s 缺少端口号",optarg);
return 2;
}
*tmp = '\0'; //将optarg从':'开始截断
proxyport = atoi(tmp+1); //把代理服务器端口号设置好
break;
case '?':
usage();
exit(0);
break;
default:
usage();
return 2;
break;
}
}
//选项参数解析完毕后,刚好是读到URL,此时argv[optind]指向URL
if(optind == argc) //这样说明没有输入URL,不明白的话自己写一条命令行看看
{
fprintf(stderr,"缺少URL参数\n");
usage();
return 2;
}
if(benchtime == 0)
benchtime = 30;
fprintf(stderr,"webbench: 一款轻巧的网站测压工具 1.5 covered by fh\nGPL Open Source Software\n");
//OK,我们解析完命令行后,首先先构造http请求报文
build_request(argv[optind]); //参数当然是URL
//请求报文构造好了
//开始测压
printf("\n测试中:\n");
switch(method)
{
case METHOD_OPTIONS:
printf("OPTIONS");
break;
case METHOD_HEAD:
printf("HEAD");
break;
case METHOD_TRACE:
printf("TRACE");
break;
case METHOD_GET:
default:
printf("GET");
break;
}
printf(" %s",argv[optind]);
switch(http)
{
case 0:
printf("(使用 HTTP/0.9)");
break;
case 1:
printf("(使用 HTTP/1.0)");
break;
case 2:
printf("(使用 HTTP/1.1)");
break;
}
printf("\n");
printf("%d 个客户端",clients);
printf(",%d s",benchtime);
if(force)
printf(",选择提前关闭连接");
if(proxyhost != NULL)
printf(",经由代理服务器 %s:%d ",proxyhost,proxyport);
if(force_reload)
printf(",选择无缓存");
printf("\n"); //换行不能少!库函数是默认行缓冲,子进程会复制整个缓冲区,
//若不换行刷新缓冲区,子进程会把缓冲区的的也打出来!
//而换行后缓冲区就刷新了,子进程的标准库函数的那块缓冲区就不会有前面的这些了
//真正开始压力测试
return bench();
}
void build_request(const char* url)
{
char tmp[10];
int i = 0;
bzero(host,MAXHOSTNAMELEN);
bzero(request,REQUEST_SIZE);
//缓存和代理都是http1.0后才有的
//无缓存和代理都要在http1.0以上才能使用
//因此这里要处理一下,不然可能会出问题
if(force_reload && proxyhost != NULL && http < 1)
http = 1;
//HEAD请求是http1.0后才有
if(method == METHOD_HEAD && http < 1)
http = 1;
//OPTIONS和TRACE都是http1.1才有
if(method == METHOD_OPTIONS && http < 2)
http = 2;
if(method == METHOD_TRACE && http < 2)
http = 2;
//开始填写http请求
//请求行
//填写请求方法
switch(method)
{
case METHOD_HEAD:
strcpy(request,"HEAD");
break;
case METHOD_OPTIONS:
strcpy(request,"OPTIONS");
break;
case METHOD_TRACE:
strcpy(request,"TRACE");
break;
default:
case METHOD_GET:
strcpy(request,"GET");
}
strcat(request," ");
//判断URL的合法性
//1.URL中没有"://"
if(strstr(url,"://") == NULL)
{
fprintf(stderr,"\n%s:是一个不合法的URL\n",url);
exit(2);
}
//2.URL过长
if(strlen(url) > 1500)
{
fprintf(stderr,"URL 长度过过长\n");
exit(2);
}
//3.没有代理服务器却填写错误
if(proxyhost == NULL) //若无代理
{
if(strncasecmp("http://",url,7) != 0) //忽略大小写比较前7位
{
fprintf(stderr,"\nurl无法解析,是否需要但没有选择使用代理服务器的选项?\n");
usage();
exit(2);
}
}
//定位url中主机名开始的位置
//比如 http://www.xxx.com/
i = strstr(url,"://") - url + 3;
//4.在主机名开始的位置找是否有'/',若没有则非法
if(strchr(url + i,'/') == NULL)
{
fprintf(stderr,"\nURL非法:主机名没有以'/'结尾\n");
exit(2);
}
//判断完URL合法性后继续填写URL到请求行
//无代理时
if(proxyhost == NULL)
{
//有端口号时,填写端口号
if(index(url+i,':') != NULL && index(url,':') < index(url,'/'))
{
//设置域名或IP
strncpy(host,url+i,strchr(url+i,':') - url - i);
bzero(tmp,10);
strncpy(tmp,index(url+i,':')+1,strchr(url+i,'/') - index(url+i,':')-1);
//设置端口号
proxyport = atoi(tmp);
//避免写了':'却没写端口号
if(proxyport == 0)
proxyport = 80;
}
else //无端口号
{
strncpy(host,url+i,strcspn(url+i,"/")); //找到url+i到第一个”/"之间的字符个数
}
}
else //有代理服务器就简单了,直接填就行,不用自己处理
{
strcat(request,url);
}
//填写http协议版本到请求行
if(http == 1)
strcat(request," HTTP/1.0");
if(http == 2)
strcat(request," HTTP/1.1");
strcat(request,"\r\n");
//请求报头
if(http > 0)
strcat(request,"User-Agent:WebBench 1.5\r\n");
//填写域名或IP
if(proxyhost == NULL && http > 0)
{
strcat(request,"Host: ");
strcat(request,host);
strcat(request,"\r\n");
}
//若选择强制重新加载,则填写无缓存
if(force_reload && proxyhost != NULL)
{
strcat(request,"Pragma: no-cache\r\n");
}
//我们目的是构造请求给网站,不需要传输任何内容,当然不必用长连接
//否则太多的连接维护会造成太大的消耗,大大降低可构造的请求数与客户端数
//http1.1后是默认keep-alive的
if(http > 1)
strcat(request,"Connection: close\r\n");
//填入空行后就构造完成了
if(http > 0)
strcat(request,"\r\n");
}
//父进程的作用:创建子进程,读子进程测试到的数据,然后处理
static int bench()
{
int i = 0,j = 0;
long long k = 0;
pid_t pid = 0;
FILE* f = NULL;
//尝试建立连接一次
i = Socket(proxyhost == NULL?host:proxyhost,proxyport);
if(i < 0)
{
fprintf(stderr,"\n连接服务器失败,中断测试\n");
return 3;
}
close(i);//尝试连接成功了,关闭该连接
//建立父子进程通信的管道
if(pipe(mypipe))
{
perror("通信管道建立失败");
return 3;
}
//让子进程去测试,建立多少个子进程进行连接由参数clients决定
for(i = 0;i < clients;i++)
{
pid = fork();
if(pid <= 0)
{
sleep(1);
break; //失败或者子进程都结束循环,否则该子进程可能继续fork了,显然不可以
}
}
//处理fork失败的情况
if(pid < 0)
{
fprintf(stderr,"第 %d 子进程创建失败",i);
perror("创建子进程失败");
return 3;
}
//子进程执行流
if(pid == 0)
{
//由子进程来发出请求报文
benchcore(proxyhost == NULL?host : proxyhost,proxyport,request);
//子进程获得管道写端的文件指针
f = fdopen(mypipe[1],"w");
if(f == NULL)
{
perror("管道写端打开失败");
return 3;
}
//向管道中写入该子进程在一定时间内请求成功的次数
//失败的次数
//读取到的服务器回复的总字节数
fprintf(f,"%d %d %lld\n",speed,failed,bytes);
fclose(f); //关闭写端
return 0;
}
else
{
//子进程获得管道读端的文件指针
f = fdopen(mypipe[0],"r");
if(f == NULL)
{
perror("管道读端打开失败");
return 3;
}
//fopen标准IO函数是自带缓冲区的,
//我们的输入数据非常短,并且要求数据要及时,
//因此没有缓冲是最合适的
//我们不需要缓冲区
//因此把缓冲类型设置为_IONBF
setvbuf(f,NULL,_IONBF,0);
speed = 0; //连接成功的总次数,后面除以时间可以得到速度
failed = 0; //失败的请求数
bytes = 0; //服务器回复的总字节数
//唯一的父进程不停的读
while(1)
{
pid = fscanf(f,"%d %d %lld",&i,&j,&k);//得到成功读入的参数个数
if(pid < 3)
{
fprintf(stderr,"某个子进程死亡\n");
break;
}
speed += i;
failed += j;
bytes += k;
//我们创建了clients,正常情况下要读clients次
if(--clients == 0)
break;
}
fclose(f);
//统计处理结果
printf("\n速度:%d pages/min,%d bytes/s.\n请求:%d 成功,%d 失败\n",\
(int)((speed+failed)/(benchtime/60.0f)),\
(int)(bytes/(float)benchtime),\
speed,failed);
}
return i;
}
//闹钟信号处理函数
static void alarm_handler(int signal)
{
timeout = 1;
}
//子进程真正的向服务器发出请求报文并以其得到此期间的相关数据
void benchcore(const char* host,const int port,const char* req)
{
int rlen;
char buf[1500];
int s,i;
struct sigaction sa;
//安装闹钟信号的处理函数
sa.sa_handler = alarm_handler;
sa.sa_flags = 0;
if(sigaction(SIGALRM,&sa,NULL))
exit(3);
//设置闹钟函数
alarm(benchtime);
rlen = strlen(req);
nexttry:
while(1)
{
//只有在收到闹钟信号后会使 time = 1
//即该子进程的工作结束了
if(timeout)
{
if(failed > 0)
{
failed--;
}
return;
}
//建立到目标网站服务器的tcp连接,发送http请求
s = Socket(host,port);
if(s < 0)
{
failed++; //连接失败
continue;
}
//发送请求报文
if(rlen != write(s,req,rlen))
{
failed++;
close(s); //写失败了也不能忘了关闭套接字
continue;
}
//http0.9的特殊处理
//因为http0.9是在服务器回复后自动断开连接的,不keep-alive
//在此可以提前先彻底关闭套接字的写的一半,如果失败了那么肯定是个不正常的状态,
//如果关闭成功则继续往后,因为可能还有需要接收服务器的恢复内容
//但是写这一半是一定可以关闭了,作为客户端进程上不需要再写了
//因此我们主动破坏套接字的写端,但是这不是关闭套接字,关闭还是得close
//事实上,关闭写端后,服务器没写完的数据也不会再写了,这个就不考虑了
if(http == 0)
{
if(shutdown(s,1))
{
failed++;
close(s);
continue;
}
}
//-f没有设置时默认等待服务器的回复
if(force == 0)
{
while(1)
{
if(timeout)
break;
i = read(s,buf,1500); //读服务器发回的数据到buf中
if(i < 0)
{
failed++; //读失败
close(s); //失败后一定要关闭套接字,不然失败个数多时会严重浪费资源
goto nexttry; //这次失败了那么继续下一次连接,与发出请求
}
else
{
if(i == 0) //读完了
break;
else
bytes += i; //统计服务器回复的字节数
}
}
}
if(close(s))
{
failed++;
continue;
}
speed++;
}
}
源码
git clone https://github.com/l-f-h/webbench-1.5.git
make&&make clean
最后想说一说关于webbench,20年前左右一位大佬写了最初的开源版本,后来不断有人去更新,1.5版本是多进程版本,受益于多进程,其优点是比较稳定,各进程毕竟不会互相影响,父子进程间通信时基本不会出Bug,也不需要加任何锁,但是缺点个人感觉也是比较明显的。
首先,从代码的角度来讲,我自己研究了大半天才把整个理清楚,因为最初的版本用了太多的全局变量,实在是对于阅读源码的人不友好,但是在实现的时候就还好了,毕竟需要什么就在全局加什么,反而思路清楚。(似乎这个问题也不好避免)
其次,再者就是多线程来做肯定性能要好得多,毕竟进程的开销实在是不小,开2g内存跑的话差不多3000个进程就不行了,但是现在都动不动就8g起,似乎也不太在意这个问题,但是线程无论如何都会好很多的。
最后就是一个细节问题,在统计服务器回复的字节数时个人认为应该检测其是否回复了正确信息(2xx)
过一段时间搞一个多线程版本,顺便解决一下一些问题。
前段时间测自己的web服务器发现我漏了对于http1.1没有填充好报文,当时自己没有测到,希望各位看到这篇博客的人能够注意下这一点!