python爬取CRMEB3.2 后台订单数据并导出excel
最近在学习爬虫的时候,正好用一个开源的CRMEB小程序商城框架搭建了一个,发现后台导出订单功能不好用,也没办法更好的控制想获取什么信息就获取什么信息,于是自己尝试写了一个简单的爬虫爬取需要的信息。
运行环境
Python3.8、 requests、openpyxl
安装依赖包:
pip3 install requests, openpyxl寻找订单接口地址:
登录进入后台获取数据接口及Cookie,由于我这里用的是我自己搭建的后台,账号密码我自己都知道,我们登陆之后,直接用Cookie进行登录。
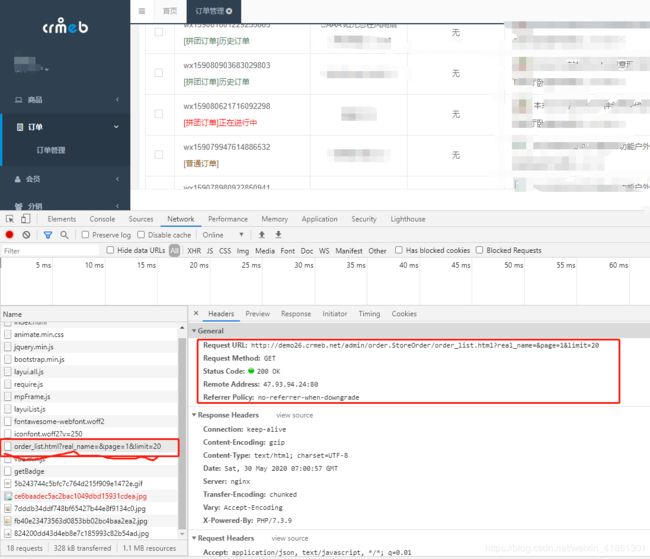
我们获取到的订单管理的接口地址是:你的域名/admin/order.store_order/order_list.html?page=1&limit=20
URL总共有两个参数,page为页码,limit为每一页显示的数量,一会爬取的时候修改这里的值就可以了。
创建一个load.py文件
import json
import requests
filename = 'order_list.json'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36',
'Referer': 'http://shop.crmeb.net/admin/order.store_order/index.html',
'Cookie': '复制替换为你的Cookie信息'
}
text_json = requests.get(
# 爬取270条数据
'http://shop.crmeb.net/admin/order.store_order/order_list.html?page=1&limit=270',
headers=headers
).content.decode('utf-8')
# 爬取之后存入order_list.json文件
with open(filename, 'w', encoding='utf-8') as object_fp:
object_fp.write(text_json)其实这上一步也可以直接用接口地址,或者采用复制粘贴保存到本地,但为了学习爬虫我们还是采用代码的方式保存获取。
解析刚才爬取的json文件,获取想要的信息,并保存到excel中,数据放在本地的好处是执行比较快。
创建一个function_crmeb.py文件
import json
import re
import requests
from openpyxl import Workbook
filename = 'order_list.json'
def load_json(filename):
"""读取json,获取数据"""
with open(filename, 'r') as objfile:
datas = json.load(objfile).get('data', '不存在')
return datas
def read_data(dict_name):
"""
dict_name对应的每个值,读取订单信息
order_id - 订单ID | pay_price - 实际支付 | pay_type_name - 支付类型 | pink_name - 订单类型
mark - 用户备注(邮箱)| total_num - 订单数量 | add_time - 支付时间 | _info - 商品名称(返回一个列表)
"""
datas = load_json(filename)
return [data[dict_name] for data in datas]
def get_request(url, params=None, headers=None):
""" GET方式爬取页面信息,返回推广人信息 """
tgr_list = []
oid = read_data('id')
for id in oid:
params = {'oid': id}
text = requests.get(url, params=params, headers=headers).content.decode('utf-8')
regex = re.compile(r'推广人: (.*)这个文件主要用来获取json的数据,但是他的推广人信息不在这个数据里边,而在每个产品的详情页,他的详情页有是以静态模板生成的,我们需要根据订单ID来获取每个产品的详情页,再利用正则表达式获取推广人信息,并保存到excel中,具体大家看代码吧,这个还有优化的空间,欢迎大家学习研究,请勿用于非法用途。