Hadoop 详细配置文档
准备配置:
1、用sudo gedit /etc/hostname ,在打开的文件里更改主机名
2、为了虚拟机之间能够ping通,需要修改主机名
sudo gedit /etc/hosts 命令,把对应的主机名进行更改,同时更改前面对应的ip地址
3、关闭防火墙:用sudo ufw version 来查看是否有防火墙
开启/关闭防火墙:sudo ufw enable/disable
SSH配置
1、终端输入ssh localhost 来测试是否有sshserver
如果出现request confuse,则使用sudo apt-get install openssh-server语句,安装服务,一路回车
教程网站https://www.linuxidc.com/Linux/2015-01/112045.htm
2、对新用户user配置ssh公匙认证。
mkdir ~/.ssh 创建隐藏ssh文件夹
cd ~/.ssh 转到ssh文件夹
ssh-keygen -t rsa 生成密匙(不加sudo)
3、
如果权限不够,无法生成rsa文件,则是.ssh文件夹权限不够
更改.ssh文件夹权限:chmod 777 ~/.ssh
注:
如果无法更改可能是文件夹所属权限问题,在root用户下输入:chown + -R + 所属者 文件路径 。可以把文件夹的权限更改到指定所有者,-R递归下面的每一个文件(夹)
4、scp ~/.ssh/id_rsa.pub [email protected]:~/.ssh/ras.pub
将host1上.ssh下的所有文件复制到主机host2上
然后在host2上追加:cat rsa.pub >> .ssh/authorized_keys
5、用ssh [email protected] 命令测试是否成功(如果主机名一致可以不加h1@,如果不一致必须要加h1@)
6、用ls -al 语句显示.ssh文件夹下的主要内容有4个:
授权钥匙:authorized_keys(不一定有)
私有钥匙:id_rsa
公用钥匙:id_rsa.pub
登录日志:known_hosts
JDK安装配置:
- 下载jdk压缩包(.tar),(需要较低版本的,11.0的版本不能用)
- 打开profile文件(sudo gedit /etc/profile)配置环境变量
(Ubuntu系统还要配置.bashrc文件:sudo gedit ~/.bashrc)
export JAVA_HOME=/usr/java/jdk1.8.0_191
export JRE_HOME=${JAVA_HOME}/jre
export PATH=$PATH:${JAVA_HOME}/bin
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib- 用 source /etc/profile 命令刷新profile文件(每次打开profile文件后都要source)
Ubuntu系统还要配置~/.bashrc文件
Source ~/.bashrc 更新
用 echo $PATH (或 Java -version)查看是否配置成功
HADOOP配置
1、下载Hadoop压缩包(.tar),解压到/home/h1/目录下,重命名为hadoop
2、在hadoop目录新建名为hdfs的文件夹
文件结构:/home/h1/hadoop/hdfs/
在hdfs文件夹下新建tmp文件夹
文件结构:/home/h1/hadoop/hdfs/tmp/
在hdfs文件夹下新建name文件夹
文件结构:/home/h1/hadoop/hdfs/name/
在hdfs文件夹下新建data文件夹
文件结构:/home/h1/hadoop/hdfs/data/
3、配置hadoop的配置文件:
先进入/home/h1/hadoop/etc/hadoop/文件夹下:
(实际操作中,用主机的ip地址代替master,用从机ip地址代替slave)
~1、配置core-site.xml文件(用sudo gedit core-site.xml 命令打开)
在
hadoop.tmp.dir
file:/home/h1/hadoop/hdfs/tmp
A base for other temporary directories.
io.file.buffer.size
131072
fs.defaultFS
hdfs://master:9000
注意:第一个属性中的value和我们之前创建的/hadoop/hdfs/tmp路径要一 致
~2、配置hadoop-env.sh文件(用sudo gedit hadoop-env.sh命令打开)
将JAVA_HOME文件配置作为本机JAVA_HOME路径

~3、配置yarn-env.sh文件(用sudo gedit yarn-env.sh 命令打开)
将其中的JAVA_HOME修改为本机的JAVA_HOME路径(先把这一行#去掉)

~4、配置hdfs-site.xml文件(用sudo gedit hdfs-site.xml 命令打开)
在
dfs.replication
1
dfs.namenode.name.dir
file:/home/h1/hadoop/hdfs/name
true
dfs.datanode.data.dir
file:/home/h1/hadoop/hdfs/data
true
dfs.namenode.secondary.http-address
master:9001
dfs.webhdfs.enabled
true
dfs.permissions
false
注意(其中第二个dfs.namenode.name.dir和dfs.datanode.data.dir的value和之前创建的/hdfs/name和/hdfs/data路径一致;因为这里只有一个从主机slave1,所以dfs.replication设置为1)
另外在这个文件中追加以下代码,可以设置分块大小:
dfs.blocksize
31457280
dfs.namenode.fs-limits.min-block-size
31457280
Value值为分块的大小,31457280为30MB(以字节为单位。)
~5、复制mapred-site.xml.template文件,并命名为mapred-site.xml
(用sudo gedit mapred-site.xml 命令打开)
配置 mapred-site.xml,在标签
mapreduce.framework.name
yarn
~6、配置yarn-site.xml文件(用sudo gedit yarn-site.xml 命令打开)
在
yarn.resourcemanager.address
master:18040
yarn.resourcemanager.scheduler.address
master:18030
yarn.resourcemanager.webapp.address
master:18088
yarn.resourcemanager.resource-tracker.address
master:18025
yarn.resourcemanager.admin.address
master:18141
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.auxservices.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
~7、配置slaves文件(用sudo gedit slaves命令打开)
把原本的localhost删掉,改成从机的主机名
4、配置hadoop的环境变量打开profile文件(sudo gedit /etc/profile)
(Ubuntu还有.bashrc)
在后面添加:
HADOOP_HOME=/home/h1/hadoop
CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath):$CLASSPATH
HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin然后用 source /etc/profile 命令刷新profile文件
用scp命令将hadoop文件夹拷贝到从机上,传过去后在从机上面对hadoop进行环境变量配置,如4步。
5、初始化hadoop:hdfs namenode -format
6、开启hadoop:start-all.sh
在master上键入jps看到4个文件表明成功
在h1上键入jps看到3个文件表明成功
7、测试hadoop:
hadoop jar /home/h1/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar pi 10 10
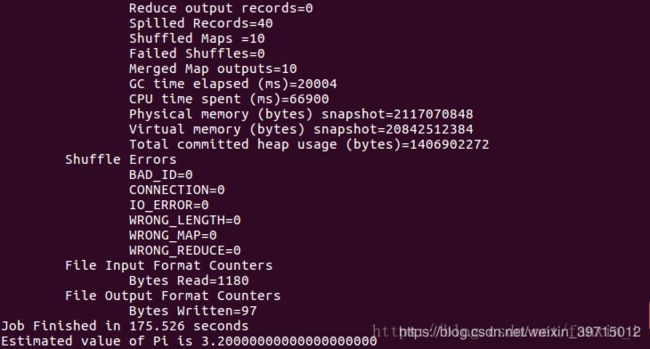
出现上面图片表明成功。
测试:
wordcount测试
1.在当前用户目录下建立hadoop_data文件夹
2.建立file1.txt file2.txt文件,内容自定即可
3.在hadoop根目录下建立文件夹
hdfs dfs -mkdir /intput
查看hadoop根目录
hdfs dfs -ls /
4.将本地文件上传到hadoop目录下
hdfs dfs -put /home/h1/hadoop_data/*.txt /input/
5.执行测试程序
hadoop jar /home/h1/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.1.jar wordcount /input /output
6.查看结果
hadoop fs -cat /output/part-r-00000
补充:
1、初始化成功后,启动失败
初始化次数过多,namenode和hdfs文件夹内容不匹配
解决:删除Hadoop 下的logs文件夹里面的所有内容
删除hdfs文件夹下的三个文件夹,在重新创建三个文件夹
在重新初始化,在启动。
2、jps找不到
配置~/.bashrc 和profile文件
3、初始化过多会进入安全模式:
退出安全模式:hadoop dfsadmin -safemode leave