自然语言处理之-----Word2Vec
A Beginner’s Guide to Word2Vec and Neural Word Embeddings
- Introduction to Word2Vec
Word2vec是一个处理文本的双层神经网络。它的输入是一个文本语料库,它的输出是一组向量:该语料库中单词的特征向量。虽然Word2vec不是深度神经网络,但它将文本转换为深网可以理解的数字形式。 Deeplearning4j实现了一个分布式的Word2vec for Java和Scala,它可以在Spark上运行GPU。
Word2vec的应用程序不仅仅是解析野外的句子。它也可以应用于基因,代码,喜欢,播放列表,社交媒体图和其他可以辨别模式的语言或符号系列。
为什么?因为单词就像上面提到的其他数据一样只是离散状态,我们只是在寻找这些状态之间的过渡概率:它们共同发生的可能性。所以gene2vec,like2vec和follower2vec都是可能的。考虑到这一点,下面的教程将帮助您了解如何为任何离散和共现状态组创建神经嵌入。
Word2Vec的目的和用处是将相似单词的向量组合在向量空间中。也就是说,它以数学方式检测相似性。 Word2Vec创建的向量是单词特征的分布式数字表示,诸如单个单词的上下文之类的特征。它没有人为干预就这样做了。
有了足够的数据,用法和上下文,Word2Vec可以根据过去的外观对单词的含义进行高度准确的猜测。这些猜测可用于建立单词与其他单词的关联(例如“男人”是“男孩”,“女人”是“女孩”),或集群文档并按主题对其进行分类。这些集群可以构成搜索,情感分析和科学研究,法律发现,电子商务和客户关系管理等多个领域的建议的基础。
Word2Vec神经网络的输出是一个词汇表,其中每个项目都附有一个向量,可以将其输入深度学习网络或简单地查询以检测单词之间的关系。
测量余弦相似度,没有相似性表示为90度角,而1的总相似度是0度角,完全重叠;瑞典等于瑞典,而挪威与瑞典的余弦距离为0.760124,是其他任何国家中最高的。
以下是使用Word2vec与“瑞典”相关联的单词列表,按照接近顺序排列:

斯堪的纳维亚国家和几个富裕,北欧,日耳曼国家都位列前九。
- Neural Word Embeddings
我们用来表示单词的向量称为神经词嵌入,表示很奇怪。有一件事描述了另一件事,即使这两件事完全不同。正如埃尔维斯科斯特洛所说:“写关于音乐就像跳舞建筑一样。”Word2vec对文字进行“矢量化”,通过这样做,它使自然语言成为可读的 - 我们可以开始对文字执行强大的数学运算来检测它们的相似之处。
因此,神经词嵌入表示带有数字的单词。这是一个简单但不太可能的翻译。
Word2vec类似于自动编码器,对矢量中的每个单词进行编码,但不是通过重建训练输入单词,而是像限制Boltzmann机器那样,word2vec训练单词与输入语料库中与其相邻的其他单词。
它以两种方式之一来实现,或者使用上下文来预测目标词(一种称为连续词语或CBOW的方法),或者使用一个词来预测目标上下文,这被称为skip-gram。我们使用后一种方法,因为它可以在大型数据集上生成更准确的结果。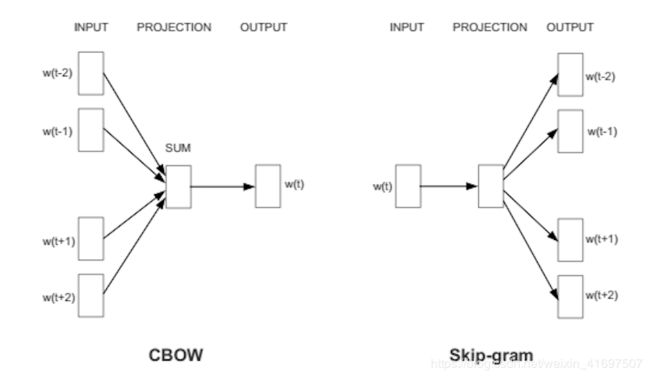
当分配给单词的特征向量不能用于准确预测该单词的上下文时,将调整向量的分量。语料库中的每个单词的上下文是教师发送错误信号以调整特征向量。通过调整矢量中的数字,将通过其上下文判断为相似的单词的矢量更靠近在一起。
就像梵高的向日葵画是一幅二维的油画混合物,在19世纪80年代后期在巴黎的一个三维空间中代表植物物质,因此在矢量中排列的500个数字可以代表一个单词或一组单词。
这些数字将每个单词定位为500维向量空间中的一个点。超过三维的空间难以想象。 (Geoff Hinton教导人们想象13维空间,建议学生首先描绘三维空间,然后对自己说:“十三,十三,十三。”?
一组训练有素的单词向量将在该空间中将相似的单词放在彼此靠近的位置。橡树,榆树和桦树这两个词可能聚集在一个角落里,而战争,冲突和纷争则挤在另一个角落里。
类似的事物和想法被证明是“接近”的。它们的相对意义已被转化为可测量的距离。质量成为数量,算法可以完成他们的工作。但相似性只是Word2vec可以学习的许多关联的基础。例如,它可以衡量一种语言的单词之间的关系,并将它们映射到另一种语言。

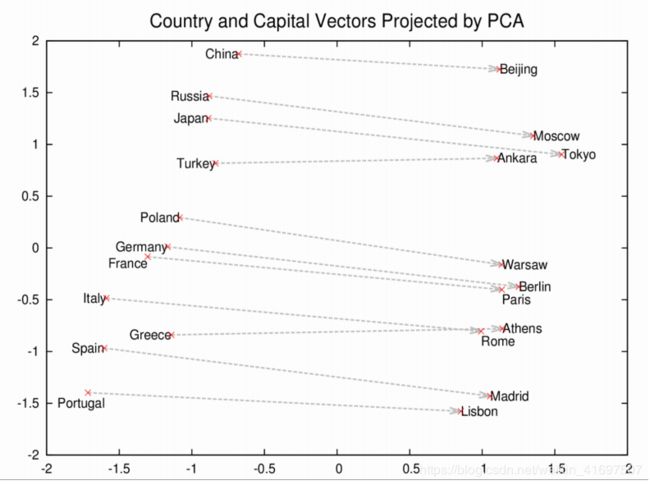
这些向量是更全面的单词几何的基础。 罗马,巴黎,柏林和北京不仅彼此靠近,而且它们在向量空间中的距离与它们的首都相似; 即罗马 - 意大利=北京 - 中国。 如果你只知道罗马是意大利的首都,并且想知道中国的首都,那么罗马 - 意大利+中国将会回归北京。
- Amusing Word2Vec Results
Let’s look at some other associations Word2vec can produce.
Instead of the pluses, minus and equals signs, we’ll give you the results in the notation of logical analogies, where : means “is to” and :: means “as”; e.g. “Rome is to Italy as Beijing is to China” = Rome:Italy::Beijing:China. In the last spot, rather than supplying the “answer”, we’ll give you the list of words that a Word2vec model proposes, when given the first three elements:
king:queen:?[woman, Attempted abduction, teenager, girl]
//Weird, but you can kind of see it
China:Taiwan::Russia:[Ukraine, Moscow, Moldova, Armenia]
//Two large countries and their small, estranged neighbors
house:roof::castle:[dome, bell_tower, spire, crenellations, turrets]
knee:leg::elbow:[forearm, arm, ulna_bone]
New York Times:Sulzberger::Fox:[Murdoch, Chernin, Bancroft, Ailes]
//The Sulzberger-Ochs family owns and runs the NYT.
//The Murdoch family owns News Corp., which owns Fox News.
//Peter Chernin was News Corp.'s COO for 13 yrs.
//Roger Ailes is president of Fox News.
//The Bancroft family sold the Wall St. Journal to News Corp.
love:indifference::fear:[apathy, callousness, timidity, helplessness, inaction]
//the poetry of this single array is simply amazing…
Donald Trump:Republican::Barack Obama:[Democratic, GOP, Democrats, McCain]
//It’s interesting to note that, just as Obama and McCain were rivals,
//so too, Word2vec thinks Trump has a rivalry with the idea Republican.
monkey:human::dinosaur:[fossil, fossilized, Ice_Age_mammals, fossilization]
//Humans are fossilized monkeys? Humans are what’s left
//over from monkeys? Humans are the species that beat monkeys
//just as Ice Age mammals beat dinosaurs? Plausible.
building:architect::software:[programmer, SecurityCenter, WinPcap]
This model was trained on the Google News vocab, which you can import and play with. Contemplate, for a moment, that the Word2vec algorithm has never been taught a single rule of English syntax. It knows nothing about the world, and is unassociated with any rules-based symbolic logic or knowledge graph. And yet it learns more, in a flexible and automated fashion, than most knowledge graphs will learn after many years of human labor. It comes to the Google News documents as a blank slate, and by the end of training, it can compute complex analogies that mean something to humans.
You can also query a Word2vec model for other assocations. Not everything has to be two analogies that mirror each other.
Geopolitics: Iraq - Violence = Jordan
Distinction: Human - Animal = Ethics
President - Power = Prime Minister
Library - Books = Hall
Analogy: Stock Market ≈ Thermometer
By building a sense of one word’s proximity to other similar words, which do not necessarily contain the same letters, we have moved beyond hard tokens to a smoother and more general sense of meaning.
- N-grams & Skip-grams
单词一次一个地读入矢量,并在一定范围内来回扫描。 这些范围是n-gram,n-gram是来自给定语言序列的n个项的连续序列; 它是unigram,bigram,trigram,four-gram或5-gram的第n个版本。 skip-gram只是从n-gram中删除项目。
由Mikolov推广并在DL4J实现中使用的跳过 - 克表示已被证明比其他模型更准确,例如连续的单词,由于生成的更通用的上下文。
然后将该n-gram输入神经网络以学习给定单词向量的重要性; 即重要性被定义为其作为某些较大含义或标签的指标的有用性。
- Advances in NLP: ElMO, BERT and GPT-2
单词向量构成了自然语言处理的最新进展的基础,包括ElMO,ULMFit和BERT等语言模型。但那些语言模型改变了他们表达单词的方式;也就是说,矢量代表的变化。
Word2vec是一种用于生成单词分布式表示的算法,我们指的是单词类型;即,词汇表中的任何给定单词,例如get或grab或go具有其自己的单词向量,并且这些向量有效地存储在查找表或词典中。不幸的是,这种单词表示方法并不是多义词,也不是给定单词或短语的许多可能含义的共存。例如,go是一个动词,它也是一个棋盘游戏; get是一个动词,它也是一个动物的后代。给定单词类型的含义,例如go或get,根据其上下文而有所不同;即围绕它的词。
ElMO和BERT证明的一点是,通过对给定单词的上下文进行编码,通过在向量中包含表示单词的给定实例的前后单词的信息,我们可以在自然语言处理任务中获得更好的结果。 BERT的表现归功于注意机制。
在测量常识推理的SWAG基准测试中,ELMo被发现产生与非上下文单词向量相关的5%误差减少,而BERT在ELMo之后显示出额外66%的误差减少。 最近,OpenAI与GPT-2的合作在响应提示时产生了令人惊讶的良好结果。