企业—hadoop简介及其部署
一.hadoop简介及其原理
HDFS原理介绍
HDFS(Hadoop Distributed File System )Hadoop分布式文件系统。是根据google发表的论文翻版的。
1.HDFS的组成:
-
NameNode:Master节点(也称元数据节点),是系统唯一的管理者。负责元数据的管理(名称空间和数据块映射信息);配置副本策略;处理客户端请求
-
DataNode:数据存储节点(也称Slave节点),存储实际的数据;执行数据块的读写;汇报存储信息给NameNode
-
Sencondary NameNode:分担namenode的工作量;是NameNode的冷备份;合并fsimage和fsedits然后再发给namenode。注意:在hadoop 2.x 版本,当启用 hdfs ha 时,将没有这一角色
-
client:系统使用者,调用HDFS API操作文件;与NameNode交互获取文件元数据;与DataNode交互进行数据读写。注意:写数据时文件切分由Client完成
热备份:b是a的热备份,如果a坏掉。那么b立即运行代替a的工作
冷备份:b是a的冷备份,如果a坏掉。那么b不能立即代替a工作。但是b上存储a的一些信息,减少a坏掉之后的损失
2.hdfs架构原则
-
元数据与数据分离:文件本身的属性(即元数据)与文件所持有的数据分离
-
主/从架构:一个HDFS集群是由一个NameNode和一定数目的DataNode组成
-
一次写入多次读取:HDFS中的文件在任何时间只能有一个Writer。当文件被创建,接着写入数据,最后,一旦文件被关闭,就不能再修改
-
移动计算比移动数据更划算:数据运算,越靠近数据,执行运算的性能就越好,由于hdfs数据分布在不同机器上,要让网络的消耗最低,并提高系统的吞吐量,最佳方式是将运算的执行移到离它要处理的数据更近的地方,而不是移动数据
二.部署
实验环境:
- rhel 7.3 firewalld is disabled
| 主机名(IP) | 服务 |
|---|---|
| server5(172.25.254.5) | hdfs,nfs,(namenode) |
| server6(172.25.254.6) | nfs,(datanode) |
| server7(172.25.254.7) | nfs,(datanaode) |
| server8(172.25.254.8) | 客户端,nfs,(datanode) |
1.hadoop部署及其测试
1.建立hadoop用户,并且设置密码
[root@server5 ~]# useradd -u 1000 hadoop
[root@server5 ~]# id hadoop
uid=1000(hadoop) gid=1000(hadoop) groups=1000(hadoop)
[root@server5 ~]# passwd hadoop
2.进入到hadoop用户下,官网下载hadoop安装包并且进行安装,需要配置java的运行环境,因此也需要java的压缩包
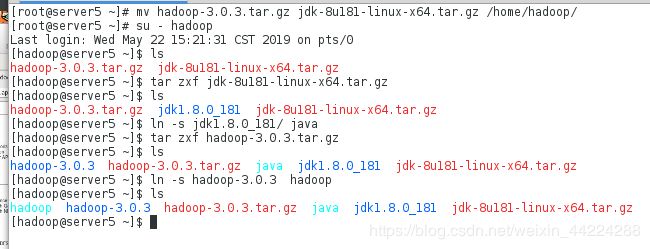
[root@server5 ~]# mv hadoop-3.0.3.tar.gz jdk-8u181-linux-x64.tar.gz /home/hadoop/
[root@server5 ~]# su - hadoop
[hadoop@server5 ~]$ tar zxf jdk-8u181-linux-x64.tar.gz
[hadoop@server5 ~]$ ln -s jdk1.8.0_181/ java
[hadoop@server5 ~]$ tar zxf hadoop-3.0.3.tar.gz
[hadoop@server5 ~]$ ln -s hadoop-3.0.3 hadoop
3.在hadoop的配置文件中添加java的路径
[hadoop@server5 hadoop]$ pwd
/home/hadoop/hadoop/etc/hadoop
[hadoop@server5 hadoop]$ vim hadoop-env.sh
文件编辑内容如下:
54 export JAVA_HOME=/home/hadoop/java
4.配置java的环境变量
[hadoop@server5 ~]$ vim .bash_profile
文件编辑内容如下:
10 PATH=$PATH:$HOME/.local/bin:$HOME/bin:$HOME/java/bin
[hadoop@server5 ~]$ source .bash_profile
[hadoop@server5 ~]$ jps
1592 Jps ##显示配置成功之后可以调用
5.测试
[hadoop@server5 hadoop]$ pwd
/home/hadoop/hadoop
//建立输入目录
[hadoop@server5 hadoop]$ mkdir input
//将etc/hadoop中的相应的算法案例cp到input目录下:
[hadoop@server5 hadoop]$ cp etc/hadoop/*.xml input/
//执行算法并且将其输出到output目录下:
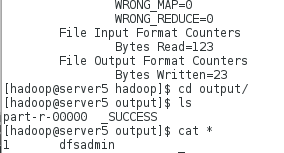
[hadoop@server5 hadoop]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.3.jar grep input/ output 'dfs[a-z.]+'
//进入output目录显示计算成功:
[hadoop@server5 hadoop]$ cd output/
[hadoop@server5 output]$ ls
part-r-00000 _SUCCESS
2.伪分布式
1.server5编辑配置文件
[hadoop@server5 hadoop]$ pwd
/home/hadoop/hadoop/etc/hadoop
[hadoop@server5 hadoop]$ vim core-site.xml
文件编辑内容如下:
19
20
21 fs.defaultFS
22 hdfs://localhost:9000
23
24
[hadoop@server5 hadoop]$ vim hdfs-site.xml
文件编辑内容如下:
19
20
21 dfs.replication
22 1 ##自己充当节点
23
24
~
2.对本机及其相关本机相关域名生成钥匙做免密连接
[hadoop@server5 hadoop]$ ssh-keygen
[hadoop@server5 hadoop]$ ssh-copy-id localhost
[hadoop@server5 hadoop]$ ssh-copy-id server5
3.格式化namenode节点并且卡其hdfs服务
[hadoop@server5 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server5 hadoop]$ bin/hdfs namenode -format
[hadoop@server5 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server5 hadoop]$ cd sbin/
[hadoop@server5 sbin]$ ./start-dfs.sh
Starting namenodes on [localhost]
Starting datanodes
Starting secondary namenodes [server5]
[hadoop@server5 sbin]$ jps //开启服务之后会生成相应的节点
2144 DataNode
2470 Jps
2327 SecondaryNameNode
2045 NameNode
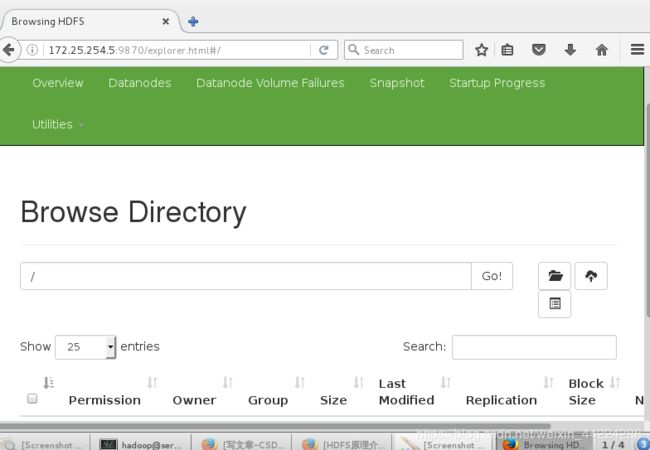
4.在浏览器上查看
http://172.25.254.5:9870
5.测试:
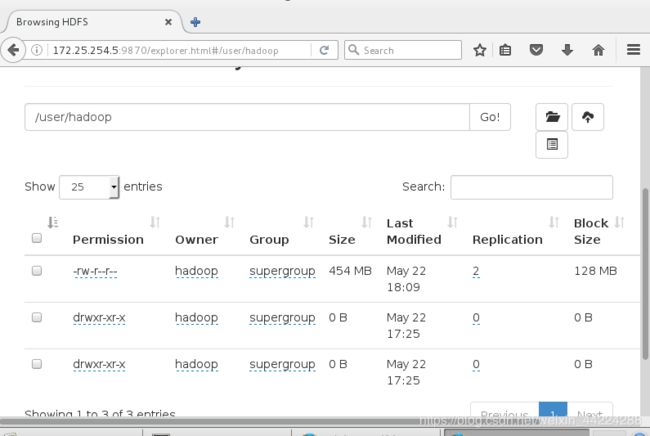
//创建目录,并且上传文件
[hadoop@server5 sbin]$ cd /home/hadoop/hadoop
[hadoop@server5 hadoop]$ bin/hdfs dfs -mkdir -p /user/hadoop
[hadoop@server5 hadoop]$ bin/hdfs dfs -ls
[hadoop@server5 hadoop]$ bin/hdfs dfs -put input
[hadoop@server5 hadoop]$ bin/hdfs dfs -ls ##查看文件上传成功
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2019-05-22 16:01 input
在浏览器页面查看:
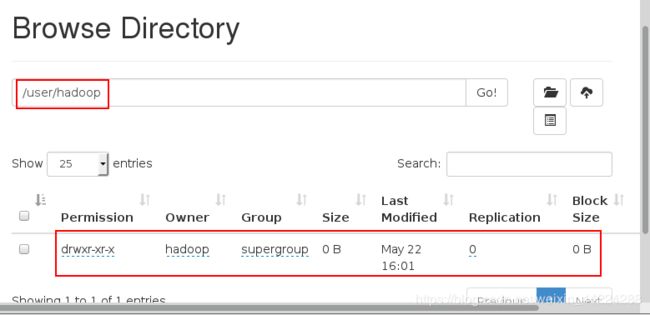
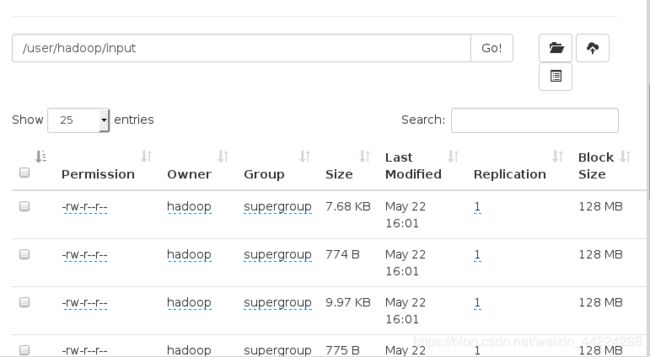
a.删除已经在本机上执行的input和output目录重新进行测试:
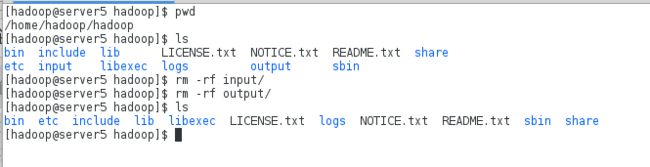
2.重新执行另一种算法来记算wordcount,因为之前在hdfs系统上已经创建了input目录这里直接指定output目录即可,而此时的output目录只有在网页1上才能看到,已经不是本地的了
[hadoop@server5 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server5 hadoop]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.3.jar wordcount input output
查看hdfs文件系统上的output的内容:
[hadoop@server5 hadoop]$ bin/hdfs dfs -cat output/*
从hdfs文件系统上将output目录获取到本地:
[hadoop@server5 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server5 hadoop]$ bin/hdfs dfs -get output
[hadoop@server5 hadoop]$ cd output/
[hadoop@server5 output]$ ls
part-r-00000 _SUCCESS
在浏览器页面查看:
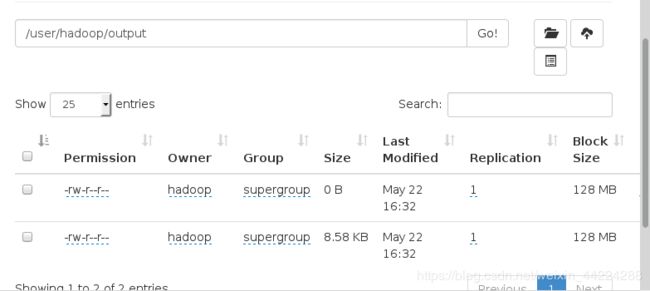
3.分布式hdfs文件系统
1.先停掉hdfs服务并且清除测试时进行相应算法产生的数据,注意算法产生的相应数据都是在/tmp目录下
[hadoop@server5 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server5 hadoop]$ sbin/stop-dfs.sh
[hadoop@server5 hadoop]$ cd /tmp/
[hadoop@server5 tmp]$ ls
hadoop hadoop-hadoop hsperfdata_hadoop
[hadoop@server5 tmp]$ rm -rf *
2.在server5,server6和server7当作节点配置共享nfs文件系统
//创建hadoop用户:在实现nfs共享文件的时候的权限共享,必须保持uid/gid一致,方可权限的传递
[root@server6 ~]# useradd hadoop
[root@server6 ~]# id hadoop
uid=1000(hadoop) gid=1000(hadoop) groups=1000(hadoop)
[root@server7 ~]# useradd hadoop
[root@server7 ~]# id hadoop
uid=1000(hadoop) gid=1000(hadoop) groups=1000(hadoop)
//分别在server5,server6及server7上安装nfs-utils
[root@server5 ~]# yum install -y nfs-utils
[root@server6 ~]# yum install -y nfs-utils
[root@server7 ~]# yum install -y nfs-utils
//在三台主机上开启服务
[root@server5 ~]# systemctl start rpcbind ##如果开启不了服务可以尝试重启以下服务然后再次开启服务就可以了
[root@server6 ~]# systemctl start rpcbind
[root@server7 ~]# systemctl start rpcbind
//在server5(hdfs)上开启nfs服务并且做相应的配置
[root@server5 ~]# systemctl start nfs-server
[root@server5 ~]# vim /etc/exports
文件编辑内容如下:
/home/hadoop *(rw,anonuid=1000,anongid=1000)
[root@server5 ~]# exportfs -rv
exporting *:/home/hadoop
[root@server5 ~]# showmount -e
Export list for server5:
/home/hadoop *
3.在server6及其server7上进行nfs文件系统的挂载
[root@server6 ~]# mount 172.25.254.5:/home/hadoop/ /home/hadoop/
[root@server6 ~]# df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/rhel-root 17811456 1100716 16710740 7% /
devtmpfs 497292 0 497292 0% /dev
tmpfs 508264 0 508264 0% /dev/shm
tmpfs 508264 6740 501524 2% /run
tmpfs 508264 0 508264 0% /sys/fs/cgroup
/dev/sda1 1038336 123376 914960 12% /boot
tmpfs 101656 0 101656 0% /run/user/0
172.25.254.5:/home/hadoop 17811456 2798848 15012608 16% /home/hadoop #显示挂载成功
[root@server7 ~]# mount 172.25.254.5:/home/hadoop/ /home/hadoop/
172.25.254.5:/home/hadoop 17811456 2798848 15012608 16% /home/hadoop #显示挂载成功
4.在server5上对server6及其server7做相应的免密登陆
[hadoop@server5 ~]$ ssh-copy-id 172.25.254.6 ##在进行copy是要输入yes免密登陆就相当于在每次进行连接时输入的yes
[hadoop@server5 ~]$ ssh-copy-id 172.25.254.7
5.编辑server5的hdfs文件系统的配置文件添加服务点口及其修改节点
[hadoop@server5 hadoop]$ pwd
/home/hadoop/hadoop/etc/hadoop
[hadoop@server5 hadoop]$ vim core-site.xml
文件编辑内容如下:
19
20
21 fs.defaultFS
22 hdfs://172.25.254.5:9000
23
24
[hadoop@server5 hadoop]$ vim hdfs-site.xml
文件编辑内容如下:
19
20
21 dfs.replication
22 2 俩个节点
23
24
[hadoop@server5 hadoop]$ vim workers
文件编辑内容:
172.25.254.6
172.25.254.7 #编辑完成之后在其它节点也能看到
server6上查看:
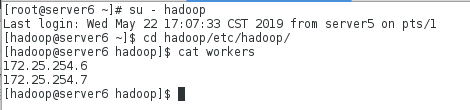
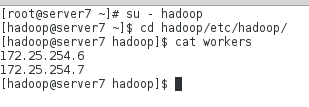
在server7上查看:
6.格式化hdfs文件系统并且开启服务
[hadoop@server5 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server5 hadoop]$ bin/hdfs namenode -format
[hadoop@server5 hadoop]$ sbin/start-dfs.sh
[hadoop@server5 hadoop]$ jps
4489 SecondaryNameNode
4622 Jps
4303 NameNode
在server6及其server7上查看datanode的节点的信息:
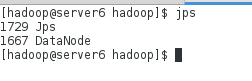
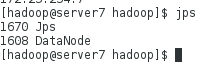
测试:
1.在server5上写入数据
[hadoop@server5 hadoop]$ bin/hdfs -mkdir -p /user/hadoop
[hadoop@server5 hadoop]$ bin/hdfs dfs -mkdir input
[hadoop@server5 hadoop]$ bin/hdfs dfs -put etc/hadoop/*.xml input
[hadoop@server5 hadoop]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.3.jar grep input/ output 'dfs[a-z.]+'
在浏览器上查看:
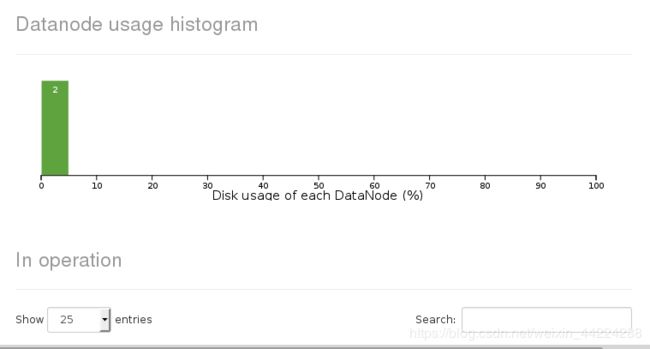
显示数据节点有2个:
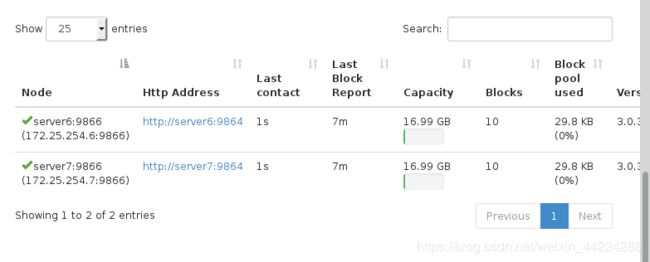
查看数据已经上传:
server8作为客户端进行测试:
[root@server8 ~]# useradd hadoop
[root@server8 ~]# id hadoop
uid=1000(hadoop) gid=1000(hadoop) groups=1000(hadoop)
[root@server8 ~]# yum install -y nfs-utils
[root@server8 ~]# systemctl start rpcbind
[root@server8 ~]# mount 172.25.254.5:/home/hadoop/ /home/hadoop/
如果卡其节点数据不成功可能是因为免密没有做好需要在server5上对server8进行ssh免密登陆
[hadoop@server8 hadoop]$ bin/hdfs --daemon start datanode ##开启数据节点
[hadoop@server8 hadoop]$ jps ##查看节点开启成功
3488 DataNode
3508 Jps
在浏览器上查看该数据节点添加成功:
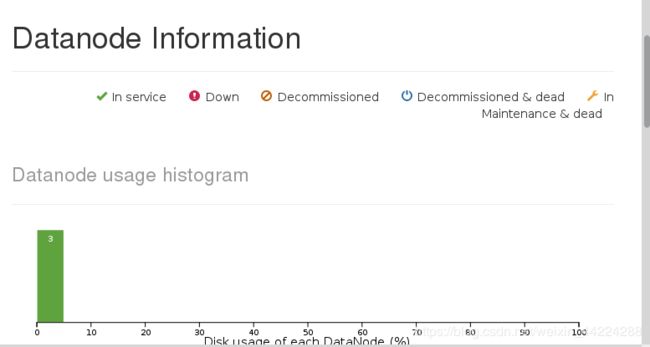
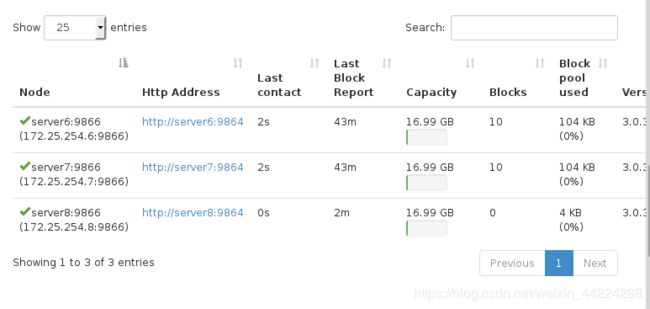
在客户端server8上上传文件并且在浏览器上查看发现数据上传成功:
[hadoop@server8 hadoop]$ dd if=/dev/zero of=file bs=1M count=500
[hadoop@server8 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server8 hadoop]$ bin/hdfs dfs -put file
在浏览器上查看: